【原创】大数据基础之Impala(2)实现细节
一 架构
Impala is a massively-parallel query execution engine, which runs on hundreds of machines in existing Hadoop clusters. It is decoupled from the underlying storage engine, unlike traditional relational database management systems where the query processing and the underlying storage engine are components of a single tightly-coupled system.
impala是一个大规模并行查询引擎,可以在现有hadoop集群上部署运行,与底层存储引擎解耦;
An Impala deployment is comprised of three services.
一个impala集群由三部分组成:impalad、statestored、catalogd;
impalad
The Impala daemon (impalad) service is dually responsible for accepting queries from client processes and orchestrating their execution across the cluster, and for executing individual query fragments on behalf of other Impala daemons. When an Impala daemon operates in the First role by managing query execution, it is said to be the coordinator for that query. However, all Impala daemons are symmetric; they may all operate in all roles. This property helps with fault-tolerance, and with load-balancing.
One Impala daemon is deployed on every machine in the cluster that is also running a datanode process - the block server for the underlying HDFS deployment - and therefore there is typically one Impala daemon on every machine. This allows Impala to take advantage of data locality, and to read blocks from the Filesystem without having to use the network.
所有的impalad是对等的,没有主从结构,这样天然具有容错和负载均衡的好处,impalad负责:
1)接收client的query请求(作为该query的coordinator)并将query分解到整个集群并行执行;
2)配合其他impalad(即其他query的coordinator)执行query的一部分;
impalad通常和datanode部署在一起,这样可以利用数据本地性,避免网络开销;
statestored
The Statestore daemon (statestored) is Impala's meta-data publish-subscribe service, which disseminates cluster-wide metadata to all Impala processes. There is a single statestored instance
statestored是impala的metadata发布订阅服务,会将集群中的metadata变更推送到所有的impalad,statestore是单点;
catalogd
Finally, the Catalog daemon (catalogd), serves as Impala's catalog repository and metadata access gateway. Through the catalogd, Impala daemons may exe-cute DDL commands that are reected in external catalog stores such as the Hive Metastore. Changes to the system catalog are broadcast via the statestore.
catalogd是impala的catalog仓库和metadata访问网关,impalad执行ddl操作时通过catalogd同步操作外部catalog比如hive metastore;所有的catalog变更也通过statestored通知所有的impalad;
实现细节
1 state
A major challenge in the design of an MPP database that is intended to run on hundreds of nodes is the coordination and synchronization of cluster-wide metadata. Impala's symmetric-node architecture requires that all nodes must be able to accept and execute queries. Therefore all nodes must have, for example, up-to-date versions of the system catalog and a recent view of the Impala cluster's membership so that queries may be scheduled correctly.
MPP(Massively Parallel Processing)数据库设计的一个主要挑战是在几百个节点的集群中协调和同步元数据;impala的对等结构要求所有的节点都能接收和执行query,所以所有的节点都必须有最新的catalog和集群中所有节点的状态;
We might approach this problem by deploying a separate cluster-management service, with ground-truth versions of all cluster-wide metadata. Impala daemons could then query this store lazily (i.e. only when needed), which would ensure that all queries were given up-to-date responses. However, a fundamental tenet in Impala's design has been to avoid synchronous RPCs wherever possible on the critical path of any query. Without paying close attention to these costs, we have found that query latency is often compromised by the time taken to establish a TCP connection, or load on some remote service. Instead, we have designed Impala to push updates to all interested parties, and have designed a simple publish-subscribe service called the statestore to disseminate metadata changes to a set of subscribers.
要解决这个问题可以部署一套单独的服务,每次需要元数据的时候主动调用服务查询(pull),这样可以保证每次查询都能拿到最新版本的元数据;但是impala设计的基本原则就是要避免在查询的关键路径上有同步rpc调用(建立连接和远程服务调用的时间开销);所以impala在设计的时候使用一个叫做statestore的发布订阅服务来推送所有的元数据更新(push);
The statestore maintains a set of topics, which are arrays of (key, value, version) triplets called entries where 'key' and 'value' are byte arrays, and 'version' is a 64-bit integer. A topic is defined by an application, and so the statestore has no understanding of the contents of any topic entry. Topics are persistent through the lifetime of the statestore, but are not persisted across service restarts. Processes that wish to receive updates to any topic are called subscribers, and express their interest by registering with the statestore at start-up and providing a list of topics. The statestore responds to registration by sending the subscriber an initial topic update for each registered topic, which consists of all the entries currently in that topic.
statestore维护一个topic的集合,每个topic实际上是(key、value、version)的数组,topic数据并没有做持久化,重启statestore后之前的topic数据就没了;每个impalad启动后都会到statestored注册,同时提供要订阅的topic列表,statestored会把订阅的topic中所有的数据都推送给impalad;
After registration, the statestore periodically sends two kinds of messages to each subscriber. The first kind of message is a topic update, and consists of all changes to a topic (new entries, modified entries and deletions) since the last update was successfully sent to the subscriber. Each subscriber maintains a per-topic most-recent-version identifier which allows the statestore to only send the delta between updates. In response to a topic update, each subscriber sends a list of changes it wishes to make to its subscribed topics. Those changes are guaranteed to have been applied by the time the next update is received.
The second kind of statestore message is a keepalive. The statestore uses keepalive messages to maintain the connection to each subscriber, which would otherwise time-out its subscription and attempt to re-register. Previous versions of the statestore used topic update messages for both purposes, but as the size of topic updates grew it became difficult to ensure timely delivery of updates to each subscriber, leading to false-positives in the subscriber's failure-detection process.
impalad向statestored注册之后,statestored会周期性的向impalad发送两种消息:1)topic更新消息;2)keepalive消息(保持长连接);
If the statestore detects a failed subscriber (for example, by repeated failed keepalive deliveries), it will cease sending updates. Some topic entries may be marked as 'transient', meaning that if their 'owning' subscriber should fail, they will be removed. This is a natural primitive with which to maintain liveness information for the cluster in a dedicated topic, as well as per-node load statistics.
The statestore provides very weak semantics: subscribers may be updated at diffierent rates (although the statestore tries to distribute topic updates fairly), and may therefore have very diffierent views of the content of a topic. However, Impala only uses topic metadata to make decisions locally, without any coordination across the cluster. For example, query planning is performed on a single node based on the catalog metadata topic, and once a full plan has been computed, all information required to execute that plan is distributed directly to the executing nodes. There is no requirement that an executing node should know about the same version of the catalog metadata topic.
statestore设计使得不同的impalad中的元数据可能在不同的时间被更新,尽管如此,impalad收到query之后只使用本地的topic元数据来生成执行计划,一旦一个执行计划生成,执行所需要的全部信息都会直接下发到执行节点,所以不要求执行节点和生成执行计划的节点拥有同样的元数据;
Although there is only a single statestore process in existing Impala deployments, we have found that it scales well to medium sized clusters and, with some configuration, can serve our largest deployments. The statestore does not persist any metadata to disk: all current metadata is pushed to the statestore by live subscribers (e.g. load information).
虽然statestored只部署一个,但是足以支撑中等规模的集群;
Therefore, should a statestore restart, its state can be recovered during the initial subscriber registration phase. Or if the machine that the statestore is running on fails, a new statestore process can be started elsewhere, and subscribers may fail over to it. There is no built-in failover mechanism in Impala, instead deployments commonly use a retargetable DNS entry to force subscribers to automatically move to the new process instance.
statestore不会持久化元数据到磁盘,当一个statestore重启时,状态很容易恢复;即使statestore所在机器挂了,一个新的statestore也很容易在其他机器上启动,但是impala并没有内置failover机制使得impalad能够切换到新的statestore,这里通常使用dns服务来实现statestore切换;
2 catalog
Impala's catalog service serves catalog metadata to Impala daemons via the statestore broadcast mechanism, and executes DDL operations on behalf of Impala daemons. The catalog service pulls information from third-party metadata stores (for example, the Hive Metastore or the HDFS Namenode), and aggregates that information into an Impala-compatible catalog structure. This architecture allows Impala to be relatively agnostic of the metadata stores for the storage engines it relies upon, which allows us to add new metadata stores to Impala relatively quickly (e.g. HBase support). Any changes to the system catalog (e.g. when a new table has been loaded) are disseminated via the statestore.
catalogd通过statestored将catalog元数据(包括后续更新)推送给impalad,同时代替impalad执行DDL操作;catalogd会从第三方元数据系统中拉取信息,这种设计使得impala很容易兼容第三方元数据;
The catalog service also allows us to augment the system catalog with Impala-specfic information. For example, we register user-defined-functions only with the catalog service (without replicating this to the Hive Metastore, for example), since they are specific to Impala.
impala udf只注册到catalogd中;
Since catalogs are often very large, and access to tables is rarely uniform, the catalog service only loads a skeleton entry for each table it discovers on startup. More detailed table metadata can be loaded lazily in the background from its third-party stores. If a table is required before it has been fully loaded, an Impala daemon will detect this and issue a prioritization request to the catalog service. This request blocks until the table is fully loaded.
catalog通常很大,所以catalogd启动时只加载所有库表的基本信息,详细信息会在需要的时候再加载(lazily);如果一个表在被查询时还没有被加载,impalad会发送一个请求给catalogd,这个请求会一直卡住直到表被加载完;
二 查询流程
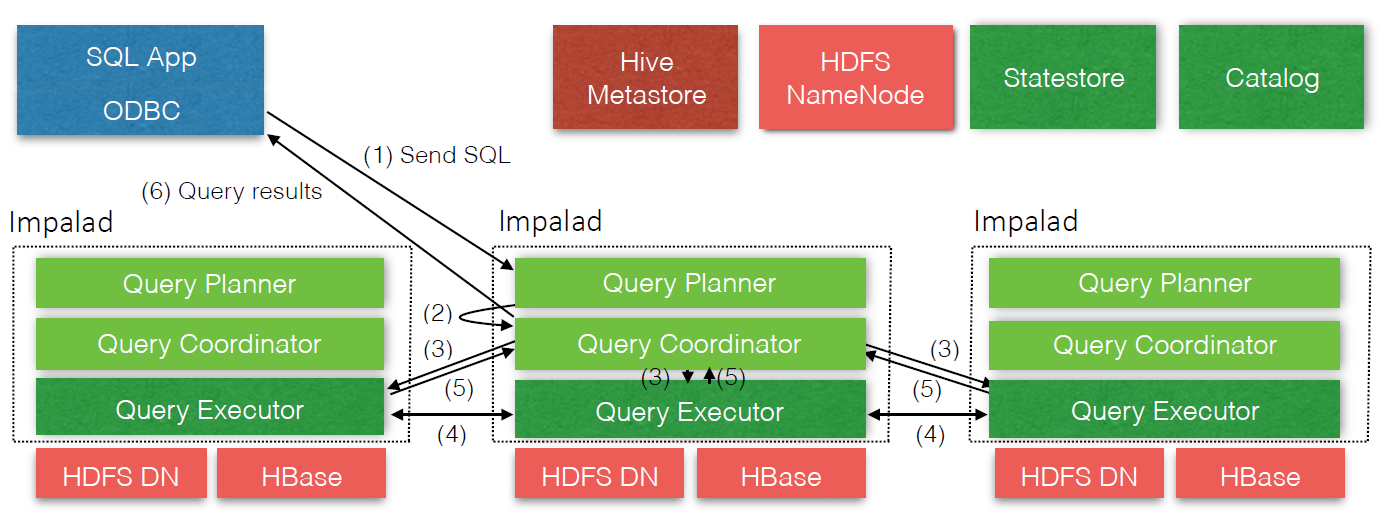
一个查询从开始到结束由6步组成
实现细节
frontend
The Impala frontend is responsible for compiling SQL text into query plans executable by the Impala backends. It is written in Java and consists of a fully-featured SQL parser and cost-based query optimizer, all implemented from scratch. In addition to the basic SQL features (select, project, join, group by, order by, limit), Impala supports inline views, uncorrelated and correlated subqueries (that are rewritten as joins), all variants of outer joins as well as explicit left/right semi- and anti-joins, and analytic window functions.
