【Social listening实操】作为一个合格的“增长黑客”,你还得重视外部数据的分析!
本文转自知乎
作者:苏格兰折耳喵
—————————————————————————————————————————————————————
在本文中,作者引出了“外部数据”这一概念,并实例分析,如何从海量的外部数据中获取可以对自身业务起到指导作用和借鉴意义的insight,并借助外部环境数据来优化自己。
现在互联网上关于“增长黑客”的概念很火,它那“四两拨千斤”、“小投入大收益”的神奇法力令无数互联网从业者为之着迷。一般来说,“增长黑客”主要依赖于企业的内部数据(如企业自身拥有的销售数据、用户数据、页面浏览数据等),以此为依据进行数据分析和推广策略拟定。但是,如果遇到如下几种情况,“增长黑客”就捉襟见肘了:
- 假如一家初创公司,自己刚起步,自身并没有还积累数据,怎么破?
- 就算有数据,但自己拥有的数据无论在“质”和“量”上都很差,正所谓“garbage in ,garbage out”,这样的数据再怎么分析和挖掘,也难以得到可作为决策依据的数据洞察……
- 能看到数量上的变化趋势,却无法精准的获悉数值变动的真正原因,比如,近期APP上的活跃度下降不少,从内部数据上,你只能看到数量上的减少,但对于用户活跃度下降的真实动因却无法准确判定,只能拍脑袋或者利用过时的经验,无法让相关人信服。
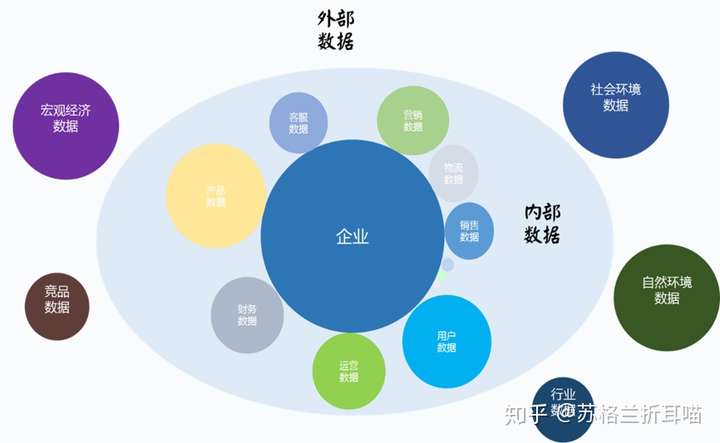
由此,笔者引出了“外部数据”这一概念,尤其是“Open Data”这片“数据蓝海”,“他山之石,可以攻玉”,从海量的外部数据中获取可以对自身业务起到指导作用和借鉴意义的insight,借助外部环境数据来优化运营和产品设计。
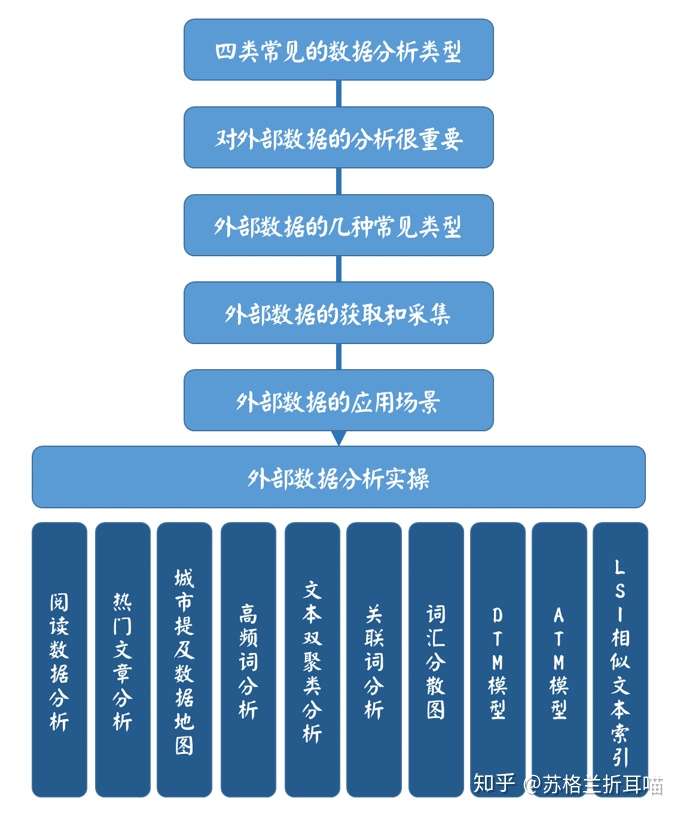
下图是本文的行文脉络:
在谈及外部数据的重要性之前,让我们先简单的看一看数据分析的四种类型。
1. 四种常见的数据分析类型
按数据分析对于决策的价值高低和处理分析复杂程度,可将数据分析归为如下图所示的4种范式:
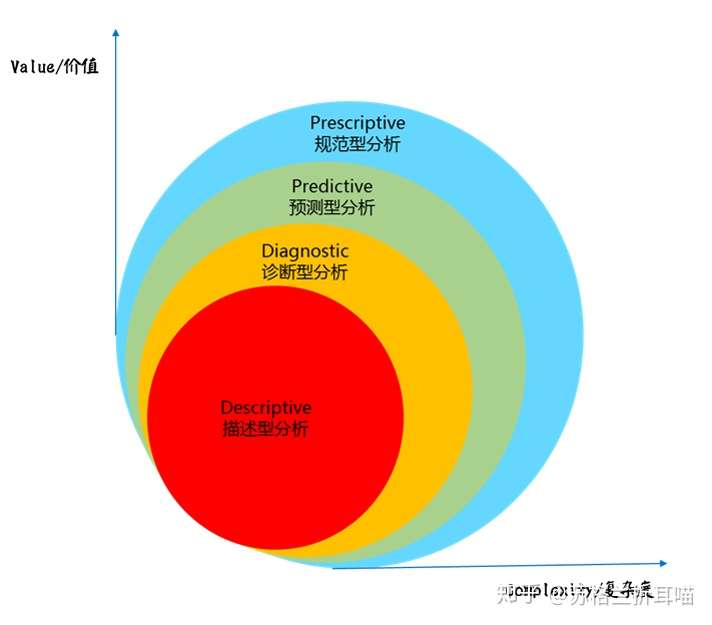
从上图可以看到,越远离坐标原点,沿坐标轴正向延伸,价值度就越高,分析处理的难度也就越大。对于数据分析师而言,“描述型分析”、“诊断型分析”和“预测型分析”最为常见,而“规范型分析”涉及比较高深的数据挖掘和机器学习知识,不是我们接下来讨论的重点。
1.1 描述型数据分析
描述型分析是用来概括、表述事物整体状况以及事物间关联、类属关系的统计方法,是上述四类中最为常见的数据分析类型。通过统计处理可以简洁地用几个统计值来表示一组数据地集中性(如平均值、中位数和众数等)和离散型(反映数据的波动性大小,如方差、标准差等)。
1.2 诊断型数据分析
在描述型分析的基础上,数据分析师需要进一步的钻取和深入,细分到特定的时间维度和空间维度,依据数据的浅层表现和自身的历史累积经验来判断现象/问题出现的原因。
1.3 预测型数据分析
预测型数据分析利用各种高级统计学技术,包括利用预测模型,机器学习,数据挖掘等技术来分析当前和历史的数据,从而对未来或其他不确定的事件进行预测。
1.4 规范型数据分析
最具价值和处理复杂度的当属规范型分析。
规范型分析通过 “已经发生什么”、“为什么发生”和“什么将发生”,也就是综合运用上述提及的描述型分析、诊断型分析和预测型分析,对潜在用户进行商品/服务推荐和决策支持。

