稀疏自动编码之反向传播算法(BP)
假设给定m个训练样本的训练集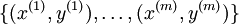 ,用梯度下降法训练一个神经网络,对于单个训练样本(x,y),定义该样本的损失函数:
,用梯度下降法训练一个神经网络,对于单个训练样本(x,y),定义该样本的损失函数:
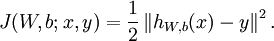
那么整个训练集的损失函数定义如下:
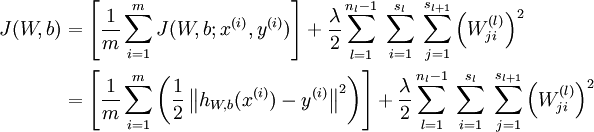
第一项是所有样本的方差的均值。第二项是一个归一化项(也叫权重衰减项),该项是为了减少权连接权重的更新速度,防止过拟合。
我们的目标是最小化关于 W 和 b 的函数J(W,b). 为了训练神经网络,把每个参数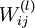 和
和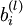 初始化为很小的接近于0的随机值(例如随机值由正态分布Normal(0,ε2)采样得到,把 ε 设为0.01), 然后运用批量梯度下降算法进行优化。由于 J(W,b) 是一个非凸函数,梯度下降很容易收敛到局部最优,但是在实践中,梯度下降往往可以取得不错的效果。最后,注意随机初始化参数的重要性,而不是全部初始化为0. 如果所有参数的初始值相等,那么所有的隐层节点会输出会全部相等,因为训练集是一样的,即输入一样,如果每个模型的参数还都一样,输出显然会相同,这样不论更新多少次参数,所有的参数还是会相等。随机初始化各个参数就是为了防止这种情况发生。
初始化为很小的接近于0的随机值(例如随机值由正态分布Normal(0,ε2)采样得到,把 ε 设为0.01), 然后运用批量梯度下降算法进行优化。由于 J(W,b) 是一个非凸函数,梯度下降很容易收敛到局部最优,但是在实践中,梯度下降往往可以取得不错的效果。最后,注意随机初始化参数的重要性,而不是全部初始化为0. 如果所有参数的初始值相等,那么所有的隐层节点会输出会全部相等,因为训练集是一样的,即输入一样,如果每个模型的参数还都一样,输出显然会相同,这样不论更新多少次参数,所有的参数还是会相等。随机初始化各个参数就是为了防止这种情况发生。
梯度下降每一次迭代用下面的方式更新参数W 和 b:
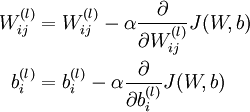
其中 α 是学习率。上述迭代的关键是计算偏导数。我们将给出一种方向传播算法,能够高效地计算这些偏导数。
由上面的总体的损失函数公式, 很容易得到偏导数公式如下:
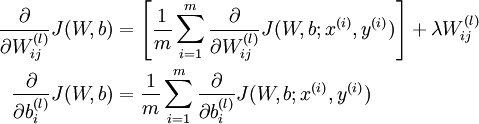
反向传播算法的思想是:给定某个训练样本(x,y),首先进行“前向传播”计算出整个网络中所有节点的激活值,包括输出节点的输出值。那么对于 l 层的节点 i ,计算它的“残差” 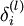 ,这个残差用来衡量该节点对输出的残差产生了多大程度的影响。对于输出节点,我们可以直接比较出网络的激活值与真正的目标值之间的残差,即
,这个残差用来衡量该节点对输出的残差产生了多大程度的影响。对于输出节点,我们可以直接比较出网络的激活值与真正的目标值之间的残差,即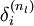 (nl 层就是输出层) 。对于隐层节点,我们用 l+1 层残差的加权平均值和 l 层的激活值来计算 .
(nl 层就是输出层) 。对于隐层节点,我们用 l+1 层残差的加权平均值和 l 层的激活值来计算 .