frontend负责将sql编译为backend可以执行的查询计划,使用java编写,包括sql解析器和查询优化器;
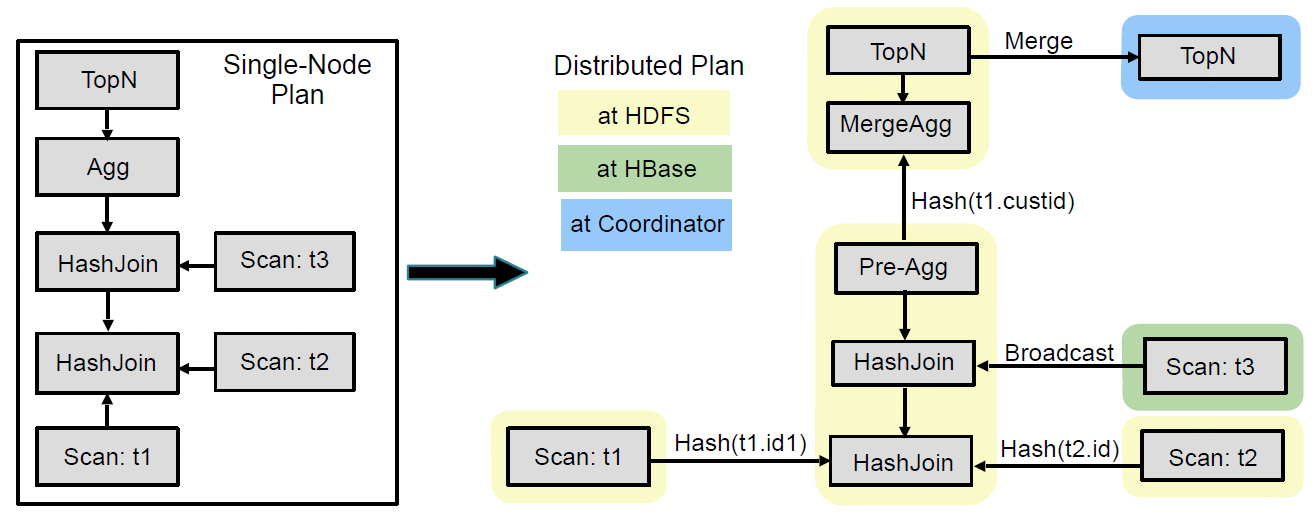
The query compilation process follows a traditional division of labor: Query parsing, semantic analysis, and query planning/optimization. We will focus on the latter, most challenging, part of query compilation. The Impala query planner is given as input a parse tree together with query-global information assembled during semantic analysis (table/column identifiers, equivalence classes, etc.). An executable query plan is constructed in two phases: (1) Single node planning and (2) plan parallelization and fragmentation.
查询编译过程包括:查询解析、语义分析、查询计划、查询优化;一个可执行的查询计划的创建有两个阶段:单节点计划和分布式计划;
In the first phase, the parse tree is translated into a non-executable single-node plan tree, consisting of the following plan nodes: HDFS/HBase scan, hash join, cross join, union, hash aggregation, sort, top-n, and analytic evaluation. This step is responsible for assigning predicates at the lowest possible plan node, inferring predicates based on equivalence classes, pruning table partitions, setting limits/offsets, applying column projections, as well as performing some cost-based plan optimizations such as ordering and coalescing analytic window functions and join reordering to minimize the total evaluation cost. Cost estimation is based on table/partition cardinalities plus distinct value counts for each column; histograms are currently not part of the statistics. Impala uses simple heuristics to avoid exhaustively enumerating and costing the entire join-order space in common cases.
第一阶段,sql会被翻译为一个不可执行的单节点的计划树;优化的因素包括:predicate pushdown(谓词下推,基于分区、limit、列预测等)和cost estimate(成本预估,基于所有列的基数计数);
The second planning phase takes the single-node plan as input and produces a distributed execution plan. The general goal is to minimize data movement and maximize scan locality: in HDFS, remote reads are considerably slower than local ones. The plan is made distributed by adding exchange nodes between plan nodes as necessary, and by adding extra non-exchange plan nodes to minimize data movement across the network (e.g., local aggregation nodes). During this second phase, we decide the join strategy for every join node (the join order is fixed at this point). The supported join strategies are broadcast and partitioned. The former replicates the entire build side of a join to all cluster machines executing the probe, and the latter hash-redistributes both the build and probe side on the join expressions. Impala chooses whichever strategy is estimated to minimize the amount of data exchanged over the network, also exploiting existing data partitioning of the join inputs.
