论文笔记:Learning Attribute-Specific Representations for Visual Tracking
Learning Attribute-Specific Representations for Visual Tracking
AAAI-2019
Paper:http://faculty.ucmerced.edu/mhyang/papers/aaai2019_tracking.pdf
本文提出一种新的学习思路,即:属性信息 (e.g., illumination changes, occlusion and motion) ,来进行 CNN 特征的学习,以得到更加鲁棒的 tracker。具体来说,就是设计一种基于属性的 CNN,并且带有多个分支,每一个分支用于分类特定属性的目标。这种设计的优势在于:在每一种挑战下,降低了目标外观的多样性,用更少的训练数据就可以训练模型(reduces the appearance diversity of the target under each attribute and thus requires less data to train the model)。我们将所有的特定属性feature,通过集成层(ensemble layer)进行聚合,得到更加具有判别力的特征来进行分类。其实这个思路,类似于 MDNet,但是又跟 MDNet 不同。

具体流程(ANT Tracker):
1. Attribute-based Neural Network:
如上图所示,该网络的前几层是从 VGG-M 模型得到的几层卷积层,用于提取底层信息,如边缘和纹理信息等。然后,用五个属性分支来学习对应属性的表达。文章作者用了 VOT 数据集提供的五个属性:target motions, camera motions, illumination variations, occlusions, and scale change, 这些挑战性因素可以涵盖 OTB100 数据集的 11 种属性。此外,VOT数据集属性的标注是每一帧都进行了标注,这就允许作者可以将训练数据集划分为不同的属性组(attribute groups)来训练对应的分支。
紧跟着这些属性分支的是 ensemble layer 和 fc layer。在测试阶段,属性组是未知的,一个视频帧可能也包含多种属性。所以,仅仅将视频帧传送到每一个分支也是不合理的。所以,作者这里将输入图像区域传递到所有的属性分支,并且训练一个 ensemble layer 来自适应的组合所有的特征,得到一个充分并且具有判别性的表达。ensemble layer 的输出被传送到 FC layer 进行最终前景和背景的分类。
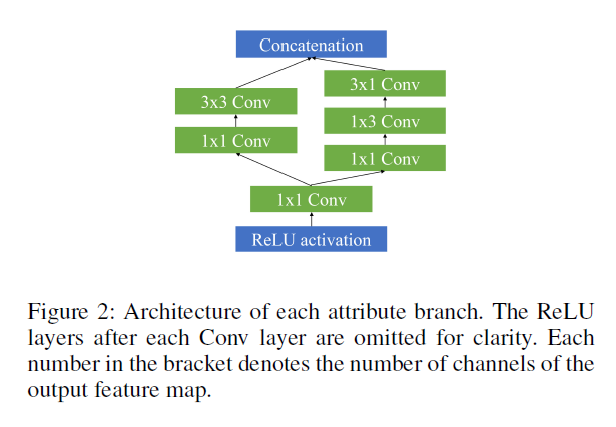
对于每一分支的结构,我们采用 Inception 的结构,如下图所示,以得到更好的feature。
2. Two-Stage Training:
作者这里提到 end-to-end learning 的方式,无法确保每个分支可以学会分类对应属性的数据(can not guarantee each branch to learn to classify data of the corresponding attribute),因为任何训练样本的分类损失都可以反向传递到所有的五个分支。为了解决这个问题,作者采用了两个阶段的训练策略。
Stage-I:training attribute branches.
这个五个分支是依次训练的。特别的,作者将 ensemble layer 和 last FC layer 移除,然后对每一种属性,添加一个 new FC layer,进行训练。
Stage-II:training ensemble layers.
一旦上述属性分支训练完毕,就开始训练 ensemble layer,以得到这些特征的最终集成特征,用于分类。首先将 FC 层给 remove 掉,然后,接上 ensemble layer 和 FC layer,继续训练。这里采用 softmax-loss 进行训练,大约 150 次迭代后,开始收敛。
3. Tracking:
在实际跟踪的时候,就直接通过采样,然后打分的方式进行:

4. 实验结果:

