python 初级1
List:Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
构造list非常简单,按照上面的代码,直接用 [ ] 把list的所有元素都括起来,就是一个list对象。通常,我们会把list赋值给一个变量,这样,就可以通过变量来引用list
由于Python是动态语言,所以list中包含的元素并不要求都必须是同一种数据类型,我们完全可以在list中包含各种数据
倒数:倒数第二用 -2 表示,倒数第三用 -3 表示,倒数第四用 -4 表示:
List的增删:list 的 append() 方法,把新元素追加到 list 的末尾
方法是用list的 insert()方法,它接受两个参数,第一个参数是索引号,第二个参数是待添加的新元素
可以用list的pop()方法删除最后一个元素;{pop()删除为依次删除,不能出现如pop(2),pop(3)这种
自动生成列表:
生成[1x1, 2x2, 3x3, ..., 10x10]
>>> L = [] >>> for x in range(1, 11): ... L.append(x * x) ... >>> L [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
但是循环太繁琐,而列表生成式则可以用一行语句代替循环生成上面的list:
>>> [x * x for x in range(1, 11)] [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
列表生成式的 for 循环后面还可以加上 if 判断。例如:
>>> [x * x for x in range(1, 11)] [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
如果我们只想要偶数的平方,不改动 range()的情况下,可以加上 if 来筛选:
>>> [x * x for x in range(1, 11) if x % 2 == 0] [4, 16, 36, 64, 100]
有了 if 条件,只有 if 判断为 True 的时候,才把循环的当前元素添加到列表中。
任务
请编写一个函数,它接受一个 list,然后把list中的所有字符串变成大写后返回,非字符串元素将被忽略。
提示:
1. isinstance(x, str) 可以判断变量 x 是否是字符串;
2. 字符串的 upper() 方法可以返回大写的字母。
def toUppers(L):
return [x.upper() for x in L if isinstance(x, str)]
print toUppers(['Hello', 'world', 101])
多层表达式:
for循环可以嵌套,因此,在列表生成式中,也可以用多层 for 循环来生成列表。
对于字符串 'ABC' 和 '123',可以使用两层循环,生成全排列:
>>> [m + n for m in 'ABC' for n in '123'] ['A1', 'A2', 'A3', 'B1', 'B2', 'B3', 'C1', 'C2', 'C3']
翻译成循环代码就像下面这样:
L = []
for m in 'ABC':
for n in '123':
L.append(m + n)
tuple:tuple是另一种有序的列表,中文翻译为“ 元组 ”。tuple 和 list 非常类似,但是,tuple一旦创建完毕,就不能修改了,创建tuple和创建list唯一不同之处是用( )替代了[ ],获取 tuple 元素的方式和 list 是一模一样的,我们可以正常使用 t[0],t[-1]等索引方式访问元素,
但是不能赋值成别的元素.()既可以表示tuple,又可以作为括号表示运算时的优先级,结果 (1) 被Python解释器计算出结果 1,导致我们得到的不是tuple,而是整数 1。正是因为用()定义单元素的tuple有歧义,所以 Python 规定,单元素 tuple 要多加一个逗号“,”,这样就避免了歧义
dict:dict={'key':value}:花括号 {} 表示这是一个dict可以简单地使用 d[key] 的形式来查找对应的 value,这和 list 很像,不同之处是,list 必须使用索引返回对应的元素,而dict使用key.
通过 key 访问 dict 的value,只要 key 存在,dict就返回对应的value。如果key不存在,会直接报错:KeyError。二是使用dict本身提供的一个 get 方法,在Key不存在的时候,返回None.