第二阶段,单节点计划树会被用来生成一个分布式执行计划;优化的因素包括:最小化数据移动,最大化的利用数据本地性,尽可能的先在本地聚合减少后续的数据移动,决定join策略(broadcast or partitioned);
All aggregation is currently executed as a local pre-aggregation followed by a merge aggregation operation. For grouping aggregations, the pre-aggregation output is partitioned on the grouping expressions and the merge aggregation is done in parallel on all participating nodes. For non-grouping aggregations, the merge aggregation is done on a single node. Sort and top-n are parallelized in a similar fashion: a distributed local sort/top-n is followed by a single-node merge operation. Analytic expression evaluation is parallelized based on the partition-by expressions. It relies on its input being sorted on the partition-by/order-by expressions. Finally, the distributed plan tree is split up at exchange boundaries. Each such portion of the plan is placed inside a plan fragment, Impala's unit of backend execution. A plan fragment encapsulates a portion of the plan tree that operates on the same data partition on a single machine.
所有的聚合在执行时都会分解为本地pre-aggregation和merge aggregation(需要shuffle);
最终,分布式计划树根据exchange(shuffle)被拆分为多个plan fragement(一个plan fragment是一个backend的执行单元);
backend
Impala's backend receives query fragments from the frontend and is responsible for their fast execution. It is designed to take advantage of modern hardware. The backend is written in C++ and uses code generation at runtime to produce efficient codepaths (with respect to instruction count) and small memory overhead, especially compared to other engines implemented in Java.
backend从frontend接收query fragment,然后负责query fragment的快速执行;它被设计为尽可能的利用现代硬件;使用C++编写,使用运行时代码生成来产生高效的代码路径(根据cpu指令数量来衡量高效)和更少的内存占用;
Impala leverages decades of research in parallel databases. The execution model is the traditional Volcano-style with Exchange operators. Processing is performed batch-at-a-time: each GetNext() call operates over batches of rows. With the exception of "stop-and-go" operators (e.g. sorting), the execution is fully pipeline-able, which minimizes the memory consumption for storing intermediate results. When processed in memory, the tuples have a canonical in-memory row-oriented format.
impala执行模型是Volcano;处理过程是一次一批,每次调用GetNext()都会在一批数据上进行操作;除了‘stop-and-go’类型的operator,执行过程是管道化的(多个operator一起执行),这样避免存储中间结果可以最小化内存占用;
Operators that may need to consume lots of memory are designed to be able to spill parts of their working set to disk if needed. The operators that are spillable are the hash join, (hash-based) aggregation, sorting, and analytic function evaluation.
一些可能消耗很多内存的operator被设计为可以根据需要将部分中间结果输出磁盘;
Impala employs a partitioning approach for the hash join and aggregation operators. That is, some bits of the hash value of each tuple determine the target partition and the remaining bits for the hash table probe. During normal operation, when all hash tables fit in memory, the overhead of the partitioning step is minimal, within 10% of the performance of a non-spillable non-partitioning-based implementation. When there is memory-pressure, a \victim" partition may be spilled to disk, thereby freeing memory for other partitions to complete their processing. When building the hash tables for the hash joins and there is reduction in cardinality of the build-side relation, we construct a Bloom filter which is then passed on to the probe side scanner, implementing a simple version of a semi-join.
针对hash join和aggregation操作,impala使用一种分区方法:每一行记录的hash值中的一些位用于确定目标分区,其他位用于hash table探查;当hash table数据全部在内存中时,分区的开销很小,大概只有10%;当有内存压力时,一些分区可能被输出到磁盘,这样释放内存使得其他分区可以完成计算;
1 Runtime Code Generation

Runtime code generation using LLVM is one of the techniques employed extensively by Impala's backend to improve execution times. Performance gains of 5x or more are typical for representative workloads.