2. 对外部数据中的分析很重要
经过上面对四种数据分析类型的描述,笔者认为现有的基于企业内部数据的数据分析实践存在如下几类特征:
- 大多数的数据分析仅停留在描述性数据分析上,未触及数据深层次的规律,没有最大限度的挖掘数据的潜在价值;
- 数据分析的对象以结构化的数值型数据为主,而对非结构化数据,尤其是文本类型的数据分析实践则较少;
- 对内部数据高度重视,如用户增长数据,销售数据,以及产品相关指标数据等,但没有和外部数据进行关联,导致分析的结果片面、孤立和失真,起不到问题诊断和决策支撑作用。
由此,我们必须对企业之外的外部数据引起重视,尤其是外部数据中的非结构化文本数据。
对于文本数据的重要性,笔者已在之前的文章中有过详细的论述,详情请参看《数据运营|数据分析中,文本分析远比数值型分析重要!(上)》。与此同时,非结构化的文本数据广泛存在于社会化媒体之中,关于社会化媒体的相关介绍,请参看《干货|如何利用Social Listening从社会化媒体中“提炼”有价值的信息?》。
3. 外部数据的几种常见类型
外部数据是互联网时代的产物,随着移动互联时代的兴起,外部数据的增长呈现井喷的趋势。各个领域的外部数据从不同角度刻画了移动互联时代的商业社会,综合这些外部数据,才能俯瞰到一个“全息式”的互联网版图。
按互联网行业和领域的不同,外部数据包括且不限于:
- 阿里(淘宝和天猫):电商大数据
- 腾讯(微信和QQ):社交网络大数据
- 新浪(新浪微博和新浪博客):社交媒体大数据
- 脉脉:职场社交大数据
- 谷歌/百度:搜索大数据
- 优酷:影视播放大数据
- 今日头条:阅读兴趣大数据
- 酷云EYE:收视大数据
- 高德地图:POI大数据
4. 外部数据的获取/采集
随着互联网时代对于“Open Data(开放数据)”或“Data Sharing(共享数据)”的日益倡导,很多互联网巨头(部分)开放了它们所积累的外部数据;再者一些可以抓取网络数据的第三方应用和编程工具不断出现,使得我们可以以免费或付费的方式获得大量外部数据(在获得对方允许和涉及商业目的的情况下),最终的形式包括未加工的原始数据、系统化的数据产品和定制化的数据服务。
以下是一些常见的外部数据分析和采集工具:
4.1 指数查询
(1)百度指数
(2)微指数
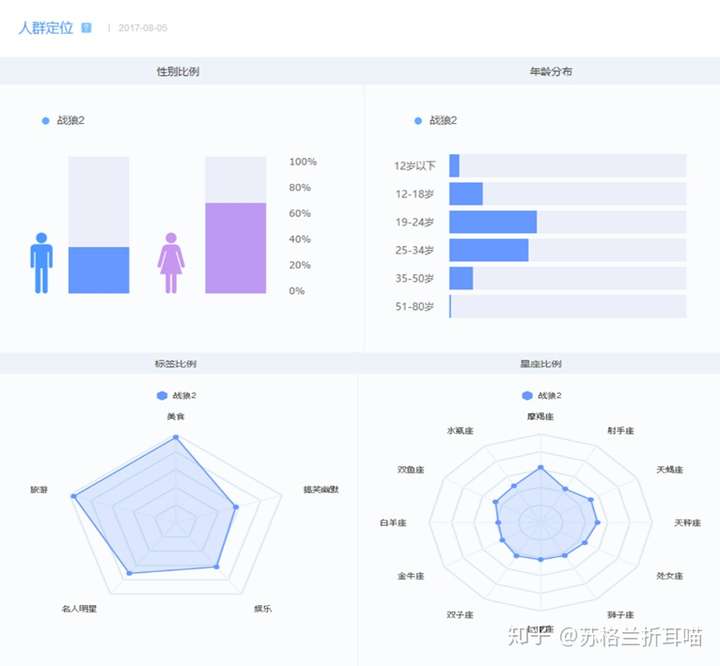
(3)优酷指数
(4)谷歌趋势
4.2 爬虫工具
(1)火车头
(2)Data Scraping
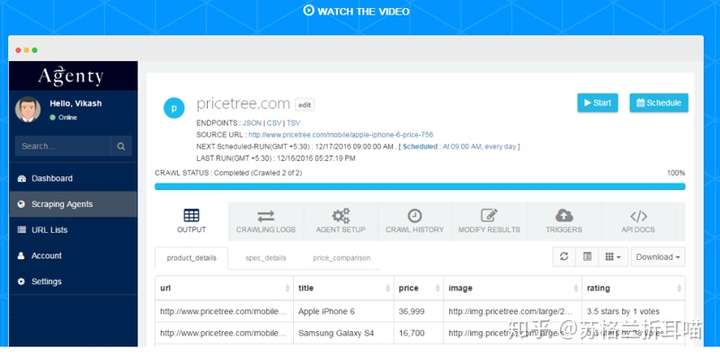
(3)八爪鱼
4.3 社会化媒体监测与分析平台
(1)新浪微舆情
关于上述工具的使用介绍,请参考笔者之前的文章《万字干货|10款数据分析“工具”,助你成为新媒体运营领域的“增长黑客》、《不懂数理和编程,如何运用免费的大数据工具获得行业洞察?》。
5. 外部数据分析的应用场景
最先对外部数据高度重视的先行者其实是政府机构,它们利用大数据舆情系统进行网络舆情的监测,但随着大数据时代的向前推进,外部数据的应用场景也越来越多,包括且不限如下方面:
- 舆情监测
- 企业口碑和客户满意度追踪
- 企业竞争情报分析
- 品牌宣传、广告投放及危机公关
- 市场机会挖掘、产品技术开发创意挖掘
- 行业趋势分析
接下来,笔者将以知名互联网社区——“人人都是产品经理”上近6年的文章数据作为实例,进行“360度无侧漏式”的数据分析,来“示范”下如何对外部数据进行挖掘,从中最大限度的“榨取”关于互联网产品、运营方面的insight。
6. 外部数据分析实操:以“人人都是产品经理”上的文章数据分析为例
“人人都是产品经理”社区创建于2010年,是一个产品经理学习、交流、分享的社会化媒体平台,每天都有更新关于互联网产品、设计、运营等的资讯和文章,由此吸聚了大量的具有互联网背景的读者。据官方宣称,截至2015年,社区共拥有300万忠实粉丝。
因此,“人人都是产品经理”在互联网界具有广泛的影响力,是国内互联网发展的一面镜子,分析它上面的文章数据可以达到见微知著、管中窥豹的效果,从中可以发掘互联网界的历史变迁和发展现状,进而展望互联网行业“将发未发”的热点和前进方向。
在笔者下面的“数据发现之旅”中,会带着3个目的,主要是:
- 通过该社区的资讯文章中,发掘国内互联网发展的一些特征;
- 发掘互联网某些栏目下的热点及其变动趋势;
- 给笔者的内容创作予以写作风格定位和题材选取方面的指导。
以下是笔者抓取的数据的原始形态,抓取了“标题”、“时间”、“正文”、“阅读量”、“评论量”、“收藏量”和“作者”这7个维度的数据,抓取时间区间是2012.05.17~2017.07.31,文章数据共计33,412条。
然后,笔者对数据进行了清洗,主要是“阅读量”,将“k(1000)“、“万(10000)”、“m(1000000)”变成了相应的数字,便于后续的数值计算和排序。同时,新增3个维度,即文章所属的栏目“类别”、“正文字数”和“标题字数”。
6.1全局纵览
6.1.1 各栏目下的文章数量分布情况
首先,先对各个栏目下的文章数量进行基础性的描述性分析,看看10个栏目类别下的文章数量分布。
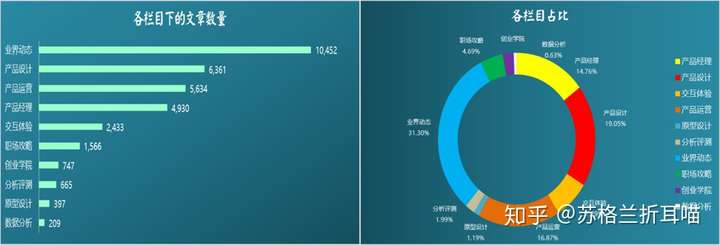
从上面的条状图和环形图可以看出,“业界动态”这一栏目下的文章数量最多,为10,452篇,占到了文章篇数总量的31.3%,其次是产品设计和产品运营,分别占到了总数的19.5%和16.87%,反倒是“产品经理”下的文章数量不多。
接下来,笔者统计了这10各栏目在过去的6年中的数量变化情况,如下面的热力图所示:
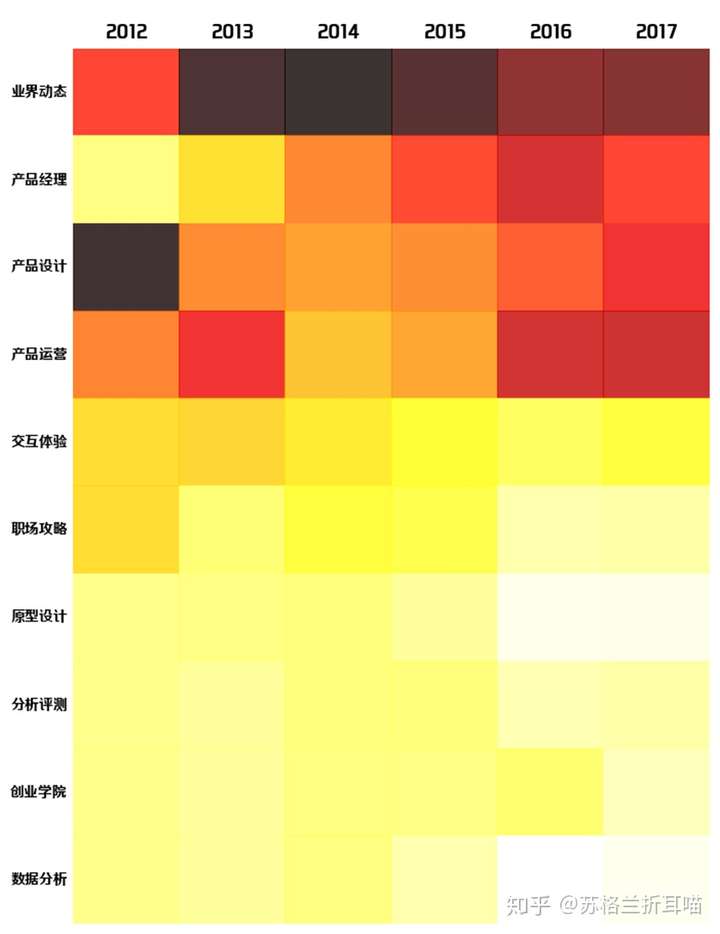
上面的热力图中,色块越深,对应的数值就越大,越浅则数值愈小。其中,互联网的“业界动态”一直是文章发布数量最多的栏目。而“产品经理”的发文数量一路飙升(当然2017年还没过完),间接地可知该职位的热度(关注和写作偏好)蹭蹭的往上窜,成为“改变世界”、拿着高薪的产品经理,是无数互联网从业人员梦寐以求的工作。与此类似的是“产品运营”栏目,发文数量也在稳步上升。
另外,“产品设计”方面的文章主要集中在2012年,可以看出以“用户体验”、“UI设计”、“信息架构”和“需求规划”为主要活动的产品设计在2012年蓬勃发展,产生了大量基于实践经验的干货文章。
6.1.2 阅读数据分析
现在,笔者从“阅读量”、“点赞量”、“收藏量”、“正文字数”和“标题字数”这些能反映读者阅读偏好的数据着手,进行由浅入深的挖掘,从中发现阅读数据中的洞察。
在统计分析之前,先去掉若干有缺失值的数据,此时文本数据总量为33,394。
(1)文章数据的描述性分析
先对所有文章的各个维度进行描述性统计分析,获得这些数据的“初の印象”。
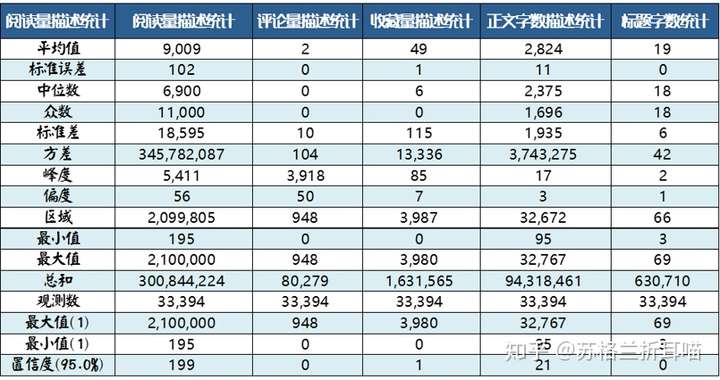
上面的数据过多,为节省篇幅,笔者仅摘取部分数据进行解读:
- 从上表中,笔者发现,单篇文章阅读量的最大值是2,100,000!阅读数高得惊人!在后面的截图中,小伙伴们可以知晓具体是哪一篇文章如此之高的阅读热度。
- 读者的评论热情不高,绝大部分的文章没有评论,这可以从“平均值”、“中位数”和“标准差”这3项指标中看出。
- 绝大部分的文章字数不超过3000,篇幅短小精悍,当然大多数文章都有配图,写得太长,读者懒得看。
- 绝大部分的标题字数不超过20字,太短说不清楚,太长看着招人烦。
(2)文章聚类分析
在该部分,笔者选取 “阅读量”、“收藏量”、“评论量”、“标题字数”这4个维度作为此次聚类分析的特征(Feature),它们共同构造了一个四维空间,每一篇文章因其在这4个维度上的数值不同,在四维空间中形成一个个的点。
以下是由DBSCAN自动聚类形成的图像,因4维空间难以在现实中呈现,故以2维的形式进行展示。
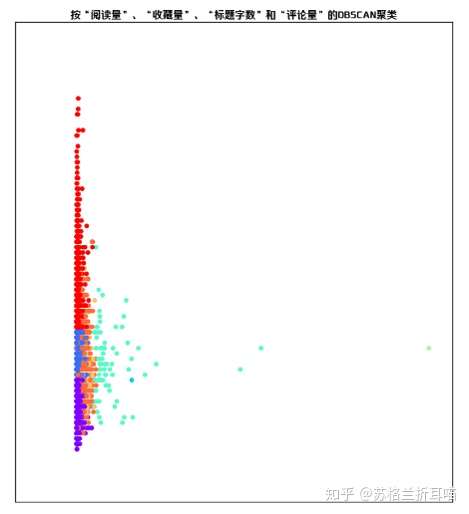
从上图可以看出,此次聚类中,有少数的异常点,由上面的描述型分析可知,阅读量极大的那几篇文章的“嫌疑”最大,现在在源数据中“揪出”它们,游街示众,然后再“除掉”。
去除掉上述异常点之后的聚类图谱:
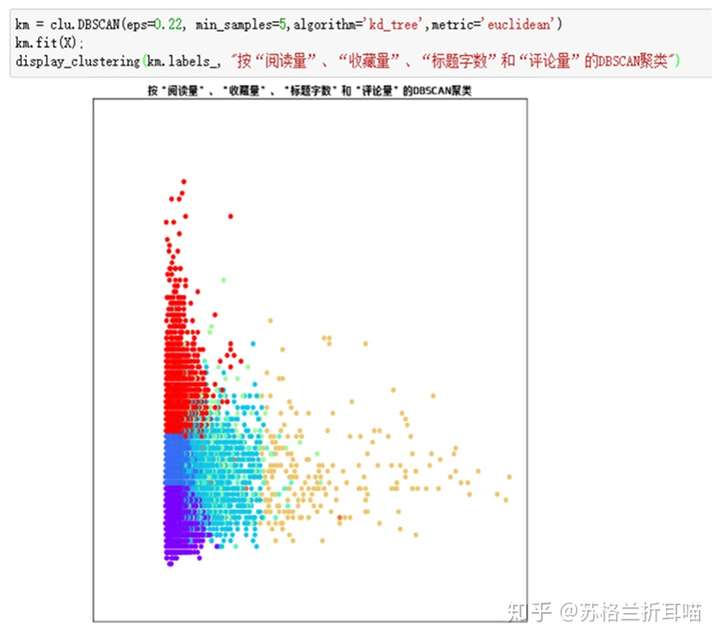
从上图中可以看出,虽然因为维度过高,不同类别簇群存在重合现象,但不同的颜色明显的将文章类别进行了区分,按照“阅读量”、“收藏量”、“评论量”、“标题字数”这4个维度进行的DBSCAN聚类可以分为5个类别。
(3) 阅读量与正文字数、标题字数之间的关联分析
接着,笔者分别对“阅读量”与“标题字数”、“正文字数”做了散点图分析,以期判断它们之间是否存在相关关系。
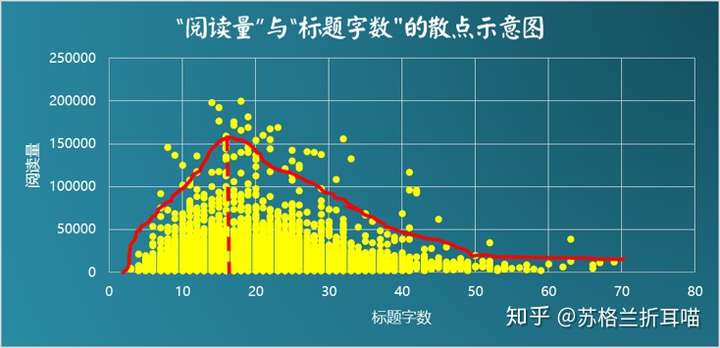
从上图来看,阅读量和标题字数之间并没有明显的线性相关性,标题字数及其对应数量的散点分布,近似形成了一条左偏态的正态曲线,从图像上印证了上面的描述性分析,而且更新了我们的认知:在10~30这个“标题字数”区间的文章数量最多,而标题字数过多未必是好事。
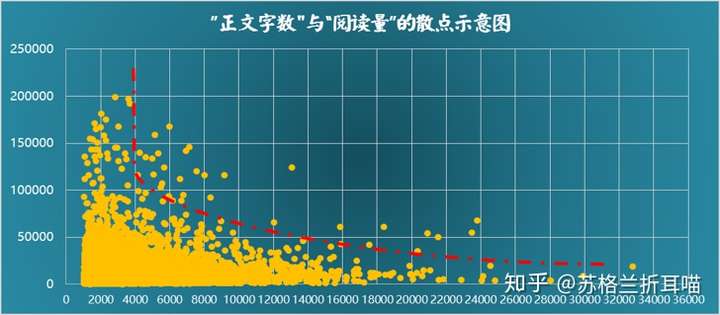
从上图可以看出,从1000字开始,阅读量和正文字数在大体上呈负相关关系,即文章字数越多,阅读量越小。由此看来,大家都比较喜欢短平快的“快餐式”阅读,篇幅太长的文章看起来太磨人。
6.1.3 热门文章特征分析
一篇文章的“收藏量”能在一定程度上反映读者对该文章的价值度的认可,较高的收藏量能代表该文章的质量属于上乘。而从一定数量的高收藏量文章中,我们又能间接的从中发掘出读者的阅读偏好,进而界定读者群体的某些特征。
在这部分,笔者筛选出收藏量大于1,000的文章,各栏目合计下来,不多不少,刚好60篇。以下是它们在各栏目下的数量分布情况:
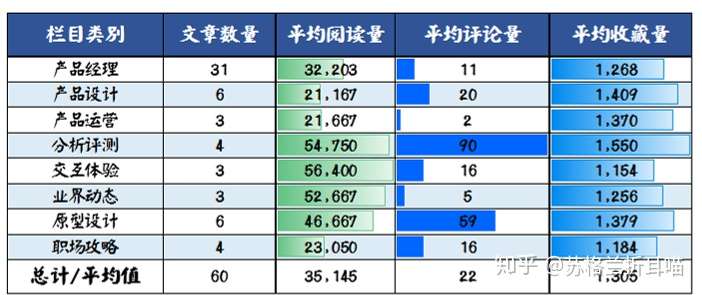
从上表中,笔者发现如下信息:
- “产品经理”栏目下收藏量过1,000的文章数量最多,占到半数;
- “分析评测”下的文章数量不多,但读者互动最多(平均评论量为90);
- “分析评测”、“交互体验”、“业界动态”、“原型设计”入围的文章数量不多,但它们的平均阅读量较高
以上3点仅是从数值型数据上获得的认知,但是这些热门文章到底有哪些特征,我们不得而知。由此,笔者统计了这些热门文章的标题中的高频词,并将其制成关键词云:

从上面的高频词,“Axure”、“干货”、“工具”、“新人”、“7天”、“速成”等高频词可以间接的推测出,这些文章的主要面向初学者(按照心理学上的“投射原理”,读者其实也大都是初学者),以干货类、工具类和方法论为主题,并透露出浓厚的“成功学气息”(如“速成”、“7天”、“必学”等词),具有这类标题特征的文章,堪称“眼球收割机”,初学者和小白们喜闻乐见,最是喜欢。
6.1.4 文本中一线~五线城市提及次数的地理分布
在该部分,笔者先列出了一个国内一、二、三、四、五线城市的城市名录,然后在经过分词处理的333,94篇文本数据中统计这些城市的提及次数(不包含简称和别称),最后制成一张反映城市提及次数的地理分布地图,进而间接地了解各个城市互联网的发展状况(一般城市的提及跟互联网产业、产品和职位信息挂钩,能在一定程度上反映该城市互联网行业的发展态势)。
经处理,制成的数据地图如下:
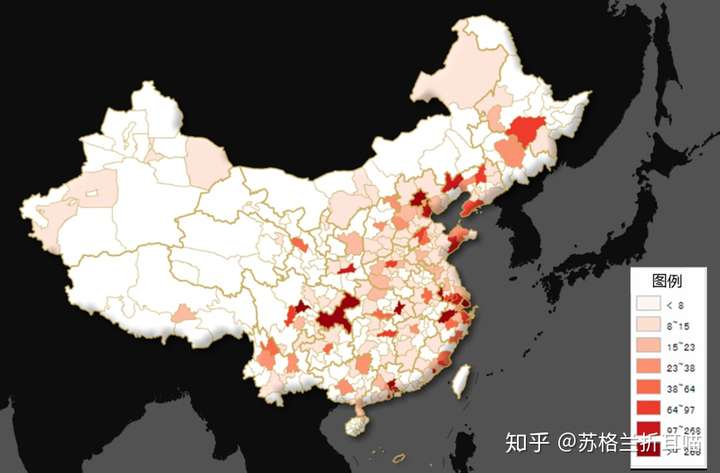
上图反映的结果比较符合常识,北上深广杭这些一线城市/互联网重镇的提及次数最多。其次是成都、天津、重庆、苏州和青岛这些二线城市,再次是哈尔滨、大连。
总结起来的一句废话就——互联网发达的城市主要集中在东南沿海。
上面的数据分析大多数是基于数值型数据的描述性分析,接下来,笔者将利用其中的文本数据做深入的文本挖掘。
6.2 针对“产品运营&数据分析”栏目的专项文本挖掘
因为笔者关注的领域主要是数据分析和产品运营,平时写的文章也大都集中在这两块,所以笔者把这两个板块的数据单独拎出来,从文本挖掘角度,做一系列由浅入深的数据分析。
6.2.1 高频词汇TOP200
首先是文本挖掘中最常规的高频词分析,笔者从中获取了TOP200词汇。

