CUDA 编程
作者:MingChaoSun
原文:https://blog.csdn.net/sunmc1204953974/article/details/51000970
一、CPU和GPU
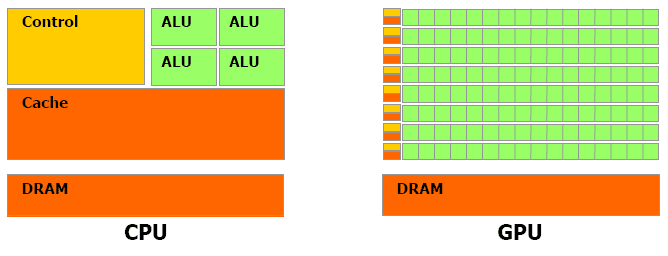
上图是CPU与GPU的对比图,对于浮点数操作能力,CPU与GPU的能力相差在GPU更适用于计算强度高,多并行的计算中。因此,GPU拥有更多晶体管,而不是像CPU一样的数据Cache和流程控制器。这样的设计是因为多并行计算的时候每个数据单元执行相同程序,不需要那么繁琐的流程控制,而更需要高计算能力,这也不需要大cache。但也因此,每个GPU的计算单元的结构是十分简单的,因此对程序的可并行性的要求也是十分苛刻的。
这里我们再介绍一下使用GPU计算的优缺点(摘自《深入浅出谈CUDA》):
使用显示芯片来进行运算工作,和使用 CPU 相比,主要有几个优点:
- 显示芯片通常具有更大的内存带宽。例如,NVIDIA 的 GeForce 8800GTX 具有超过50GB/s 的内存带宽,而目前高阶 CPU 的内存带宽则在 10GB/s 左右。
- 显示芯片具有更大量的执行单元。例如 GeForce 8800GTX 具有 128 个 “stream processors”,频率为 1.35GHz。CPU 频率通常较高,但是执行单元的数目则要少得多。
- 和高阶 CPU 相比,显卡的价格较为低廉。例如一张 GeForce 8800GT 包括512MB 内存的价格,和一颗 2.4GHz 四核心 CPU 的价格相当。
当然,使用显示芯片也有它的缺点:
- 显示芯片的运算单元数量很多,因此对于不能高度并行化的工作,所能带来的帮助就不大。
- 显示芯片目前通常只支持 32 bits 浮点数,且多半不能完全支持 IEEE 754 规格, 有些运算的精确度可能较低。目前许多显示芯片并没有分开的整数运算单元,因此整数运算的效率较差。
- 显示芯片通常不具有分支预测等复杂的流程控制单元,因此对于具有高度分支的程序,效率会比较差。
- 目前 GPGPU 的程序模型仍不成熟,也还没有公认的标准。例如 NVIDIA 和AMD/ATI 就有各自不同的程序模型。
二、CUDA架构
Host 和 Kernel
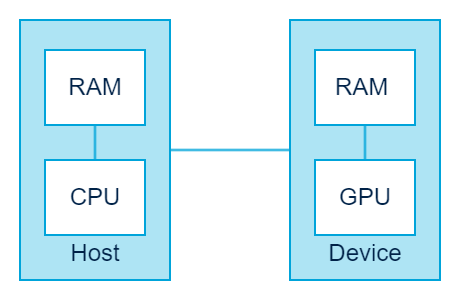
在 CUDA 的架构下,一个程序分为两个部份:host 端和 device 端。Host 端是指在 CPU 上执行的部份,而 device 端则是在显示芯片上执行的部份。Device 端的程序又称为 “kernel”。通常 host 端程序会将数据准备好后,复制到显卡的内存中,再由显示芯片执行 device 端程序,完成后再由 host 端程序将结果从显卡的内存中取回。
由于 CPU 存取显卡内存时只能透过 PCI Express 接口,因此速度较慢(PCI Express x16 的理论带宽是双向各 4GB/s),因此不能太常进行这类动作,以免降低效率。
thread-block-grid 结构
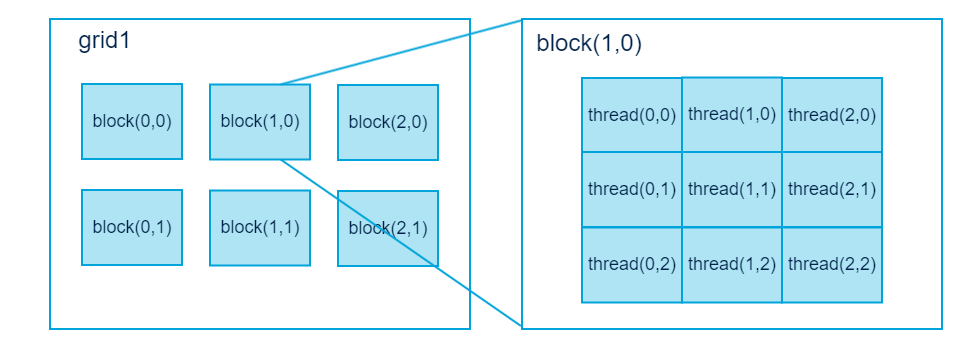
在 CUDA 架构下,显示芯片执行时的最小单位是thread。数个 thread 可以组成一个block。一个 block 中的 thread 能存取同一块共享的内存,而且可以快速进行同步的动作。
每一个 block 所能包含的 thread 数目是有限的。不过,执行相同程序的 block,可以组成grid。不同 block 中的 thread 无法存取同一个共享的内存,因此无法直接互通或进行同步。因此,不同 block 中的 thread 能合作的程度是比较低的。不过,利用这个模式,可以让程序不用担心显示芯片实际上能同时执行的 thread 数目限制。例如,一个具有很少量执行单元的显示芯片,可能会把各个 block 中的 thread 顺序执行,而非同时执行。不同的 grid 则可以执行不同的程序(即 kernel)。
每个 thread 都有自己的一份 register 和 local memory 的空间。同一个 block 中的每个thread 则有共享的一份 share memory。此外,所有的 thread(包括不同 block 的 thread)都共享一份 global memory、constant memory、和 texture memory。不同的 grid 则有各自的 global memory、constant memory 和 texture memory。
执行模式
由于显示芯片大量并行计算的特性,它处理一些问题的方式,和一般 CPU 是不同的。主要的特点包括:
内存存取 latency 的问题:CPU 通常使用 cache 来减少存取主内存的次数,以避免内存 latency 影响到执行效率。显示芯片则多半没有 cache(或很小),而利用并行化执行的方式来隐藏内存的 latency(即,当第一个 thread 需要等待内存读取结果时,则开始执行第二个 thread,依此类推)。
分支指令的问题:CPU 通常利用分支预测等方式来减少分支指令造成的 pipeline bubble。显示芯片则多半使用类似处理内存 latency 的方式。不过,通常显示芯片处理分支的效率会比较差。
因此,最适合利用 CUDA 处理的问题,是可以大量并行化的问题,才能有效隐藏内存的latency,并有效利用显示芯片上的大量执行单元。使用 CUDA 时,同时有上千个 thread 在执行是很正常的。因此,如果不能大量并行化的问题,使用 CUDA 就没办法达到最好的效率了。
CUDA 编程的更多相关文章
- 不同版本CUDA编程的问题
1 无法装上CUDA的toolkit 卸载所有的NVIDIA相关的app,包括NVIDIA的显卡驱动,然后重装. 2之前的文件打不开,one or more projects in the solut ...
- cuda编程基础
转自: http://blog.csdn.net/augusdi/article/details/12529247 CUDA编程模型 CUDA编程模型将CPU作为主机,GPU作为协处理器(co-pro ...
- CUDA学习笔记(一)——CUDA编程模型
转自:http://blog.sina.com.cn/s/blog_48b9e1f90100fm56.html CUDA的代码分成两部分,一部分在host(CPU)上运行,是普通的C代码:另一部分在d ...
- CUDA编程
目录: 1.什么是CUDA 2.为什么要用到CUDA 3.CUDA环境搭建 4.第一个CUDA程序 5. CUDA编程 5.1. 基本概念 5.2. 线程层次结构 5.3. 存储器层次结构 5.4. ...
- CUDA编程-(1)Tesla服务器Kepler架构和万年的HelloWorld
结合CUDA范例精解以及CUDA并行编程.由于正在学习CUDA,CUDA用的比较多,因此翻译一些个人认为重点的章节和句子,作为学习,程序将通过NVIDIA K40服务器得出结果.如果想通过本书进行CU ...
- cuda编程(一)
环境安装和例程运行 显卡主要有两家,ATI.NVIDIA,简称A卡和N卡.随着GPU计算能力的上升,采用GPU并行计算来加速的应用越来越多. Nvidia创立人之一,黄仁勋(Jen-Hsun Huan ...
- CUDA编程入门,Dim3变量
dim3是NVIDIA的CUDA编程中一种自定义的整型向量类型,基于用于指定维度的uint3. 例如:dim3 grid(num1,num2,num3): dim3类型最终设置的是一个三维向量,三维参 ...
- CUDA编程(六)进一步并行
CUDA编程(六) 进一步并行 在之前我们使用Thread完毕了简单的并行加速,尽管我们的程序运行速度有了50甚至上百倍的提升,可是依据内存带宽来评估的话我们的程序还远远不够.在上一篇博客中给大家介绍 ...
- CUDA编程模型之内存管理
CUDA编程模型假设系统是由一个主机和一个设备组成的,而且各自拥有独立的内存. 主机:CPU及其内存(主机内存),主机内存中的变量名以h_为前缀,主机代码按照ANSI C标准进行编写 设备:GPU及其 ...
- CUDA编程模型
1. 典型的CUDA编程包括五个步骤: 分配GPU内存 从CPU内存中拷贝数据到GPU内存中 调用CUDA内核函数来完成指定的任务 将数据从GPU内存中拷贝回CPU内存中 释放GPU内存 *2. 数据 ...
随机推荐
- 【转】IE沙箱拖拽安全策略解析
https://xlab.tencent.com/cn/2015/12/17/ie-sandbox-drop-security-policy/ IE沙箱逃逸是IE浏览器安全研究的一个重要课题,其中有一 ...
- C#获取本地磁盘信息【转载】
直接上干货简单易懂 //磁盘监控(远程/本地)//需要引用System.Management.dllpublic class RemoteMonitoring{private static str ...
- VMware三种网络介绍
前言 很多人安装虚拟机的时候,经常遇到不能上网的问题,而vmware有三种网络模式,对初学者来说也比较眼花聊乱,今天我就来基于虚拟机3种网络模式,帮大家普及下虚拟机上网的背景知识.(博文原创自http ...
- ubuntu 14.04 重装机 安装笔记 无线网卡+cuda+nvidia
1. 安装QA6714 无线网卡重要参考网页 #22 回答 https://bugs.launchpad.net/ubuntu/+source/linux-firmware/+bug/1520343? ...
- CentOS Linux 升级内核步骤和方法(转)
当前系统为CentOS Linux release 6.0 (Final),内核版本为2.6.32-71.el6.i686.由于最近内核出现最新的漏洞(linux kernel 又爆内存提权漏洞,2. ...
- ubuntu16.04微信安装
1.下载: git clone https://github.com/geeeeeeeeek/electronic-wechat/releases 2.移动微信客户端(下载解压重命名为wechat)到 ...
- 数据结构_1+AI_1
归纳一下今天看的有关数据结构和AI的知识: 数据结构:数据的组织形式和存储方法 主要包括:1.线性结构 2.树结构 3.图结构 1.线性结构:由n个元素构成的有限序列.[数组]为最简单的一种形式. 主 ...
- 关于layui中tablle 渲染数据后 sort排序问题
最近在使用easyweb框架做后台管理,案例可见https://gitee.com/whvse/EasyWeb. 其中遇到了 sort排序问题, html代码:<table class=&quo ...
- vue H5页面在微信浏览器打开软键盘关闭导致页面空缺的问题。
methods:{ inputBlur () { // window.scroll(0, 0); setTimeout(() => { // alert(1); if (document.act ...
- Linux搜索文件或内容
1.递归搜索文件内容,如果查找"hello,world!"字符串,可以这样: grep -rn "hello,world!" * * : 表示当前目录所有文件, ...