==
论文笔记:Learning Attribute-Specific Representations for Visual Tracking的更多相关文章
- 论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning
论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning 2017-06-06 21: ...
- 论文笔记: Dual Deep Network for Visual Tracking
论文笔记: Dual Deep Network for Visual Tracking 2017-10-17 21:57:08 先来看文章的流程吧 ... 可以看到,作者所总结的三个点在于: 1. ...
- 论文笔记:SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks
SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks 2019-04-02 12:44:36 Paper:ht ...
- Deep Reinforcement Learning with Iterative Shift for Visual Tracking
Deep Reinforcement Learning with Iterative Shift for Visual Tracking 2019-07-30 14:55:31 Paper: http ...
- 论文笔记之: Recurrent Models of Visual Attention
Recurrent Models of Visual Attention Google DeepMind 模拟人类看东西的方式,我们并非将目光放在整张图像上,尽管有时候会从总体上对目标进行把握,但是也 ...
- 论文笔记 — Learning to Compare Image Patches via Convolutional Neural Networks
论文: 引入论文中的一句话来说明对比图像patches的重要性,“Comparing patches across images is probably one of the most fundame ...
- 论文笔记:Fully-Convolutional Siamese Networks for Object Tracking
Fully-Convolutional Siamese Networks for Object Tracking 本文作者提出一个全卷积Siamese跟踪网络,该网络有两个分支,一个是上一帧的目标,一 ...
- 论文笔记-Deep Affinity Network for Multiple Object Tracking
作者: ShijieSun, Naveed Akhtar, HuanShengSong, Ajmal Mian, Mubarak Shah 来源: arXiv:1810.11780v1 项目:http ...
- Summary on Visual Tracking: Paper List, Benchmarks and Top Groups
Summary on Visual Tracking: Paper List, Benchmarks and Top Groups 2018-07-26 10:32:15 This blog is c ...
随机推荐
- Vue keep-alive如何实现只缓存部分页面
prop: include: 字符串或正则表达式.只有匹配的组件会被缓存. exclude: 字符串或正则表达式.任何匹配的组件都不会被缓存. 在2.1.0版本Vue中 常见用法: // 组件 exp ...
- 红黑树与AVL特性
红黑树:比较平衡的二叉树,没有一条路径会比其他路径长2倍,因而是近似平衡的.所以相对于严格要求平衡的AVL树来说,它的旋转保持平衡次数较少.插入删除次数多的情况下我们就用红黑树来取代AVL. 红黑树规 ...
- 关于SQL配置管理工具无法打开0x8004100e问题!
今天犯了个很“2”得问题,因为在远程数据库可以访问,并且也在安装程序中有看到装有SQLserver Mamngement Studio及其它程序,所以想在本地使用数据库应该可以但没想却总是报SQL配置 ...
- 3.2.1 SpringMVC入门
一. SpringMVC入门 1. MVC介绍 MVC全名 是Model View Controller, 是模型(model) - 视图(view) - 控制器(controller) 的缩写, 它 ...
- Jsoup解析XML
先导入jsoup.jar 包 方法1:不推荐,了解即可 方法 方法3: 后期学习主流
- Solaris环境下使用snoop命令抓包
(1)报文抓取 Solaris中自带有snoop抓包工具,通过执行相应的命令抓取. 抓取目的地址为10.8.3.250的数据包,并存放到/opt/cap250的文件里 snoop -o /opt/ca ...
- OpenGL入门之入门
programs on the GPU-------shader 顶点着色器-->形状(图元)装配-->几何着色器-->光栅化-->片段着色器-->测试与混合 图形渲染管 ...
- org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'dataSource' defined in class path resource [app2.xml]: Instantiation of bean failed; nested exception is org.spr
在学习spring整合hubernate时遇到的问题.c3p0遇到了一个问题,老连不上,显示java.lang.NoClassDefFoundError:com.mchange.v2.ser.Indi ...
- Asp.net Image控件显示Bitmap生成图像
from:https://blog.csdn.net/qq_29011299/article/details/81137980 using(Bitmap bmp=new Bitmap(300,50)) ...
- C# 初识Redis
一.下载:听网上的朋友説的找的是redis for windows ,直接下载即可 https://github.com/ServiceStack/redis-windows 二.下载后解压 文件 r ...