Skip list--reference wiki
In computer science, a skip list is a data structure that allows fast search within an ordered sequence of elements. Fast search is made possible by maintaining a linked hierarchy of subsequences, each skipping over fewer elements. Searching starts in the sparsest subsequence until two consecutive elements have been found, one smaller and one larger than the element searched for. Via the linked hierarchy these two elements link to elements of the next sparsest subsequence where searching is continued until finally we are searching in the full sequence. The elements that are skipped over may be chosen probabilistically.[2][3]
Properties:
| Skip List | ||
|---|---|---|
| Type | List | |
| Invented | 1989 | |
| Invented by | W. Pugh | |
| Time complexity in big O notation |
||
| Average | Worst case | |
| Space | O(n) | O(n log n)[1] |
| Search | O(log n) | O(n)[1] |
| Insert | O(log n) | O(n) |
| Delete | O(log n) | O(n) |
Contents
Description
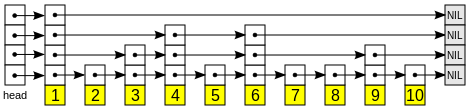
A skip list is built in layers. The bottom layer is an ordinary ordered linked list. Each higher layer acts as an "express lane" for the lists below, where an element in layer i appears in layer i+1 with some fixed probability p (two commonly used values for p are 1/2 or 1/4). On average, each element appears in 1/(1-p) lists, and the tallest element (usually a special head element at the front of the skip list) in 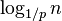 lists.
lists.
A search for a target element begins at the head element in the top list, and proceeds horizontally until the current element is greater than or equal to the target. If the current element is equal to the target, it has been found. If the current element is greater than the target, or the search reaches the end of the linked list, the procedure is repeated after returning to the previous element and dropping down vertically to the next lower list. The expected number of steps in each linked list is at most 1/p, which can be seen by tracing the search path backwards from the target until reaching an element that appears in the next higher list or reaching the beginning of the current list. Therefore, the total expected cost of a search is  which is
which is 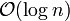 when p is a constant. By choosing different values of p, it is possible to trade search costs against storage costs.
when p is a constant. By choosing different values of p, it is possible to trade search costs against storage costs.
Implementation details


Inserting elements to skip list
The elements used for a skip list can contain more than one pointer since they can participate in more than one list.
Insertions and deletions are implemented much like the corresponding linked-list operations, except that "tall" elements must be inserted into or deleted from more than one linked list.
 operations, which force us to visit every node in ascending order (such as printing the entire list), provide the opportunity to perform a behind-the-scenes derandomization of the level structure of the skip-list in an optimal way, bringing the skip list to
operations, which force us to visit every node in ascending order (such as printing the entire list), provide the opportunity to perform a behind-the-scenes derandomization of the level structure of the skip-list in an optimal way, bringing the skip list to 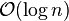 search time. (Choose the level of the i'th finite node to be 1 plus the number of times we can repeatedly divide i by 2 before it becomes odd. Also, i=0 for the negative infinity header as we have the usual special case of choosing the highest possible level for negative and/or positive infinite nodes.) However this also allows someone to know where all of the higher-than-level 1 nodes are and delete them.
search time. (Choose the level of the i'th finite node to be 1 plus the number of times we can repeatedly divide i by 2 before it becomes odd. Also, i=0 for the negative infinity header as we have the usual special case of choosing the highest possible level for negative and/or positive infinite nodes.) However this also allows someone to know where all of the higher-than-level 1 nodes are and delete them.
Alternatively, we could make the level structure quasi-random in the following way:
make all nodes level 1
j ← 1
while the number of nodes at level j > 1 do
for each i'th node at level j do
if i is odd
if i is not the last node at level j
randomly choose whether to promote it to level j+1
else
do not promote
end if
else if i is even and node i-1 was not promoted
promote it to level j+1
end if
repeat
j ← j + 1
repeat
Like the derandomized version, quasi-randomization is only done when there is some other reason to be running a operation (which visits every node).
The advantage of this quasi-randomness is that it doesn't give away nearly as much level-structure related information to an adversarial user as the de-randomized one. This is desirable because an adversarial user who is able to tell which nodes are not at the lowest level can pessimize performance by simply deleting higher-level nodes. The search performance is still guaranteed to be logarithmic.
