搞懂MySQL分区
一.InnoDB逻辑存储结构
首先要先介绍一下InnoDB逻辑存储结构和区的概念,它的所有数据都被逻辑地存放在表空间,表空间又由段,区,页组成。
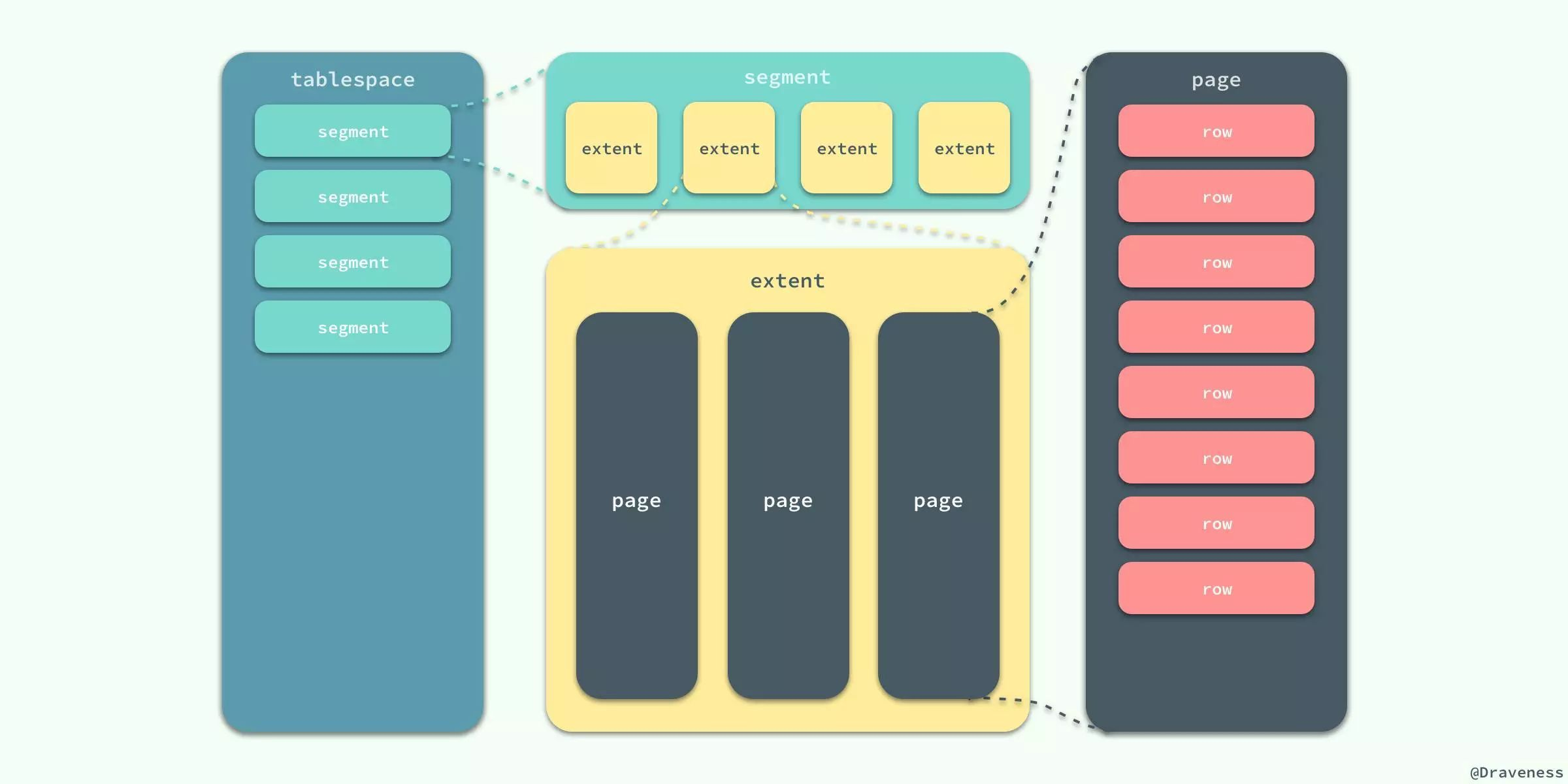
段
段就是上图的segment区域,常见的段有数据段、索引段、回滚段等,在InnoDB存储引擎中,对段的管理都是由引擎自身所完成的。
区
区就是上图的extent区域,区是由连续的页组成的空间,无论页的大小怎么变,区的大小默认总是为1MB。为了保证区中的页的连续性,InnoDB存储引擎一次从磁盘申请4-5个区,InnoDB页的大小默认为16kb,即一个区一共有64(1MB/16kb=16)个连续的页。每个段开始,先用32页(page)大小的碎片页来存放数据,在使用完这些页之后才是64个连续页的申请。这样做的目的是,对于一些小表或者是undo类的段,可以开始申请较小的空间,节约磁盘开销。
页
页就是上图的page区域,也可以叫块。页是InnoDB磁盘管理的最小单位。默认大小为16KB,可以通过参数innodb_page_size来设置。常见的页类型有:数据页,undo页,系统页,事务数据页,插入缓冲位图页,插入缓冲空闲列表页,未压缩的二进制大对象页,压缩的二进制大对象页等。
二.分区概述
分区
这里讲的分区,此“区”非彼“区”,这里讲的分区的意思是指将同一表中不同行的记录分配到不同的物理文件中,几个分区就有几个.idb文件,不是我们刚刚说的区。MySQL在5.1时添加了对水平分区的支持。分区是将一个表或索引分解成多个更小,更可管理的部分。每个区都是独立的,可以独立处理,也可以作为一个更大对象的一部分进行处理。这个是MySQL支持的功能,业务代码无需改动。要知道MySQL是面向OLTP的数据,它不像TIDB等其他DB。那么对于分区的使用应该非常小心,如果不清楚如何使用分区可能会对性能产生负面的影响。
MySQL数据库的分区是局部分区索引,一个分区中既存了数据,又放了索引。也就是说,每个区的聚集索引和非聚集索引都放在各自区的(不同的物理文件)。目前MySQL数据库还不支持全局分区。
无论哪种类型的分区,如果表中存在主键或唯一索引时,分区列必须是唯一索引的一个组成部分。
三.分区类型
目前MySQL支持一下几种类型的分区,RANGE分区,LIST分区,HASH分区,KEY分区。如果表存在主键或者唯一索引时,分区列必须是唯一索引的一个组成部分。实战十有八九都是用RANGE分区。
