MySQL千万级数据分区存储及查询优化
作为传统的关系型数据库,MySQL因其体积小、速度快、总体拥有成本低受到中小企业的热捧,但是对于大数据量(百万级以上)的操作显得有些力不从心,这里我结合之前开发的一个web系统来介绍一下MySQL数据库在千万级数据量的情况下如何优化提升查询速度。
一、基本业务需求
该系统包括硬件系统和软件系统,由中科院计算所开发的无线传感器网络负责实时数据的监测和回传到MySQL数据库,我们开发的软件系统负责对数据进行实时计算,可视化展示及异常事件报警监测。宫殿的温湿度等数据都存储在data表中,由于业务需要,data表中旧的数据要求不能删除,经过初步估算,一年的数据量大概为1200万条,之前的系统当数据量到达百万级时查询响应速度很慢,导致数据加载延迟很大,所以很有必要进行数据库的优化查询,提升响应速度。
结合故宫温湿度监测系统EasiWeb 7.1的data表查询,这里主要从以下三个方面详解MySQL的分区优化技术:
(1)EasiWeb 7.1系统data表基于分表、分区和索引的优化方案对比。
(2)EasiWeb 7.1系统中采用的优化方案及实施步骤
(3)系统模拟产生1500万数据的优化前后对比测试
二、data表优化方案选择
针对故宫系统大数据量时提升响应速度及运行性能的问题,我们团队通过研究和论证,提出了三种方案:
2.1 data表分表存储,联表查询
原理解释
分表即将一个表结构分解为多个子表,这些子表可以同一个数据库下,也可以在不同的数据库下,查询的时候通过代码控制,生成多条查询语句,进行多项子表联查,最后汇总结果,整体上的查询结果与单表一样,但平均相应速度更快。
实现方式
采用merge分表,划分的标准可以选取时间(collectTime)作为参数。主表类似于一个壳子,逻辑上封装了子表,实际上数据都是存储在子表中。我们在每年的1月1日创建一个子表data_20XX,然后将这些子表union起来构成一个主表。对于插入操作,最新的数据将会被插入到最后一个子表中;对于查询操作,通过'data'主表查询的时候,查询引擎会根据查询语句口控制选取要查询的子表集合,实现等效查询。
优缺点
优点是merge分表可以很方便得实现分表,在进行查询的时候封装了查询过程,用户编写的代码较少。
缺点是破坏了data表的结构,并且在新建子表的时候由于定时器延迟,可能导致个别数据被错误的存储。
2.2 data表分区存储
原理解释
分区把存放数据的文件分成了许多小块,存储在磁盘中不同的区域,通过提升磁盘I/O能力来提升查询速度。分区不会更改data表的结构,发生变化的是存储方式。
实现方式
采用range分区,根据数据的时间字段(collectTime)实现分区存储,以年份为基准,不同的区域存储的是不同年份的数据,可以采用合并语句进行分区的合并,分区操作由MySQL暗箱完成,从用户的角度看,data表不会改变,程序代码无需更改。
优缺点
优点是range分区实现方便,没有破坏data表的结构,用户无需更改dao层代码和查询方式。而且可以提前预设分区,比如今年是2017年,用户可以将数据分区预设到2020年,方式灵活,便于扩充。
缺点是数据存储依赖于分区的存储磁盘,一旦磁盘损坏,则会造成数据的丢失。
2.3 data表更换为Myisam搜索引擎
原理解释
MySQL提供Myisam和InnoDB类型的搜索引擎,两种搜索引擎侧重点不同,可以根据实际的需要搭配使用,以达到最优的相应效果。Myisam引擎可以平均分布I/O,获得更快的速度,InnoDB注重事务处理,适合高并发操作。

图1 BTREE存储结构
从图中就可以看出,B+Tree的内部结点不存储数据,只存储指针,而叶子结点则只存储数据,不存储指针。并且在其每个叶子节点上增加了一个指向数据的指针。
MyISAM引擎的索引结构为B+Tree,其中B+Tree的数据域存储的内容为实际数据的地址,也就是说它的索引和实际的数据是分开的,只不过是用索引指向了实际的数据,这种索引就是所谓的非聚集索引。
实现方式
修改data表的搜索引擎为Myisam,其它数据表不做更改。
优缺点
Myisam优点数据文件和索引文件可以放置在不同的目录,平均分布I/O。缺点是不合适高并发操作,对事务处理(修改和删除操作)的支持较差。
InnoDB优点是提供了具有提交、回滚和崩溃恢复能力的事务安全,适合高并发操作的事务处理。缺点是处理效率相对Myisam较差并且会占用更多的磁盘空间以保留数据和索引。
由于data表主要涉及的是查询和插入操作,提高速度是第一需求,所以可以将data表的搜索引擎改为Myisam。