基于LLVM的运行时代码生成可以提升5倍性能;
2 I/O Management
Efficiently retrieving data from HDFS is a challenge for all SQL-on-Hadoop systems. In order to perform data scans from both disk and memory at or near hardware speed, Impala uses an HDFS feature called short-circuit local reads to bypass the DataNode protocol when reading from local disk. Impala can read at almost disk bandwidth (approx.100MB/s per disk) and is typically able to saturate all available disks. We have measured that with 12 disks, Impala is capable of sustaining I/O at 1.2GB/sec. Furthermore, HDFS caching allows Impala to access memory-resident data at memory bus speed and also saves CPU cycles as there is no need to copy data blocks and/or checksum them.
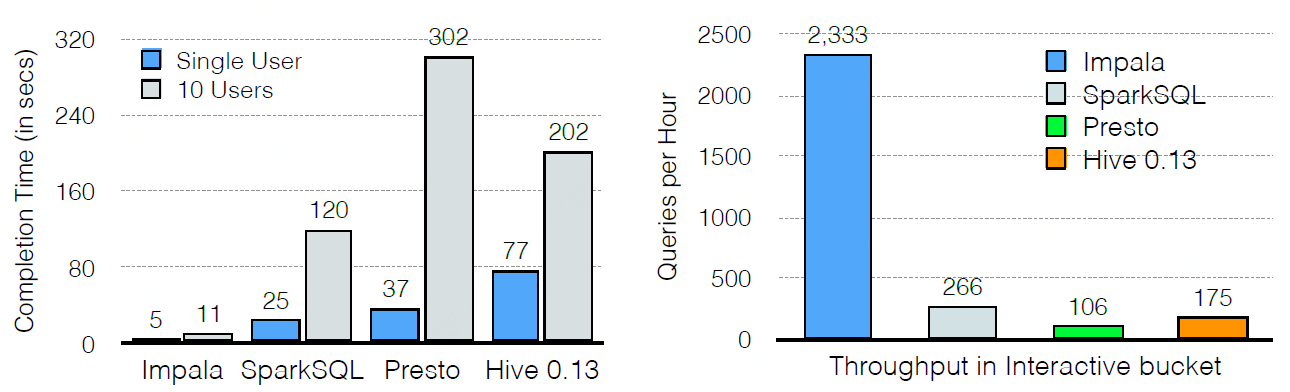
The effectiveness of Impala's I/O manager was that Impala's read throughput is from 4x up to 8x higher than the other tested systems.
impala使用short-circuit local reads来绕过DataNode来直接读取本地磁盘,这使得impala可以用磁盘带宽(每个磁盘100M/s)来读;
impala高效的IO管理可以将读性能提升4到8倍;
3 Storage Formats

Impala supports most popular file formats: Avro, RC, Sequence, plain text, and Parquet. These formats can be combined with diffierent compression algorithms, such as snappy, gzip, bz2.
In most use cases we recommend using Apache Parquet, a state-of-the-art, open-source columnar file format offering both high compression and high scan efficiency. It was co-developed by Twitter and Cloudera with contributions from Criteo, Stripe, Berkeley AMPlab, and LinkedIn. In addition to Impala, most Hadoop-based processing frameworks including Hive, Pig, MapReduce and Cascading are able to process Parquet.
Parquet consistently outperforms by up to 5x all the other formats.
impala支持大部分常见的文件格式以及压缩算法;
Parquet可以提升5倍性能;
与其他engine的对比
volcano:https://paperhub.s3.amazonaws.com/dace52a42c07f7f8348b08dc2b186061.pdf
参考:http://cidrdb.org/cidr2015/Papers/CIDR15_Paper28.pdf
【原创】大数据基础之Impala(2)实现细节的更多相关文章
- 【原创】大数据基础之Impala(1)简介、安装、使用
impala2.12 官方:http://impala.apache.org/ 一 简介 Apache Impala is the open source, native analytic datab ...
- 【原创】大数据基础之Impala(3)部分调优
1)将coordinator和executor角色分离 By default, each host in the cluster that runs the impalad daemon can ac ...
