SQL Server 阻塞原因分析
这里通过连接在sysprocesses里字段值的组合来分析阻塞源头,可以把阻塞分为以下5种常见的类型(见表)。waittype,open_tran,status,都是sysprocesses里的值,“自我修复?”列的意思,就是指阻塞能不能自动消失。
5种常见的阻塞类型
| 类型 | waittype | open_tran | status | 自我修复 | 原因/其他特征 |
| 1 | 不为0 | >=0 | runnable | 是的,当语句运行结束后 | 语句运行的时间比较长,运行时需等待某些系统资源(如硬盘读写、CPU或内存等)。 |
| 2 | 0x0000 | >0 | sleeping | 不能,但是如果运行 KILL语句,这个链接能够很容易被终止 | 可能客户端遇到了一个语句执行超时,或者主动取消了上一语句的执行,但是没有回滚开启的事务,在SQL Trace里能够看到一个Attention事件 |
| 3 | 0x0000 0x0800 0x0063 |
>=0 | runnable | 不能。知道客户端吧所有结果都主动取走,或者主动断开连接,可以运行KILL语句去终止它,但是可能要花长达30秒 | 客户端没有及时把所有结果都取走,这时可能open_tran=0,事务隔离级别也为默认(READ COMMITTED),但这个连接还会持有锁资源 |
| 4 | 0x0000 | >0 | rollback | 是的 | 在SQL Trace里能够看到这个SPID已经发来了一个Attention事件,说明客户端已经遇到了超时,或者主动要求回滚事务 |
| 5 | 各种值都有可能 | >=0 | runnable | 不能,直到客户端取消语句运行或者主动断开连接。可以运行KILL语句终止它,但是可能要花长达30秒 | 应用程序运行中产生死锁,在SQL Server中以阻塞形式体现。Sysprocesses里阻塞和被阻塞的连接hostname值是一样的 |
下面详细介绍这些类型产生的原因,以及解决方法
解决方法:
要解决这一类阻塞,数据库管理员需要和数据库应用设计人员合作,共同解决以下问题。
- 语句本身有没有可优化的空间?
这里包括修改语句本身降低复杂度、修改表格设计、调整索引等。 - SQL Server整体性能如何?是不是有资源瓶颈影响了语句执行速度?
当SQL Server 遇到诸如内存、硬盘读写、CPU等资源瓶颈是,原来能很快完成的语句有可能会花很长时间。 - 如果语句天生就很复杂,无法调优(很多处理报表的语句就是这样),就须考虑怎样把这一类应用(一般就是数据仓库应用)从OLTP系统中隔离出来。
这一类阻塞的特征,就是问题连接早就进入了空闲状态(sysprocesses.status=’sleeping’和sysprocesses.cmd=’AWAITING COMMAND’),但是,如果检查sysprocesses.open_tran,就会发现它不为0,以及事务没有提交。这类问题很多都是因为应用端遇到一个执行超时,或者其他原因,当时执行的语句被提前终止了,但是连接还保留着。应用没有跟随发来的事务提交或回滚指令,导致一个事务被遗留在SQL Server里。