2.4 综合比较
实现方式
分表后的数据实际存储在子表中,总表只是一个外壳,merge分表编码较少,更改了表的结构。
分区后的数据存储的文件分成了许多小块,不更改表的结构。
提高性能
分表侧重点是数据分表存储,联表查询,注重提高MySQL的并发能力。
分区侧重于突破磁盘的读写能力,从而达到提高MySQL性能的目的。
实现的难易度
采用merge分表与range分区两种方式难易度差不多,如果是用其他分表方式就比分区更为复杂。
range分区实现是比较简单的,建立分区的表和平常的表没有什么区。
两种方式基本上对开发端代码都是透明的。
三、最终采用的优化思路
故宫系统中的data表并发访问量不大,所以通过分表提高访问速度和并发效果不太显著,而且还可能破坏原有表的结构。而分区可以提高磁盘的读写能力,配合Myisam搜索引擎可以很大幅度提升查询速度。
所以我们采用data表分区存储+Myisam搜索引擎+建立索引的方式来优化数据库的查询
四、实施步骤及相关操作简介
实施步骤
1、将data表的搜索引擎由InnoDB更改为MyISAM
ALTER TABLE `data` ENGINE=MyISAM;
2、建立以collectime、originAddr字段的BTREE索引
ALTER TABLE `data`
ADD INDEX `collectTime` (`collectTime`) USING BTREE ,
ADD INDEX `nodeId` (`originAddr`) USING BTREE ;
3、分区之前将collectTime由char类型改为datetime/date类型,才能进行分区操作(注:char类型不支持分区操作)。
ALTER TABLE `data`
MODIFY COLUMN `collectTime` datetime NOT NULL AFTER `ID`;
4、采用range分区可以保证分区均匀
注:这里由于最早的数据从12年开始,我们采用了半年分一个区,预分区到2021年1月份,实际分区结合具体情况而定。
ALTER TABLE `data`
partition by range(to_days(collectTime))
(
partition P0 values less than (to_days('2012-01-01')),
partition P1 values less than (to_days('2012-07-01')),
partition P2 values less than (to_days('2013-01-01')),
partition P3 values less than (to_days('2013-07-01')),
partition P4 values less than (to_days('2014-01-01')),
partition P5 values less than (to_days('2014-07-01')),
partition P6 values less than (to_days('2015-01-01')),
partition P7 values less than (to_days('2015-07-01')),
partition P8 values less than (to_days('2016-01-01')),
partition P9 values less than (to_days('2016-07-01')),
partition P10 values less than (to_days('2017-01-01')),
partition P11 values less than (to_days('2017-07-01')),
partition P12 values less than (to_days('2018-01-01')),
partition P12 values less than (to_days('2018-07-01')),
partition P12 values less than (to_days('2019-01-01')),
partition P12 values less than (to_days('2019-07-01')),
partition P12 values less than (to_days('2020-01-01')),
partition P12 values less than (to_days('2020-07-01')),
