给jdk写注释系列之jdk1.6容器(11)-Queue之ArrayDeque源码解析
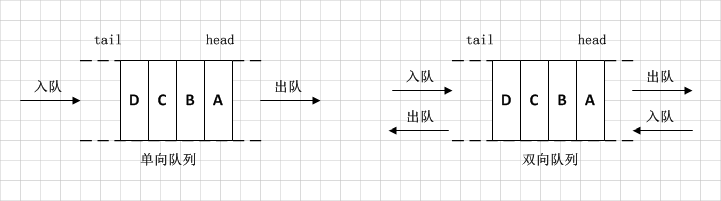
- public class ArrayDeque<E> extends AbstractCollection<E>
- implements Deque<E>, Cloneable, Serializable
- public interface Queue<E> extends Collection<E> {
- // 增加一个元素到队尾,如果队列已满,则抛出一个IIIegaISlabEepeplian异常
- boolean add(E e);
- // 添加一个元素到队尾并返回true,如果队列已满,则返回false
- boolean offer(E e);
- // 移除并返回队列头部的元素,如果队列为空,则抛出一个NoSuchElementException异常
- E remove();
- // 移除并返问队列头部的元素,如果队列为空,则返回null
- E poll();
- // 返回队列头部的元素,如果队列为空,则抛出一个NoSuchElementException异常
- E element();
- // 返问队列头部的元素,如果队列为空,则返回null
- E peek();
- }
- // 底层用数组存储元素
- private transient E[] elements;
- // 队列的头部元素索引(即将pop出的一个)
- private transient int head;
- // 队列下一个要添加的元素索引
- private transient int tail;
- // 最小的初始化容量大小,需要为2的n次幂
- private static final int MIN_INITIAL_CAPACITY = 8;
- /**
- * 默认构造方法,数组的初始容量为16
- */
- public ArrayDeque() {
- elements = (E[]) new Object[16];
- }
- /**
- * 使用一个指定的初始容量构造一个ArrayDeque
- */
- public ArrayDeque( int numElements) {
- allocateElements(numElements);
- }
- /**
- * 构造一个指定Collection集合参数的ArrayDeque
- */
- public ArrayDeque(Collection<? extends E> c) {
- allocateElements(c.size());
- addAll(c);
- }
- /**
- * 分配合适容量大小的数组,确保初始容量是大于指定numElements的最小的2的n次幂
- */
- private void allocateElements(int numElements) {
- int initialCapacity = MIN_INITIAL_CAPACITY;
- // 找到大于指定容量的最小的2的n次幂
- // Find the best power of two to hold elements.
- // Tests "<=" because arrays aren't kept full.
- // 如果指定的容量小于初始容量8,则执行一下if中的逻辑操作
- if (numElements >= initialCapacity) {
- initialCapacity = numElements;
- initialCapacity |= (initialCapacity >>> 1);
- initialCapacity |= (initialCapacity >>> 2);
- initialCapacity |= (initialCapacity >>> 4);
- initialCapacity |= (initialCapacity >>> 8);
- initialCapacity |= (initialCapacity >>> 16);
- initialCapacity++;
- if (initialCapacity < 0) // Too many elements, must back off
- initialCapacity >>>= 1; // Good luck allocating 2 ^ 30 elements
- }
- elements = (E[]) new Object[initialCapacity];
- }
- 2^1 = 10
- 2^2 = 100
- 2^3 = 1000
- 2^n = 1(n个0)
再来看下2^n-1的二进制是什么样子的:
- 2^1 - 1 = 01
- 2^2 - 1 = 011
- 2^3 - 1 = 0111
- 2^n - 1 = 0(n个1)
- // 确保容量为2的n次幂,是capacity为大于initialCapacity的最小的2的n次幂
- int capacity = 1;
- while (capacity < initialCapacity)
- capacity <<= 1;
那么这两种方法有什么区别呢?HashMap中的这种写法更容量理解,而ArrayDeque中的效果更高(最多经过4次位移和或操作+1次加一操作)。
4.入队(添加元素到队尾)
- /**
- * 增加一个元素,如果队列已满,则抛出一个IIIegaISlabEepeplian异常
- */
- public boolean add(E e) {
- // 调用addLast方法,将元素添加到队尾
- addLast(e);
- return true;
- }
- /**
- * 添加一个元素
- */
- public boolean offer(E e) {
- // 调用offerLast方法,将元素添加到队尾
- return offerLast(e);
- }
- /**
- * 在队尾添加一个元素
- */
- public boolean offerLast(E e) {
- // 调用addLast方法,将元素添加到队尾
- addLast(e);
- return true;
- }
- /**
- * 将元素添加到队尾
- */
- public void addLast(E e) {
- // 如果元素为null,咋抛出空指针异常
- if (e == null)
- throw new NullPointerException();
- // 将元素e放到数组的tail位置
- elements[tail ] = e;
- // 判断tail和head是否相等,如果相等则对数组进行扩容