可以看到,大部分是跟“运营”息息相关的词汇,比如“用户”、“运营”、“内容”、“APP”、“营销”、“微信”等词汇。
单独看其中的高频词TOP30,可以发现,这些词大部分跟新媒体运营(“内容”、“微信”、“微博”、“文章”等)、用户(“用户”、“粉丝”、“需求”、“社群”、“客户”、“消费者”等)有关系。
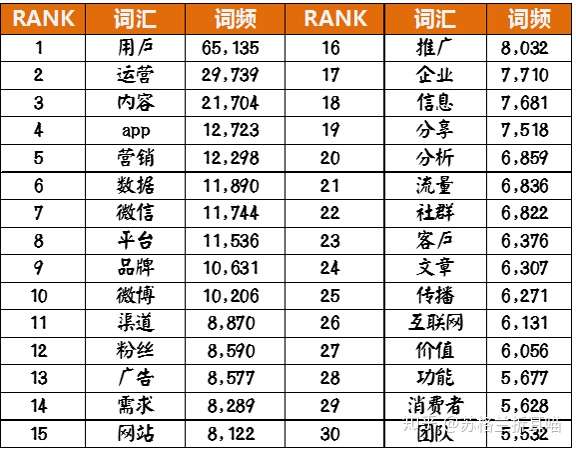
将这 TOP 200 高频词制成关键词云,直观地看到其中重要的信息。

6.2.2 Bicluster文本聚类分析
刚才笔者提到了基于关键词归纳主题的做法,在上面的高频词中,这种主题特征不甚明显,因而笔者采用更强有力的Bicluster文本聚类分析,从“数据分析&产品运营”的数千篇文章中“析出”若干“子主题”,并进行“发布年份”&“主题构成”之间的关联分析。
基于谱联合聚类算法(Spectral Co-clusteringalgorithm)的文档聚类,这部分的原理涉及到艰深的数学和算法知识,可能会引起小伙伴们的阅读不适感,如果是这样,请快速跳过,直接看后面的操作和结果。
先将待分析的文本经TF-IDF向量化构成了词频矩阵,然后使用Dhillon的谱联合聚类算法(Spectral Co-clusteringalgorithm)进行双聚类(Biclusters)。所得到的“文档-词汇”双聚类(Biclusters)会把某些文档子集中的常用词汇聚集在一起,由若干个关键词构成某个主题。
正式分析之前,先对保存在Excel中的文本数据做一定的预处理,使用“乾坤大挪移”,将Excel中的文本数据按年份一条条的归到不同的文件夹下面,具体步骤如下图所示:

做好预处理后,进行正式的Bicluster文本聚类,结果如下:

上面的分析结果中,Bicluster1的话题区分度不明显,且仅包含2个文档和16个关键词,所以排除掉这个主题,仅留下其他5个主题,排除噪声,从这些子话题中的主要关键词来归纳其要旨。
为了看得更清楚,笔者将这些数据整理成二维表格的形式:
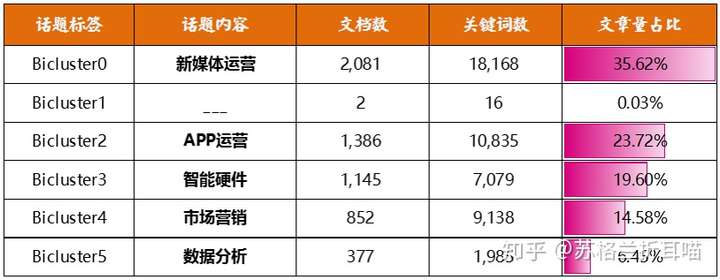
从上表可以看出,“数据分析&产品运营”下的子话题中,涉及“新媒体运营”的内容最多,占到文档总量的35.62%,其次是“APP运营”和“智能硬件”方面的话题,分别占到文档总量的23.72%和19.6%。而“数据分析”话题下的文档数最少。
将子话题和年份进行交叉分析,可以从中了解到各个子话题在各年份的信息分布量,从某种意义上讲,也就是话题热度。
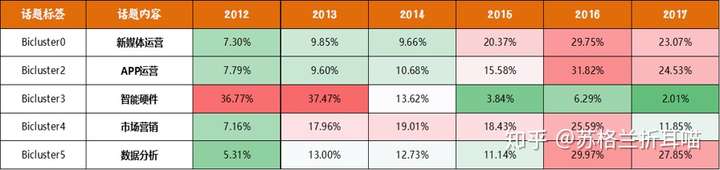
从上表可以看到,“智能硬件”的子话题在2012和2013年的热度最高,而“APP运营”和“数据分析”在2016和2017年开始火了起来,而“新媒体运营”在近3年也是风光无限。而单独从2016年来看,除了“智能硬件”方面的话题不火外,其他三个话题均有较高的热度,达到了近5年来热度峰值,看来2016年是个特殊的年份。
总体上,除了“智能硬件”这个子话题外,其他3个子话题热度都呈现出不断上升的趋势,当然,笔者假设2017年的4个月过完的时候还是如此。
6.2.3 基于“数据分析&产品运营”语境下的关联词分析
接下来进行的是基于Word Embedding的Word2vec词向量分析,将正文分词文本直接进行词向量模型训练,然后用来进行关联词分析。
Word2vec是Word Embedding(词嵌入)中的一种,是将文本进行词向量处理,将这些词汇映射到向量空间,变成一个个词向量(WordVector),以使这些词汇在便于被计算机识别和分析的同时,还具有语义上的关联性,而不仅仅是基于词汇之间的共现关系。类似的例子可以参看笔者之前的文章《用数据全方位解读<欢乐颂2>》、《以<大秦帝国之崛起>为例,来谈大数据舆情分析和文本挖掘》。
由此,通过Word2vec,我们可以查找到在“数据分析&产品运营”语境下的各个词汇的关联词。
先看看笔者最关心的“数据分析”,在“数据分析&产品运营”语境下有哪些词与之关联度最高,这里采用的method是’predict_output_word’,也就是把“数据分析”单个词当做语境,预测在“数据分析”语境下的关联词。(Report the probability distribution of the center word given the context words as input to the trainedmodel.)

在这种情况下,“数据分析”与自身的关联度不是1了,因为它可能在一段话里出现两次。后面关联度较高的词汇依次是“统计分析”、“数据挖掘”、“BI”、“Excel”等,从其中的几个数据工具(Growing IO、神策和友盟等)来看,厂家的品宣软文做的还是蛮好的。
再来看看“数据挖掘”+“运营”下的关联词有哪些,这次采用的method是’most_similar’,结果如下:

结果显示,这2个词的组合得到的关联词,除了“数据分析”外,还有“精细化”、“BI”、“统计分析”、“(用户)画像”、“数据模型”、“指标体系”、“产品策划”等关键词,它们是数据运营中涉及较多的概念。
下面是“pm”和“运营”的共同关联词,它们能较好的说明运营和产品之间的存在的某些“公共关系”。

本来,这两个职位由于跟进流程多,涉及面广,需要干各种“杂活”,因而很多产品或运营抱怨自己就是 “打杂”的。近一段时间,互联网界某些专家适时造出“全栈产品”和“全栈运营”这两个新概念,认为必须在这两个岗位上掌握更多的“斜杠”技能,熟谙相关领域的各个“工种”,最好精通各个流程。要做好这两个“非技术”的岗位,很多方面不仅要“略懂”,还要扮演“多面手”的角色,比如“技术开发”、“产品策划”等,如此才能在实际工作中“独当一面”。
接下来,笔者从中挑选出出90个跟“数据分析”具有较高关联度的词汇,看哪些词汇在该语境下中提及次数最多,以及这些词之间的共现关系(Co-occurrence Relation),通过词汇链接关系的多寡,找到重要性程度最高的词汇。

从字体大小来看, “数据”、“数据分析”、“运营”、“数据挖掘”“数据库”、“预测”等词链接的词汇最多,它们的重要性程度在这90个词汇中的重要性程度最高。
从颜色上来看,这90个词根据“关系亲疏(共现关系)”聚集为5个社群(Community),最为突出的是3个社群,分别是:
- 橙色系的“SPSS”和“SAS”,数据分析工具类;
- 紫色系的“数据”、“数据分析”、“数据挖掘”等,数据分析相关重要的概念;
- 绿色系的“营销”、“社会化媒体”、“监测”等,品牌营销类。
其中,“社会化媒体”与“营销”之间的线条最为明显,代表它们之间有很强的关联度---因为社会化媒体正式营销活动的载体,营销活动必须在各类社会化媒体(微信、微博、头条号等)实施。
6.2.4 Lexical dispersion plot(词汇分散图)
接下来,笔者想了解“产品运营&数据分析”栏目中的某些词在2012.05~2017.07之间的数量分布情况,以及它们出现的位置信息(the location of a word in the text),这时可以利用Lexicaldispersion plot(词汇分散图)进行分析,它可以揭示某个词汇在一段文本中的分布情况(Producea plot showing the distribution of the words through the text)。
笔者先将待分析的文本按时间顺序进行排列,分词后再进行Lexicaldispersion plot分析。因此,文本字数的累积增长方向与时间正向推移的方向一致。图中纵轴表示词汇,横轴是文本字数,是累加的;黑色竖线表示该词汇在文本中被提及一次,对应横轴能看到它所处的位置信息,空白则表示无提及。

从上图可以看出,在近4,500,000词汇量的文本中,“运营”、“微博”和“电商”在近6年里的提及次数极高,中间的间隙较少,贯穿始终,它们是作家谈论最多的三个词汇/话题。像“新媒体”、“微信公众号”、“用户运营”、“社群”等词汇,在头两年的提及热度不高,但后来居上,提及量呈现逐渐上涨的趋势。而“BI”、“CRM”在近六年内呈零星分布,提及量较少,在“产品运营&数据分析”栏目中属于冷门话题。
6.2.5 利用DTM模型(Dynamic Topic Models )分析主题下的热点变迁
上面的分析是针对某个词汇的时间动态分析,这里笔者要分析的是某个话题随时间的变迁情况(This implements topics that change over time)。笔者运用的模型是DTM模型 (Dynamic Topic Models ),它是“概率主题模型”家族的一员,用于对语料库中主题演变进行建模。
它基于这样的假设:
蕴含时间因素的主题,尽管它包含的关键词会随着时间的变化而产生相应的变化,但它如构成要素不断更新换代的“忒修斯之船(The Ship of Theseus)”一般,即使同一主题下的开端和末尾中的主题词没有一个是相同的,但还是原先的主题,保留有相同的语境。(By having a time-basedelement to topics, context is preserved while key-words may change.)
首先,从“产品运营&数据分析”中“解析”出如下6个子话题,它们是“运营”、“商业模式”、“流量运营&数据分析”、“品牌营销&数据分析”、“电商运营”和“内容运营”,如下表所示:
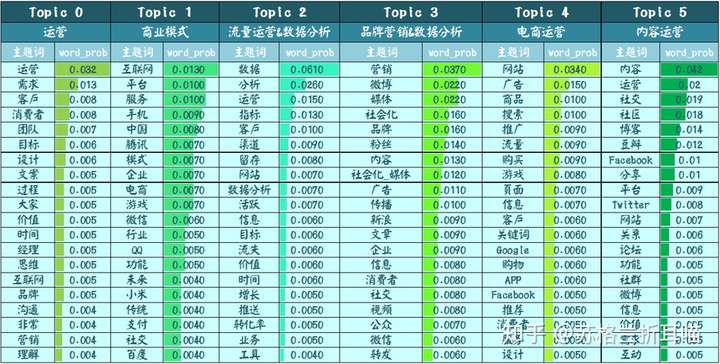
笔者对Topic2,也就是“流量运营&数据分析”在2012.05~2017.07间的话题变迁情况感兴趣,于是将这6年间出现的主题词重新整合,制成下面的热力图:
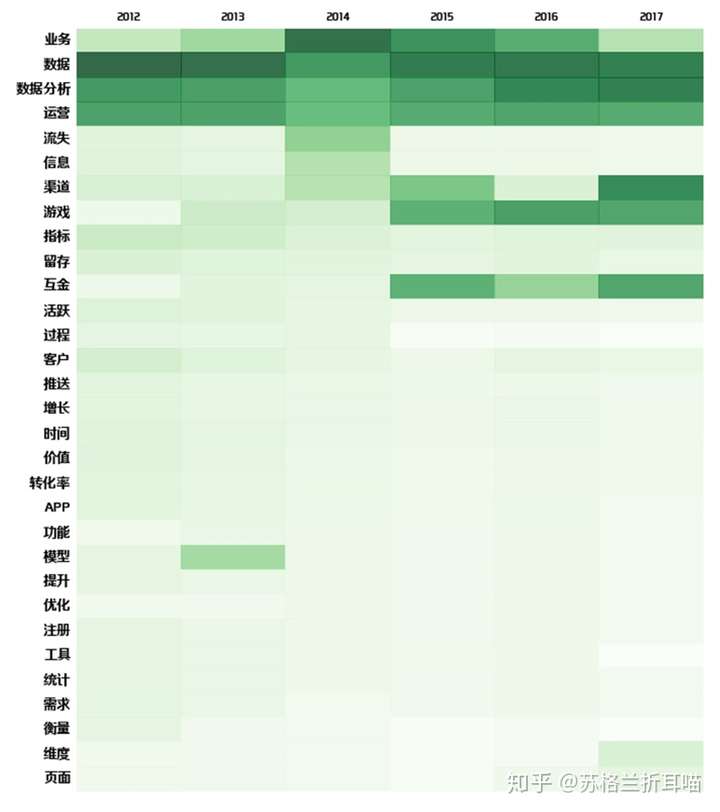
上图中纵轴是主题词,横轴是年份,颜色由浅入深代表数值的由小到大。从中可以明显的看出,“流量运营&数据分析”子话题下的“数据”、“数据分析”、“运营”和“业务”在该话题中始终处于“核心地位”,保持较高且稳定的word_prob值。而“渠道”、“游戏”、“互金”在近3年的word_prob值有了较大的提升,说明社区的作者在近期比较关注这3个主题词所代表的领域,间接表明它们在互联网中的话题热度呈现上升趋势。
6.2.6 利用ATM模型(Author-TopicModel)分析作家写作主题分布
在这个版块,笔者想了解“人人都是产品经理”上作家的写作主题,分析某些牛X作家喜欢写哪方面的文章(比如“产品运营”、“数据分析”、“新媒体运营”等)写作了啥,主题相似度的作者有哪些。
为此,笔者采用了ATM模型进行分析,注意,这不是自动取款机的缩写,而是author-topic model:
ATM模型(author-topic model)也是“概率主题模型”家族的一员,是LDA主题模型(Latent Dirichlet Allocation )的拓展,它能对某个语料库中作者的写作主题进行分析,找出某个作家的写作主题倾向,以及找到具有同样写作倾向的作家,它是一种新颖的主题探索方式。
首先,先从文本中“析出”若干主题,经过探索,10个主题的区分度正好。根据各个主题下的主题词特征,笔者将这10个主题归纳为 :“行业动态”、“电商运营”、“商业模式”、“产品运营”、“社交媒体”、“互金产品”、“数据运营”、“用户研究”、“产品设计”和“新媒体运营”。