- 【原创】大数据基础之Zookeeper(2)源代码解析
核心枚举 public enum ServerState { LOOKING, FOLLOWING, LEADING, OBSERVING; } zookeeper服务器状态:刚启动LOOKING,f ...
- 【原创】大数据基础之Benchmark(2)TPC-DS
tpc 官方:http://www.tpc.org/ 一 简介 The TPC is a non-profit corporation founded to define transaction pr ...
- 【原创】大数据基础之词频统计Word Count
对文件进行词频统计,是一个大数据领域的hello word级别的应用,来看下实现有多简单: 1 Linux单机处理 egrep -o "\b[[:alpha:]]+\b" test ...
- 大数据基础知识:分布式计算、服务器集群[zz]
大数据中的数据量非常巨大,达到了PB级别.而且这庞大的数据之中,不仅仅包括结构化数据(如数字.符号等数据),还包括非结构化数据(如文本.图像.声音.视频等数据).这使得大数据的存储,管理和处理很难利用 ...
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
- 大数据基础知识问答----hadoop篇
handoop相关知识点 1.Hadoop是什么? Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速 ...
- hadoop大数据基础框架技术详解
一.什么是大数据 进入本世纪以来,尤其是2010年之后,随着互联网特别是移动互联网的发展,数据的增长呈爆炸趋势,已经很难估计全世界的电子设备中存储的数据到底有多少,描述数据系统的数据量的计量单位从MB ...
随机推荐
- WSL、Git on Windows 、Putty等的创建的rsa秘钥与连接linux的使用。
1. 在windows 上面可以使用多种方式创建公钥和私钥 这里从一开始说: 1.1 windows subsystem linux 的方式最简单了 cmd 命令行 下 进入 WSL 输入命令 bas ...
- MIUI9 解锁并刷入TWRP后,删除解锁密码
如果因为某种原因导致解锁密码失效(比如刷了其他ROM),还原备份回来之后,解锁密码失效了. 那么可以进入TWRP,然后通过 adb shell 进入\data\system\文件夹 用rm命令删除g ...
- linux添加超级管理员用户,修改,删除用户
useradd一个用户后,去修改/etc/passwd文件中的这个用户这一行,把其中的uid改为0,gid改为0(其中****代表一个用户名)这样****就具有root权限了 如:root2:x:0: ...
- 微言netty:不在浮沙筑高台
1. 写作缘起 几年前,我在一家农业物联网公司,负责解决其物联网产品线.我们当时基于.net平台打造了一套实时数据采集系统,可以把数以百万级的传感器传送回来的数据采集入库并根据这些数据进行建模.在搭建 ...
- Django组件之Form表单
一.Django中的Form表单介绍 我们之前在HTML页面中利用form表单向后端提交数据时,都会写一些获取用户输入的标签并且用form标签把它们包起来. 与此同时我们在好多场景下都需要对用户的输入 ...
- Flask上下文管理、session原理和全局g对象
一.一些python的知识 1.偏函数 def add(x, y, z): print(x + y + z) # 原本的写法:x,y,z可以传任意数字 add(1,2,3) # 如果我要实现一个功能, ...
- 第六十六天 js操作高级
1.对象使用的高级 对象的key为字符类型,value为任意类型 var obj ={ name:"name", "person-age":18 } // 访问 ...
- Python 正则处理_re模块
正则表达式 动机 文本处理成为计算机常见工作之一 对文本内容搜索,定位,提取是逻辑比较复杂的工作 为了快速方便的解决上述问题,产生了正则表达式技术 定义 文本的高级匹配模式, 提供搜索, 替换, 本质 ...
- JavaScript- BOM, DOM
BOM Browser Object Model 浏览器对象模型, 提供与浏览器窗口进行交互的方法 它使 JavaScript 有能力与浏览器进行“对话”. BOM 最主要的对象就是 window 对 ...
- 【转】 如何重写hashCode()和equals()方法
转自:http://blog.csdn.net/neosmith/article/details/17068365 hashCode()和equals()方法可以说是Java完全面向对象的一大特色.它 ...