B树详解
B树
具体讲解之前,有一点,再次强调下:B-树,即为B树。因为B树的原英文名称为B-tree,而国内很多人喜欢把B-tree译作B-树,其实,这是个非常不好的直译,很容易让人产生误解。如人们可能会以为B-树是一种树,而B树又是一种一种树。而事实上是,B-tree就是指的B树。特此说明。
我们知道,B 树是为了磁盘或其它存储设备而设计的一种多叉(下面你会看到,相对于二叉,B树每个内结点有多个分支,即多叉)平衡查找树。与本blog之前介绍的红黑树很相似,但在降低磁盘I/0操作方面要更好一些。许多数据库系统都一般使用B树或者B树的各种变形结构,如下文即将要介绍的B+树,B*树来存储信息。
B树与红黑树最大的不同在于,B树的结点可以有许多子女,从几个到几千个。那为什么又说B树与红黑树很相似呢?因为与红黑树一样,一棵含n个结点的B树的高度也为O(lgn),但可能比一棵红黑树的高度小许多,应为它的分支因子比较大。所以,B树可以在O(logn)时间内,实现各种如插入(insert),删除(delete)等动态集合操作。
如下图所示,即是一棵B树,一棵关键字为英语中辅音字母的B树,现在要从树种查找字母R(包含n[x]个关键字的内结点x,x有n[x]+1]个子女(也就是说,一个内结点x若含有n[x]个关键字,那么x将含有n[x]+1个子女)。所有的叶结点都处于相同的深度,带阴影的结点为查找字母R时要检查的结点):
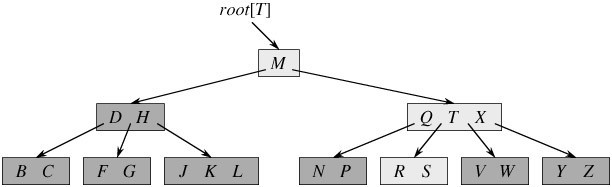
相信,从上图你能轻易的看到,一个内结点x若含有n[x]个关键字,那么x将含有n[x]+1个子女。如含有2个关键字D H的内结点有3个子女,而含有3个关键字Q T X的内结点有4个子女。
B 树又叫平衡多路查找树。一棵m阶的B 树 (m叉树)的特性如下:
- 树中每个结点最多含有m个孩子(m>=2);
- 除根结点和叶子结点外,其它每个结点至少有[ceil(m / 2)]个孩子(其中ceil(x)是一个取上限的函数);
- 若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点);
- 所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部接点或查询失败的接点,实际上这些结点不存在,指向这些结点的指针都为null);(读者反馈@冷岳:这里有错,叶子节点只是没有孩子和指向孩子的指针,这些节点也存在,也有元素。@JULY:其实,关键是把什么当做叶子结点,因为如红黑树中,每一个NULL指针即当做叶子结点,只是没画出来而已)。
- 每个非终端结点中包含有n个关键字信息: (n,P0,K1,P1,K2,P2,......,Kn,Pn)。其中:
a) Ki (i=1...n)为关键字,且关键字按顺序升序排序K(i-1)< Ki。
b) Pi为指向子树根的接点,且指针P(i-1)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
c) 关键字的个数n必须满足: [ceil(m / 2)-1]<= n <= m-1。如下图所示:

针对上面第5点,再阐述下:B树中每一个结点能包含的关键字(如之前上面的D H和Q T X)数有一个上界和下界。这个下界可以用一个称作B树的最小度数(算法导论中文版上译作度数,最小度数即内节点中节点最小孩子数目)t(t>=2)表示。