遇到这类问题,许多使用者会误以为是SQL Server端什么地方没有处理好。其实,执行超时(command timeout)完全是一个客户端的行为。当客户端应用向SQL Server发来语句执行请求时,自己会有一个执行超时设置。一般ADO或ADO.NET的连接超时时限是30秒。如果30秒以内SQL Server没有完成语句返回任何结果,客户端就会发送一个Attention的消息给SQL Server,告诉SQL Server它不想继续等下去了。SQL Server收到这个消息后,会终止当前正在运行的语句(或批处理)。但是,为了维护客户端的逻辑,SQL Server默认不会自动回滚或提交这个连接已经打开的事务,而是等待客户端的后续决定。如果客户端不发来回滚或提交指令,SQL Server会永远的把这个事务保持下去,直到客户端断开连接为止。
这里可以用下面这个实验来模拟这个问题。在Management Studio里创建一个连接到SQL Server,运行下面的批处理语句:

use sqlnexus
go
BEGIN TRAN
SELECT *
FROM ReadTrace.tblInterestingEvents
WITH(HOLDLOCK) SELECT
*
FROM sysobjects s1,sysobjects
s2 COMMIT TRAN
由于使用了HOLDLOCK参数,第一句SELECT会在运行结束后,在表格上维持一个TAB的S锁。如果批处理全部完成,这个锁会在提交事务的时候释放。但是第二句的SELECT会执行很久。请在等待3~4秒钟以后取消执行。然后运行下面的语句,检查open_tran和锁的情况。
SELECT @@TRANCOUNT
GO sp_lock GO
通过结果(见图)可以得知:
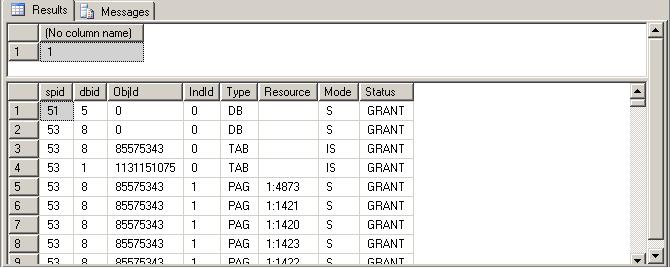
(1) 批处理被取消的时候,“COMMIT TRAN”这条语句没有被执行到。SQL Server没有对“BEGIN TRAN”开启的那个事务做任何处理,只保持其活动的状态。
(2) 第一句SELECT带来的锁由于事务没有结束,所以锁还保持着(objID=85575343, Type=TAB, Mode=IS)。
现在,如果有其他连接要修改ReadTrace.tblInterestingEvents这张表,就会被阻塞住。
解决办法:
1. 应用程序本身必须意识到审核语句都有可能遇到意外终止情况,做好错误处理工作。这些工作包括
a) 在做SQL Server调用的时候,必须加上错误捕捉和处理语句
SQL Server客户端驱动程序(包括ODBC和OLE DB)当语句执行遇到意外终止(包括超时)的时候,都会向应用返回错误信息。客户端在捕捉到错误信息时。除了做记录以外(这对问题定位非常有帮助),还要运行下面这句话,把没有提交的事务回滚掉。
IF @@TRANCOUNT>0 ROLLBACK TRAN
有些程序员会问,我在T-SQL批处理里已经写了T-SQL层面的错误捕捉和处理语句(IF @@ERROR<>0 ROLLBACK TRAN),还有必要让应用程序再做一遍么?需要意识到的是,有些异常(比如超时)终止的是整个T-SQL批处理的执行,而不仅仅是当前语句。所以当这些异常发生的时候,T-SQL层面错误捕捉和处理语句很可能也一起被取消了。它们不能发挥想象中的作用。在应用程序里的错误捕捉和处理语句是必不可少的。
b) 设置连接属性“SET SACT_ABORT ON”
当SET SACT_ABORT为ON时,如果执行T-SQL语句产生运行错误,整个事务将会终止并回滚
当SET SACT_ABORT为OFF时,处理方法不是唯一的。有时只回滚产生错误的T-SQL语句,而事务将继续进行处理。如果错误很严重,及时SET SACT_ABORT 为OFF,也可能回滚整个事务。OFF是默认设置。
如果没有办法很快规范应用程序的错误捕捉和处理语句,一个最快的方法就是在每个连接建立以后,或者是容易出问题的存储过程的开头,运行“SET XACT_ABORT ON”,让SQL Server帮助应用程序回滚事务。
c) 考虑是否要关闭连接池
一般的SQL Server应用都会使用连接池来得到良好的性能。如果有一个连接忘记把事务关闭就推出连接,那么这个连接会被交还给连接池,但是这个时候事务不会被清理。客户端驱动程序会在这个连接下一次被重用的时候(又有新的用户要建立连接),发一句sp_reset_connection命令清理当前连接上次遗留下来的所有对象,包括回滚未提交的事务。如果连接交还给连接池以后很久都没有被重用,那它的事务就会持续长时间,引起阻塞。有些Java程序使用的驱动程序,提供连接池功能,但是不提供连接重用时的事务清理功能。这样的连接池对应用开发质量要求很高,比较容易发生阻塞。
如果不能很快的实施建议a)和b),把连接池关闭能缩短食事务持续时间,也能从一定程度上缓解阻塞问题。
2. 分析为什么连接会遇到异常终止
这里又得谈到错误信息记录了。有了错误信息,就可以判定是超时问题,还是其他SQL Server错误。如果是超时问题,可按照第一种阻塞进行处理。
还有一种孤儿事务的来源,是连接开启了隐式事务(implicit transaction)而没有加入及时提交事务的机制。如果连接处于隐式事务模式(SET IMPLICIT_TRANSACTIONS ON),并且连接当前不再事务中,则执行下列任何一条语句都会开启一个新的事务。
| ALTER TABLE | FETCH | REVOKE |
| CREATE | GRANT | SELECT |
| DELETE | INSERT | TRUNCATE_TABLE |
| DROP | OPEN | UPDATE |
对于因为此设置为ON而自动打开的事务,SQL Server会自动帮你打开事务,但是不会自动帮你提交。用户必须在该事务结束后将其显式提交或回滚。否则,当用户断开连接时,事务及其包含的所有数据更改将被回滚。事务提交后,执行上述任意一条语句又会启动一个新事务。隐式事务模式将始终生效,知道连接执行SET IMPLICIT_TRANSACTIONS OFF语句使连接恢复为自动提交模式。在自动提交模式下,所有单个语句在成功完成时将被提交,不会有事务遗留。
为什么会有连接要开启隐式事务呢?除了程序员有意为之以外,很多是客户端数据库连接驱动,或者空间为了实现它的事务功能(注意不是SQL Server通过T-SQL语句直接提供的)而选用这个机制。如果应用程序出现意外,或者脚本没有处理好,会有应用层事务未提交的现象。在SQL Server里也体现为一个孤儿事务。严格约束应用层对事务的使用,直接使用SQL Server里面的事务,是避免这种问题出现的好方法。
语句在SQL Server内执行总时间不仅包含SQL Server的执行时间,还包含把结果集发给客户端的时间。如果结果集比较大,SQL Server会分几次打包发出,每发一次,都要等待客户端的确认。只有确认以后,SQL Server才会发送下一个结果集包。所有结果都发完以后,SQL Server才认为语句执行完毕,释放执行申请的资源(包括锁资源)。
如果处于某种原因,客户端应用处理结果非常缓慢甚至没有相应,或者干脆不理睬SQL Server发送结果集的请求,则SQL Server会耐心的等待,因此会导致语句长时间执行而发生阻塞。
解决方法:
- 在设计程序时,一定要慎重返回大结果集。这种行为不仅会对SQL Server和网络带来很大负担,对应用程序本身来讲,也要花很多资源去处理结果集。如果最终用户只需要部分结果集就可以,则在发送SQL Server指令的时候就要指定好。要避免居于不管三七二十一所有数据都要,而结果集只取走开头一部分去展示这样的行为发生。
- 如果应用程序的确须返回大结果集,例如一些报表系统,则要考虑报表数据库和生产数据库分开。
- 如果1和2在短期内不能实现,可以和最终用户协商,返回大结果集的连接使用READ UNCOMMITTED事务隔离级别。这样查询语句就不会申请S锁了。
这种情况常是由第一类情况衍生来的。有时候数据库管理员发现一个连接阻塞住了别人,为了解决问题,会让连接主动退出或强制退出(轻质退出应用,或者直接在SQL Server端KILL连接)。对于大部分情况,这些措施会消除阻塞。但是要记住的是,不管是在客户端退出,还是要服务器端KILL,为了维护数据库事务的一致性,SQL Server都会对连接还没有来得及完成提交的事务做回滚动作。SQL Server要找到所有当前事务修改过的记录,把它们改回原来的状态。所以,如果一个DELETE、INSERT或UPDATE已经运行了一个小时,可能回滚也需要一个小时,在这个过程中,阻塞还会延续,我们只能等待。
有些用户可能等不及,直接重启SQL Server。当SQL Server关闭的时候,回滚动作会被中断,SQL Server会被很快关掉,但是这个回滚动作在下次SQL Server重启的时候会重新开始(数据库做恢复的时候)。重启的时候如果回滚不能很快结束,整个数据库都不可用,可能会带来更严重的后果。
解决方法:
最好的方法是在工作时间尽量不要做这种大的修改操作。这些操作尽量安排在半夜或者周末的时间完成。如果操作已经做了很久,最好耐心等它做完。如果一定要在有工作负荷的时候做,最好把一个大操作分成若干小操作分步完成。
一个客户端的应用在运行过程中会使用到许多资源,包括线程资源,信号量资源,内存资源,IO资源等,SQL Server也是资源之一。如果发生死锁的两端不全是SQL Server,SQL Server的死锁判断机制可能不起作用。这时如果应用端没有处理好,可能会永远等下去。而SQL Server内部的表现可能仅仅是一个阻塞。但是这个阻塞不会自动消除。这样的阻塞对SQL Server的性能会产生很大影响。
下面我们举两个这种应用端死锁的例子。
1) 在应用的一个线程中开启不止一个数据库连接而产生的死锁(见图)。
假设应用有一个线程有这样的逻辑:
● 开始运行
● 建立数据库连接A,调用存储过程ProcA。打开结果集A。
● 建立数据库连接B,调用存储过程ProcB。打开结果集B。
● 轮流读取结果集A、B,整合输出最终结果。
● 关闭结果集A、B,关机连接A、B。
● 结束运行
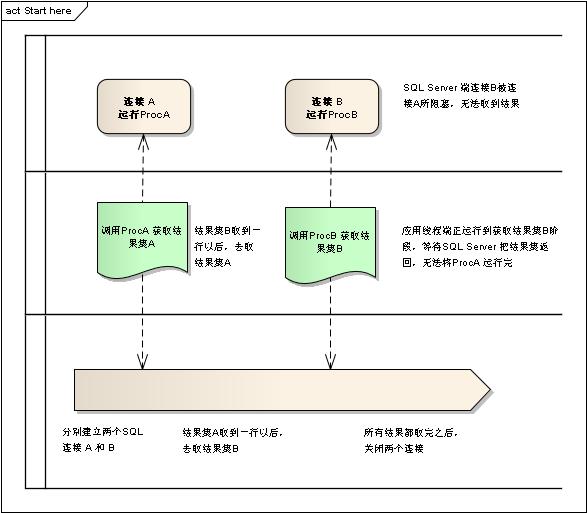
在正常情况下这样的设计看上去没有问题,但是实际上很脆弱。因为在线程内部,这个逻辑是线程执行的。假设存储过程ProcA是一个事务,在返回结果集之前因为一些操作申请了一些排他锁,而ProcB为了返回结果又要用到这些锁,那会发生什么情况呢?
发生的情况会是连接A在等线程把连接B上的结果读出来,再来处理结果集A,而连接B等待连接A完成事务后再释放锁。双方相互等待,产生思索。
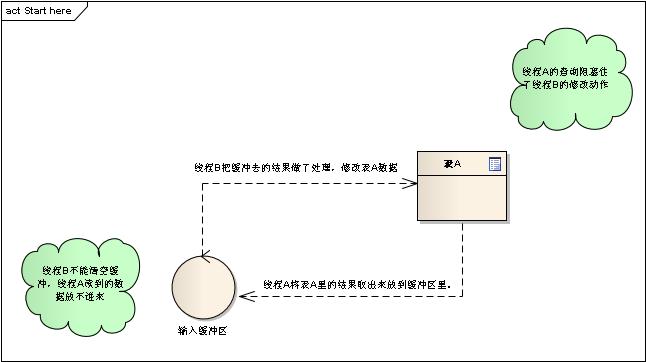
1) 两个线程间的死锁(见图)。
如果应用有两个线程,每个线程各开一个数据库连接,那上面的逻辑不会出问题。因为运行ProcA的那个线程会先做完,释放阻塞住连接B的锁,让B也能够接着跑完。但是假设有下列逻辑:
线程A:建立数据库连接A,不断读取表格A,按条取出记录,做一定处理后发给线程B的输入缓存。
线程B:建立数据库连接B,从输入缓存读取数据,依据收到的记录对表格A进行修改。
这个逻辑会产生什么问题呢?我们知道表格修改会在表上申请一些排他锁。如果线程A正在读取这条记录,修改动作会被阻塞住。这个时候线程B就会进入等待状态。但是线程A需要线程B输入缓存清空后才能写入。如果线程B还没来得及清空,它也不得不等待,这时候也会产生死锁(在SQL Server里是一个阻塞)。
解决方法:
复杂的程序还可能会出现其他的死锁形式。为了避免这种死锁,要在应用调用SQL Server的时候设置执行超时,并写好错误处理机制(参见阻塞原因2)。一旦死锁发生,SQL Server的操作在等待一段时间后会因为超时而放弃,并释放出SQL Server内部的资源,解决死锁。
小结:应更多从程序设计着手解决阻塞问题
很多用户有一种误解,认为阻塞是一个数据库问题。当阻塞问题发生的时候,都希望从数据库层面找到方法,一劳永逸地解决问题。可是,阻塞本身是为了完成事务的隔离,是应用程序向SQL Server提出的要求。所以很多时候,光从数据库端努力是不能解决阻塞问题的。在应用程序层面也要做很多工作。例如应用在做连接的时候选择什么样的隔离级别,事务开始和结束的时间点选择,连接的建立和回收机制,指令复杂度的控制等。应用程序还应该考虑到控制结果集大小,并及时从SQL Server端取走数据。还要考虑SQL Server指令执行时间长短控制,以及发生超时或其他意外后的错误处理机制等。尤其是对高并发量、高响应要求的关键业务系统,在设计应用时必须要考虑好上面这些关键因素。对于关键的业务逻辑,必须逐个审查,保证应用选择的是能够满足业务需求的最低隔离级别,事务的大小已经控制到了最小的粒度。而运行的语句,也要有良好的数据库设计,保证它不会随着数据库的增大和用户量的增多,占用更多的资源和运行时间。如果做不到这几点,就会容易发生应用在用户量比较少,或者数据库比较小的初始阶段性能不错,但是当用户量增长或数据量增大以后性能越来越慢的问题。
SQL Server 阻塞原因分析的更多相关文章
- 需要我们了解的SQL Server阻塞原因与解决方法
需要我们了解的SQL Server阻塞原因与解决方法 上篇说SQL Server应用模式之OLTP系统性能分析.五种角度分析sql性能问题.本章依然是SQL性能 五种角度其一“阻塞与死锁” 这里通过连 ...
- 一个特殊的SQL Server阻塞案例分析
上周,在SQL Server数据库下面遇到了一个有意思的SQL阻塞(SQL Blocking)案例.其实个人对SQL Server的阻塞还是颇有研究的.写过好几篇相关文章. 至于这里为什么要总结一下这 ...
- SQL Server 在线进程分析处理
SQL Server 在线进程分析处理 前言 数据库在线进程处理在很多时候需要人为干预已达到预期管理目标,下面整理一下常用的在线进程管理方法,便于后续工作使用. 一.查看目标数据库在线进程,并杀死指定 ...
- sql server 阻塞与锁
SQL Server阻塞与锁 在讨论阻塞与加锁之前,需要先理解一些核心概念:并发性.事务.隔离级别.阻塞锁及死锁. 并发性是指多个进程在相同时间访问或者更改共享数据的能力.一般情况而言,一个系统在互不 ...
- Sql Server 阻塞的常见原因和解决办法
1. 由于语句运行时间太长而导致的阻塞,语句本身在正常运行中,只须等待某些系统资源 解决办法: a. 语句本身有没有可优化的空间 b. Sql Server 整体性能如何,是不是有资源瓶颈影响了语句执 ...
- SQL Server 阻塞分析
一.加锁(locking).阻塞(blocking).死锁(deadlock)定义 加锁:用于管理多个连接的进程.当连接需要访问一块数据时,在这些数据上放置某种类型的锁. 阻塞 ...
- SQL Server阻塞blocking案例分析
今天在性能测试过程中发现大量阻塞报警,检查whoisactive(https://github.com/amachanic/sp_whoisactive/)数据发现,阻塞blocking头部sessi ...
- SQL Server死锁的分析、处理与预防
1.基本原理 所谓“死锁”,在操作系统的定义是:在一组进程中的各个进程均占有不会释放的资源,但因互相申请被其他进程所站用不会释放的资源而处于的一种永久等待状态. 定义比较抽象,下图可以帮助你比较直观的 ...
- SQL Server 阻塞排除的 2 方法
背景知识: 是什么造成了阻塞? 从锁的观点来看.可访问对象前一定要对对象加锁不管你是读还是写,如果用户A以经持有对象,说明A以在对象上加锁,如果这时B 也想访问这个对象.它也要对对象加锁.重点来了如果 ...
随机推荐
- sqli-labs:11-16,post注入
sqli11: post:uname=xx' order by 2#&passwd=bla&submit=Submit(判定字段为2) 解释下为什么结果不是admin,这是sql执行的 ...
- 高负载PHP调优
高负载PHP调优 针对PHP的Linux调优 调整文件描述符限制 # ulimit -n 1000000 # vi /etc/security/limits.conf # Setting Shell ...
- android 打开新窗口
ImageView loginBtn = (ImageView)findViewById(R.id.login_button); loginBtn.setOnClickListener(new Vie ...
- barcode(index)
在很多情况下,我们需要把多个样本混合在一起,在同一个通道(lane)里完成测序.像转录组测序.miRNA测序.lncRNA测序.ChIP测序等等,通常每个样本所需要的数据量都比较少,远少于HiSeq一 ...
- HDU 6185(打表代码
/** @xigua */ #include <cstdio> #include <cmath> #include <iostream> #include < ...
- canvas 实现微信小游戏
var canvas = document.getElementById('canvas'); var cxt = canvas.getContext('2d'); var timer; var iS ...
- Element类型
除了document,element类型也算是最常用的类型 Element节点有以下特征: nodeType 值为1 nodeName 元素的标签名 nodeValue 值为null parentNo ...
- php,判断ajax,get,post
PHP自定义函数判断是否为Get.Post及Ajax提交的方法 /** * 是否是AJAx提交的 * @return bool */ function isAjax(){ if(isset($_SER ...
- AngularJS中$interval和$timeout的使用
我们在项目中会出现定时刷新,延迟加载等多种场景. 接下来就看$interval和$timeout的使用 $interval可用于定时任务,我们只需在controller注入$interval即可使用. ...
- C#程序集问题:混合模式程序集是针对“v2.0.50727”版的运行时生成的.....
今天在把以前写的代码生成工具从原来的.NET3.5升级到.NET4.0,同时准备进一步完善,将程序集都更新后,一运行程序在一处方法调用时报出了一个异常: 混合模式程序集是针对“v2.0.50727”版 ...