在SQL Server 2016里使用查询存储进行性能调优
作为一个DBA,排除SQL Server问题是我们的职责之一,每个月都有很多人给我们带来各种不能解释却要解决的性能问题。
我就多次听到,以前的SQL Server的性能问题都还好且在正常范围内,但现在一切已经改变,SQL Server开始糟糕, 疯狂的事情不能解释。在这个情况下我介入,分析下整个SQL Server的安装,最后用一些神奇的调查方法找出性能问题的根源。
但很多时候问题的根源是一样的:所谓的计划回归(Plan Regression),即特定查询的执行计划已经改变。昨天SQL Server已经缓存了在计划缓存里缓存了一个好的执行计划,今天就生成、缓存最后重用了一个糟糕的执行计划——不断重复。
进入SQL Server 2016后,我就变得有点多余了,以为微软引进了查询存储(Query Store)。这是这个版本最热门的功能!查询存储帮助你很容易找出你的性能问题是不是计划回归造成的。如果你找到了计划回归,这很容易强制一个特定计划不使用计划向导。听起来很有意思?让我们通过一个特定的场景,向你展示下在SQL Server 2016里,如何使用查询存储来找出并最终修正计划回归。
查询存储(Query Store)——我的对手
在SQL Server 2016里,在你使用查询存储功能前,你要对这个数据库启用它。这是通过ALTER DATABASE语句实现,如你所见的下列代码:
CREATE DATABASE QueryStoreDemo
GO USE QueryStoreDemo
GO -- Enable the Query Store for our database
ALTER DATABASE QueryStoreDemo
SET QUERY_STORE = ON
GO -- Configure the Query Store
ALTER DATABASE QueryStoreDemo SET QUERY_STORE
(
OPERATION_MODE = READ_WRITE,
CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 367),
DATA_FLUSH_INTERVAL_SECONDS = 900,
INTERVAL_LENGTH_MINUTES = 1,
MAX_STORAGE_SIZE_MB = 100,
QUERY_CAPTURE_MODE = ALL,
SIZE_BASED_CLEANUP_MODE = OFF
)
GO
在线帮助为你提供了各个选项的详细信息。接下来我创建一个简单的表,创建一个非聚集索引,最后插入80000条记录。
-- Create a new table
CREATE TABLE Customers
(
CustomerID INT NOT NULL PRIMARY KEY CLUSTERED,
CustomerName CHAR(10) NOT NULL,
CustomerAddress CHAR(10) NOT NULL,
Comments CHAR(5) NOT NULL,
Value INT NOT NULL
)
GO -- Create a supporting new Non-Clustered Index.
CREATE UNIQUE NONCLUSTERED INDEX idx_Test ON Customers(Value)
GO -- Insert 80000 records
DECLARE @i INT = 1
WHILE (@i <= 80000)
BEGIN
INSERT INTO Customers VALUES
(
@i,
CAST(@i AS CHAR(10)),
CAST(@i AS CHAR(10)),
CAST(@i AS CHAR(5)),
@i
) SET @i += 1
END
GO
为了访问我们的表,我额创建了一个简单的存储过程,传入value值作为过滤谓语。
-- Create a simple stored procedure to retrieve the data
CREATE PROCEDURE RetrieveCustomers
(
@Value INT
)
AS
BEGIN
SELECT * FROM Customers
WHERE Value < @Value
END
GO
现在我用80000的参数值来执行存储过程。
-- Execute the stored procedure.
-- This generates an execution plan with a Key Lookup (Clustered).
EXEC RetrieveCustomers 80000
GO
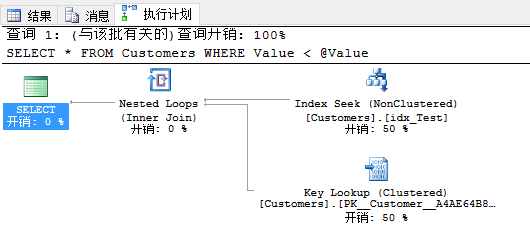
现在当你查看实际的执行计划时,你会看到查询优化器已经选择了有419个逻辑读的聚集索引扫描运算符。SQL Server并没有使用非聚集索引,因为这样没有意义,由于临界点。这个查询结果并没有选择性。

现在假设SQL Server发生了些事情(例如重启,故障转移),SQL Server忽略已经缓存的计划,这里我通过执行DBCC FREEPROCCACHE从计划缓存里抹掉每个缓存的计划来模拟SQL Server重启(不要在生产环境里使用!)。
-- Get rid of the cached execution plan...
DBCC FREEPROCCACHE
GO
现在有人再次调用你的存储过程,这次输入参数值是1。这次执行计划不一样,因为现在在执行计划里你会有书签查找。SQL Server估计行数是1,在非聚集索引里没有找到任何行。因此与非聚集索引查找结合的书签查找才有意义,因为这个查询是有选择性的。
现在我再执行用80000参数值的查询。
-- Execute the stored procedure
EXEC RetrieveCustomers 1
GO -- Execute the stored procedure again
-- This introduces now a plan regression, because now we get a Clustered Index Scan
-- instead of the Key Lookup (Clustered).
EXEC RetrieveCustomers 80000
GO
当你再次看STATISTICS IO的输出,你会看到这个查询现在产生了160139个逻辑读——刚才的查询只有419个逻辑读。这个时候DBA的手机就会响起,性能问题。但今天我们要不同的方式解决——使用刚才启用的查询存储。
当你再次看实际的执行计划,在你面前你会看到有一个计划回归,因为SQL Server刚重用了书签查找的的计划缓存。刚才你有聚集索引扫描运算符的执行计划。这是SQL Server里参数嗅探的副作用。
让我们通过查询存储来详细了解这个问题。在SSMS里的对象资源管理器里,SQL Server 2016提供了一个新的结点叫查询存储,这里你会看到一些报表。
【前几个资源使用查询】向你展示了最昂贵的查询,基于你选择的维度。这里切换到【逻辑读取次数】。
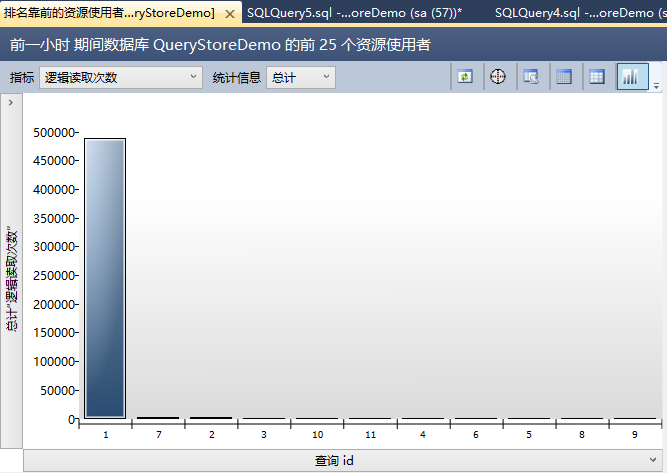
这里在你面前有一些查询。最昂贵的查询生成了近500000个逻辑读。这是我们的初始语句。这已经是第一个WOW效果的的查询存储:SQL Server重启后,查询存储的数据还是存在的!第2个是你存储过程里的SELECT语句。在查询存储里每个捕获的查询都有一个标示号——这里是7。最后当你看报告的右边,你会看这个查询的不同执行计划。

如你所见,查询存储捕获了2个不同的执行计划,一个ID是7,一个ID是8。当你点击计划ID时,SQL Server会在报表的最下面为你显示估计的执行计划。

计划8是聚集索引扫描,计划7是书签查找。如你所见,使用查询存储分析计划回归非常简单。但你现在还没结束。你现在可以对指定的查询强制执行计划。 现在你知道包含聚集索引扫描的执行计划有更好的性能。因此现在你可以通过点击【强制执行计划】强制查询7使用执行计划。

搞定,我们已经解决问题了!
现在当你执行存储过程(用80000的输入参数值),在执行计划里你可以看到聚集索引扫描,执行计划只生成419个逻辑读——很简单,是不是?绝对不是!!!!
微软告诉我们只给修正SQL Server性能相关的“新方式”。你只是强制了特定的计划,一切都还好。这个方法有个大的问题,因为性能问题的根源并没有解决!这个问题的关键是因为书签查找计划没有稳定性。取决于首次执行计划默认的输入值,执行计划因此就被不断重用。
通常我会建议调整下你的索引设计,创建一个覆盖索引来保证计划的稳定性。但强制特定执行计划只是临时解决问题——你还是要修正你问题的根源。
小结
不要误解我:SQL Server 2016里的查询存储功能很棒,可以帮你更容易理解计划回归。它也会帮你“临时”强制特定的执行计划。但性能调优的目标还是一样:你要找到问题根源,尝试解决问题——不要在外面晃荡!
感谢关注!
在SQL Server 2016里使用查询存储进行性能调优的更多相关文章
- sql server 2016新特性 查询存储(Query Store)的性能影响
前段时间给客户处理性能问题,遇到一个新问题, 客户的架构用的是 alwayson ,并且硬件用的是4路96核心,内存1T ,全固态闪存盘,sql server 2016 . 问题 描述 客户经常出现 ...
- SQL Server 2016里的sys.dm_exec_input_buffer
在你的DBA职业里,你们谁有用过DBCC INPUTBUFFER命令,来获得已经提交到SQL Server特定会话的最后SQL语句?请举手!大家都用过! 我们都知道DBCC命令有点尴尬,因为你不能在T ...
- SQL Server 2016里TempDb的提升
几个星期前,SQL Server 2016的最新CTP版本已经发布了:CTP 2.4(目前已经是CTP 3.0).这个预览版相比以前的CTP包含了很多不同的提升.在这篇文章里我会谈下对于SQL Ser ...
- SQL Server 2016:内存列存储索引
作者 Jonathan Allen,译者 谢丽 SQL Server 2016的一项新特性是可以在“内存优化表(Memory Optimized Table)”上添加“列存储索引(Columnstor ...
- SQL Server 2016 查询存储性能优化小结
SQL Server 2016已经发布了有半年多,相信还有很多小伙伴还没有开始使用,今天我们来谈谈SQL Server 2016 查询存储性能优化,希望大家能够喜欢 作为一个DBA,排除SQL Ser ...
- SQL Server 2016 CTP2.2 的关键特性
SQL Server 2016 CTP2.2 的关键特性 正如微软CEO 说的,SQL Server2016 是一个Breakthrough Flagship Database(突破性的旗舰级数据库 ...
- SQL Server 2014里的性能提升
在这篇文章里我想小结下SQL Server 2014引入各种惊艳性能提升!! 缓存池扩展(Buffer Pool Extensions) 缓存池扩展的想法非常简单:把页文件存储在非常快的存储上,例如S ...
- SQL Server 列存储性能调优(翻译)
原文地址:http://social.technet.microsoft.com/wiki/contents/articles/4995.sql-server-columnstore-performa ...
- 数据库技术丛书:SQL Server 2016 从入门到实战(视频教学版) PDF
1:书籍下载方式: SQL Server2016从入门到实战 PDF 下载 链接:https://pan.baidu.com/s/1sWZjdud4RosPyg8sUBaqsQ 密码:8z7w 学习 ...
随机推荐
- Tesseract-OCR识别中文与训练字库实例
关于中文的识别,效果比较好而且开源的应该就是Tesseract-OCR了,所以自己亲身试用一下,分享到博客让有同样兴趣的人少走弯路. 文中所用到的身份证图片资源是百度找的,如有侵权可联系我删除. 一. ...
- 高性能网站架构设计之缓存篇(4)- Redis 主从复制
Redis 的主从复制配置非常容易,但我们先来了解一下它的一些特性. redis 使用异步复制.从 redis 2.8 开始,slave 也会周期性的告诉 master 现在的数据量.可能只是个机制, ...
- 使用WMI和性能计数器监控远程服务器权限设置
应用场景:在web服务器中,通过.NET编码使用WMI查询远程服务器的一些硬件配置信息,使用性能计数器查询远程机器的运行时资源使用情况.在网上没有找到相关的东西,特记录与大家共享. 将web服务器和所 ...
- [.NET领域驱动设计实战系列]专题十:DDD扩展内容:全面剖析CQRS模式实现
一.引言 前面介绍的所有专题都是基于经典的领域驱动实现的,然而,领域驱动除了经典的实现外,还可以基于CQRS模式来进行实现.本专题将全面剖析如何基于CQRS模式(Command Query Respo ...
- 升级AutoMapper后遇到的“Missing map”与“Missing type map configuration”问题
前几天发现 AutoMapper 3.3 的一个性能问题(详见:遭遇AutoMapper性能问题:映射200条数据比100条慢了近千倍),于是将 AutoMapper 升级至最新的 5.1.1 看是否 ...
- s3c2440笔记1(启动)
s3c2440启动方式 1. 从nand flash 启动 1.1 上电后将nand flash中的前4KB数据复制到“Stepping Stone”: 1.2 CPU 执行“Stepping Sto ...
- 【原创】三分钟教你学会MVC框架——基于java web开发(2)
没想到我的上一篇博客有这么多人看,还有几位看完之后给我留言加油,不胜感激,备受鼓励,啥都别说了,继续系列文章之第二篇.(如果没看过我第一篇博客的朋友,可以到我的主页上先浏览完再看这篇文章,以免上下文对 ...
- [PCB制作] 1、记录一个简单的电路板的制作过程——四线二项步进电机驱动模块(L6219)
前言 现在,很多人手上都有一两个电子设备,但是却很少有人清楚其中比较关键的部分(PCB电路板)是如何制作出来的.我虽然懂点硬件,但是之前设计的简单系统都是自己在万能板上用导线自己焊接的(如下图左),复 ...
- Sizeof的计算看内存分配
本文记录了有关sizeof的一些计算,主要有下面的四种情况:(如有错误,敬请留言) 使用sizeof()计算普通变量所占用的内存空间 sizeof计算类对象所占用空间的大小-用到了字节对齐 sixeo ...
- SQL-truncate && delete && drop 的区别
有些人在删除表的所有记录的时候,喜欢这样来——不给DELETE 语句提供WHERE 子句,表中的所有记录都将被删除.但这种方法是不可取的,正确的应该使用 TRUNCATE TABLE tb_name ...