It would be tempting to make the following "optimization": In the part which says "Next, for each i'th...", forget about doing a coin-flip for each even-odd pair. Just flip a coin once to decide whether to promote only the even ones or only the odd ones. Instead of 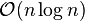 coin flips, there would only be of them. Unfortunately, this gives the adversarial user a 50/50 chance of being correct upon guessing that all of the even numbered nodes (among the ones at level 1 or higher) are higher than level one. This is despite the property that he has a very low probability of guessing that a particular node is at level N for some integer N.
coin flips, there would only be of them. Unfortunately, this gives the adversarial user a 50/50 chance of being correct upon guessing that all of the even numbered nodes (among the ones at level 1 or higher) are higher than level one. This is despite the property that he has a very low probability of guessing that a particular node is at level N for some integer N.
A skip list does not provide the same absolute worst-case performance guarantees as more traditional balanced tree data structures, because it is always possible (though with very low probability) that the coin-flips used to build the skip list will produce a badly balanced structure. However, they work well in practice, and the randomized balancing scheme has been argued to be easier to implement than the deterministic balancing schemes used in balanced binary search trees. Skip lists are also useful in parallel computing, where insertions can be done in different parts of the skip list in parallel without any global rebalancing of the data structure. Such parallelism can be especially advantageous for resource discovery in an ad-hoc Wireless network because a randomized skip list can be made robust to the loss of any single node.[4]
There has been some evidence that skip lists have worse real-world performance and space requirements than B trees due to memory locality and other issues.[5]
Indexable skiplist
As described above, a skiplist is capable of fast insertion and removal of values from a sorted sequence, but it has only slow lookups of values at a given position in the sequence (i.e. return the 500th value); however, with a minor modification the speed of random access indexed lookups can be improved to .
For every link, also store the width of the link. The width is defined as the number of bottom layer links being traversed by each of the higher layer "express lane" links.
For example, here are the widths of the links in the example at the top of the page:
1 10
o---> o---------------------------------------------------------> o Top level
1 3 2 5
o---> o---------------> o---------> o---------------------------> o Level 3
1 2 1 2 5
o---> o---------> o---> o---------> o---------------------------> o Level 2
1 1 1 1 1 1 1 1 1 1 1
o---> o---> o---> o---> o---> o---> o---> o---> o---> o---> o---> o Bottom level Head 1st 2nd 3rd 4th 5th 6th 7th 8th 9th 10th NIL
Node Node Node Node Node Node Node Node Node Node
Notice that the width of a higher level link is the sum of the component links below it (i.e. the width 10 link spans the links of widths 3, 2 and 5 immediately below it). Consequently, the sum of all widths is the same on every level (10 + 1 = 1 + 3 + 2 + 5 = 1 + 2 + 1 + 2 + 5).
To index the skiplist and find the i'th value, traverse the skiplist while counting down the widths of each traversed link. Descend a level whenever the upcoming width would be too large.
For example, to find the node in the fifth position (Node 5), traverse a link of width 1 at the top level. Now four more steps are needed but the next width on this level is ten which is too large, so drop one level. Traverse one link of width 3. Since another step of width 2 would be too far, drop down to the bottom level. Now traverse the final link of width 1 to reach the target running total of 5 (1+3+1).
function lookupByPositionIndex(i)
node ← head
i ← i + 1 # don't count the head as a step
for level from top to bottom do
while i ≥ node.width[level] do # if next step is not too far
i ← i - node.width[level] # subtract the current width
node ← node.next[level] # traverse forward at the current level
repeat
repeat
return node.value
end function
This method of implementing indexing is detailed in Section 3.4 Linear List Operations in "A skip list cookbook" by William Pugh.
History
Skip lists were first described in 1990 by William Pugh.[2]
To quote the author:
- Skip lists are a probabilistic data structure that seem likely to supplant balanced trees as the implementation method of choice for many applications. Skip list algorithms have the same asymptotic expected time bounds as balanced trees and are simpler, faster and use less space.
Usages
List of applications and frameworks that use skip lists:
- Cyrus IMAP server offers a "skiplist" backend DB implementation (source file)
- Lucene uses skip lists to search delta-encoded posting lists in logarithmic time.
- QMap (up to Qt 4) template class of Qt that provides a dictionary.
- Redis, an ANSI-C open-source persistent key/value store for Posix systems, uses skip lists in its implementation of ordered sets.[6]
- nessDB, a very fast key-value embedded Database Storage Engine (Using log-structured-merge (LSM) trees), uses skip lists for its memtable.
