Spark的DataFrame的窗口函数使用
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处
SparkSQL这块儿从1.4开始支持了很多的窗口分析函数,像row_number这些,平时写程序加载数据后用SQLContext 能够很方便实现很多分析和查询,如下
val sqlContext = new SQLContext(sc)
sqlContext.sql(“select ….”)
然而我看到Spark后续版本的DataFrame功能很强大,想试试使用这种方式来实现比如row_number这种功能,话不多说,快速用pyspark测试一下,记录一下遇到的问题.
from pyspark.sql import Row, functions as F
from pyspark.sql.window import Window
from pyspark import SparkContext
sc = SparkContext("local[3]", "test data frame on 2.0")
testDF = sc.parallelize( (Row(c="class1", s=50), Row(c="class2", s=40), Row(c="class3", s=70), Row(c="class2", s=49), Row(c="class3", s=29), Row(c="class1", s=78) )).toDF()
(testDF.select("c", "s", F.rowNumber().over(Window.partitionBy("c").orderBy("s")).alias("rowNum") ).show())
spark-submit提交任务后直接报错如下

告诉我RDD没有toDF()属性,查阅spark官方文档得知还是需要用SQLContext或者sparkSession来初始化一下,先考虑用SQLContext吧,修改代码如下
from pyspark.sql import Row, functions as F
from pyspark.sql.window import Window
from pyspark import SparkContext
from pyspark.sql import SQLContext
sc = SparkContext("local[3]", "test data frame on 2.0")
rddData = sc.parallelize( (Row(c="class1", s=50), Row(c="class2", s=40), Row(c="class3", s=70), Row(c="class2", s=49), Row(c="class3", s=29), Row(c="class1", s=78)))
sqlContext = SQLContext(sc)
testDF = rddData.toDF()
(testDF.select("c", "s", F.rowNumber().over(Window.partitionBy("c").orderBy("s")).alias("rowNum") ).show())
spark-submit提交任务后接着报另外一个错,如下

ok,错误很清楚,rowNumber这里我写错了,没有这个函数,查阅spark源码中的functions.py,会发现如下说明
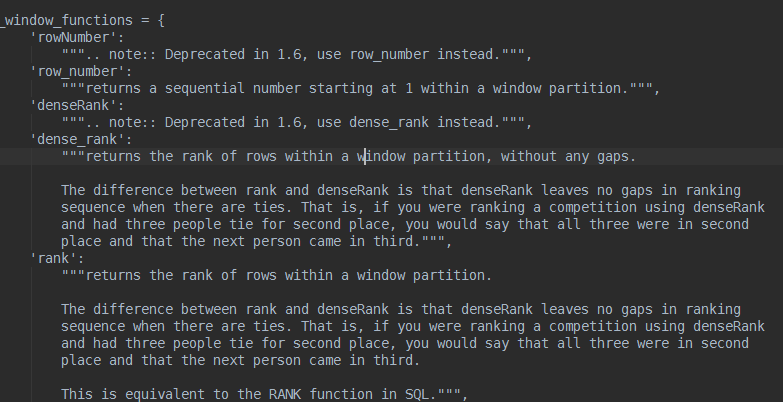
这里说了,rowNumber从1.6开始,用row_number代替,直接修改py脚本如下
from pyspark.sql import Row, functions as F
from pyspark.sql.window import Window
from pyspark import SparkContext
from pyspark.sql import SQLContext
sc = SparkContext("local[3]", "test data frame on 2.0")
rddData = sc.parallelize( (Row(c="class1", s=50), Row(c="class2", s=40), Row(c="class3", s=70), Row(c="class2", s=49), Row(c="class3", s=29), Row(c="class1", s=78)))
sqlContext = SQLContext(sc)
testDF = rddData.toDF()
(testDF.select("c", "s", F.row_number().over(Window.partitionBy("c").orderBy("s")).alias("rowNum") ).show())
这次运行没问题,结果如下
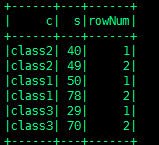
但是我只想取每组rowNum为1的那个,代码如下
from pyspark.sql import Row, functions as F
from pyspark.sql.window import Window
from pyspark import SparkContext
from pyspark.sql import SQLContext
sc = SparkContext("local[3]", "test data frame on 2.0")
rddData = sc.parallelize( (Row(c="class1", s=50), Row(c="class2", s=40), Row(c="class3", s=70), Row(c="class2", s=49), Row(c="class3", s=29), Row(c="class1", s=78)))
sqlContext = SQLContext(sc)
testDF = rddData.toDF()
result = (testDF.select("c", "s", F.row_number().over(Window.partitionBy("c").orderBy("s")).alias("rowNum")))
finalResult = result.where(result.rowNum <= 1).show()
可以看到,sql能实现的DataFrame的函数都可以实现,毕竟DataFrame是基于row和column的,就是写起来麻烦点.
