EF大数据批量处理----BulkInsert
之前做项目的时候,做出来的系统的性能不太好,在框架中使用了EntityFramework,于是就在网上查资料,研究如何提高EF的性能。
在这分享一篇博客 批量操作提升EntityFramework的性能
里面提供了一个扩展库Entity Framework扩展库,在这里面找到了一些比较好的方法。下面主要介绍其中的一个方法—-批量添加BulkInsert。
这些扩展方法在哪里找?
在VS中新建EF之后,右键解决方案下的引用, 选择管理NuGet程序包,搜索Z.EntityFramework.Extensions并安装。
然后在类里面添加引用之后就可以直接点出来。
批量添加和EF本身自带的添加性能提高了多少?
下面咱们就用实例说话:
构造一个10W个studentinfo实例:
'''定义要添加数据的条数'''
int customerCount = 100000;
'''定义一个实体集合'''
List<studentInfo> customers = new List<studentInfo>();
'''想集合中添加数据'''
for (int i = 0; i < customerCount; i++)
{
studentInfo customer = new studentInfo()
{
name = "2" + i,
sex = "2" + i,
studentID = "2" + i,
age = "2"
};
customers.Add(customer);
Console.Write(".");
}用EF自带的添加方法将数据添加到数据库中,为了计算使用时间,加上StopWatch:
'''开始计时'''
Stopwatch watch = Stopwatch.StartNew();
using (EFTestEntities dbcontext = new EFTestEntities())
{
foreach (var entity in customers)
{
dbcontext.studentInfoes.Add(entity);
}
dbcontext.SaveChanges();
}
'''计时结束'''
watch.Stop();
'''输出时间'''
Console.WriteLine(string.Format("{0} customers are created, cost {1} milliseconds.", customerCount, watch.ElapsedMilliseconds));好了现在运行,等待中……
哎~~实在是没有耐心等待它运行完。
怎么办,减少数据量,先添加1000条:

还好,用时6157毫秒,6.157秒;
接着走,把数据量改为10000条:
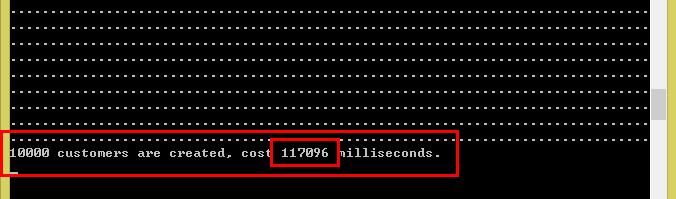
运行完了,共117096毫秒,117.096秒,将近两分钟。实在是没有耐心再测100000条的了,接下来直接测批量添加的方法。
将上面的添加到数据库中的代码换成下面的代码:
dbcontext.BulkInsert(customers);
dbcontext.BulkSaveChanges();直接上10W条:
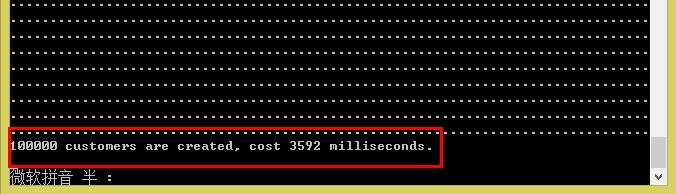
运行完了,共3592毫秒,3.592秒,真快啊~~
那么20W呢?
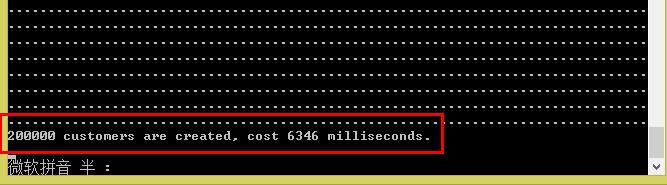
20W条数据运行完,才花了6346毫秒,6.346秒的时间。比上面的方法添加1000条的数据用的时间差不多,看来EF自带的添加方法慢,是毋庸置疑的了。
为什么扩展方法用的时间这么少?