- skipdb is an open-source database format using ordered key/value pairs.
- ConcurrentSkipListSet and ConcurrentSkipListMap in the Java 1.6 API.
- leveldb, a fast key-value storage library written at Google that provides an ordered mapping from string keys to string values
- Skip lists are used for efficient statistical computations of running medians (also known as moving medians).
Skip lists are also used in distributed applications (where the nodes represent physical computers, and pointers represent network connections) and for implementing highly scalable concurrent priority queues with less lock contention,[7] or even without locking,[8][9][10] as well lockless concurrent dictionaries.[11] There are also several US patents for using skip lists to implement (lockless) priority queues and concurrent dictionaries.[citation needed]
See also
- Bloom filter
- Skip graph
- Skip trees, an alternative data structure to Skip lists in a concurrent approach: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.47.514
- Skip tree graphs: http://www0.cs.ucl.ac.uk/staff/a.gonzalezbeltran/pubs/icc2007.pdf, http://www0.cs.ucl.ac.uk/staff/a.gonzalezbeltran/pubs/AGB-comcom08.pdf
References
- ^ Jump up to:a b http://www.cs.uwaterloo.ca/research/tr/1993/28/root2side.pdf
- ^ Jump up to:a b Pugh, W. (1990). "Skip lists: A probabilistic alternative to balanced trees". Communications of the ACM 33 (6): 668. doi:10.1145/78973.78977. edit
- Jump up^ Deterministic skip lists
- Jump up^ Shah, Gauri Ph.D.; James Aspnes (December 2003). Distributed Data Structures for Peer-to-Peer Systems (PDF). Retrieved 2008-09-23.
- Jump up^ http://resnet.uoregon.edu/~gurney_j/jmpc/skiplist.html
- Jump up^ "Redis ordered set implementation".
- Jump up^ Shavit, N.; Lotan, I. (2000). "Skiplist-based concurrent priority queues". Proceedings 14th International Parallel and Distributed Processing Symposium. IPDPS 2000. p. 263.doi:10.1109/IPDPS.2000.845994. ISBN 0-7695-0574-0. edit
- Jump up^ Sundell, H.; Tsigas, P. (2003). "Fast and lock-free concurrent priority queues for multi-thread systems". Proceedings International Parallel and Distributed Processing Symposium. p. 11. doi:10.1109/IPDPS.2003.1213189. ISBN 0-7695-1926-1. edit
- Jump up^ Fomitchev, M.; Ruppert, E. (2004). "Lock-free linked lists and skip lists". Proceedings of the twenty-third annual ACM symposium on Principles of distributed computing - PODC '04. p. 50. doi:10.1145/1011767.1011776. ISBN 1581138024. edit
- Jump up^ Bajpai, R.; Dhara, K. K.; Krishnaswamy, V. (2008). "QPID: A Distributed Priority Queue with Item Locality". 2008 IEEE International Symposium on Parallel and Distributed Processing with Applications. p. 215. doi:10.1109/ISPA.2008.90. ISBN 978-0-7695-3471-8. edit
- Jump up^ Sundell, H. K.; Tsigas, P. (2004). "Scalable and lock-free concurrent dictionaries". Proceedings of the 2004 ACM symposium on Applied computing - SAC '04. p. 1438.doi:10.1145/967900.968188. ISBN 1581138121. edit
External links
- "Skip list" entry in the Dictionary of Algorithms and Data Structures
- Skip Lists: A Linked List with Self-Balancing BST-Like Properties on MSDN in C# 2.0
- SkipDB, a BerkeleyDB-style database implemented using skip lists.
- Skip Lists lecture (MIT OpenCourseWare: Introduction to Algorithms)
- Open Data Structures - Chapter 4 - Skiplists
- Demo applets
- Skip List Applet by Kubo Kovac
- Thomas Wenger's demo applet on skiplists
- Implementations
- A generic Skip List in C++ by Antonio Gulli
- Algorithm::SkipList, implementation in Perl on CPAN
- John Shipman's implementation in Python
- Raymond Hettinger's implementation in Python
- A Lua port of John Shipman's Python version
- Java Implementation with index based access
- ConcurrentSkipListSet documentation for Java 6 (and sourcecode)
Skip list--reference wiki的更多相关文章
- Red–black tree ---reference wiki
source address:http://en.wikipedia.org/wiki/Red%E2%80%93black_tree A red–black tree is a type of sel ...
