pyquery 学习
pyquery 是python仿照jQuery的严格实现,语法与jQuery几乎完全相同,所以对于学过前端的朋友们可以立马上手,没学过的小朋友也别灰心,我们马上就能了解到pyquery的强大.
1 安装
pip install pyquery
2 官方文档
http://pyquery.readthedocs.io/
3 学习代码html代码
html = '''
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
4 字符串初始化
html = '''
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
# 格式化html文本,获取'$对象
doc=pq(html) # doc ---> '$'
#获取html文本下所有的li标签
print(doc('li'))
结果

5 URL初始化
from pyquery import PyQuery as pq
#直接获取网页源码
doc=pq(url='https://www.baidu.com')
title=doc(':submit').attr.value
print(title)
结果

6 文件初始化
from pyquery import PyQuery as pq
#读取文件
doc = pq(filename='demo.html')
print(doc('li'))
结果

7 基于css选择器
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
#找id=container标签下 所有class=list标签下的 所有的li标签
print(doc('#container .list li'))
结果

8 查找元素
子元素(不找孙子)
(链式寻找,doc($)找到的标签对象可以继续查找)
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
#先获取所有的class=list 标签
items = doc('.list')
#再获取所有的li标签
lis=items('li')
print(lis)
结果

#获取当前标签的所有子标签
lis=items.children()
print(type(lis))
print(lis)
结果

父元素(不找爷爷)
html = '''
<html>
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</html>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
#获取当前标签的父级别标签(不取爷爷标签)
container = items.parent()
print(type(container))
print(container)
结果

9 遍历
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
#寻找class=items-0并且class=active的标签
li = doc('.item-0.active')
print(li)
结果

10 获取文本
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">我们一起high high</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
#定位到 a标签
a = doc('.item-0.active a')
print(a)
#输出文本使用.text()
print(a.text())
结果
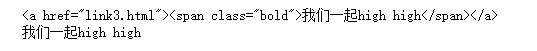
11 获取HTML
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
#获取对应 标签下的 html数据
print(li.html())
结果

12 DOM操作
addClass、removeClass
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
#给选定标签删除 class='active'
li.removeClass('active')
print(li)
#给选定标签添加 class='active'
li.addClass('active')
print(li)
结果

attr、css
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
#添加属性 name=link
li.attr('name', 'link')
print(li)
#添加css font-size=14px
li.css('font-size', '14px')
print(li)
结果

remove
html = '''
<div class="wrap">
Hello, World
<p>This is a paragraph.</p>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
wrap = doc('.wrap')
print(wrap.text())
#find 找到指定标签,remove 移除
wrap.find('p').remove()
print(wrap.text())
结果
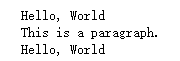
其他DOM方法
13 伪类选择器
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
# 获取第一个li 标签
li = doc('li:first-child')
print(li)
#获取最后一个li 标签
li = doc('li:last-child')
print(li)
#获取第2个li 标签
li = doc('li:nth-child(2)')
print(li)
#获取索引>2 的li 标签
li = doc('li:gt(2)')
print(li)
#获取偶数 的li标签
li = doc('li:nth-child(2n)')
print(li)
#获取文本包含second的 li标签
li = doc('li:contains(second)')
print(li)
结果

更多CSS选择器可以查看 http://www.w3school.com.cn/css/index.asp
pyquery 学习的更多相关文章
- python爬虫之pyquery学习
相关内容: pyquery的介绍 pyquery的使用 安装模块 导入模块 解析对象初始化 css选择器 在选定元素之后的元素再选取 元素的文本.属性等内容的获取 pyquery执行DOM操作.css ...
- pyquery学习笔记
很早就听说了pyquery的强大.写了个简单的测试程序实验下. 思路是找个动态网页,先用PhantomJS加载,然后用PYQUERY解析. 1.随便找了个带表格的股票网页,里面有大量的股票数据,测试的 ...
- python之pyquery 学习
pyquery是jQuery的Python实现,可以用以解析HTML网页的内容.官网文档:http://pythonhosted.org/pyquery/ 下载:https://pypi.python ...
- 学习PyQuery库
学习PyQuery库 好了,又是学习的时光啦,今天学习pyquery 来进行网页解析 常规导入模块(PyQuery库中的pyquery类) from pyquery import PyQuery as ...
- 学习使用pyquery解析器爬小说
一.背景:个人喜欢在网上看小说,但是,在浏览器中阅读小说不是很方便,喜欢找到小说的txt版下载到手机上阅读,但是有些小说不太好找txt版本,考虑自己从网页上爬一爬,自己搞定小说的txt版本.正好学习一 ...
- 爬虫学习笔记(六)PyQuery模块
PyQuery模块也是一个解析html的一个模块,它和Beautiful Soup用起来差不多,它是jquery实现的,和jquery语法差不多,会用jquery的人用起来就比较方便了. Pyquer ...
- python爬虫神器PyQuery的使用方法
你是否觉得 XPath 的用法多少有点晦涩难记呢? 你是否觉得 BeautifulSoup 的语法多少有些悭吝难懂呢? 你是否甚至还在苦苦研究正则表达式却因为少些了一个点而抓狂呢? 你是否已经有了一些 ...
- Pyquery API中文版
Pyquery的用法与jQuery相同,可以直接参考jQuery API学习.
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
随机推荐
- struct和union的区别
1)union是几个不同类型的变量共占一段内存(相互覆盖):struct是把不同类型的数据组合成一个整体 2)对齐方式略有区别:union不需要+,只需要拿出对齐后的最长 structure unio ...
- 关于java集合类HashMap的理解
一.HashMap概述 HashMap基于哈希表的 Map 接口的实现.此实现提供所有可选的映射操作,并允许使用 null 值和 null 键.(除了不同步和允许使用 null 之外,HashMap ...
- Java 面试知识点解析(四)——版本特性篇
前言: 在遨游了一番 Java Web 的世界之后,发现了自己的一些缺失,所以就着一篇深度好文:知名互联网公司校招 Java 开发岗面试知识点解析 ,来好好的对 Java 知识点进行复习和学习一番,大 ...
- jQuery-01:on live bind delegate
摘自:https://www.cnblogs.com/moonreplace/archive/2012/10/09/2717136.html moonreplace这位大牛的 当我们试图绑定一些事件到 ...
- Spring MVC温故而知新-从零开始
Spring MVC简介 Spring MVC是一款基于MVC架构模式的轻量级Web框架,目的是将Web开发模块化,对整体架构进行解耦. Spring MVC有一下优点: 作为Spring框架的一部分 ...
- SOA专题---Dropwizard与Spring Boot比较
在这篇文章中我们将讨论的Java轻量级框架Dropwizard和Spring Boot的相似性和差异. 首先,这是一个选择自由和速度需要,无论你在Dropwizard和Spring Boot选择哪个, ...
- Deep Learning Enables You to Hide Screen when Your Boss is Approaching
https://github.com/Hironsan/BossSensor/ 背景介绍 学生时代,老师站在窗外的阴影挥之不去.大家在玩手机,看漫画,看小说的时候,总是会找同桌帮忙看着班主任有没有来. ...
- Spring-cloud (九) Hystrix请求合并的使用
前言: 承接上一篇文章,两文本来可以一起写的,但是发现RestTemplate使用普通的调用返回包装类型会出现一些问题,也正是这个问题,两文没有合成一文,本文篇幅不会太长,会说一下使用和适应的场景. ...
- Java 学习笔记 (四) Java 语句优化
这个问题是从headfirst java看到的. 需求: 一个移动电话用的java通讯簿管理系统,要求最有效率的内存使用方法. 下面两段程序的优缺点,哪个占用内存更少. 第一段: Contact[]c ...
- 【bzoj 4407】于神之怒加强版
Description 给下N,M,K.求 Input 输入有多组数据,输入数据的第一行两个正整数T,K,代表有T组数据,K的意义如上所示,下面第二行到第T+1行,每行为两个正整数N,M,其意 ...