- 每个非根的结点必须至少含有t-1个关键字。每个非根的内结点至少有t个子女。如果树是非空的,则根结点至少包含一个关键字;
- 每个结点可包含之多2t-1个关键字。所以一个内结点至多可有2t个子女。如果一个结点恰好有2t-1个关键字,我们就说这个结点是满的(而稍后介绍的B*树作为B树的一种常用变形,B*树中要求每个内结点至少为2/3满,而不是像这里的B树所要求的至少半满);
- 当关键字数t=2(t=2的意思是,tmin=2,t可以>=2)时的B树是最简单的(有很多人会因此误认为B树就是二叉查找树,但二叉查找树就是二叉查找树,B树就是B树,B树的真正最准确的定义为:一棵含有t(t>=2)个关键字的平衡多路查找树)。每个内结点可能因此而含有2个、3个或4个子女,亦即一棵2-3-4树,然而在实际中,通常采用大得多的t值。
B树中的每个结点根据实际情况可以包含大量的关键字信息和分支(当然是不能超过磁盘块的大小,根据磁盘驱动(disk drives)的不同,一般块的大小在1k~4k左右);这样树的深度降低了,这就意味着查找一个元素只要很少结点从外存磁盘中读入内存,很快访问到要查找的数据。
B树的类型和节点定义如下图所示:

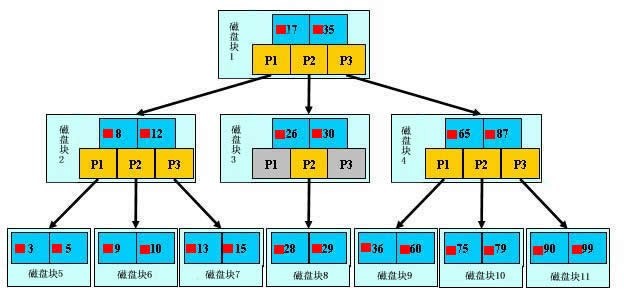
为了简单,这里用少量数据构造一棵3叉树的形式,实际应用中的B树结点中关键字很多的。上面的图中比如根结点,其中17比表示一个磁盘文件的文件名;小红方块表示这个17文件内容在硬盘中的存储位置;p1表示指向17左子树的指针。
其结构可以简单定义为:
typedef struct {
/*文件数*/
int file_num;
/*文件名(key)*/
char * file_name[max_file_num];
/*指向子节点的指针*/
BTNode * BTptr[max_file_num+1];
/*文件在硬盘中的存储位置*/
FILE_HARD_ADDR offset[max_file_num];
}BTNode;
假如每个盘块可以正好存放一个B树的结点(正好存放2个文件名)。那么一个BTNODE结点就代表一个盘块,而子树指针就是存放另外一个盘块的地址。
下面,咱们来模拟下查找文件29的过程:
- 根据根结点指针找到文件目录的根磁盘块1,将其中的信息导入内存。【磁盘IO操作 1次】
- 此时内存中有两个文件名17、35和三个存储其他磁盘页面地址的数据。根据算法我们发现17<29<35,因此我们找到指针p2。
- 根据p2指针,我们定位到磁盘块3,并将其中的信息导入内存。【磁盘IO操作 2次】
- 此时内存中有两个文件名26,30和三个存储其他磁盘页面地址的数据。根据算法我们发,26<29<30,因此我们找到指针p2。
- 根据p2指针,我们定位到磁盘块8,并将其中的信息导入内存。【磁盘IO操作 3次】
- 此时内存中有两个文件名28,29。根据算法我们查找到文,29,并定位了该文件内存的磁盘地址。
分析上面的过程,发现需要3次磁盘IO操作和3次内存查找操作。关于内存中的文件名查找,由于是一个有序表结构,可以利用折半查找提高效率。至于IO操作时影响整个B树查找效率的决定因素。
当然,如果我们使用平衡二叉树的磁盘存储结构来进行查找,磁盘4次,最多5次,而且文件越多,B树比平衡二叉树所用的磁盘IO操作次数将越少,效率也越高。
B树的高度
根据上面的例子我们可以看出,对于辅存做IO读的次数取决于B树的高度。而B树的高度由什么决定的呢?