下面详细给出了反向传播算法的步骤:
1. 进行前馈传播,计算每一层的中所有节点的激活值
2. 对于输出层(第nl 层)的节点 i 的残差:
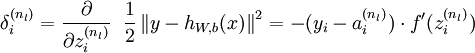
这里需要注意: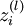 表示第 l 层节点 i 的所有输出之和,f 是激活函数,例如
表示第 l 层节点 i 的所有输出之和,f 是激活函数,例如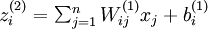 ,
,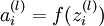 等,另外,最后一层(输出层)的假设函数
等,另外,最后一层(输出层)的假设函数 的输出值就是该层节点的激活值。
的输出值就是该层节点的激活值。
3. 对于 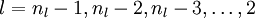
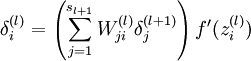
4. 计算偏导数:
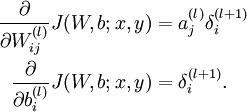
下面用矩阵-向量化的操作方式重写这个算法。其中" "表示matlab中的点乘。对于
"表示matlab中的点乘。对于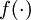 同样向量化,
同样向量化,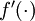 也作同样处理,即
也作同样处理,即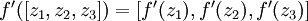 .
.
BP算法重写如下:
1. 进行前馈传播,计算每一层的中所有节点的激活值
2. 对于输出层(第nl 层)的节点 i 的残差:
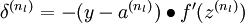
3. 对于
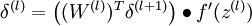
4. 计算偏导数:
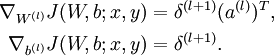
注意:在上面的第2步和第3步,,我们需要为每一个 节点 i 计算其 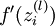 . 假设
. 假设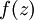 是sigmoid激活函数,在前向传播的过程中已经存储了所有节点的激活值
是sigmoid激活函数,在前向传播的过程中已经存储了所有节点的激活值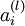 ,因此利用我们在
,因此利用我们在
稀疏自动编码之神经网络
中推导出的sigmoid激活函数的导数求法:对于sigmoid函数f(z) = 1 / (1 + exp( − z)),它的导函数为f'(z) = f(z)(1 − f(z)).可以提前算出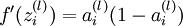 ,这里用到我们上面提到的.
,这里用到我们上面提到的.
最后,给出完整的梯度下降法.在下面的伪代码中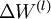 ,
,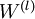 都是矩阵,
都是矩阵,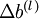 ,
,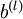 是向量。
是向量。
1. 对于每一层,即所有 l , 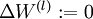 ,
, 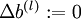 (设置为全零矩阵或者向量)
(设置为全零矩阵或者向量)
2. 从第一个训练样本开始,一直到最后一个(第 m 个训练样本):
a. 用反向传播计算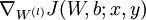 和
和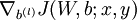
b. 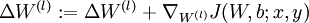 .
.
c. 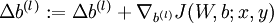 .
.
3. 更新参数:
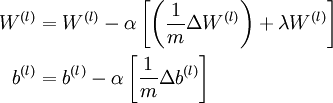
现在,我们可以重复梯度下降法的迭代步骤来减小损失函数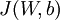 的值,进而训练出我们的神经网络。
的值,进而训练出我们的神经网络。
学习来源:http://deeplearning.stanford.edu/wiki/index.php/Backpropagation_Algorithm
稀疏自动编码之反向传播算法(BP)的更多相关文章
- 深度神经网络(DNN)反向传播算法(BP)
在深度神经网络(DNN)模型与前向传播算法中,我们对DNN的模型和前向传播算法做了总结,这里我们更进一步,对DNN的反向传播算法(Back Propagation,BP)做一个总结. 1. DNN反向 ...
- 【机器学习】反向传播算法 BP
知识回顾 1:首先引入一些便于稍后讨论的新标记方法: 假设神经网络的训练样本有m个,每个包含一组输入x和一组输出信号y,L表示神经网络的层数,S表示每层输入的神经元的个数,SL代表最后一层中处理的单元 ...
- 神经网络与机器学习 笔记—反向传播算法(BP)
先看下面信号流图,L=2和M0=M1=M2=M3=3的情况,上面是前向通过,下面部分是反向通过. 1.初始化.假设没有先验知识可用,可以以一个一致分布来随机的挑选突触权值和阈值,这个分布选择为均值等于 ...
- 卷积神经网络(CNN)反向传播算法
在卷积神经网络(CNN)前向传播算法中,我们对CNN的前向传播算法做了总结,基于CNN前向传播算法的基础,我们下面就对CNN的反向传播算法做一个总结.在阅读本文前,建议先研究DNN的反向传播算法:深度 ...
- 神经网络训练中的Tricks之高效BP(反向传播算法)
神经网络训练中的Tricks之高效BP(反向传播算法) 神经网络训练中的Tricks之高效BP(反向传播算法) zouxy09@qq.com http://blog.csdn.net/zouxy09 ...
- 机器学习 —— 基础整理(七)前馈神经网络的BP反向传播算法步骤整理
这里把按 [1] 推导的BP算法(Backpropagation)步骤整理一下.突然想整理这个的原因是知乎上看到了一个帅呆了的求矩阵微分的方法(也就是 [2]),不得不感叹作者的功力.[1] 中直接使 ...
- 【深度学习】BP反向传播算法Python简单实现
转载:火烫火烫的 个人觉得BP反向传播是深度学习的一个基础,所以很有必要把反向传播算法好好学一下 得益于一步一步弄懂反向传播的例子这篇文章,给出一个例子来说明反向传播 不过是英文的,如果你感觉不好阅读 ...
- 反向传播(BP)算法理解以及Python实现
全文参考<机器学习>-周志华中的5.3节-误差逆传播算法:整体思路一致,叙述方式有所不同: 使用如上图所示的三层网络来讲述反向传播算法: 首先需要明确一些概念, 假设数据集\(X=\{x^ ...
- 人工神经网络反向传播算法(BP算法)证明推导
为了搞明白这个没少在网上搜,但是结果不尽人意,最后找到了一篇很好很详细的证明过程,摘抄整理为 latex 如下. (原文:https://blog.csdn.net/weixin_41718085/a ...
随机推荐
- RandomAcessFile、MappedByteBuffer和缓冲读/写文件
项目需要进行大文件的读写,调查测试的结果使我决定使用MappedByteBuffer及相关类进行文件的操作,效果不是一般的高. 网上参考资源很多,如下两篇非常不错: 1.花1K内存实现高效I/O的Ra ...
- android操作文件
Android中读取/写入文件的方法,与Java中的I/O是一样的,提供了openFileInput()和openFileOutput()方法来读取设备上的文件.但是在默认状态下,文件是不能在不同的程 ...
- boost的link 和 runtime-link,搭配shared 和 static
转自:http://blog.csdn.net/yasi_xi/article/details/8660549 link:生成动态链接库/静态链接库.生成动态链接库需使用shared方式,生成静态链接 ...
- 从SVN导出指定版本号之间修改的文件(转)
从SVN导出指定版本号之间修改的文件(转) 当一个网站项目进入运营维护阶段以后,不会再频繁地更新全部源文件到服务器,这个时间的修改大多是局部的,因此更新文件只需更新修改过的文件,其他没有修改过的文 ...
- STM32 UART 重映射
在进行原理图设计的时候发现管脚的分配之间有冲突,需要对管脚进行重映射,在手册中了解到STM32 上有很多I/O口,也有很多的内置外设像:I2C,ADC,ISP,USART等 ,为了节省引出管脚,这些内 ...
- python27+django调用数据库
我用的mysql版,先上无模板的版本,在views里加上 import MySQLdb 然后在下方写函数 def use_databases(request): db = MySQLdb.connec ...
- 【JNI】OPUS压缩与解压的JNI调用(.DLL版本)
OPUS压缩与解压的JNI调用(.DLL版本) 一.写在开头: 理论上讲,这是我在博客园的第一篇原创的博客,之前也一直想找个地方写点东西,把最近做的一些东西归纳总结下,但是一般工程做完了一高兴就把东西 ...
- mybatis源码学习: 编译的方法
mybatis3用了一段时间,抽出时间来研究一下.具体用法参考官方文档就行,源码在这里.mybatis相对而言,规模较小,可以从中学习如何编写高质量的java项目. mybatis3使用maven管理 ...
- Linux下gdb使用整理记录
1.创建cpp文件:vim sourcefile.cpp 2.生成可执行文件:g++ -g sourcefile.cpp -o exename ------据说是要必须加上-g参数,否则不可调试 3. ...
- Strom学习笔记一
---恢复内容开始--- Storm 是个实时的.分布式以及具备高容错的计算系统.同Hadoop一样Storm也可以处理大批量的数据,然而Storm在保证高可靠性的前提下还可以让处理进行的更加实时:也 ...