partition P12 values less than (to_days('2021-01-01')),
)
5、分区情况查询
SELECT * FROM
INFORMATION_SCHEMA.partitions
WHERE
TABLE_SCHEMA = schema()
AND TABLE_NAME='data';
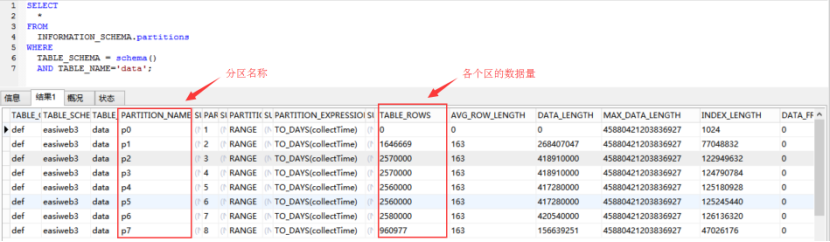
图2 查看分区信息
相关操作简介
1、由于range分区函数无法识别char型字段,所以要在分区之前将collectTime由char类型改为datetime类型,才能进行range分区操作。
2、采用range分区时,要用to_days(collectime)的分区方式,采用这种方式,在查询的时候只会在相应的分区查找,而如果不加to_days(),在查询的时候,会对全表进行扫描。
3、分区优化后,查询速度提升主要体现在非跨区查询的时候,当查询条件均属于一个区域时,数据库可以快速定位到所查分区,而不会扫描全表。
4、每次插入数据的时候,数据库会判定对应的collectTime属于哪个分区,从而存储到对应的分区中,不会影响其它分区。
五、1500万数据测试对比
1.经过数十次的多条件跨区与不跨区查询测试,相比没有做优化的data表,优化后查询速度提升90%以上。
2、不跨区域查询响应速度<=0.5s,跨区查询在第一次比较慢,但之后在翻页查询的时候,相应速度<=1s。
3、查询的时候由于计算机性能差异,所以同样的查询在不同的机器上查询速度会有所不用,我们采用的测试环境为i7 4500U酷睿 2核 4线程处理器 8G RAM 普通硬盘。
表1 data表查询对比测试结果
|
编号 |
测试条件 |
collectTime字段 |
优化前 查询时间 |
优化后 查询时间 |
|
1 |
NodeID,data1,data2,collectTime |
2017/1/19—2017/4/19 |
2.59s |
0.74s |
|
2 |
NodeID,data1,data2,collectTime |
2017/1/19—2017/7/19 |
16.64s |
0.96s |
|
3 |
NodeID,data1,data2,collectTime |
2016/8/19—2017/2/19 |
34.3s |
2.49s |
|
4 |
NodeID,data1,data2,collectTime |
2016/1/19—2017/1/19 |
46.52s |
2.50s |
|
5 |
NodeID,data1,data2,collectTime |
2015/2/19—2017/3/19 |
78.12s |
3.73s |
|
6 |
NodeID,data1,data2,collectTime |
2015/3/19—2017/4/19 |
250.33s |
4.42s |
|
7 |
NodeID,data1,data2,collectTime |
2015/1/19—2017/4/19 |
226.10s |
4.39s |
|
8 |
NodeID,data1,data2,collectTime |
2014/4/19—2017/4/19 |
410.22s |
5.50s |
|
9 |
NodeID,data1,data2,collectTime |
2014/2/19—2017/4/19 |
437.50s |
5.50s |
|
10 |
NodeID,data1,data2,collectTime |
2014/1/19—2017/4/19 |
558.05s |
5.70s |
|
11 |
NodeID,data1,data2,collectTime |
2012/4/19—2017/4/19 |
--(响应时间过长) |
8.70s |
六、测试查询数据部分截图
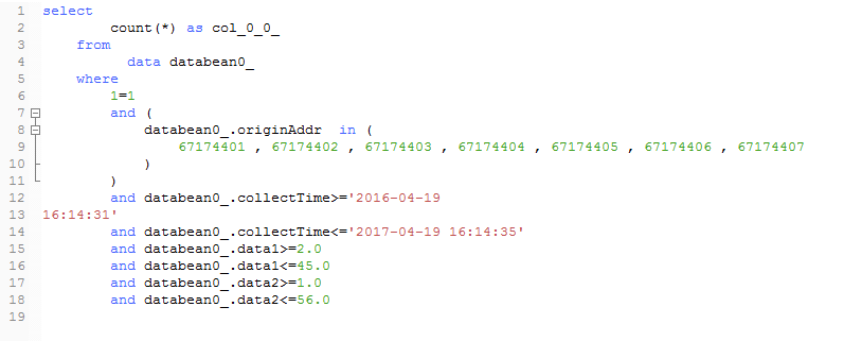
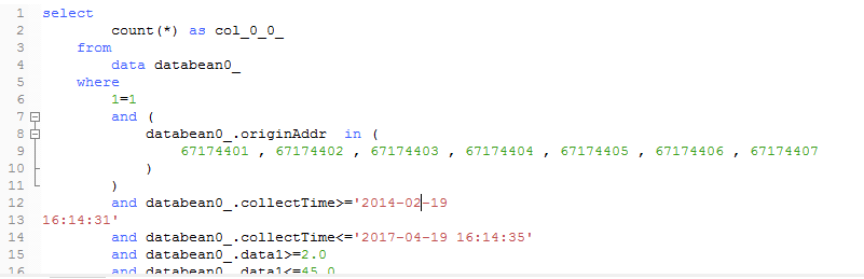
MySQL千万级数据分区存储及查询优化的更多相关文章
- (转载)MYSQL千万级数据量的优化方法积累
转载自:http://blog.sina.com.cn/s/blog_85ead02a0101csci.html MYSQL千万级数据量的优化方法积累 1.分库分表 很明显,一个主表(也就是很重要的表 ...