RANGE分区
RANGE分区是实战最常用的一种分区类型,行数据基于属于一个给定的连续区间的列值被放入分区。但是记住,当插入的数据不在一个分区中定义的值的时候,会抛异常。RANGE分区主要用于日期列的分区,比如交易表啊,销售表啊等。可以根据年月来存放数据。如果你分区走的唯一索引中date类型的数据,那么注意了,优化器只能对YEAR(),TO_DAYS(),TO_SECONDS(),UNIX_TIMESTAMP()这类函数进行优化选择。实战中可以用int类型,那么只用存yyyyMM就好了。也不用关心函数了。
CREATE TABLE `m_test_db`.`Order` (
`id` INT NOT NULL AUTO_INCREMENT,
`partition_key` INT NOT NULL,
`amt` DECIMAL(5) NULL,
PRIMARY KEY (`id`, `partition_key`)) PARTITION BY RANGE(partition_key) PARTITIONS 5( PARTITION part0 VALUES LESS THAN (201901), PARTITION part1 VALUES LESS THAN (201902), PARTITION part2 VALUES LESS THAN (201903), PARTITION part3 VALUES LESS THAN (201904), PARTITION part4 VALUES LESS THAN (201905)) ;
这时候我们先插入一些数据
INSERT INTO `m_test_db`.`Order` (`id`, `partition_key`, `amt`) VALUES ('', '', '');
INSERT INTO `m_test_db`.`Order` (`id`, `partition_key`, `amt`) VALUES ('', '', '');
INSERT INTO `m_test_db`.`Order` (`id`, `partition_key`, `amt`) VALUES ('', '', '');
现在我们查询一下,通过EXPLAIN PARTITION命令发现SQL优化器只需搜对应的区,不会搜索所有分区
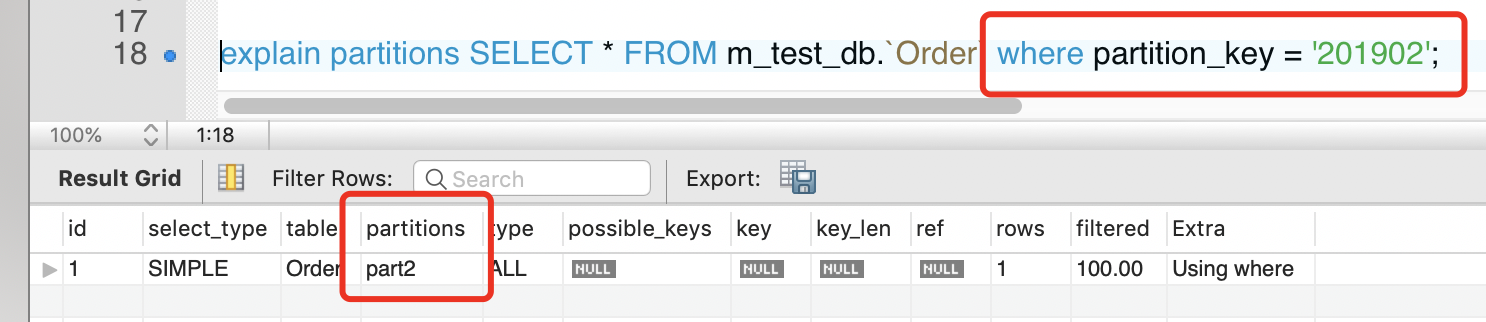
如果sql语句有问题,那么会走所有区。会很危险。所以分区表后,select语句必须走分区键。
以下3种不是太常用,就一笔带过了。
LIST分区
LIST分区和RANGE分区很相似,只是分区列的值是离散的,不是连续的。LIST分区使用VALUES IN,因为每个分区的值是离散的,因此只能定义值。
HASH分区
说到哈希,那么目的很明显了,将数据均匀的分布到预先定义的各个分区中,保证每个分区的数量大致相同。
KEY分区
KEY分区和HASH分区相似,不同之处在于HASH分区使用用户定义的函数进行分区,KEY分区使用数据库提供的函数进行分区。
四.分区和性能
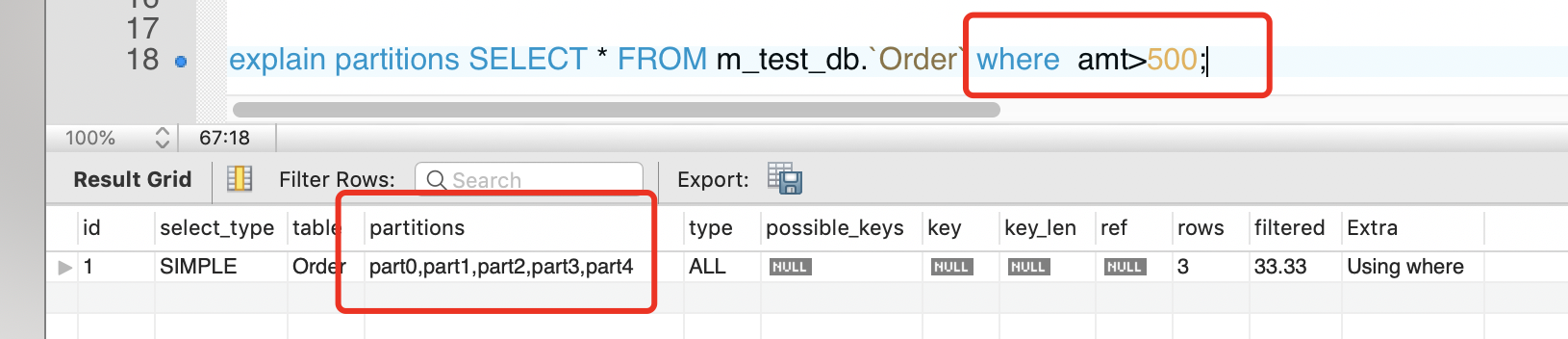
一项技术,不是用了就一定带来益处。比如显式锁功能比内置锁强大,你没玩好可能导致很不好的情况。分区也是一样,不是启动了分区数据库就会运行的更快,分区可能会给某些sql语句性能提高,但是分区主要用于数据库高可用性的管理。数据库应用分为2类,一类是OLTP(在线事务处理),一类是OLAP(在线分析处理)。对于OLAP应用分区的确可以很好的提高查询性能,因为一般分析都需要返回大量的数据,如果按时间分区,比如一个月用户行为等数据,则只需扫描响应的分区即可。在OLTP应用中,分区更加要小心,通常不会获取一张大表的10%的数据,大部分是通过索引返回几条数据即可。
比如一张表1000w数据量,如果一句select语句走辅助索引,但是没有走分区键。那么结果会很尴尬。如果1000w的B+树的高度是3,现在有10个分区。那么不是要(3+3)*10次的逻辑IO?(3次聚集索引,3次辅助索引,10个分区)。所以在OLTP应用中请小心使用分区表。
在日常开发中,如果想查看sql语句的分区查询结果可以使用explain partitions + select sql来获取,partitions标识走了哪几个分区。
mysql> explain partitions select * from TxnList where startTime>'2016-08-25 00:00:00' and startTime<'2016-08-25 23:59:00';
+----+-------------+-------------------+------------+------+---------------+------+---------+------+-------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------------------+------------+------+---------------+------+---------+------+-------+-------------+
| 1 | SIMPLE | ClientActionTrack | p20160825 | ALL | NULL | NULL | NULL | NULL | 33868 | Using where |
+----+-------------+-------------------+------------+------+---------------+------+---------+------+-------+-------------+
1 row in set (0.00 sec)
参考:
《MySQL技术内幕》
第一张图是从哪里偷来的忘记了- -!
搞懂MySQL分区的更多相关文章
- 一文彻底搞懂MySQL分区
一个执着于技术的公众号 一.InnoDB逻辑存储结构 首先要先介绍一下InnoDB逻辑存储结构和区的概念,它的所有数据都被逻辑地存放在表空间,表空间又由段,区,页组成. 段 段就是上图的segment ...
- 彻底搞懂MySQL为什么要使用B+树索引
目录 MySQL的存储结构 表存储结构 B+树索引结构 B+树页节点结构 为什么要用B+树索引 二叉树 多叉树 B树 B+树 搞懂这个问题之前,我们首先来看一下,MySQL表的存储结构 MySQL的存 ...
- 一本彻底搞懂MySQL索引优化EXPLAIN百科全书
1.MySQL逻辑架构 日常在CURD的过程中,都避免不了跟数据库打交道,大多数业务都离不开数据库表的设计和SQL的编写,那如何让你编写的SQL语句性能更优呢? 先来整体看下MySQL逻辑架构图: M ...
- 搞懂MySQL InnoDB B+树索引
一.InnoDB索引 InnoDB支持以下几种索引: B+树索引 全文索引 哈希索引 本文将着重介绍B+树索引.其他两个全文索引和哈希索引只是做简单介绍一笔带过. 哈希索引是自适应的,也就是说这个不能 ...