dict的第一个特点是查找速度快,无论dict有10个元素还是10万个元素,查找速度都一样。而list的查找速度随着元素增加而逐渐下降。
不过dict的查找速度快不是没有代价的,dict的缺点是占用内存大,还会浪费很多内容,list正好相反,占用内存小,但是查找速度慢。
由于dict是按 key 查找,所以,在一个dict中,key不能重复。
dict的第二个特点就是存储的key-value序对是没有顺序的!这和list不一样.不能用dict存储有序的集合。
dict 对象有一个 values() 方法,这个方法把dict转换成一个包含所有value的list,这样,我们迭代的就是 dict的每一个 value
d = { 'Adam': 95, 'Lisa': 85, 'Bart': 59 }
print d.values()
# [85, 95, 59]
for v in d.values():
print v
# 85
# 95
# 59
dict除了values()方法外,还有一个 itervalues() 方法,用 itervalues() 方法替代 values() 方法,迭代效果完全一样:
d = { 'Adam': 95, 'Lisa': 85, 'Bart': 59 }
print d.itervalues()
# <dictionary-valueiterator object at 0x106adbb50>
for v in d.itervalues():
print v
# 85
# 95
# 59
两方法不同之处:
1. values() 方法实际上把一个 dict 转换成了包含 value 的list。
2. 但是 itervalues() 方法不会转换,它会在迭代过程中依次从 dict 中取出 value,所以 itervalues() 方法比 values() 方法节省了生成 list 所需的内存。
3. 打印 itervalues() 发现它返回一个 <dictionary-valueiterator> 对象,这说明在Python中,for 循环可作用的迭代对象远不止 list,tuple,str,unicode,dict等,任何可迭代对象都可以作用于for循环,而内部如何迭代我们通常并不用关心。
如果一个对象说自己可迭代,那我们就直接用 for 循环去迭代它,可见,迭代是一种抽象的数据操作,它不对迭代对象内部的数据有任何要求。
dict 对象的 items() 方法返回的值
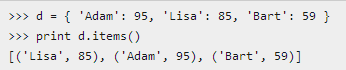
可以看到,items() 方法把dict对象转换成了包含tuple的list,我们对这个list进行迭代,可以同时获得key和value:
>>> for key, value in d.items(): ... print key, ':', value ... Lisa : 85 Adam : 95 Bart : 59
和 values() 有一个 itervalues() 类似, items() 也有一个对应的 iteritems(),iteritems() 不把dict转换成list,而是在迭代过程中不断给出 tuple,所以, iteritems() 不占用额外的内存
set:set 持有一系列元素,这一点和 list 很像,但是set的元素没有重复,而且是无序的,这点和 dict 的 key很像。
由于set存储的是无序集合,所以我们没法通过索引来访问。
访问 set中的某个元素实际上就是判断一个元素是否在set中。
添加元素时,用set的add()方法如果添加的元素已经存在于set中,add()不会报错,但是不会加进去了
删除set中的元素时,用set的remove()方法如果删除的元素不存在set中,remove()会报错,所以用add()可以直接添加,而remove()前需要判断
函数:要调用一个函数,需要知道函数的名称和参数,比如求绝对值的函数 abs,它接收一个参数也可以在交互式命令行通过 help(abs) 查看abs函数的帮助信息调用 函数的时候,如果传入的参数数量不对,会报TypeError的错误,并且Python会明确地告诉你如果传入的参数数量是对的,但参数类型不能被函数所接受,也会 报TypeError的错误
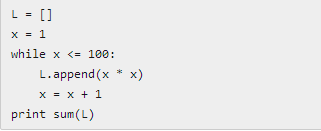
几个简单函数:比较函数 cmp(x, y) 如果 x<y,返回 -1,如果x==y,返回 0,如果 x>y,返回 1。 int()函数可以把其他数据类型转换为整数。str()函数把其他类型转换成 str类型。sum()函数接受一个list作为参数,并返回list所有元素之和
定义一个函数:定义一个函数要使用 def 语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用 return 语句返回
注意,函数体内部的语句在执行时,一旦执行到return时,函数就执行完毕,并将结果返回。因此,函数内部通过条件判断和循环可以实现非常复杂的逻辑。
如果没有return语句,函数执行完毕后也会返回结果,只是结果为 None。
return None可以简写为return
函数返回。
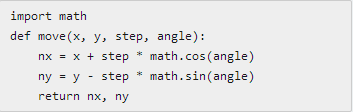
比如在游戏中经常需要从一个点移动到另一个点,给出坐标、位移和角度,就可以计算出新的坐标:
# math包提供了sin()和 cos()函数,用import引用它
range函数:
函数原型:range(start, end, scan):
参数含义:start:计数从start开始。默认是从0开始。例如range(5)等价于range(0, 5);
end:技术到end结束,但不包括end.例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
scan:每次跳跃的间距,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
递归函数:在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数
递归函数的优点是定义简单,逻辑清晰。理论上,所有的递归函数都可以写成循环的方式,但循环的逻辑不如递归清晰。
使用递归函数需要注意防止栈溢出。在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出
汉诺塔问题:
汉诺塔 (http://baike.baidu.com/view/191666.htm) 的移动也可以看做是递归函数。
我们对柱子编号为a, b, c,将所有圆盘从a移到c可以描述为:
如果a只有一个圆盘,可以直接移动到c;
如果a有N个圆盘,可以看成a有1个圆盘(底盘) + (N-1)个圆盘,首先需要把 (N-1) 个圆盘移动到 b,然后,将 a的最后一个圆盘移动到c,再将b的(N-1)个圆盘移动到c。
请编写一个函数,给定输入 n, a, b, c,打印出移动的步骤:
move(n, a, b, c)
例如,输入 move(2, 'A', 'B', 'C'),打印出:
A --> B
A --> C
B --> C

可变参数:
如果想让一个函数能接受任意个参数,我们就可以定义一个可变参数:

可变参数的名字前面有个 * 号,我们可以传入0个、1个或多个参数给可变参数:


切片(slice):L[a:b:c],a表示从哪里开始切(包含在内),b表示切到哪里(不包含在内),c表示隔几个切。
L[0:3]表示,从索引0开始取,直到索引3为止,但不包括索引3。即索引0,1,2,正好是3个元素。
如果第一个索引是0,还可以省略:

只用一个 : ,表示从头到尾:

切片操作还可以指定第三个参数:

第三个参数表示每N个取一个,上面的 L[::2] 会每两个元素取出一个来,也就是隔一个取一个。
迭代:
迭代操作就是对于一个集合,无论该集合是有序还是无序,我们用 for 循环总是可以依次取出集合的每一个元素。
注意: 集合是指包含一组元素的数据结构,我们已经介绍的包括: 1. 有序集合:list,tuple,str和unicode; 2. 无序集合:set 3. 无序集合并且具有 key-value 对:dict
迭代是一个动词,它指的是一种操作,在Python中,就是 for 循环。
索引迭代:
Python中,迭代永远是取出元素本身,而非元素的索引
对于有序集合,元素确实是有索引的。方法是使用 enumerate() 函数:
>>> L = ['Adam', 'Lisa', 'Bart', 'Paul'] >>> for index, name in enumerate(L): ... print index, '-', name ... 0 - Adam 1 - Lisa 2 - Bart 3 - Paul
使用 enumerate() 函数,我们可以在for循环中同时绑定索引index和元素name。但是,这不是 enumerate() 的特殊语法。实际上,enumerate() 函数把:
['Adam', 'Lisa', 'Bart', 'Paul']
变成了类似:
[(0, 'Adam'), (1, 'Lisa'), (2, 'Bart'), (3, 'Paul')]
因此,迭代的每一个元素实际上是一个tuple
索引迭代也不是真的按索引访问,而是由 enumerate() 函数自动把每个元素变成 (index, element) 这样的tuple,再迭代,就同时获得了索引和元素本身
zip()函数可以把两个 list 变成一个 list:
>>> zip([10, 20, 30], ['A', 'B', 'C']) [(10, 'A'), (20, 'B'), (30, 'C')]
任务
zip()函数可以把两个 list 变成一个 list:
>>> zip([10, 20, 30], ['A', 'B', 'C']) [(10, 'A'), (20, 'B'), (30, 'C')]
在迭代 ['Adam', 'Lisa', 'Bart', 'Paul'] 时,如果我们想打印出名次 - 名字(名次从1开始),请考虑如何在迭代中打印出来。
提示:考虑使用zip()函数和range()函数
L = ['Adam', 'Lisa', 'Bart', 'Paul']
for index, name in zip(range(1, len(L)+1), L):
print index, '-', name
python 初级1的更多相关文章
- Decorator——Python初级函数装饰器
最近想整一整数据分析,在看一本关于数据分析的书中提到了(1)if __name__ == '__main__' (2)列表解析式 (3)装饰器. 先简单描述一下前两点,再详细解说Python初级的函数 ...
- python初级装饰器编写
最近项目太忙好久没有学习python了,今天更新一下吧~~ 1.什么是python装饰器: 装饰器本质上是一个python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外的功能,装饰器的返 ...
- Python初级教程
Python语言的特点 优点: - 简单 - 易学 - 免费,开源 - 高层语言 - 可移植性(可再多平台运行) - 解释性(不需要编译,可直接运行) - 面向对象 - 可扩展性(缺点:运行效率相对较 ...
- python 初级重点
关于python初学时遇到的重点: 1 python 2 和3 的区别 python2**不识别中文** -*- coding: utf-8 -*-(因为不能识别中文,所以代码有中文时需要在最前面加入 ...
- python初级实战-----主机在线情况监控web
背景 公司有600多台服务器,打算写一个小程序,能一眼看见哪些服务器不在线. 大体思路是: 1.把所有服务器ip存进数据库,ping命令判断服务器是否在线 2.更新数据库中ip的状态 3.简单的web ...
- python初级实战-----关于邮件发送问题
python发邮件需要掌握两个模块的用法,smtplib和email,这俩模块是python自带的,只需import即可使用.smtplib模块主要负责发送邮件,email模块主要负责构造邮件. sm ...
- 程序媛计划——python初级课时3~5
产生1-10中的随机数: for 循环:所有可遍历对象都能用于for循环,如一个字符串. len(list),list中的元素类型可以各不相同:可以直接用下标对list元素赋值来更新列表 对字符串可以 ...
- 程序媛计划——python初级课时1~2
在命令行中运行py文件:python 文件路径/文件名 python变量必须赋值后才能使用,因为py变量只有赋值后才会被创建. py可以同时给多个变量赋值:a,b,c = 10,20,'dfjkdj' ...
- 【Python初级】由判定回文数想到的,关于深浅复制,以及字符串反转的问题
尝试用Python实现可以说是一个很经典的问题,判断回文数. 让我们再来看看回文数是怎么定义的: 回数是指从左向右读和从右向左读都是一样的数,例如1,121,909,666等 解决这个问题的思路,可以 ...
随机推荐
- highcharts 插件问题
Uncaught TypeError: $(...).highcharts is not a function 解决方法: $('#container').highcharts({ colors: [ ...
- scrollViewDidEndScrollingAnimation和scrollViewDidEndDecelerating的区别
#pragma mark - 监听 /** * 点击了顶部的标题按钮 */ - (void)titleClick:(XMGTitleButton *)titleButton { // 修 ...
- AFN和ASI区别
AFN和ASI区别 一.AFN和ASI的区别 1.底层实现1> AFN的底层基于OC的NSURLConnection和NSURLSession2> ASI的底层基于纯C语言的CFNetwo ...
- SpringMVC常用配置-处理程序异常以及404错误
- Spring操作指南-AOP基本示例(基于注解)
- [Android Tips] 22. Available Java 7 Features in Android
This only allows Java 7 language features, and you can hardly benefit from anything since a half of ...
- leetcode Super Pow
题目描述: superPow(int a, int[] b),b是一个int数组,每个元素都是正的个位数,组合起来表示一个正整数,例如b=[1,2,3]表示123,求解a^b mod 1337. 思路 ...
- 使用Maven构建Java Web项目时,关于jsp中引入js、css文件路径问题。
今天有点闲,自己动手搭建一个Java Web项目,遇到jsp中引入js.css文件时路径不正确的问题,于是在网上查阅了很多资料,最终都无法解决问题,于是,上stackoverflow找到了解决方法,这 ...
- 常用git命令总结
这些命令是最常用的,一般的提交代码.拉取代码.合并代码.分支切换等等操作用这些命令就足够了. 1.git init 把一个目录初始化成git仓库 2.git add test.txt 把文 ...
- 浅谈JSON.stringify 函数与toJosn函数和Json.parse函数
JSON.stringify 函数 (JavaScript) 语法:JSON.stringify(value [, replacer] [, space]) 将 JavaScript 值转换为 Jav ...