kappa系数
kappa计算结果为-1~1,通常kappa是落在 0~1 间,可分为五组来表示不同级别的一致性:
| 0.0~0.20 | 极低的一致性(slight) |
| 0.21~0.40 | 一般的一致性(fair) |
| 0.41~0.60 | 中等的一致性(moderate) |
| 0.61~0.80 | 高度的一致性(substantial) |
| 0.81~1 | 几乎完全一致(almost perfect) |
计算公式:

po是每一类正确分类的样本数量之和除以总样本数.
假设每一类的真实样本个数分别为a1,a2,...,aC,预测出来的每一类的样本个数分别为b1,b2,...,bC,总样本个数为n,则有:pe=(a1×b1+a2×b2+...+aC×bC) / (n×n).
举例分析:
学生考试的作文成绩,由两个老师给出 好、中、差三档的打分,现在已知两位老师的打分结果,需要计算两位老师打分之间的相关性kappa系数:
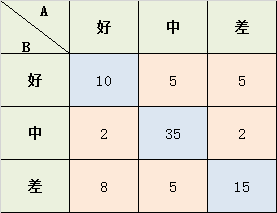
Po = (10+35+15) / 87 = 0.689
a1 = 10+2+8 = 20; a2 = 5+35+5 = 45; a3 = 5+2+15 = 22;
b1 = 10+5+5 = 20; b2 = 2+35+2 = 39; b3 = 8+5+15 = 28;
Pe = (a1*b1 + a2*b2 + a3*b3) / (87*87) = 0.455
K = (Po-Pe) / (1-Pe) = 0.4293578
from sklearn.svm import SVC
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix X,y = make_classification()
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3) svc = SVC()
svc.fit(X_train,y_train)
y_pred = svc.predict(X_test) result = confusion_matrix(y_test, y_pred) def kappa_coefficient(confusion_matrix):
"""
descibe:compute kappa coefficient
param confusion_matrix:matrix
return kappa coefficient
"""
import numpy as np P_0 = 0
for i in range(len(confusion_matrix)):
P_0 = P_0+confusion_matrix[i,i] a = []
b = []
for i in range(len(confusion_matrix)):
a.append(sum(confusion_matrix[i]))
b.append(sum(confusion_matrix[:,i])) P_e = sum(np.array(a)*np.array(b))/(sum(a)*sum(a))
kappa = (P_0/sum(a)-P_e)/(1-P_e) return kappa kappa_coefficient(confusion_matrix=result)
kappa系数的更多相关文章
- 10. 混淆矩阵、总体分类精度、Kappa系数
一.前言 表征分类精度的指标有很多,其中最常用的就是利用混淆矩阵.总体分类精度以及Kappa系数. 其中混淆矩阵能够很清楚的看到每个地物正确分类的个数以及被错分的类别和个数.但是,混淆矩阵并不能一眼就 ...
- kappa系数在评测中的应用
◆版权声明:本文出自胖喵~的博客,转载必须注明出处. 转载请注明出处:http://www.cnblogs.com/by-dream/p/7091315.html 前言 最近打算把翻译质量的人工评测好 ...
- kappa系数在大数据评测中的应用
◆版权声明:本文出自胖喵~的博客,转载必须注明出处. 转载请注明出处:http://www.cnblogs.com/by-dream/p/7091315.html 前言 最近打算把翻译质量的人工评测好 ...
- kappa 一致性系数计算实例
kappa系数在遥感分类图像的精度评估方面有重要的应用,因此学会计算kappa系数是必要的 实例1 实例2
- Kappa(cappa)系数只需要看这一篇就够了,算法到python实现
1 定义 百度百科的定义: 它是通过把所有地表真实分类中的像元总数(N)乘以混淆矩阵对角线(Xkk)的和,再减去某一类地表真实像元总数与被误分成该类像元总数之积对所有类别求和的结果,再除以总像元数的平 ...
- 【一致性检验指标】Kappa(cappa)系数
1 定义 百度百科的定义: 它是通过把所有地表真实分类中的像元总数(N)乘以混淆矩阵对角线(Xkk)的和,再减去某一类地表真实像元总数与被误分成该类像元总数之积对所有类别求和的结果,再除以总像元数的平 ...
- python数据分析所需要了解的操作。
import pandas as pd data_forest_fires = pd.read_csv("data/forestfires.csv", encoding='gbk' ...
- 基于sklearn的metrics库的常用有监督模型评估指标学习
一.分类评估指标 准确率(最直白的指标)缺点:受采样影响极大,比如100个样本中有99个为正例,所以即使模型很无脑地预测全部样本为正例,依然有99%的正确率适用范围:二分类(准确率):二分类.多分类( ...
- python基础全部知识点整理,超级全(20万字+)
目录 Python编程语言简介 https://www.cnblogs.com/hany-postq473111315/p/12256134.html Python环境搭建及中文编码 https:// ...
随机推荐
- linux二进制/十六进制日志文件如何查看和编辑
使用cat查看二进制,显示乱码 [root@localhost ~]# cat /var/log/wtmp ~~~reboot3.10.0-514.el7.x86_64 �YO#5~~~runleve ...
- streamdataio 实时数据分发平台
streamdataio 是一个实时的数据分发平台(当然是收费的,但是设计部分可以借鉴),我们可以通过这个平台 方便的拉取rest api 数据,或者发布数据到后端,streamdataio 可以帮助 ...
- Linux服务器定位CPU高占用率代码位置经历
http://blog.csdn.net/zhu19774279/article/details/51303000
- Java Dom4j XML用法总结
1.新建XML文档: Document doc = DocumentHelper.createDocument(); Element root = d ...
- mysql 5.45 以后需要 需要 安全套接字问题
错误异常:According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established ...
- pycharm开发django项目 static报404解决方法
settings文件中确保有以下配置 # Static files (CSS, JavaScript, Images)# https://docs.djangoproject.com/en/1.10/ ...
- Linux(CentOS7.0)下 C访问MySQL (转)
按语: 最近项目在云服务器上 centos6.8,安装了mysql5.5.39 server和client,但C连接不知所措: 后在官网下载了 devel.share .share-comp ...
- Jmeter ----Bean shell使用
一.什么是Bean Shell BeanShell是一种完全符合Java语法规范的脚本语言,并且又拥有自己的一些语法和方法; BeanShell是一种松散类型的脚本语言(这点和JS类似); BeanS ...
- Linux中chown和chmod的区别和用法
转载自:http://www.cnblogs.com/EasonJim/p/6525242.html chmod修改第一列内容,chown修改第3.4列内容: chown用法: 用来更改某个目录或文件 ...
- C#实现Google S2算法
S2其实是来自几何数学中的一个数学符号 S²,它表示的是单位球.S2 这个库其实是被设计用来解决球面上各种几何问题的.值得提的一点是,除去 golang 官方 repo 里面的 geo/s2 完成度目 ...