根据B树的高度公式: 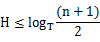
其中T为度数(每个节点包含的元素个数),即所谓的阶数,N为总元素个数或总关键字数。
我们可以看出T对于树的高度有决定性的影响。因此如果每个节点包含更多的元素个数,在元素个数相同的情况下,则更有可能减少B树的高度。这也是为什么SQL Server中需要尽量以窄键建立聚集索引。因为SQL Server中每个节点的大小为8092字节,如果减少键的大小,则可以容纳更多的元素,从而减少了B树的高度,提升了查询的性能。
上面B树高度的公式也可以进行推导得出,将每一层级的的元素个数加起来,比如度为T的节点,根为1个节点,第二层至少为2个节点,第三层至少为2t个节点,第四层至少为2t*t个节点。将所有最小节点相加,从而得到节点个数N的公式:
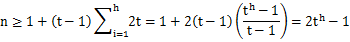
两边取对数,则可以得到树的高度公式。
这也就是说每个节点必须至少有两个子元素,因为根据高度公式,如果每个节点只有一个元素,也就是T=1的话,那么高度将会趋于正无穷。
4.B+-tree
B+-tree:是应文件系统所需而产生的一种B-tree的变形树。
一棵m阶的B+树和m阶的B树的差异在于:
1.有n棵子树的结点中含有n个关键字; (而B 树是n棵子树有n-1个关键字)
2.所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (而B 树的叶子节点并没有包括全部需要查找的信息)
3.所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息)
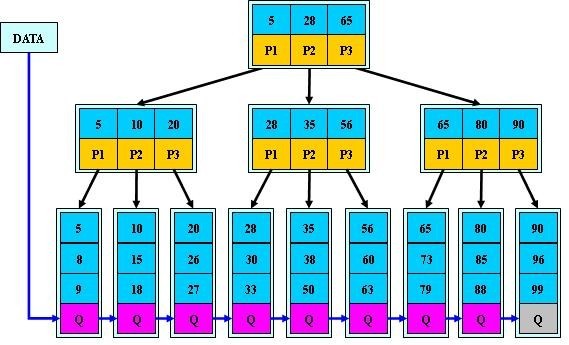
a) 为什么说B+-tree比B 树更适合实际应用中操作系统的文件索引和数据库索引?
1) B+-tree的磁盘读写代价更低
B+-tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而B+ 树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+ 树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
2) B+-tree的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
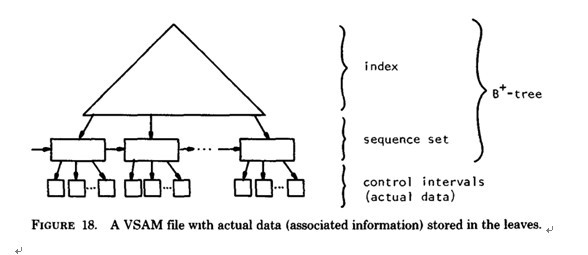
b) B+-tree的应用: VSAM(虚拟存储存取法)文件(来源论文 the ubiquitous Btree 作者:D COMER - 1979 )
5.B*-tree
B*-tree是B+-tree的变体,在B+ 树非根和非叶子结点再增加指向兄弟的指针;B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2)。给出了一个简单实例,如下图所示:
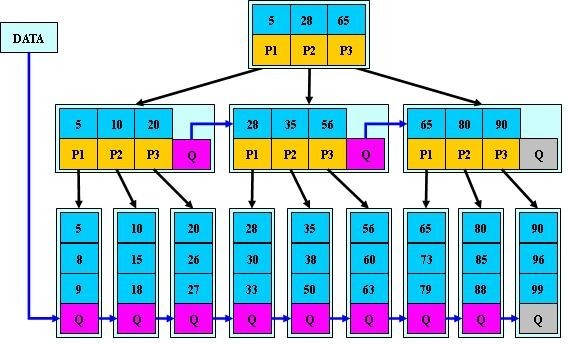
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针。
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针。
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
6、B树的插入、删除操作
- 树中每个结点含有最多含有m个孩子,即m满足:ceil(m/2)<=m<=m。
- 除根结点和叶子结点外,其它每个结点至少有[ceil(m / 2)]个孩子(其中ceil(x)是一个取上限的函数);
- 若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点);
- 所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部接点或查询失败的接点,实际上这些结点不存在,指向这些结点的指针都为null);
- 每个非终端结点中包含有n个关键字信息: (n,P0,K1,P1,K2,P2,......,Kn,Pn)。其中:
a) Ki (i=1...n)为关键字,且关键字按顺序升序排序K(i-1)< Ki。
b) Pi为指向子树根的接点,且指针P(i-1)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
c) 除根结点之外的结点的关键字的个数n必须满足: [ceil(m / 2)-1]<= n <= m-1(叶子结点也必须满足此条关于关键字数的性质,根结点除外)。
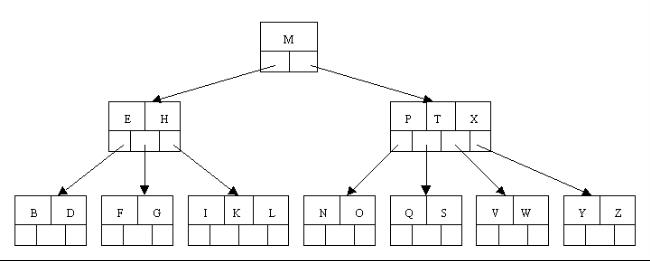
ok,下面咱们以一棵5阶(即树中任一结点至多含有4个关键字,5棵子树)B树实例进行讲解(如下图所示):
备注:
- 关键字数(2-4个)针对--非根结点(包括叶子结点在内),孩子数(3-5个)--针对根结点和叶子结点之外的内结点。当然,根结点是必须至少有2个孩子的,不然就成直线型搜索树了。
- 曾在一次面试中被问到,一棵含有N个总关键字数的m阶的B树的最大高度是多少?答曰:log_ceil(m/2)N (上面中关于m阶B树的第1点特性已经提到:树中每个结点含有最多含有m个孩子,即m满足:ceil(m/2)<=m<=m。而树中每个结点含孩子数越少,树的高度则越大,故如此)。在2012微软4月份的笔试中也问到了此问题。更多原理请看上文第3小节末:B树的高度。
下图中关键字为大写字母,顺序为字母升序。
结点定义如下:
typedef struct{
int Count; // 当前节点中关键元素数目
ItemType Key[4]; // 存储关键字元素的数组
long Branch[5]; // 伪指针数组,(记录数目)方便判断合并和分裂的情况
} NodeType;
6.1、插入(insert)操作
插入一个元素时,首先在B树中是否存在,如果不存在,即在叶子结点处结束,然后在叶子结点中插入该新的元素,注意:如果叶子结点空间足够,这里需要向右移动该叶子结点中大于新插入关键字的元素,如果空间满了以致没有足够的空间去添加新的元素,则将该结点进行“分裂”,将一半数量的关键字元素分裂到新的其相邻右结点中,中间关键字元素上移到父结点中(当然,如果父结点空间满了,也同样需要“分裂”操作),而且当结点中关键元素向右移动了,相关的指针也需要向右移。如果在根结点插入新元素,空间满了,则进行分裂操作,这样原来的根结点中的中间关键字元素向上移动到新的根结点中,因此导致树的高度增加一层。如下图所示:

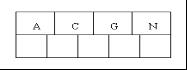
1、OK,下面咱们通过一个实例来逐步讲解下。插入以下字符字母到一棵空的B 树中(非根结点关键字数小了(小于2个)就合并,大了(超过4个)就分裂):C N G A H E K Q M F W L T Z D P R X Y S,首先,结点空间足够,4个字母插入相同的结点中,如下图:
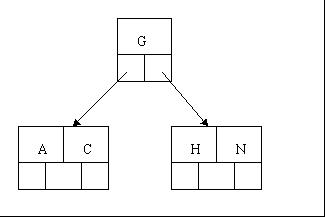
2、当咱们试着插入H时,结点发现空间不够,以致将其分裂成2个结点,移动中间元素G上移到新的根结点中,在实现过程中,咱们把A和C留在当前结点中,而H和N放置新的其右邻居结点中。如下图:
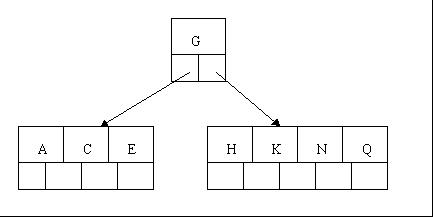
3、当咱们插入E,K,Q时,不需要任何分裂操作
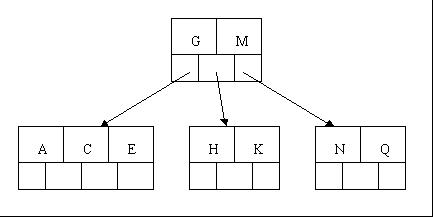
4、插入M需要一次分裂,注意M恰好是中间关键字元素,以致向上移到父节点中
5、插入F,W,L,T不需要任何分裂操作
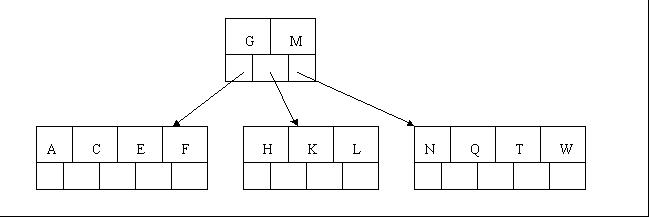
6、插入Z时,最右的叶子结点空间满了,需要进行分裂操作,中间元素T上移到父节点中,注意通过上移中间元素,树最终还是保持平衡,分裂结果的结点存在2个关键字元素。

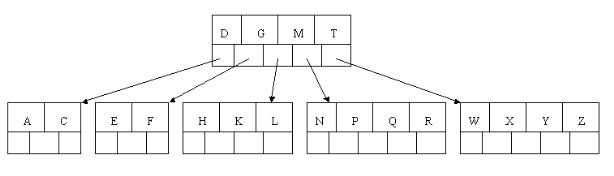
7、插入D时,导致最左边的叶子结点被分裂,D恰好也是中间元素,上移到父节点中,然后字母P,R,X,Y陆续插入不需要任何分裂操作(别忘了,树中至多5个孩子)。
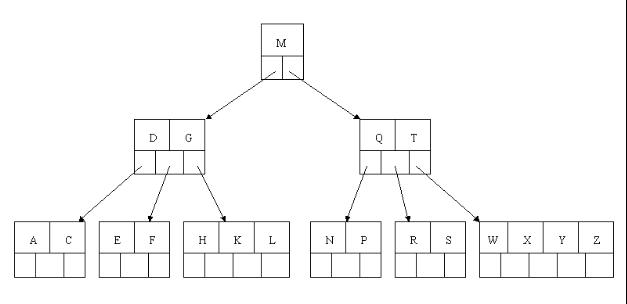
8、最后,当插入S时,含有N,P,Q,R的结点需要分裂,把中间元素Q上移到父节点中,但是情况来了,父节点中空间已经满了,所以也要进行分裂,将父节点中的中间元素M上移到新形成的根结点中,注意以前在父节点中的第三个指针在修改后包括D和G节点中。这样具体插入操作的完成,下面介绍删除操作,删除操作相对于插入操作要考虑的情况多点。
6.2、删除(delete)操作
(1)删除操作的两个步骤
第一步骤:在树中查找被删关键字K所在的地点
第二步骤:进行删去K的操作
(2)删去K的操作
B-树是二叉排序树的推广,中序遍历B-树同样可得到关键字的有序序列(具体遍历算法【参见练习】)。任一关键字K的中序前趋(后继)必是K的左子树(右子树)中最右(左)下的结点中最后(最前)一个关键字。
若被删关键字K所在的结点非树叶,则用K的中序前趋(或后继)K'取代K,然后从叶子中删去K'。从叶子*x开始删去某关键字K的三种情形为:
情形一:若x->keynum>Min,则只需删去K及其右指针(*x是叶子,K的右指针为空)即可使删除操作结束。
注意:

情形二:若x->keynum=Min,该叶子中的关键字个数已是最小值,删K及其右指针后会破坏B-树的性质(3)。若*x的左(或右)邻兄弟结点*y中的关键字数目大于Min,则将*y中的最大(或最小)关键字上移至双亲结点*parent中,而将*parent中相应的关键字下移至x中。显然这种移动使得双亲中关键字数目不变;*y被移出一个关键字,故其keynum减1,因它原大于Min,故减少1个关键字后keynum仍大于等于Min;而*x中已移入一个关键字,故删K后*x中仍有Min个关键字。涉及移动关键字的三个结点均满足B-树的性质(3)。 请读者验证,上述操作后仍满足B-树的性质(1)。移动完成后,删除过程亦结束。
情形三:若*x及其相邻的左右兄弟(也可能只有一个兄弟)中的关键字数目均为最小值Min,则上述的移动操作就不奏效,此时须*x和左或右兄弟合并。不妨设*x有右邻兄弟*y(对左邻兄弟的讨论与此类似),在*x中删去K后,将双亲结点*parent中介于*x和*y之间的关键字K,作为中间关键字,与并x和*y中的关键字一起"合并"为一个新的结点取代*x和*y。因为*x和*y原各有Min个关键字,从双亲中移人的K'抵消了从*x中删除的K,故新结点中恰有2Min(即2「m/2」-2≤m-1)个关键字,没有破坏B-树的性质(3)。但由于K'从双亲中移到新结点后,相当于从*parent中删去了K',若parent->keynum原大于Min,则删除操作到此结束;否则,同样要通过移动*parent的左右兄弟中的关键字或将*parent与其 左右兄弟合并的方法来维护B-树性质。最坏情况下,合并操作会向上传播至根,当根中只有一个关键字时,合并操作将会使根结点及其两个孩子合并成一个新的根,从而使整棵树的高度减少一层。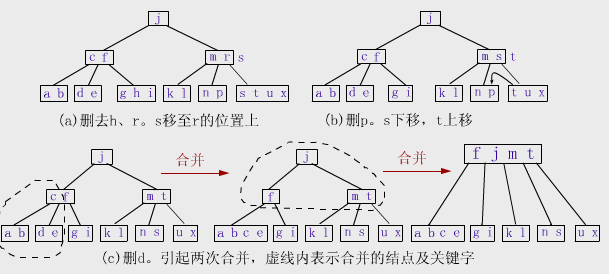
分析:
第1个被删的关键字h是在叶子中,且该叶子的keynum>Min(5阶B-树的Min=2),故直接删去即可。第2个删去的r不在叶子中,故用中序后继s取代r,即把s复制到r的位置上,然后从叶子中删去s。第3个删去的p所在的叶子中的关键字数目是最小值Min,但其右兄弟的keynum>Min,故可以通过左移,将双亲中的s移到p所在的结点,而将右兄弟中最小(即最左边)的关键字t上移至双亲取代s。当删去d时,d所在的结点及其左右兄弟均无多余的关键字,故需将删去d后的结点与这两个兄弟中的一个(图中是选择左兄弟(ab))及其双亲中分隔这两个被合并结点的关键字c合并在一起形成一个新结点(abce)。但因为双亲中失去c后keynum<Min,故必须对该结点做调整操作,此时它只有一个右兄弟,且右兄弟无多余的关键字,不可能通过移动关键字来解决。因此引起再次合并,因根只有一个关键字,故合并后树高度减少一层,从而得到上图的最后一个图。
B-树的高度及性能分析
B-树上操作的时间通常由存取磁盘的时间和CPU计算时间这两部分构成。B-树上大部分基本操作所需访问盘的次数均取决于树高h。关键字总数相同的情况下B-树的高度越小,磁盘I/O所花的时间越少。
与高速的CPU计算相比,磁盘I/O要慢得多,所以有时忽略CPU的计算时间,只分析算法所需的磁盘访问次数(磁盘访问次数乘以一次读写盘的平均时间(每次读写的时间略有差别)就是磁盘I/O的总时间)。
1、B-树的高度
定理9.1 若n≥1,m≥3,则对任意一棵具有n个关键字的m阶B-树,其树高h至多为:
logt((n+1)/2)+1。
这里t是每个(除根外)内部结点的最小度数,即

由上述定理可知:B-树的高度为O(logtn)。于是在B-树上查找、插入和删除的读写盘的次数为O(logtn),CPU计算时间为O(mlogtn)。
2、性能分析
①n个结点的平衡的二叉排序的高度H(即lgn)比B-树的高度h约大lgt倍。
【例】若m=1024,则lgt=lg512=9。此时若B-树高度为4,则平衡的二叉排序树的高度约为36。显然,若m越大,则B-树高度越小。
②若要作为内存中的查找表,B-树却不一定比平衡的二叉排序树好,尤其当m较大时更是如此。
因为查找等操作的CPU计算时间在B-树上是
O(mlogtn)=0(lgn·(m/lgt))
而m/lgt>1,所以m较大时O(mlogtn)比平衡的二叉排序树上相应操作的时间O(lgn)大得多。因此,仅在内存中使用的B-树必须取较小的m。(通常取最小值m=3,此时B-树中每个内部结点可以有2或3个孩子,这种3阶的B-树称为2-3树)。
B+树是B-树的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
如:(M=3)
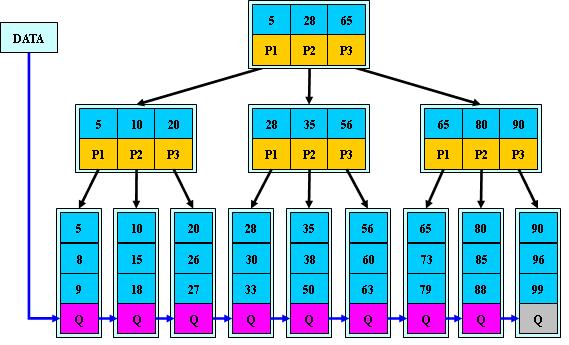
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4.更适合文件索引系统;
B*树
是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针;
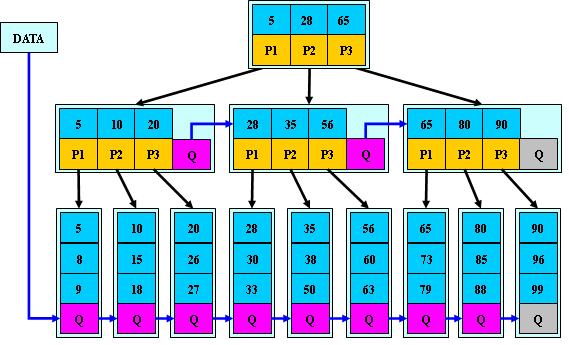
B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2);
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
B树详解的更多相关文章
- 数据结构图文解析之:AVL树详解及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- trie字典树详解及应用
原文链接 http://www.cnblogs.com/freewater/archive/2012/09/11/2680480.html Trie树详解及其应用 一.知识简介 ...
- Linux DTS(Device Tree Source)设备树详解之二(dts匹配及发挥作用的流程篇)【转】
转自:https://blog.csdn.net/radianceblau/article/details/74722395 版权声明:本文为博主原创文章,未经博主允许不得转载.如本文对您有帮助,欢迎 ...
- JavaScript---Dom树详解,节点查找方式(直接(id,class,tag),间接(父子,兄弟)),节点操作(增删改查,赋值节点,替换节点,),节点属性操作(增删改查),节点文本的操作(增删改查),事件
JavaScript---Dom树详解,节点查找方式(直接(id,class,tag),间接(父子,兄弟)),节点操作(增删改查,赋值节点,替换节点,),节点属性操作(增删改查),节点文本的操作(增删 ...
- 线段树详解 (原理,实现与应用)(转载自:http://blog.csdn.net/zearot/article/details/48299459)
原文地址:http://blog.csdn.net/zearot/article/details/48299459(如有侵权,请联系博主,立即删除.) 线段树详解 By 岩之痕 目录: 一:综述 ...
- Linux dts 设备树详解(二) 动手编写设备树dts
Linux dts 设备树详解(一) 基础知识 Linux dts 设备树详解(二) 动手编写设备树dts 文章目录 前言 硬件结构 设备树dts文件 前言 在简单了解概念之后,我们可以开始尝试写一个 ...
- Linux dts 设备树详解(一) 基础知识
Linux dts 设备树详解(一) 基础知识 Linux dts 设备树详解(二) 动手编写设备树dts 文章目录 1 前言 2 概念 2.1 什么是设备树 dts(device tree)? 2. ...
- AVL树详解
AVL树 参考了:http://www.cppblog.com/cxiaojia/archive/2012/08/20/187776.html 修改了其中的错误,代码实现并亲自验证过. 平衡二叉树(B ...
- trie树--详解
文章作者:yx_th000 文章来源:Cherish_yimi (http://www.cnblogs.com/cherish_yimi/) 转载请注明,谢谢合作.关键词:trie trie树 数据结 ...
- 转:trie树--详解
前几天学习了并查集和trie树,这里总结一下trie. 本文讨论一棵最简单的trie树,基于英文26个字母组成的字符串,讨论插入字符串.判断前缀是否存在.查找字符串等基本操作:至于trie树的删除单个 ...
随机推荐
- Archlinux 2015.07.01 和 Windows7 双系统 安装教程
提前在windows7下给Archlinux预留一个分区,大小最好在20G以上(根据自己硬盘情况分配). 第一步,安装前的准备 从arch官网下载最新的ISO文件archlinux-2015.07.0 ...
- WP、Win10开发或者WPF开发时绘制自定义窗体~例如:一个手机
WP and Win10 效果:(数字是参考值,和UI无关) <Page x:Class="_05.AllControls._BorderUsePage" xmlns=&qu ...
- Ajax在IE浏览器会出现中文乱码解决办法
在AJAX浏览器来进行发送数据时,一般它所默认的都是UTF-8的编码. Ajax在IE浏览器会出现中文乱码的情况!解决办法如下 <script type="text/javascrip ...
- 开发笔记:基于EntityFramework.Extended用EF实现指定字段的更新
今天在将一个项目中使用存储过程的遗留代码迁移至新的架构时,遇到了一个问题——如何用EF实现数据库中指定字段的更新(根据UserId更新Users表中的FaceUrl与AvatarUrl字段)? 原先调 ...
- IOS开发初步
由于工程实践项目的原因,得学习下IOS开发,今天才知道苹果09年才出的开发工具和开发包,也就是说,满打满算,现在顶多有5年IOS开发的工作经验.在我国2010年才火起来,因为那时候国内的iphone4 ...
- 自制Https证书并在Spring Boot和Nginx中使用
白话Https一文中, 介绍了Https存在的目的和工作原理,但多是偏向于原理性的介绍,本文介绍如何一步一步自制一个能够通过浏览器认证的Https证书,并讲解在Spring Boot环境和Nginx环 ...
- Windows Azure Cloud Service (37) 浅谈Cloud Service
<Windows Azure Platform 系列文章目录> 最近在和一些客户聊天,常常被遇到这样的问题: 1.问题一:我在创建一个新的Windows Azure Virtual Mac ...
- Windows Azure Virtual Network (7) 设置Azure Virtual Machine固定公网IP (Virtual IP Address, VIP) (2)
<Windows Azure Platform 系列文章目录> 本文介绍的是,当用户在创建Azure Virtual Machine的时候,忘记绑定公网IP,需要重新绑定公网IP的具体操作 ...
- 使用git提交中删除idea
https://segmentfault.com/q/1010000000720031 http://www.tuicool.com/articles/a6Nf63F 先有项目,然后分享至github ...
- Maven提高篇系列之(六)——编写自己的Plugin(本系列完)
这是一个Maven提高篇的系列,包含有以下文章: Maven提高篇系列之(一)——多模块 vs 继承 Maven提高篇系列之(二)——配置Plugin到某个Phase(以Selenium集成测试为例) ...