- if ( (tail = (tail + 1) & ( elements.length - 1)) == head)
- // 进行两倍扩容
- doubleCapacity();
- }
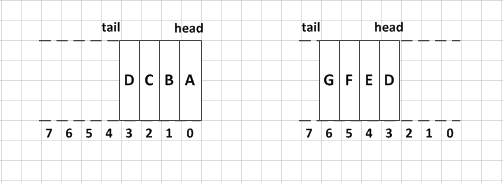
这里,( (tail = (tail + 1) & ( elements.length - 1)) == head)这句代码是关键,为什么会这样写呢。正常的添加元素后应该是将tail+1对不对,但是队列的删除和添加是不在同一端的,什么意思呢,我们画个图看一下。
- 2^1 = 10
- 2^2 = 100
- 2^3 = 1000
- 2^n = 1(n个0)
再来看下2^n-1的二进制是什么样子的:
- 2^1 - 1 = 01
- 2^2 - 1 = 011
- 2^3 - 1 = 0111
- 2^n - 1 = 0(n个1)
- /**
- * 数组将要满了的时候(tail==head)将,数组进行2倍扩容
- */
- private void doubleCapacity() {
- // 验证head和tail是否相等
- assert head == tail;
- int p = head ;
- // 记录数组的长度
- int n = elements .length;
- // 计算head后面的元素个数,这里没有采用jdk中自带的英文注释right,是因为所谓队列的上下左右,只是我们看的方位不同而已,如果上面画的图,这里就应该是left而非right
- int r = n - p; // number of elements to the right of p
- // 将数组长度扩大2倍
- int newCapacity = n << 1;
- // 如果此时长度小于0,则抛出IllegalStateException异常,什么时候newCapacity会小于0呢,前面我们说过了int值<<1越界
- if (newCapacity < 0)
- throw new IllegalStateException( "Sorry, deque too big" );
- // 创建一个长度是原数组大小2倍的新数组
- Object[] a = new Object[newCapacity];
- // 将原数组head后的元素都拷贝值新数组
- System. arraycopy(elements, p, a, 0, r);
- // 将原数组head前的元素都拷贝到新数组
- System. arraycopy(elements, 0, a, r, p);
- // 将新数组赋值给elements
- elements = (E[])a;
- // 重置head为数组的第一个位置索引0
- head = 0;
- // 重置tail为数组的最后一个位置索引+1((length - 1) + 1)
- tail = n;
- }
- /**
- * 移除并返回队列头部的元素,如果队列为空,则抛出一个NoSuchElementException异常
- */
- public E remove() {
- // 调用removeFirst方法,移除队头的元素
- return removeFirst();
- }
- /**
- * @throws NoSuchElementException {@inheritDoc}
- */
- public E removeFirst() {
- // 调用pollFirst方法,移除并返回队头的元素
- E x = pollFirst();
- // 如果队列为空,则抛出NoSuchElementException异常
- if (x == null)
- throw new NoSuchElementException();
- return x;
- }
- /**
- * 移除并返问队列头部的元素,如果队列为空,则返回null
- */
- public E poll() {
- // 调用pollFirst方法,移除并返回队头的元素
- return pollFirst();
- }
- public E pollFirst() {
- int h = head ;
- // 取出数组队头位置的元素
- E result = elements[h]; // Element is null if deque empty
- // 如果数组队头位置没有元素,则返回null值
- if (result == null)
- return null;
- // 将数组队头位置置空,也就是删除元素
- elements[h] = null; // Must null out slot
- // 将head指针往前移动一个位置
- head = (h + 1) & (elements .length - 1);
- // 将队头元素返回
- return result;
- }
- /**
- * 返回队列头部的元素,如果队列为空,则抛出一个NoSuchElementException异常
- */
- public E element() {
- // 调用getFirst方法,获取队头的元素
- return getFirst();
- }
- /**
- * @throws NoSuchElementException {@inheritDoc}
- */
- public E getFirst() {
- // 取得数组head位置的元素
- E x = elements[head ];
- // 如果数组head位置的元素为null,则抛出异常
- if (x == null)
- throw new NoSuchElementException();
- return x;
- }
- /**
- * 返回队列头部的元素,如果队列为空,则返回null
- */
- public E peek() {
- // 调用peekFirst方法,获取队头的元素
- return peekFirst();
- }
- public E peekFirst() {
- // 取得数组head位置的元素并返回
- return elements [head]; // elements[head] is null if deque empty
- }
给jdk写注释系列之jdk1.6容器(11)-Queue之ArrayDeque源码解析的更多相关文章
- 给jdk写注释系列之jdk1.6容器(8)-TreeSet&NavigableMap&NavigableSet源码解析
TreeSet是一个有序的Set集合. 既然是有序,那么它是靠什么来维持顺序的呢,回忆一下TreeMap中是怎么比较两个key大小的,是通过一个比较器Comparator对不对,不过遗憾的是,今天仍然 ...
- 给jdk写注释系列之jdk1.6容器(13)-总结篇之Java集合与数据结构
是的,这篇blogs是一个总结篇,最开始的时候我提到过,对于java容器或集合的学习也可以看做是对数据结构的学习与应用.在前面我们分析了很多的java容器,也接触了好多种常用的数据结构,今天 ...
- 给jdk写注释系列之jdk1.6容器(12)-PriorityQueue源码解析
PriorityQueue是一种什么样的容器呢?看过前面的几个jdk容器分析的话,看到Queue这个单词你一定会,哦~这是一种队列.是的,PriorityQueue是一种队列,但是它又是一种什么样的队 ...
- 给jdk写注释系列之jdk1.6容器(9)-Strategy设计模式之Comparable&Comparator接口
前面我们说TreeMap和TreeSet都是有顺序的集合,而顺序的维持是要靠一个比较器Comparator或者map的key实现Comparable接口. 既然说到排序,首先我们不用去关心什 ...
- 给jdk写注释系列之jdk1.6容器(7)-TreeMap源码解析
TreeMap是基于红黑树结构实现的一种Map,要分析TreeMap的实现首先就要对红黑树有所了解. 要了解什么是红黑树,就要了解它的存在主要是为了解决什么问题,对比其他数据结构比如数组,链 ...
- 给jdk写注释系列之jdk1.6容器(10)-Stack&Vector源码解析
前面我们已经接触过几种数据结构了,有数组.链表.Hash表.红黑树(二叉查询树),今天再来看另外一种数据结构:栈. 什么是栈呢,我就不找它具体的定义了,直接举个例子,栈就相当于一个很窄的木桶 ...
- 给jdk写注释系列之jdk1.6容器(6)-HashSet源码解析&Map迭代器
今天的主角是HashSet,Set是什么东东,当然也是一种java容器了. 现在再看到Hash心底里有没有会心一笑呢,这里不再赘述hash的概念原理等一大堆东西了(不懂得需要先回去看下Has ...
- 给jdk写注释系列之jdk1.6容器(5)-LinkedHashMap源码解析
前面分析了HashMap的实现,我们知道其底层数据存储是一个hash表(数组+单向链表).接下来我们看一下另一个LinkedHashMap,它是HashMap的一个子类,他在HashMap的基础上维持 ...
- 给jdk写注释系列之jdk1.6容器(4)-HashMap源码解析
前面了解了jdk容器中的两种List,回忆一下怎么从list中取值(也就是做查询),是通过index索引位置对不对,由于存入list的元素时安装插入顺序存储的,所以index索引也就是插入的次序. M ...
随机推荐
- Salt自动化之自动更新Gitfs-爱折腾技术网
Salt自动化之自动更新Gitfs-爱折腾技术网 pygit2
- 第二百七十九天 how can I 坚持
竟然说我是猪,也是有点受不了了.其实也没什么,无所谓. 一个人有了信仰,不管成不成功,至少不会迷茫. sql语句,left on and 和where,left on是先检索,再关联,主表是完整 ...
- 转】Apache解决高并发和高可用
原博主于: http://www.ha97.com/5803.html 感谢! 服务器集群 Apache 和 nginx(web服务器) 1. 多台集群机器联合处理一个任务. 2. 一台机器处 ...
- typedef typedef struct的使用
typedef通常情况用于声明结构体之类的 1,定义某些便于记忆的结构体或者使现有的类型看上去更加整齐,比如后来因为经常使用而被添加进入c/c++标准头文件的stdint.h typedef sign ...
- HDU 3416 Marriage Match IV (求最短路的条数,最大流)
Marriage Match IV 题目链接: http://acm.hust.edu.cn/vjudge/contest/122685#problem/Q Description Do not si ...
- Spring bean configuration inheritance
In Spring, the inheritance is supported in bean configuration for a bean to share common values, pro ...
- js写的替换字符串(相当于js操作字符串的一个练习)
1.达到的效果 1./main_1.do,/left_1.do -> main:1,left:1 2./tbl_type/v_list_{id}.do -> tbl_type:list:{ ...
- 框架学习笔记:深度解析StrangeIoC内部运行机制
StrangeIoC的设计和RobotLegs一致,所以我的解析会对照RobotLegs来看. 整个框架使用的是MVCS的模式,关于MVCS模式大家可以点这里进行查看,这里就不谈了,既然Strange ...
- hdu 4786 Fibonacci Tree (2013ACMICPC 成都站 F)
http://acm.hdu.edu.cn/showproblem.php?pid=4786 Fibonacci Tree Time Limit: 4000/2000 MS (Java/Others) ...
- HTML5画布Canvas
一.Canvas概念介绍 1.概念 Canvas : 画布 2.作用 : HTML5 Canvas 元素用于图形的绘制, 通过脚本(通常是JavaScript)来完成.它本身只是个图形容器,必须使用脚 ...