同时,在数据处理的过程中,模型建立了作者(author)、主题(topic)及文档(document)之间的映射关联关系,以dict的形式保存数据。

模型训练完毕,先看看笔者自己的写作主题分布吧。值得注意的是,这里的文档数据经过甄选,并不是全部的文档数据,因此数量会少于网站上所看到的文章数。
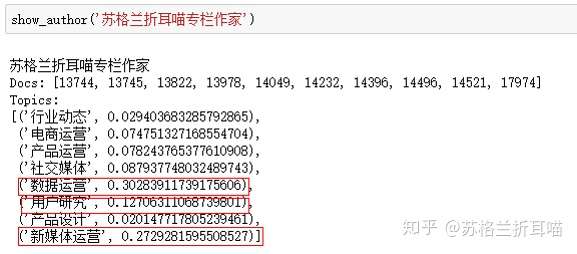
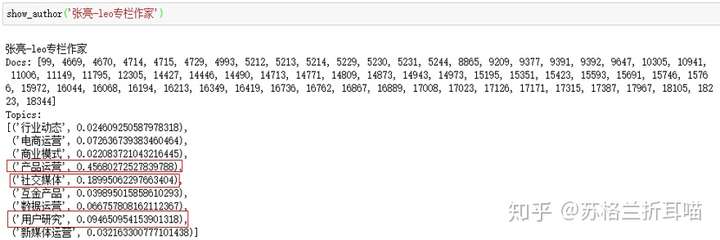
上面的“Docs”中的元素是文章对应的文档ID编号按照时间顺序排列的,“Topics”中的元素有两列,一列代表主题,一列代表主题的权重大小。很明显,笔者的写作主题主要集中在“数据运营”、“新媒体运营”和“用户研究”这3个主题上,有些直接从标题即可看出,有些“潜藏”在文章的正文论述之中。

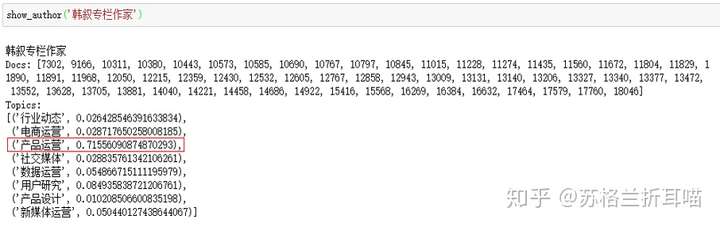
再看看运营大神韩叙的写作主题分布,很明显,他侧重于写产品运营方面的干货文章,而且写作主题很明确。
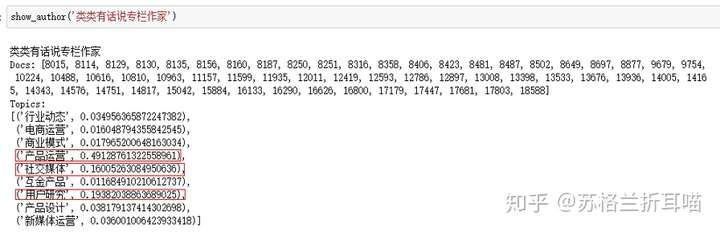
再看看另一位专栏作家类类的写作主题分布,他倾向于写产品运营、用户研究和社交媒体方面的文章,看过他文章的人都知道,他尤其擅长基于社区的用户运营。
再看看另一位运营大神——张亮,他的写作主题跟类类几近一致,也是产品运营、用户研究和社交媒体方面的干货分享。
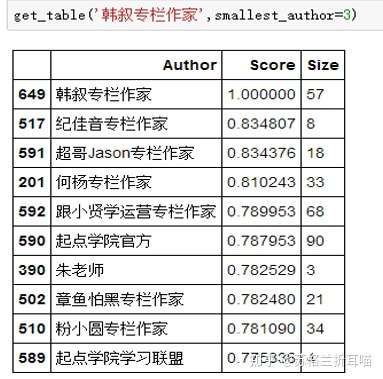
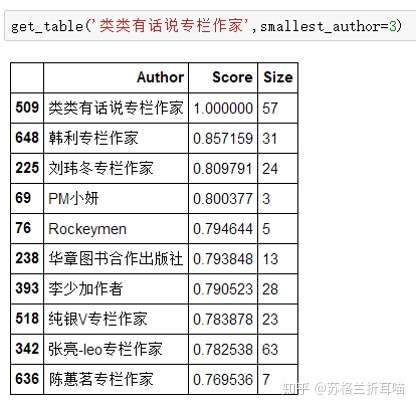
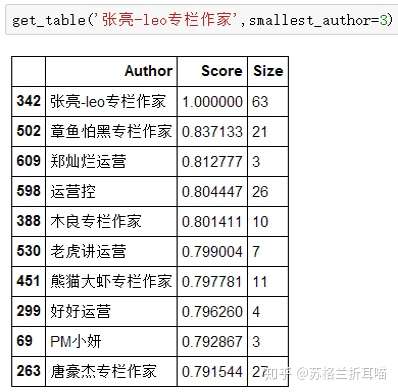
接下来,根据上述作者的写作主题分布,笔者找出与他们写作相似度最高的作家,为保持准确度,笔者有一个限制条件——发文数量不小于3篇。
结果以表格的形式展示,主要的维度有“作者(Author)”、“相似度得分(Score)”和“文档数量(Size)”。以下是“韩叙”“类类有话说”和“张亮-leo”的相似作者名单TOP10,限于篇幅,笔者就不做过多分析了。
6.2.7 LSI相似标题索引
最后,笔者想通过文章标题之间的语义相似关系来找到相同主题的文章,而这种语义相关性不仅仅是字面上的(不包含相同的词汇,但其中的词含义相近)。利过LSI(Latent Semantic Index,潜在语义索引)就可以做到这一点。
通过“词袋模型(bag-of-words)”将语句映射到特定的Vector Space Model (VSM)中,比较语句向量化后的余弦夹角值(介于0-1之间),值越大,就代表相似度越高。详细的原理推导,小伙伴们可以自行Google脑补。
从标题中找出主题相似的文章,检索感兴趣的内容,不仅仅是通过关键词检索,潜在语义分析。
在这里,笔者先后对如下三篇文章进行LSI语义索引:
- 当数据分析遭遇心理动力学:用户深层次的情感需求浮出水面(万字长文,附实例分析)
- 万字干货|10款数据分析“工具”,助你成为新媒体运营领域的“增长黑客”
- 数据运营实操 | 如何用聚类分析进行企业公众号的内容优化
结果显示如下:



从上面的索引结果可以看到,搜寻到的语句和原语句之间即使没有包含相同的词汇,但语义上是相关的,分别从属于4“用户研究”、“运营实操根据”和“内容运营”这三个话题。笔者通过这种文本相似度索引,就可以找到自己感兴趣的内容,进行更进一步的文本挖掘。
结语
限于篇幅,上述许多模型的用途/使用场景,笔者并未展开详说,比如Lexical Dispersion Plot、Bicluster文本聚类和DTM模型可以预测词汇和主题的热度,从而为写作选材和热点追踪提供参考;而LSI相似文本索引和ATM模型可以在内容创作中进行竞品分析,找到与笔者写作主题相近的作家和内容进行针对性的分析,知己知彼,做好自己的写作风格定位。
拿笔者的分析实践为例,在“数据分析”栏目中,采用上述分析手段,笔者发现相关文章大都是理论型和设想型的论述,缺少真实的数据分析实例支撑,真正投入到实际工作中的效果也未可知;同时,很多是常规的、基础性的数值型分析,介绍的工具则是Excel、SQL、SPSS,难以满足当今大数据背景下的数据分析实践。因此,笔者的写作风格倾向于“少许理论+实操”,尽量少扯“看起来对、看过就忘”的理论,在数据分析工具和方法的使用上尽量做到多样化,实例分析不为得出具体的结论,重在开拓读者的数据分析思路,授人以鱼。
最后,透过上面的外部数据分析实例,笔者还想再扯点无关的:
- 要厘清不同数据类型的特征,如本例中的数值型数据、文本型数据以及从中抽取的关系型数据,对其采用合适的分析思路和挖掘方法;
- 数据分析的方法要尽可能的多样化,如本例中采用了多种分析方法和模型,如交叉分析、高频词分析、关键信息抽取、词汇分散图分析和ATM模型等;
- 在分析层次上,以业务逻辑为轴线,由浅入深,由简入繁,由表及里,既有描述型的统计分析,也有诊断型的数据挖掘,还有基于演变规律(如动态主题模型)的预测型分析。
数据来源及参考资料:
1. 数据来源:人人都是产品经理,http://www.woshipm.com
2. Kemal Eren,An introduction to biclustering, http://www.kemaleren.com/an-introduction-to-biclustering.html
3. Ofir Pele and MichaelWerman, A linear time histogram metric for improved SIFT matching,2008.
4. Matt Kusner et al. From Embeddings To Document Distances,2015.
5. Michal Rosen-Zvi, Thomas Griffiths et al. The Author-Topic Modelfor Authors and Documents
6. David Hall et al. Studying the Historyof Ideas Using Topic Models
7. D.Blei and J. Lafferty. Dynamic topicmodels. In Proceedings of the 23rd International Conference on MachineLearning, 2006.
【Social listening实操】作为一个合格的“增长黑客”,你还得重视外部数据的分析!的更多相关文章
- 【Social listening实操】用大数据文本挖掘,来洞察“共享单车”的行业现状及走势
本文转自知乎 作者:苏格兰折耳喵 ----------------------------------------------------- 对于当下共享单车在互联网界的火热状况,笔者想从大数据文本挖 ...
- 【Social listening实操】从社交媒体传播和文本挖掘角度解读《欢乐颂2》
本文转自知乎 作者:苏格兰折耳喵 ----------------------------------------------------- 作为数据分析爱好者,本文作者将想从数据的角度去解读< ...
- 【Social listening实操】如何运用免费的大数据工具获得行业洞察?
本文转自知乎 作者:苏格兰折耳喵 ----------------------------------------------------- 当我们想要创业却对市场行情不甚了解,该如何迅速了解市场行情 ...
- 技术实操丨HBase 2.X版本的元数据修复及一种数据迁移方式
摘要:分享一个HBase集群恢复的方法. 背景 在HBase 1.x中,经常会遇到元数据不一致的情况,这个时候使用HBCK的命令,可以快速修复元数据,让集群恢复正常. 另外HBase数据迁移时,大家经 ...
- Python相关分析—一个金融场景的案例实操
哲学告诉我们:世界是一个普遍联系的有机整体,现象之间客观上存在着某种有机联系,一种现象的发展变化,必然受与之关联的其他现象发展变化的制约与影响,在统计学中,这种依存关系可以分为相关关系和回归函数关系两 ...
- 如何利用Social Listening从社会化媒体中“提炼”有价值的信息?
本文转自知乎 作者:苏格兰折耳喵 ----------------------------------------------------- 在本文中,笔者将会介绍大数据分析主要的处对象---社会化媒 ...
- ABP入门系列(1)——学习Abp框架之实操演练
作为.Net工地搬砖长工一名,一直致力于挖坑(Bug)填坑(Debug),但技术却不见长进.也曾热情于新技术的学习,憧憬过成为技术大拿.从前端到后端,从bootstrap到javascript,从py ...
- Selenium之unittest测试框架详谈及实操
申明:本文是基于python3.x及selenium3.x. unittest,也可以称为PyUnit,可以用来创建全面的测试套件,可以用于单元自动化测试(模块).功能自动化测试(UI)等等. 官方文 ...
- unittest测试框架详谈及实操(二)
类级别的setUp()方法与tearDown()方法 在实操(一)的例子中,通过setUp()方法为每个测试方法都创建了一个Chrome实例,并且在每个测试方法执行结束后要关闭实例.是不是觉得有个多余 ...
随机推荐
- mysql 性能
https://blog.csdn.net/zengxuewen2045/article/category/6388631 #sda 磁盘信息dstat -D sda 3 5 #找出系统瓶颈dstat ...
- git 克隆指定分支
git clone -b v2.8.1 https://git.oschina.net/oschina/android-app.git
- django 数据模型中 null=True 和 blank=True 有什么区别
null: If True, Django will store empty values as NULL in the database. Default is False. 如果为True,空值将 ...
- Android 如何让EditText不自动获取焦点 (转)
在项目中,一进入一个页面, EditText默认就会自动获取焦点. 那么如何取消这个默认行为呢? 在网上找了好久,有点 监听软键盘事件,有点 调用 clearFouse()方法,但是测试了都没有! x ...
- 在CAD二次开发中使用状态条按钮
Pane pane = new Pane(); pane.Enabled = true; pane.Text = "状态条按钮"; pane.ToolTipText = " ...
- [蓝桥杯ALGO-53.算法训练_最小乘积(基本型)
问题描述 给两组数,各n个. 请调整每组数的排列顺序,使得两组数据相同下标元素对应相乘,然后相加的和最小.要求程序输出这个最小值. 例如两组数分别为: -5和- 那么对应乘积取和的最小值应为: (-) ...
- C/C++中字符串和数字互转小结
一. 数字 转 char*型 1.sprintf函数(适合C和C++) 示例: char str[50]; int num = 345; sprintf(str,"%d",num) ...
- STL基础--算法(修改数据的算法)
修改元素的算法 copy, move, transform, swap, fill, replace, remove vector<int> vec = {9,60,70,8,45,87, ...
- C++11--20分钟了解C++11 (下)
20分钟了解C++11 9 override关键字 (虚函数使用) * * 避免在派生类中意外地生成新函数 */ // C++ 03 class Dog { virtual void A(int); ...
- Java自定义数据验证注解Annotation
本文转载自:https://www.jianshu.com/p/616924cd07e6 Java注解Annotation用起来很方便,也越来越流行,由于其简单.简练且易于使用等特点,很多开发工具都提 ...