- mysql千万级数据量查询出所有重复的记录
查询重复的字段需要创建索引,多个条件则创建组合索引,各个条件的索引都存在则不必须创建组合索引 有些情况直接使用GROUP BY HAVING则能直接解决:但是有些情况下查询缓慢,则需要使用下面其他的方 ...
- Mysql千万级数据删除实操-企业案例
某天,在生产环节中,发现一个定时任务表,由于每次服务区查询这个表就会造成慢查询,给mysql服务器带来不少压力,经过分析,该表中绝对部分数据是垃圾数据 需要删除,约1050万行,由于缺乏处理大数据的额 ...
- mysql 千万级数据查询效率实践,分析 mysql查询优化实践--本文只做了一部分,仅供参考
数据量, 1300万的表加上112万的表 注意: 本文只做了部分优化,并不全面,仅供参考, 欢迎指点. 请移步tim查看,因为写的时候在tim写的,粘贴过来截图有问题,就直接上链接了. https ...
- MySQL 千万 级数据量根据(索引)优化 查询 速度
一.索引的作用 索引通俗来讲就相当于书的目录,当我们根据条件查询的时候,没有索引,便需要全表扫描,数据量少还可以,一旦数据量超过百万甚至千万,一条查询sql执行往往需要几十秒甚至更多,5秒以上就已经让 ...
- mysql千万级数据优化查询
我们在做一个项目,一个网站或一个app时,用户量巨增,当使用的mysql数据库中的表数据达到千万级时,可以从以下方面考滤优化: 1.在设计数据库表的时候就要考虑到优化 2.查询sql语句上的优化 3. ...
- MYSQL千万级数据量的优化方法积累
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- mysql千万级数据量根据索引优化查询速度
(一)索引的作用 索引通俗来讲就相当于书的目录,当我们根据条件查询的时候,没有索引,便需要全表扫描,数据量少还可以,一旦数据量超过百万甚至千万,一条查询sql执行往往需要几十秒甚至更多,5秒以上就已经 ...
- 【转】Mysql千万级数据表结构修改
当需要对表进行ddl操作如加索引.增删列时,数据量小时直接在线修改表结构影响不大当表达到百万.千万数据就不能直接在线修改表结构 下面是具体的过程:1.备份数据select * from ih_orde ...
随机推荐
- PHP斐波那契数列
一个斐波那契数列的求法 1 1 2 3 5 8 13 21 34 55 要求写出算法 //数组法 function test($num){ $arr=[]; for($i=0;$i<=$nu ...
- react-native-echarts 安卓版打包后,部分手机图表不显示问题
1. 找到 node_modules\native-echarts\src\components\Echarts\tpl.html 文件 ,把它复制到 (android\app\src\main\a ...
- delphi RTTI 四 获取类属性列表
delphi RTTI 四 获取类属性列表 GetPropList(btn1.ClassInfo, tkAny, PropList) PropCount := GetTypeData(btn1.Cla ...
- 深度学习原理与框架-Tensorflow基本操作-变量常用操作 1.tf.random_normal(生成正态分布随机数) 2.tf.random_shuffle(进行洗牌操作) 3. tf.assign(赋值操作) 4.tf.convert_to_tensor(转换为tensor类型) 5.tf.add(相加操作) tf.divide(相乘操作) 6.tf.placeholder(输入数据占位
1. 使用tf.random_normal([2, 3], mean=-1, stddev=4) 创建一个正态分布的随机数 参数说明:[2, 3]表示随机数的维度,mean表示平均值,stddev表示 ...
- Java基础之用记事本编辑java代码运行,并且打成jar包后运行
使用记事本写java代码 1.在d盘新建一个记事本,名字叫做zhanzhuang.java,会询问不可用,是否继续,点击是 2.在里面编辑就如下内容,注意文件的名字要和 class 后面的名字相对应 ...
- iframe+form表单提交数据
<h6>基于iframe+Form表单</h6> <iframe id="iframe" name="ifra" onclick= ...
- CSS COLOR
CSS COLOR Color Review We've completed our extensive tour of the colors in CSS! Let's review the key ...
- ELK实时日志分析平台环境部署--完整记录(转)
在日常运维工作中,对于系统和业务日志的处理尤为重要.今天,在这里分享一下自己部署的ELK(+Redis)-开源实时日志分析平台的记录过程(仅依据本人的实际操作为例说明,如有误述,敬请指出)~ ==== ...
- 一个简单的dropdown(CSS+jquery)
by 司徒正美 .dropdown{ position: relative; } .dropdown div{ position: relative; width:200px; height:30px ...
- 如何设置java环境变量
以安装目录是E:\Program Files\Java\jDK1.7.0为例: