[Python]实践:实现探测Web服务质量
来源:Python 自动化运维 技术与最佳实践
HTTP服务是最流行的互联网应用之一,服务质量的好坏关系到用户体验以及网站的运营服务水平,最常用的有两个标准:1、服务的可用性,比是否处于正常提供服务状态,而不是出现404页面未找到或者500页面错误等;2、服务的响应速度,比如静态类文件下载时间都控制在毫秒级,动态CGI为秒级。
该示例使用pycurl的setopt与getinfo方法实现HTTP服务质量的探测,获取监控URL返回的HTTP状态码,HTTP状态码采用pycurl.HTTP_CODE常量得到,以及从HTTP请求到完成下载期间各环节的响应时间,通过pycurl.NAMELOOKUP_TIME,pycurl.CONNECT_TIME,pycurl.PRETRANSFER_TIME,pycurl.R等常量来实现。另外通过pycurl.WRITEHEADER,pycurl.WRITEDATA常量得到目标URL的HTTP响应头部及页面内容。
一、安装 pycurl模块
1.要求curl-config包支持,需要源码方式重新安装curl
#wget http://curl.haxx.se/download/curl-7.36.0.tar.gz
#tar -zxvf curl-7.36.0.tar.gz
#cd curl-7.36.0.tar.gz
#./configure
#make && make install
#export LD_LIBRARY_PATH=/usr/local/lib
#
2.安装pycurl
下载地址:https://pypi.python.org/pypi/pycurl,上传至服务器
# tar -zxvf pycurl-7.43.0.1.tar.gz
# cd pycurl-7.43.0.1/
# python setup.py install --curl-config=/usr/local/bin/curl-config
3.检验安装结果
二、编写脚本simple.py
#!/usr/bin/python
# -*- coding:UTF-8 -*-
import os, sys
import time
import pycurl #探测的目标URL
URL= "http://www.baidu.com"
#创建一个Curl对象
c = pycurl.Curl() #定义请求的URL常量
c.setopt(pycurl.URL, URL)
#定义请求连接的等待时间
c.setopt(pycurl.CONNECTTIMEOUT, 5)
#定义请求超时时间
c.setopt(pycurl.TIMEOUT, 5)
#屏蔽下载进度条
c.setopt(pycurl.NOPROGRESS, 1)
#完成交互后强制断开连接,不重用
c.setopt(pycurl.FORBID_REUSE, 1)
#指定HTTP重定向的最大数为1
c.setopt(pycurl.MAXREDIRS, 1)
#设置保存DNS信息的时间为30秒
c.setopt(pycurl.DNS_CACHE_TIMEOUT, 30)
#创建一个文件对象,以“wb”方式打开,用来存储返回的http头部及页面内容
indexfile = open(os.path.dirname(os.path.realpath(__file__)) + "/content.txt", "wb")
#将返回的HTTP HEADER定向到indexfile文件
c.setopt(pycurl.WRITEHEADER, indexfile)
#将返回的HTML内容定向到indexfile文件对象
c.setopt(pycurl.WRITEDATA, indexfile)
try:
#提交请求
c.perform()
except Exception, e:
print "connection error: " + str(e)
indexfile.close()
c.close()
sys.exit() #获取DNS解析时间
NAMELOOKUP_TIME = c.getinfo(c.NAMELOOKUP_TIME)
#获取建立连接时间
CONNECT_TIME = c.getinfo(c.CONNECT_TIME)
#获取从建立连接到准备传输所消耗的时间
PRETRANSFER_TIME = c.getinfo(c.PRETRANSFER_TIME)
#获取从建立连接到传输开始消耗的时间
STARTTRANSFER_TIME = c.getinfo(c.STARTTRANSFER_TIME)
#获取传输的总时间
TOTAL_TIME = c.getinfo(c.TOTAL_TIME)
#获取HTTP状态码
HTTP_CODE = c.getinfo(c.HTTP_CODE)
#获取下载数据包大小
SIZE_DOWNLOAD = c.getinfo(c.SIZE_DOWNLOAD)
#获取HTTP头部大小
HEADER_SIZE = c.getinfo(c.HEADER_SIZE)
#获取平均下载速度
SPEED_DOWNLOAD = c.getinfo(c.SPEED_DOWNLOAD)
#打印输出相关数据
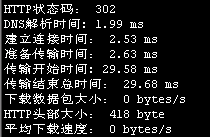
print "HTTP状态码: %d" % (HTTP_CODE)
print "DNS解析时间: %.2f ms" % (NAMELOOKUP_TIME * 1000)
print "建立连接时间: %.2f ms" % (CONNECT_TIME * 1000)
print "准备传输时间: %.2f ms" % (PRETRANSFER_TIME * 1000)
print "传输开始时间: %.2f ms" % (STARTTRANSFER_TIME * 1000)
print "传输结束总时间: %.2f ms" %(TOTAL_TIME * 1000)
print "下载数据包大小: %d bytes/s" %(SIZE_DOWNLOAD)
print "HTTP头部大小: %d byte" %(HEADER_SIZE)
print "平均下载速度: %d bytes/s" %(SPEED_DOWNLOAD)
#关闭文件及Curl对象
indexfile.close()
c.close()
chmod +x simple.py #授予执行权限
./simple.py #执行脚本
执行结果如下:
[Python]实践:实现探测Web服务质量的更多相关文章
- 6.python探测Web服务质量方法之pycurl模块
才开始学习的时候有点忽略了这个模块,觉得既然Python3提供了requests库,为什么多此一举学习这个模块.后来才发现pycurl在探测Web服务器的时候的强大. pycurl是一个用c语言写的l ...
- Python学习笔记 - 实现探测Web服务质量
#!/usr/bin/python3# _*_ coding:utf-8 _*_import sys, osimport timeimport pycurl url = "https://d ...
- python3之模板pycurl探测web服务质量
1.pycurl简介 pycURL是libcurl多协议文件传输库的python接口,与urllib模块类似,PycURL可用于从python程序中获取由URL标识的对象,功能很强大,libcurl速 ...
- 使用pycurl探测web服务质量
1:pycurl模块的安装方法 easy_install pycurl pip install pycurl 2:示例代码如下,是在python3下实现的,如若使用python2稍作修改即可 # -* ...
- 探测web服务质量方法
- 探测web服务器质量——pycurl
pycurl是一个用C语言写的libcurl Python实现,功能非常强大,支持的操作协议有FTP.HTTP.HTTPS.TELNET等,可以理解为Linux下curl命令功能的Python封装,简 ...
- [Python] 利用Django进行Web开发系列(一)
1 写在前面 在没有接触互联网这个行业的时候,我就一直很好奇网站是怎么构建的.现在虽然从事互联网相关的工作,但是也一直没有接触过Web开发之类的东西,但是兴趣终归还是要有的,而且是需要自己动手去实践的 ...
- Python 实现简单的 Web
简单的学了下Python, 然后用Python实现简单的Web. 因为正在学习计算机网络,所以通过编程来加强自己对于Http协议和Web服务器的理解,也理解下如何实现Web服务请求.响应.错误处理以及 ...
- [Python] 利用Django进行Web开发系列(二)
1 编写第一个静态页面——Hello world页面 在上一篇博客<[Python] 利用Django进行Web开发系列(一)>中,我们创建了自己的目录mysite. Step1:创建视图 ...
随机推荐
- Flask--异常处理
异常处理: abort(404)-捕获HTTP抛出的统一状态码 @app.errorhandler-捕获全局异常错误码,捕获异常错误 @app.route("/demo4") de ...
- Linux LVM 简单操作
查看当前磁盘分区情况fdisk -l 磁盘分区fdisk /dev/sdb# 可能用到的Type :# 8e Linux LVM# fd Linux raid auto 创建PVpvcreate /d ...
- SpringBoot使用redis缓存List
一.概述 最近在做性能优化,之前有一个业务是这样实现的: 1.温度报警后第三方通讯管理机直接把报警信息保存到数据库: 2.我们在数据库中添加触发器,(BEFORE INSERT)根据这条报警信息处理业 ...
- ALGO-143_蓝桥杯_算法训练_字符串变换
问题描述 相信经过这个学期的编程训练,大家对于字符串的操作已经掌握的相当熟练了.今天,徐老师想测试一下大家对于字符串操作的掌握情况.徐老师自己定义了1,,,,5这5个参数分别指代不同的5种字符串操作, ...
- Tomacat 配置
server.xml文件中元素: 1.<Service name="Catalina"> 这个元素相当于IIS的一个网站.该元素可有多个.每个元素会根据名字在conf文 ...
- Java连接S3并上传Redis
package com.shinho.bigdatalake.redis; import com.amazonaws.regions.Region; import com.amazonaws.regi ...
- YAML配置,spring boot 配置文件
1 概念YAML是一种人们可以轻松阅读的数据序列化格式,并且它非常适合对动态编程语言中使用的数据类型进行编码.YAML是YAML Ain't Markup Language简写,和GNU(" ...
- lucene索引查看工具luke和文本提取工具Tika
luke可以方便的查看lucene的索引信息,当然也可以查看solr和es中的索引信息(基于lucene实现). 查看索引前,要注意lucene版本的问题,高版本的lucene用低版本的luke工具就 ...
- Jmeter(二十五)Jmeter之系统函数
都忘了Jmeter4.0已发布((*^▽^*))具体优化项还没体验,记录一下,传送门:http://jmeter.apache.org/download_jmeter.cgi Jmeter的系统函数已 ...
- C# 公共类
https://github.com/Jimmey-Jiang/Common.Utility/tree/master/Utility%E5%9F%BA%E7%A1%80%E7%B1%BB%E5%A4% ...