Django--ORM(模型层)-重点
一、ORM简介
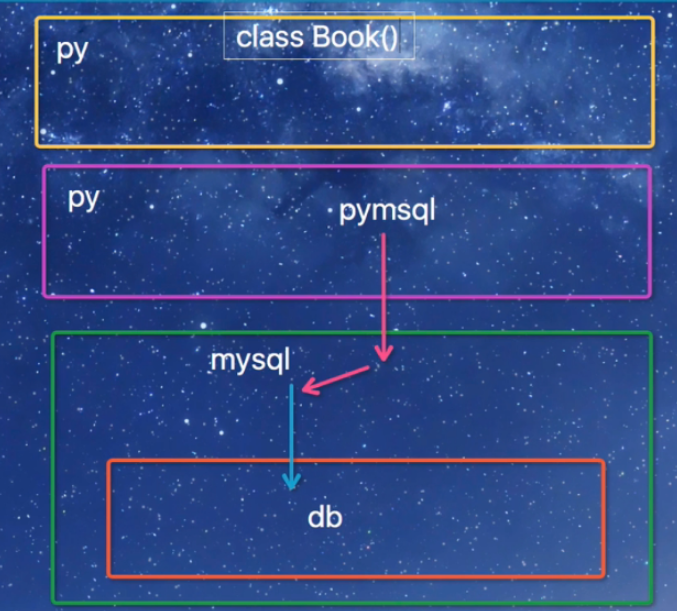
MVC或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,
通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的工作量,不需要面对因数据库变更而导致的无效劳动
ORM是“对象-关系-映射”的简称。
模块间有依赖关系必然存在耦合

数据库迁移也不影响,比如sql数据库转移到Oracle数据库
只能对这一层操作表操作,无法对数据库操作
二、单表操作--添加
先自己生成一个数据库:

1 创建模型
创建名为book的app,在book下的models.py中创建模型:
from django.db import models
# Create your models here. class Book(models.Model):
id=models.AutoField(primary_key=True)
title=models.CharField(max_length=32)
state=models.BooleanField()
pub_date=models.DateField()
price=models.DecimalField(max_digits=8,decimal_places=2)
publish=models.CharField(max_length=32)
2 更多字段和参数
每个字段有一些特有的参数,例如,CharField需要max_length参数来指定VARCHAR数据库字段的大小。还有一些适用于所有字段的通用参数。
这些参数在文档中有详细定义,这里我们只简单介绍一些最常用的:
<1> CharField
字符串字段, 用于较短的字符串.
CharField 要求必须有一个参数 maxlength, 用于从数据库层和Django校验层限制该字段所允许的最大字符数. <2> IntegerField
#用于保存一个整数. <3> FloatField
一个浮点数. 必须 提供两个参数: 参数 描述
max_digits 总位数(不包括小数点和符号)
decimal_places 小数位数
举例来说, 要保存最大值为 999 (小数点后保存2位),你要这样定义字段: models.FloatField(..., max_digits=5, decimal_places=2)
要保存最大值一百万(小数点后保存10位)的话,你要这样定义: models.FloatField(..., max_digits=19, decimal_places=10)
admin 用一个文本框(<input type="text">)表示该字段保存的数据. <4> AutoField
一个 IntegerField, 添加记录时它会自动增长. 你通常不需要直接使用这个字段;
自定义一个主键:my_id=models.AutoField(primary_key=True)
如果你不指定主键的话,系统会自动添加一个主键字段到你的 model. <5> BooleanField
A true/false field. admin 用 checkbox 来表示此类字段. <6> TextField
一个容量很大的文本字段.
admin 用一个 <textarea> (文本区域)表示该字段数据.(一个多行编辑框). <7> EmailField
一个带有检查Email合法性的 CharField,不接受 maxlength 参数. <8> DateField
一个日期字段. 共有下列额外的可选参数:
Argument 描述
auto_now 当对象被保存时,自动将该字段的值设置为当前时间.通常用于表示 "last-modified" 时间戳.
auto_now_add 当对象首次被创建时,自动将该字段的值设置为当前时间.通常用于表示对象创建时间.
(仅仅在admin中有意义...) <9> DateTimeField
一个日期时间字段. 类似 DateField 支持同样的附加选项. <10> ImageField
类似 FileField, 不过要校验上传对象是否是一个合法图片.#它有两个可选参数:height_field和width_field,
如果提供这两个参数,则图片将按提供的高度和宽度规格保存.
<11> FileField
一个文件上传字段.
要求一个必须有的参数: upload_to, 一个用于保存上载文件的本地文件系统路径. 这个路径必须包含 strftime #formatting,
该格式将被上载文件的 date/time
替换(so that uploaded files don't fill up the given directory).
admin 用一个<input type="file">部件表示该字段保存的数据(一个文件上传部件) . 注意:在一个 model 中使用 FileField 或 ImageField 需要以下步骤:
(1)在你的 settings 文件中, 定义一个完整路径给 MEDIA_ROOT 以便让 Django在此处保存上传文件.
(出于性能考虑,这些文件并不保存到数据库.) 定义MEDIA_URL 作为该目录的公共 URL. 要确保该目录对
WEB服务器用户帐号是可写的.
(2) 在你的 model 中添加 FileField 或 ImageField, 并确保定义了 upload_to 选项,以告诉 Django
使用 MEDIA_ROOT 的哪个子目录保存上传文件.你的数据库中要保存的只是文件的路径(相对于 MEDIA_ROOT).
出于习惯你一定很想使用 Django 提供的 get_<#fieldname>_url 函数.举例来说,如果你的 ImageField
叫作 mug_shot, 你就可以在模板中以 {{ object.#get_mug_shot_url }} 这样的方式得到图像的绝对路径. <12> URLField
用于保存 URL. 若 verify_exists 参数为 True (默认), 给定的 URL 会预先检查是否存在( 即URL是否被有效装入且
没有返回404响应).
admin 用一个 <input type="text"> 文本框表示该字段保存的数据(一个单行编辑框) <13> NullBooleanField
类似 BooleanField, 不过允许 NULL 作为其中一个选项. 推荐使用这个字段而不要用 BooleanField 加 null=True 选项
admin 用一个选择框 <select> (三个可选择的值: "Unknown", "Yes" 和 "No" ) 来表示这种字段数据. <14> SlugField
"Slug" 是一个报纸术语. slug 是某个东西的小小标记(短签), 只包含字母,数字,下划线和连字符.#它们通常用于URLs
若你使用 Django 开发版本,你可以指定 maxlength. 若 maxlength 未指定, Django 会使用默认长度: 50. #在
以前的 Django 版本,没有任何办法改变50 这个长度.
这暗示了 db_index=True.
它接受一个额外的参数: prepopulate_from, which is a list of fields from which to auto-#populate
the slug, via JavaScript,in the object's admin form: models.SlugField
(prepopulate_from=("pre_name", "name"))prepopulate_from 不接受 DateTimeFields. <13> XMLField
一个校验值是否为合法XML的 TextField,必须提供参数: schema_path, 它是一个用来校验文本的 RelaxNG schema #的文件系统路径. <14> FilePathField
可选项目为某个特定目录下的文件名. 支持三个特殊的参数, 其中第一个是必须提供的.
参数 描述
path 必需参数. 一个目录的绝对文件系统路径. FilePathField 据此得到可选项目.
Example: "/home/images".
match 可选参数. 一个正则表达式, 作为一个字符串, FilePathField 将使用它过滤文件名.
注意这个正则表达式只会应用到 base filename 而不是
路径全名. Example: "foo.*\.txt^", 将匹配文件 foo23.txt 却不匹配 bar.txt 或 foo23.gif.
recursive可选参数.要么 True 要么 False. 默认值是 False. 是否包括 path 下面的全部子目录.
这三个参数可以同时使用.
match 仅应用于 base filename, 而不是路径全名. 那么,这个例子:
FilePathField(path="/home/images", match="foo.*", recursive=True)
...会匹配 /home/images/foo.gif 而不匹配 /home/images/foo/bar.gif <15> IPAddressField
一个字符串形式的 IP 地址, (i.e. "24.124.1.30").
<16> CommaSeparatedIntegerField
用于存放逗号分隔的整数值. 类似 CharField, 必须要有maxlength参数.
常见字段和参数
更多参数:
(1)null 如果为True,Django 将用NULL 来在数据库中存储空值。 默认值是 False. (1)blank 如果为True,该字段允许不填。默认为False。
要注意,这与 null 不同。null纯粹是数据库范畴的,而 blank 是数据验证范畴的。
如果一个字段的blank=True,表单的验证将允许该字段是空值。如果字段的blank=False,该字段就是必填的。 (2)default 字段的默认值。可以是一个值或者可调用对象。如果可调用 ,每有新对象被创建它都会被调用。 (3)primary_key 如果为True,那么这个字段就是模型的主键。如果你没有指定任何一个字段的primary_key=True,
Django 就会自动添加一个IntegerField字段做为主键,所以除非你想覆盖默认的主键行为,
否则没必要设置任何一个字段的primary_key=True。 (4)unique 如果该值设置为 True, 这个数据字段的值在整张表中必须是唯一的 (5)choices
由二元组组成的一个可迭代对象(例如,列表或元组),用来给字段提供选择项。 如果设置了choices ,默认的表单将是一个选择框而不是标准的文本框,<br>而且这个选择框的选项就是choices 中的选项。
更多参数
3 settings配置
若想将模型转为mysql数据库中的表,需要在settings中配置:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME':'bms', # 要连接的数据库,连接前需要创建好
'USER':'root', # 连接数据库的用户名
'PASSWORD':'', # 连接数据库的密码
'HOST':'127.0.0.1', # 连接主机,默认本级
'PORT':3306 # 端口 默认3306
}
}
注意1:NAME即数据库的名字,在mysql连接前该数据库必须已经创建,而上面的sqlite数据库下的db.sqlite3则是项目自动创建 USER和PASSWORD分别是数据库的用户名和密码。
设置完后,再启动我们的Django项目前,我们需要激活我们的mysql。然后,启动项目,会报错:no module named MySQLdb 。这是因为django默认你导入的驱动是MySQLdb,
可是MySQLdb 对于py3有很大问题,所以我们需要的驱动是PyMySQL 所以,我们只需要找到项目名文件下的init,在里面写入:

import pymysql
pymysql.install_as_MySQLdb()
最后通过两条数据库迁移命令即可在指定的数据库中创建表 :
python manage.py makemigrations
python manage.py migrate




注意2:确保配置文件中的INSTALLED_APPS中写入我们创建的app名称
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
"book"
]
注意3:如果报错如下:
django.core.exceptions.ImproperlyConfigured: mysqlclient 1.3.3 or newer is required; you have 0.7.11.None
MySQLclient目前只支持到python3.4,因此如果使用的更高版本的python,需要修改如下:
通过查找路径C:\Programs\Python\Python36-32\Lib\site-packages\Django-2.0-py3.6.egg\django\db\backends\mysql 这个路径里的文件把
if version < (1, 3, 3):
raise ImproperlyConfigured("mysqlclient 1.3.3 or newer is required; you have %s" % Database.__version__)
注释掉 就OK了。
注意4: 如果想打印orm转换过程中的sql,需要在settings中进行如下配置:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
三、单表 - 添加 查询
url
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
path('index/', views.index),
]
view--方法一
from django.shortcuts import render, HttpResponse # Create your views here. from app01.models import Book # 导入Book对象 def index(request):
# 添加表记录 # 方式1: # 所有字段必须和modles的一一对应
book_obj = Book(
id=1,
title='pyhon红宝书',
state=True,
price=10,
pub_date='2012-02-21',
publish='人民出版社'
)
book_obj.save() # 相当于commit提交 return HttpResponse('<h1>数据操作成功</h1>')
启动Django---浏览器中输入


方法2:推荐使用
# 方式二 类对应表,表中字段对应类中属性
# create返回值就是当前生成表的对象记录
book_obj=Book.objects.create(title='php',price=100,pub_date='2018-11-12',publish='人民日报出版社') print(book_obj.title)
print(book_obj.price)
print(book_obj.pub_date)
四、查询表纪录--查询API
<1> all(): 查询所有结果 <2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 <3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,
如果符合筛选条件的对象超过一个或者没有都会抛出错误。 <4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 <5> order_by(*field): 对查询结果排序 <6> reverse(): 对查询结果反向排序 <8> count(): 返回数据库中匹配查询(QuerySet)的对象数量。 <9> first(): 返回第一条记录 <10> last(): 返回最后一条记录 <11> exists(): 如果QuerySet包含数据,就返回True,否则返回False <12> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列
model的实例化对象,而是一个可迭代的字典序列
<13> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 <14> distinct(): 从返回结果中剔除重复纪录
具体分析
1、all()
class Book(models.Model):
id=models.AutoField(primary_key=True)
title=models.CharField(max_length=32)
pub_date=models.DateField()
# 最对有8位,有两位小数 999999.99
price=models.DecimalField(max_digits=8,decimal_places=2)
publish=models.CharField(max_length=32) def __str__(self):# 调用Book返回title
return self.title
不加访问显示:

加上后:

# 1. all() 调用者:Book.objects 返回值QuerySet对象
book_list = Book.objects.all()
print(book_list) # [obj1, obj2, ....] for obj in book_list:
print(obj.title, obj.price) print(book_list[1].title)
print(book_list[1].price)

(2)first,last 返回第一条记录\最后一条记录
#(2)first last 调用者 queryset 对象 返回值 model对象
book=Book.objects.all().first()
book2=Book.objects.all()[0]
book3=Book.objects.all().last()
print(book,book2,book3)

(3)filter()---对应 where语句 过滤 调用者:
Book.objects 返回值QuerySet对象
#(3)filter()---对应 where语句 过滤 调用者:Book.objects 返回值QuerySet对象
# 它包含了与所给筛选条件相匹配的对象
book_list=Book.objects.filter(price=100)
print(book_list)
print(book_list.first()) 多个条件:
print(Book.objects.filter(title='go',price=100)) # <QuerySet [<Book: go>]>
return HttpResponse('ok')

(4)get()
返回与所给筛选条件相匹配的对象,返回结果有且只有一个如果符合筛选条件的对象超过一个或者没有都会抛出错误。
#(4) get() 有且只有一个查询结果时才有意义,查询有多个或者查询的没有结果--都报错
# 返回值model对象
book_obj=Book.objects.get(title='go')
print(book_obj.price)
(5)exclude()
#(5) exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象
# 意思是选出 title!='go'的数据
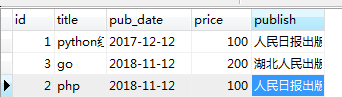
ret=Book.objects.exclude(title='go')
print(ret)

(6)order_by(*field): 对查询结果排序
#(6)order by 对查询结果排序-----------------
调用者QuerySet对象 返回值QuerySet对象
ret=Book.objects.all().order_by('id') # 当price相等时,用ID进行排序 默认升序 ret2=Book.objects.all().order_by('price','id') print(ret) print(ret2) # 降序排列 order_by('-id')

(8)count
# 7. count 调用者QuerySet对象 返回值int数字
ret = Book.objects.all().count() # 数字
print(ret)
(9)exits
#(8)exits 如果QuerySet包含数据,就返回True,否则返回False
ret = Book.objects.all()
ret1 = Book.objects.all().exists() # limit 1 取出一条就行
if ret:
print('ok') if ret1:
print('oK2')

(10) reverse():对查询结果反向排序
ret = Book.objects.all().order_by('id').reverse()
print(ret) # <QuerySet [<Book: linux>, <Book: go>, <Book: python红宝书>]>

(11)values--返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列
ret = Book.objects.all()
for i in ret:
print(i.title) # 遍历去查 很麻烦
ret = Book.objects.all().values('price')
print(ret)
# <QuerySet [{'price': Decimal('100.00')}, {'price': Decimal('100.00')}, {'price': Decimal('80.00')}]> ret = Book.objects.all().values('price','title')
print(ret)
# <QuerySet [{'price': Decimal('100.00'), 'title': 'python红宝书'}, {'price': Decimal('100.00'), 'title': 'go'}, {'price': Decimal('80.00'), 'title': 'linux'}]> ret = Book.objects.values('title') # 相当于 all().values()
print(ret)
# <QuerySet [{'title': 'go'}, {'title': 'linux'}, {'title': 'python红宝书'}]> print(ret[0].get('title')) # go 字典使用 .get 没有数据时 不会报错 # '''
# values() 工作原理
# temp[]
# for obj in Book.object.all()
# temp.append({"price"=obj.price})
# return temp
# '''


(12)values_list---它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
#(13)values_list 调用者 queryset 返回值 queryset 里面放着元祖
ret = Book.objects.all().values_list('price')
ret2 = Book.objects.all().values_list('price', 'title')
print(ret)
print(ret2)

区别:
多个值
"""
values: list字典
<QuerySet [{'price': Decimal('10.00'), 'title': 'pyhon红宝书'},
{'price': Decimal('100.00'), 'title': 'php'},
{'price': Decimal('100.00'), 'title': 'go'}]>
values_list: 元组
<QuerySet [(Decimal('10.00'), 'pyhon红宝书'),
(Decimal('100.00'), 'php'),
(Decimal('100.00'), 'go')]>
"""
(13)distinct-去重-----从返回结果中剔除重复纪录
ret = Book.objects.all().distinct() # id不同,不能去重
print(ret)

ret1 = Book.objects.all().values('price')
print(ret1)
ret = Book.objects.all().values('price').distinct() # 存在相同price,可以去重
print(ret)


# distinct 怎么用 配合着values() values_list()使用
ret = Book.objects.all().distinct() # 这么写没意义
print(ret)
明确每个方法的调用者 queryset 返回值 queryset
# 链式操作 返回的是queryset可以继续调用方法
Book.objects.all().filter().order_by().filter().reverse().first()
--------------------------------------------------------------------------
# 返回值model对象,只能进行点操作
book_obj=Book.objects.get(title='go')
print(book_obj.price)
queryset理解为字典或者列表里面放着的对象
五、单表查询之模糊查询
基于双下划线的模糊查询
Book.objects.filter(price__in=[100,200,300])
Book.objects.filter(price__gt=100)
Book.objects.filter(price__lt=100)
Book.objects.filter(price__range=[100,200])
Book.objects.filter(title__contains="python")
Book.objects.filter(title__icontains="python")
Book.objects.filter(title__startswith="py")
Book.objects.filter(pub_date__year=2012)
---------------------------------
# 1 大于
ret=Book.objects.filter(price__gt=100)
print('ret',ret)

# 2 小于
ret2 = Book.objects.filter(price__lt=200)
print('ret2',ret2)

# 3 某个区间的数据
ret3 = Book.objects.filter(price__gt=100,price__lt=200)
print('ret3',ret3)

# 4 以什么开头的数据
ret4 = Book.objects.filter(title__startswith='py')

# 5 以什么结尾
ret5 = Book.objects.filter(title__endswith='红宝书')
print('ret4',ret4)
print('ret5',ret5)

# 6 包含什么 大小写敏感
ret6=Book.objects.filter(title__contains='h')
print('ret6:',ret6)

# 7 包含什么大小写敏感
ret7=Book.objects.filter(title__icontains='H')
print('ret7:',ret7)

# 8 在什么里面
ret8 = Book.objects.filter(price__in=[100, 200, 50])
print('ret8:',ret8)

# 9 在什么范围内 100 >= x >= 50
ret9=Book.objects.filter(price__range=[50,100])
print('ret9',ret9)

# 10 在哪一年 哪一月
ret10 = Book.objects.filter(pub_date__year=2018)
print('ret10',ret10) # <QuerySet [<Book: go>, <Book: linuxO>]>

ret11 = Book.objects.filter(pub_date__year=2018,pub_date__month=11,pub_date__day=12)
print('ret11',ret11) # <QuerySet []>

六、单表之删除与修改表记录
删除方法就是 delete()。它运行时立即删除对象而不返回任何值。例如:
model_obj.delete()
# 1 删除 调用者 queryset 返回者 元祖
ret = Book.objects.filter(price=200).delete()
print(ret)

# 2 删除 调用者 model 对象 返回者 元祖
ret = Book.objects.filter(price=100).first().delete()
print(ret)

# 3 修改 调用者 queryset 返回者 int model 不能调 update
# ret = Book.objects.filter(title='php').update(title='python')
print('ret',ret)

ret = Book.objects.filter(price=100).update(title='lin')
print(ret) # model 不能调 update
ret = Book.objects.filter(price=80).first().update(title='liliaa')
print(ret) # 'Book' object has no attribute 'update'
练习:
1、图书管理系统 实现功能:book单表的增删改查
2 、查询操作练习
1 查询老男孩出版社出版过的价格大于200的书籍2 查询2017年8月出版的所有以py开头的书籍名称3 查询价格为50,100或者150的所有书籍名称及其出版社名称4 查询价格在100到200之间的所有书籍名称及其价格5 查询所有人民出版社出版的书籍的价格(从高到低排序,去重)Django--ORM(模型层)-重点的更多相关文章
- 4.Django|ORM模型层
ORM简介 MVC或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的 ...
- Python之路【第二十九篇】:django ORM模型层
ORM简介 MVC或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的 ...
- python 全栈开发,Day70(模板自定义标签和过滤器,模板继承 (extend),Django的模型层-ORM简介)
昨日内容回顾 视图函数: request对象 request.path 请求路径 request.GET GET请求数据 QueryDict {} request.POST POST请求数据 Quer ...
- Django基础(2)--模板自定义标签和过滤器,模板继承 (extend),Django的模型层-ORM简介
没整理完 昨日回顾: 视图函数: request对象 request.path 请求路径 request.GET GET请求数据 QueryDict {} request.POST POST请求数据 ...
- Django模板自定义标签和过滤器,模板继承(extend),Django的模型层
上回精彩回顾 视图函数: request对象 request.path 请求路径 request.GET GET请求数据 QueryDict {} request.POST POST请求数据 Quer ...
- 64、django之模型层(model)--建表、查询、删除基础
要说一个项目最重要的部分是什么那铁定数据了,也就是数据库,这篇就开始带大家走进django关于模型层model的使用,model主要就是操纵数据库不使用sql语句的情况下完成数据库的增删改查.本篇仅带 ...
- 【Django】模型层说明
[Django模型层] 之前大概介绍Django的文章居然写了两篇..这篇是重点关注了Django的模型层来进行学习. ■ 模型定义 众所周知,Django中的模型定义就是定义一个类,其基本结构是这样 ...
- django之模型层(model)--建表、查询、删除基础
要说一个项目最重要的部分是什么那铁定数据了,也就是数据库,这篇就开始带大家走进django关于模型层model的使用,model主要就是操纵数据库不使用sql语句的情况下完成数据库的增删改查.本篇仅带 ...
- Django之模型层(2)
Django之模型层(2) 一.创建模型 实例:我们来假定下面这些概念,字段和关系. 作者模型:一个作者由姓名和年龄. 作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息.作者详情 ...
- 第五章、Django之模型层----多表查询
目录 第五章.Django之模型层----多表查询 一.一对多字段增删改查 1.增 2.查 3.改 4. 删除 二.多对多的增删改查 1. 增 2. 改 3. 删 三.ORM跨表查询 四.正反向的概念 ...
随机推荐
- python函数 传参的多种方式 解读
1.函数的参数在哪里定义 在python中定义函数的时候,函数名后面的括号里就是用来定义参数的,如果有多个参数的话,那么参数之间直接用逗号, 隔开 案列: 2.带参数的函数调用: 函数定义了参数,那么 ...
- R语言—统计结果输出至本地文件方法总结
1.sink()在代码开始前加一行:sink(“output.txt”),就会自动把结果全部输出到工作文件夹下的output.txt文本文档.这时在R控制台的输出窗口中是看不到输出结果的.代码结束时用 ...
- MATLAB的一些小技巧
写论文要将图片保存为tiff格式,还要求dpi,还要标注,真是麻烦,下面的命令是最方便的程序化处理方式了 MATLAB text标注后 保存为 tiff 图片,图片到边框间无空白 clear all; ...
- 关于string.Template的简单介绍
一.简介 string模块定义了一种新字符串类型Template,它简化了特定的字符串置换操作. 何谓“简化”?我们可以先想一下我们之前比较常用的有关字符串的“置换”操作有哪些:一种是利用%操作符实现 ...
- [UE4]Switch on String,根据字符串决定条件分支,类似于高级语言中的switch语句
- React 懒加载组件
//组件第一次初始化的时候加载. import React, {PropTypes} from 'react'; //import AppComposer from './views/App/AppC ...
- c#属性 ——面向对象
String. Format(字符串格式化输出) 相当于Console.WriteLine(字符串格式化输出); 而String.Format是返回一个字符串 属性: 因为把字段全public,会非常 ...
- switch case 变量初始化问题
今天再写alsa的时候遇到一个稀奇古怪的问题,网上看了下资料,摘出来入下 代码: int main() { ; switch(a) { : ; break; : break; default: bre ...
- MySQL 之 MySQL数据库的优化
服务器物理硬件的优化 在挑选硬件服务器时,我们应该从下面几个方面着重对MySQL服务器的硬件配置进行优化,也就是说将项目中的资金着重投入到如下几处: 1.磁盘寻道能力(磁盘I/O),我们现在用的都是S ...
- 删除win7任务栏通知区域图标的方法
大家都知道程序运行后会在任务栏的通知区域显示表明正在运行,但是有很多失效的图标也会在此显示,那么怎么样删除那些没用的图标呢? 1.在开始运行里输入:regedit进入注册表编辑器 2.进入注册表编辑器 ...