参考资料:http://spark.apache.org/docs/1.3.1/api/python/pyspark.sql.html
Spark的DataFrame的窗口函数使用的更多相关文章
- Spark sql -- Spark sql中的窗口函数和对应的api
一.窗口函数种类 ranking 排名类 analytic 分析类 aggregate 聚合类 Function Type SQL DataFrame API Description Ranking ...
- pandas和spark的dataframe互转
pandas的dataframe转spark的dataframe from pyspark.sql import SparkSession # 初始化spark会话 spark = SparkSess ...
- 【spark】dataframe常见操作
spark dataframe派生于RDD类,但是提供了非常强大的数据操作功能.当然主要对类SQL的支持. 在实际工作中会遇到这样的情况,主要是会进行两个数据集的筛选.合并,重新入库. 首先加载数据集 ...
- Spark操作dataFrame进行写入mysql,自定义sql的方式
业务场景: 现在项目中需要通过对spark对原始数据进行计算,然后将计算结果写入到mysql中,但是在写入的时候有个限制: 1.mysql中的目标表事先已经存在,并且当中存在主键,自增长的键id 2. ...
- Spark:将DataFrame写入Mysql
Spark将DataFrame进行一些列处理后,需要将之写入mysql,下面是实现过程 1.mysql的信息 mysql的信息我保存在了外部的配置文件,这样方便后续的配置添加. //配置文件示例: [ ...
- Spark:DataFrame批量导入Hbase的两种方式(HFile、Hive)
Spark处理后的结果数据resultDataFrame可以有多种存储介质,比较常见是存储为文件.关系型数据库,非关系行数据库. 各种方式有各自的特点,对于海量数据而言,如果想要达到实时查询的目的,使 ...
- [Spark][Python][DataFrame][RDD]DataFrame中抽取RDD例子
[Spark][Python][DataFrame][RDD]DataFrame中抽取RDD例子 sqlContext = HiveContext(sc) peopleDF = sqlContext. ...
- [Spark][Python][DataFrame][RDD]从DataFrame得到RDD的例子
[Spark][Python][DataFrame][RDD]从DataFrame得到RDD的例子 $ hdfs dfs -cat people.json {"name":&quo ...
- [Spark][Python][DataFrame][Write]DataFrame写入的例子
[Spark][Python][DataFrame][Write]DataFrame写入的例子 $ hdfs dfs -cat people.json {"name":" ...
随机推荐
- 终于等到你:CYQ.Data V5系列 (ORM数据层)最新版本开源了
前言: 不要问我框架为什么从收费授权转到免费开源,人生没有那么多为什么,这些年我开源的东西并不少,虽然这个是最核心的,看淡了就也没什么了. 群里的网友:太平说: 记得一年前你开源另一个项目的时候我就说 ...
- 【AutoMapper官方文档】DTO与Domin Model相互转换(上)
写在前面 AutoMapper目录: [AutoMapper官方文档]DTO与Domin Model相互转换(上) [AutoMapper官方文档]DTO与Domin Model相互转换(中) [Au ...
- C语言 · Anagrams问题
问题描述 Anagrams指的是具有如下特性的两个单词:在这两个单词当中,每一个英文字母(不区分大小写)所出现的次数都是相同的.例如,"Unclear"和"Nuclear ...
- android http 抓包
有时候想开发的时候想看APP发出的http请求和响应是什么,这就需要抓包了,这可以得到一些不为人知的api,比如还可以干些“坏事”... 需要工具: Fiddler2 抓包(点击下载) Android ...
- 深入理解MySql子查询IN的执行和优化
IN为什么慢? 在应用程序中使用子查询后,SQL语句的查询性能变得非常糟糕.例如: SELECT driver_id FROM driver where driver_id in (SELECT dr ...
- C#中如何在Excel工作表创建混合型图表
在进行图表分析的时候,我们可能需要在一张图表呈现两个或多个样式的图表,以便更加清晰.直观地查看不同的数据大小和变化趋势.在这篇文章中,我将分享C#中如何在一张图表中创建不同的图表类型,其中包括如何在同 ...
- PHP之购物车的代码
该文章记录了购物车的实现代码,仅供参考 book_sc_fns.php <?php include_once('output_fns.php'); include_once('book_fns. ...
- ABP领域层
1.实体Entites 1.1 概念 实体是DDD(领域驱动设计)的核心概念之一. 实体是具有唯一标识的ID且存储在数据库总.实体通常被映射成数据库中的一个表. 在ABP中,实体继承自Entity类. ...
- JavaScript学习笔记(四)——jQuery插件开发与发布
jQuery插件就是以jQuery库为基础衍生出来的库,jQuery插件的好处是封装功能,提高了代码的复用性,加快了开发速度,现在网络上开源的jQuery插件非常多,随着版本的不停迭代越来越稳定好用, ...
- iOS自定义model排序
在开发过程中,可能需要按照model的某种属性排序. 1.自定义model @interface Person : NSObject @property (nonatomic,copy) NSStri ...