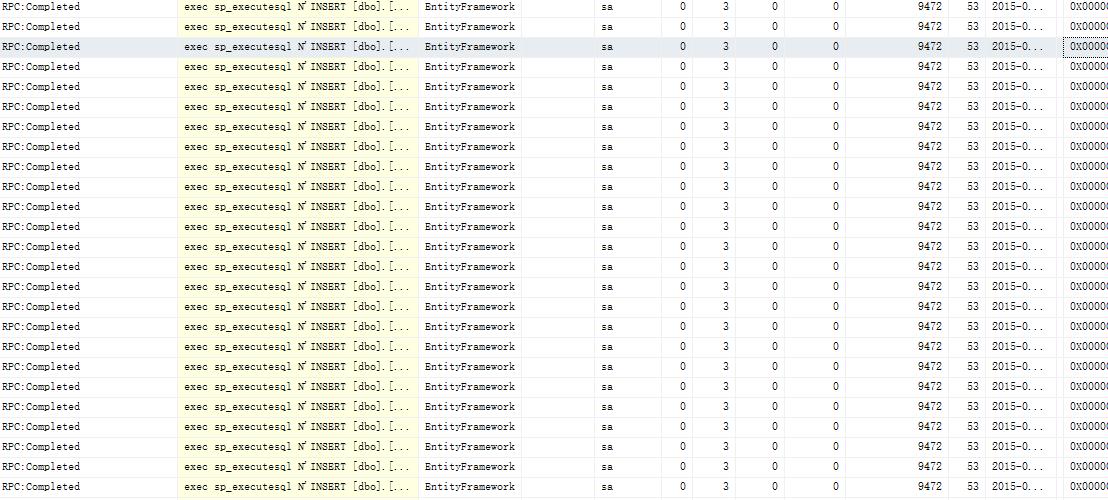
EF自带的方法,会增加与数据库的交互次数,一般地,EF的一个上下文在提交时会打开一个数据连接,然后把转换成的SQL语句一条一条的发到数据库端,然后去提交,下面的图片是我用SQL Server Profiler记录的和数据库交互的操作,这只是一小部分,试想,如果你的数据量达到万级别(更不用说百万,千万数据了),那对数据库的压力是很大的
而扩展方法运行时与数据库的交互是这样的:
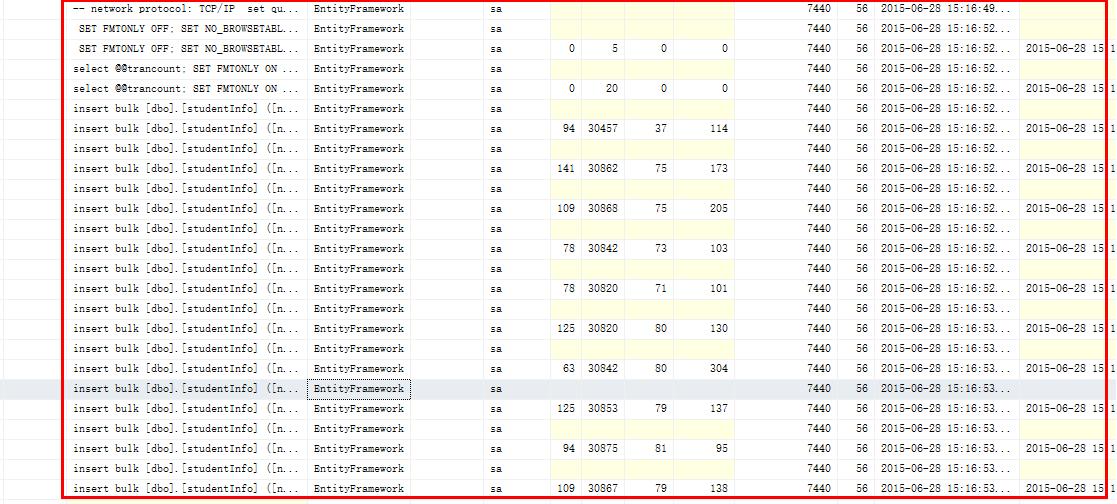
批量添加的方法是生成一条SQL语句,和数据库只交互一次。那为什么图片中有多条Insert语句呢,当你使用BulkInsert时,如果数据达到4万之前,那在SQL的解释时,也是很有压力的,有多情况下会超时,当然这与你的数据库服务器有关,但为了性能与安全,将Bulk操作变为分批提交,即将上W的数据进行分解,分用1W数据量提交一次,这样,对数据库的压力就小一些。
EF大数据批量处理----BulkInsert的更多相关文章
- EF大数据批量添加性能问题(续)
昨天在园子里发了一篇如题的文章EF大数据批量添加性能问题,就引来一大堆的吐槽,我认为知识就应该这样分享出来,不然总以为自己很了不起:再说说昨天那篇文章,很多自认为很牛逼的人都评论说把SaveChang ...
- EF大数据批量处理 EntityFrameWork下增加扩展方法
为EF操作方法添加扩展方法 BulkInsert 大致设计方式为 通过当前DbContext 获取当前连接字符串,调用连接字符串获取当前实体的所有字段及字段属性,映射到DataTable中 在调用Sy ...
- EF大数据批量添加性能问题
前几天做一个批量发消息的功能,因为要向消息表中批量写入数据,用的EF框架的插入方法:不用不知道,一用吓一跳:就10000条数据就耗时好几分钟,对应追求用户体验的我来说这是极不能容忍的,后来改为拼接SQ ...
- .net core利用MySqlBulkLoader大数据批量导入MySQL
最近用core写了一个数据迁移小工具,从SQLServer读取数据,加工后导入MySQL,由于数据量太过庞大,数据表都过百万,常用的dapper已经无法满足.三大数据库都有自己的大数据批量导入数据的方 ...
- c#几种数据库的大数据批量插入(SqlServer、Oracle、SQLite和MySql)
这篇文章主要介绍了c#几种数据库的大数据批量插入(SqlServer.Oracle.SQLite和MySql),需要的朋友可以了解一下. 在之前只知道SqlServer支持数据批量插入,殊不知道Ora ...
- 分享MSSQL、MySql、Oracle的大数据批量导入方法及编程手法细节
1:MSSQL SQL语法篇: BULK INSERT [ database_name . [ schema_name ] . | schema_name . ] [ table_name | vie ...
- java,大数据批量插入、更新
public void exec(Connection conn){ try { conn.setAutoCommit(false); Long beginTime = System.currentT ...
- C#中几种数据库的大数据批量插入
C#语言中对SqlServer.Oracle.SQLite和MySql中的数据批量插入是支持的,不过Oracle需要使用Orace.DataAccess驱动. IProvider里有一个用于实现批量插 ...
- C#:几种数据库的大数据批量插入
在之前只知道SqlServer支持数据批量插入,殊不知道Oracle.SQLite和MySql也是支持的,不过Oracle需要使用Orace.DataAccess驱动,今天就贴出几种数据库的批量插入解 ...
随机推荐
- Quartz定时任务详解一
以下是我在应用的的一个基本配置: #---------调度器属性---------------- org.quartz.scheduler.instanceName = TestScheduler o ...
- Avalon总线学习 ---Avalon Interface Specifications
Avalon总线学习 ---Avalon Interface Specifications 1.Avalon Interfaces in a System and Nios II Processor ...
- 代码编辑器之notepad++
引用及下载地址:http://www.iplaysoft.com/notepad-plus.html NotePad++ 优秀的支持语法高亮的开源免费编辑器绿色版下载 EditPlus,它始终是一款收 ...
- 查看耗时长,CPU 100% 的SQL
[session_id], [request_id], [start_time] AS '开始时间', [status] AS '状态', [command] AS '命令', dest.[text] ...
- InfluxDB 的UTC时间问题与简单的持续查询语句
原文:https://blog.csdn.net/Vblegend_2013/article/details/80904275 最近项目中使用了时序数据库InfluxDB 各方性能也是蛮强大的.但是唯 ...
- 使用C#调用PI-SDK进行基于PI的开发
一.概述 PI-SDK(Plant Information Software Develop Kit)是OSI公司提供的基于面向对象的访问PI数据库的软件开发工具包,它可以对以下数据库进行读写: ² ...
- Mysql 性能优化7【重要】sql语句的优化 慢查询
慢查询时间设置 慢查询日志分析工具 另一个慢查询日志分析工具 如何对sql进行特定的优化
- 数据仓库专题(21):Kimball总线矩阵说明-官方版
一.前言 Over the years, I have found that a matrix depiction of the data warehouse plan is a pretty goo ...
- win10和ubuntu16.04双系统时间同步
在win10安装了ubuntu双系统,发现在两个系统见时间相差8个小时,这是由于windows和和ubuntu对于从主板取得时间后的处理方式不同,如果你把位置设为上海,ubuntu总是把主板时间当作u ...
- 【问题解决】使用docker配置redis主从复制,不生效
不生效,解决 原因1:修改 bind 原因2: Slave即的db save失败,因为没有写权限