- 搞懂MySQL GTID原理
从MySQL 5.6.5 开始新增了一种基于 GTID 的复制方式.通过 GTID 保证了每个在主库上提交的事务在集群中有一个唯一的ID.这种方式强化了数据库的主备一致性,故障恢复以及容错能力. GT ...
- 五分钟搞懂MySQL索引下推
大家好,我是老三,今天分享一个小知识点--索引下推. 如果你在面试中,听到MySQL5.6"."索引优化" 之类的词语,你就要立马get到,这个问的是"索引下推 ...
- 一文搞懂│mysql 中的备份恢复、分区分表、主从复制、读写分离
目录 mysql 的备份和恢复 mysql 的分区分表 mysql 的主从复制读写分离 mysql 的备份和恢复 创建备份管理员 创建备份管理员,并授予管理员相应的权限 备份所需权限:select,r ...
- 一文搞懂mysql索引底层逻辑,干货满满!
一.什么是索引 在mysql中,索引是一种特殊的数据库结构,由数据表中的一列或多列组合而成,可以用来快速查询数据表中有某一特定值的记录.通过索引,查询数据时不用读完记录的所有信息,而只是查询索引列即可 ...
- 搞懂MySQL InnoDB事务ACID实现原理
前言 说到数据库事务,想到的就是要么都做修改,要么都不做.或者是ACID的概念.其实事务的本质就是锁和并发和重做日志的结合体.那么,这一篇主要讲一下InnoDB中的事务到底是如何实现ACID的. 原子 ...
随机推荐
- 分布式缓存技术redis学习系列
分布式缓存技术redis学习系列(一)--redis简介以及linux上的安装以及操作redis问题整理 分布式缓存技术redis学习系列(二)--详细讲解redis数据结构(内存模型)以及常用命令 ...
- 对图片进行索引,存入数据库sqlite3中,实现快速搜索打开
对图片进行索引,存入数据库中,实现快速搜索打开 这个任务分为两步: 第一步:建立索引 import os import shutil import sqlite3 # 扫描函数,需扫描路径目录处 ...
- The following untracked working tree files would be overwritten by merge
git pull的时候遇到这样的问题: The following untracked working tree files would be overwritten by merge balabal ...
- [译] PEP 255--简单的生成器
我正打算写写 Python 的生成器,然而查资料时发现,引入生成器的 PEP 没人翻译过,因此就花了点时间翻译出来.如果在阅读时,你有读不懂的地方,不用怀疑,极有可能是我译得不到位.若出现这种情况,我 ...
- 为什么需要Docker?
前言 只有光头才能变强. 文本已收录至我的GitHub仓库,欢迎Star:https://github.com/ZhongFuCheng3y/3y 估计大家也可能听过Docker这项技术(在论坛上.招 ...
- BugkuCTF~Mobile~WriteUp
最近,开始记录一篇关于 Android 逆向分析的 WriteUp 方便有需要的人学习,也欢迎大家相互交流, 发现不 一样的世界. 一. signin 考点:反编译.静态分析 Topic Link:h ...
- C# 创建含多层分类标签的Excel图表
相较于数据,图表更能直观的体现数据的变化趋势.在数据表格中,同一数据值,可能同时代表不同的数据分类,表现在图表中则是一个数据体现在多个数据分类标签下.通常生成的图表一般默认只有一种分类标签,下面的方法 ...
- vue3+typescript引入外部文件
vue3+typescript中引入外部文件有几种方法 (eg:引入echarts) 第一种方法: 1 indext.html中用script引入 <div id="app" ...
- SuperMap iObject入门开发系列之五管线属性查询
本文是一位好友“托马斯”授权给我来发表的,介绍都是他的研究成果,在此,非常感谢. 管线属性查询功能针对单一管线图层进行特定的条件查询,然后将查询结果输出为列表,并添加点位闪烁功能,例如查询污水管线中, ...
- react native中使用echarts
开发平台:mac pro node版本:v8.11.2 npm版本:6.4.1 react-native版本:0.57.8 native-echarts版本:^0.5.0 目标平台:android端收 ...