- lua weak table 概念解析
lua weak table 经常看到lua表中有 weak table的用法, 例如: weak_table = setmetatable({}, {__mode="v"}) 官 ...
- Hash Map (Hash Table)
Reference: Wiki PrincetonAlgorithm What is Hash Table Hash table (hash map) is a data structure use ...
- I/O exception (java.net.SocketException) caught when processing request: Connect
Exception [一个故障引发的话题] 最近,项目中的短信模块收到一个故障日志,要求我协助调查一下: 2010-05-07 09:22:07,221 [?:?] INFO httpclient. ...
- 一些日常工具集合(C++代码片段)
一些日常工具集合(C++代码片段) ——工欲善其事,必先利其器 尽管不会松松松,但是至少维持一个比较小的常数还是比较好的 在此之前依然要保证算法的正确性以及代码的可写性 本文依然会持久更新,因为一次写 ...
- Visual Studio 2019 for Mac 离线更新方法
当你打开Visual Studio 2019 for Mac检查更新时,如果下载更新包很慢,可以尝试如下操作: 打开Finder(访达),找到~/Library/Caches/VisualStudio ...
- Torrent文件的解析与转换
Torrent简介 BitTorrent协议的种子文件(英语:Torrent file)可以保存一组文件的元数据.这种格式的文件被BitTorrent协议所定义.扩展名一般为".torren ...
- Implementing the skip list data structure in java --reference
reference:http://www.mathcs.emory.edu/~cheung/Courses/323/Syllabus/Map/skip-list-impl.html The link ...
- snakeyaml - Documentation.wiki
SnakeYAML Documentation This documentation is very brief and incomplete. Feel free to fix or improve ...
随机推荐
- Watermarking 3D Polygonal Meshes in the Mesh Spectral Domain
这周看了一篇Ryutarou Ohbuchi网格水印的论文,论文中提出在网格的频率域中加入水印.对于网格而言,没有如图像中的DCT等转换到频率域的变换,因此用什么量来模拟传统频率域中的系数,是很关键的 ...
- OpenGL学习——基本概念和坐标变换
基本概念 基本功能:几何图形.变换.着色.光照.贴图 高级功能:曲面图元.光栅操作.景深.shader编程 状态机 先设置状态参数:多边形.顶点列表.填充颜色.纹理.混合模式.坐标系 再调用绘图指 ...
- RabbitMQ (四) 路由选择 (Routing) -摘自网络
本篇博客我们准备给日志系统添加新的特性,让日志接收者能够订阅部分消息.例如,我们可以仅仅将致命的错误写入日志文件,然而仍然在控制面板上打印出所有的其他类型的日志消息. 1.绑定(Bindings) 在 ...
- 第二百八十五天 how can I 坚持
今天好平凡啊. 晚上给徐斌打电话说忘带钥匙了,一块吃了个饭. 回到家,什么都不想做,好消沉. 玩了几局象棋,很多东西只是玩玩,但还是会认真,认真就会输,好惨. 最近在关注万科幸福里,可是.首付付不起啊 ...
- 最近的bug列表总结(C++)
最近写了一大段代码,抽象得厉害,容易绕进去,因为写单测的代价很大(借口),所以很多问题到联调的是否才发现. 而且花费了很大的经历才查出来,主要问题有如下几个问题 1. 变量未初始化 具体来说,就是指针 ...
- Xcode 的正确打开方式——Debugging
程序员日常开发中有大量时间都会花费在 debug 上,从事 iOS 开发不可避免地需要使用 Xcode.这篇博客就主要介绍了 Xcode 中几种能够大幅提升代码调试效率的方式. “If debuggi ...
- HDU 3072 Intelligence System (强连通分量)
Intelligence System Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Othe ...
- [C语言 - 10] C语言保留字
一 数据类型关键字 12 个: 1 . char 2 . short 3 . int 4 . long 5. enum 6. float 7. dou ...
- 文件频繁IO能有多大的差别
测试文件写同样大小的文件,单次记录较小和单次记录较大能有多大的性能差别. 最终写入同样大小的文件,小记录需要写入10w次,大记录需要写入1w次,看下最终的性能报告
- [ALGO-3] K好数
算法训练 K好数 时间限制:1.0s 内存限制:256.0MB 问题描写叙述 假设一个自然数N的K进制表示中随意的相邻的两位都不是相邻的数字,那么我们就说这个数是K好数.求L位K进制数中K好数 ...