增长中的时间序列存储(Scaling Time Series Data Storage) - Part I
本文摘译自 Netflix TechBlog : Scaling Time Series Data Storage — Part I
重点:扩容、缓存、冷热分区、分块。
时序数据 - 会员观看历史
Netflix的用户,每天观看1.4亿小时的内容。每位用户在查看影片和保存观看记录的时候,都会提供几个数据点。Netflix分析这些观看数据并且提供实时的精确书签和个性化推荐。
观看历史数据在如下三个方面增长:
- 随着时间进展,每位会员都会有更多的观看数据需要被保存。
- 随着会员数量增长,更多的会员的观看数据需要被保存。
- 会员每月观看时间在增加,每位会员都有更多的观看数据需要被保存。
随着Netflix在第一个十年增长到了1亿全球会员,这里有观看历史数据也有了巨大的增长。这边文章重点关注,怎样面对持续增长的观看历史数据的巨大挑战。
简单的开始
第一个云原生的版本使用了Cassandra。
在最初的版本里,每位会员的观看数据被以一个单独行保存在了Cassandra里。这使得会员增长的扩容变得很高效,并且读一位会员的完整观看记录变得简单高效。但是随着会员的增加,更重要的是每位会员观看了更多的影片,每行的大小以及总体的大小都在增长。
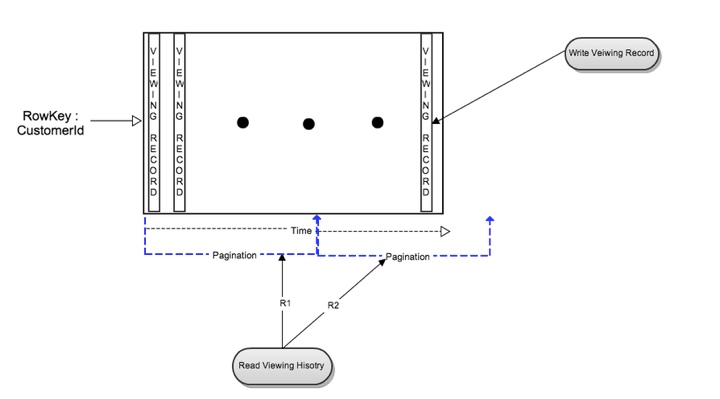
当每位会员的观看数据变多的时候,读有很多列的行就会成为很大的压力。
缓存层
Cassandra在写观看历史数据方面工作的很好,但是需要去优化读延迟的问题。为了优化读延迟,在增加写工作的代价下,我们在Cassandra存储前添加了一个内存中的分片缓存层(EVCache)。每个想Cassandra的写,都会导致一个额外的缓存查找,并且在缓存命中的时候新数据会和已存在的值合并。观看历史读请求会先被缓存服务。如果缓存未命中,条目会从Gassandra中读取,并且被压缩然后插入到缓存中。
配合着额外的缓存层,单一的Cassandra表存储方式在很多年都工作的很好。基于CustomerId的分区,在Cassandra集群上也扩容的很好。到2012年,观看历史的Cassandra集群,已经是Netflix最大的Cassandra集群。
重新设计:实时和压缩存储方式
为了可以设计出足以满足未来5年增长预期的方式,团队分析了数据的特点和数据模式,然后围绕两个主要目标重新设计了观看历史的存储:
- 更小的存储空间。
- 随着每位会员的观看增长,保持读写性能的一致性。
对于每位会员,观看历史数据被分成了两个部分:
- 实时或者最近观看历史(LiveVH): 更少数量的最近观看记录,更频繁的更新。这部分数据以未压缩的格式,保存在上述的简单设计里。
- 压缩或者归档的观看历史(CompressedVH): 更大数量的老观看记录,更少的更新。数据被压缩以减少存储空间。压缩后的观看记录,保存在每个row key中的单一行里。
LiveVH和CompressedVh呗保存在不同的表里,并且经过不同的调校去达到更好的性能。
写流程
新的观看记录,使用和上边描述一样的方式写入LiveVH。
读流程
为了能够从新设计中获益,观看历史的API被更新增加了带有读最近或全部数据的选项。
- 最近观看历史:对于大多数情况,结果只从LiveVH里读取。限制了数据大小以获得低得多的延迟。
- 完整观看历史:从LiveVH 和 CompressedVH 中并行读来实现。由于数据压缩以及CompressedVH有更少的列,更少的数据被读取;因此读速度有了显著的提高。
CompressedVH 更新流程
在从LiveVH中读观看历史记录的时候,如果记录的数量超过了配置的阈值,最近观看记录会一个后台任务被汇总、压缩、保存在CompressedVH里。汇总的数据会带row key:CustomerId被保存在CompressedVH中。新汇总的记录会被记录版本,并且在被写入后会被读取检查一致性。只有在验证过新版本的一致性后,旧版本的汇总数据会被删除。
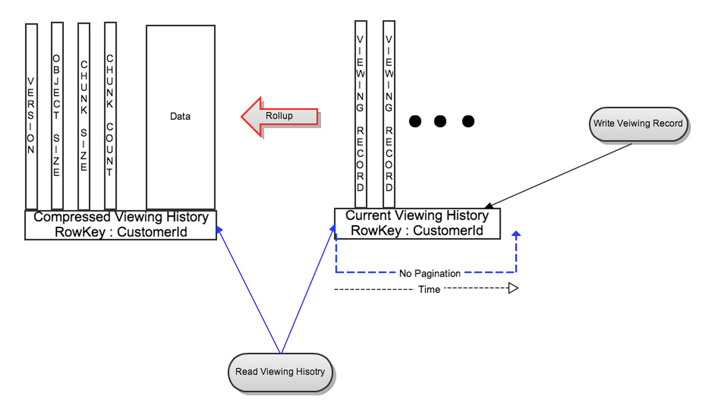
通过分块自动扩容
对于大部分会员来说,在一行里保存压缩后的全部观影数据,在读流程里有着很好的性能。但是由于少量的有着非常大观影历史的会员来说,从CompressedVH的单行里读取记录由于和上述类似的原因开始变慢。所以需要对这种少见的情况有个上限,并且避免影响到正常情况的读写延迟。
为了解决这些问题,如果数据大小超过了配置的阈值,我们会把汇总压缩的数据分成了几块。这些块保存在不同的Cassandra节点上。这样并行读写这些块使得即使非常大的观看记录也可以有个读写延迟的上限。
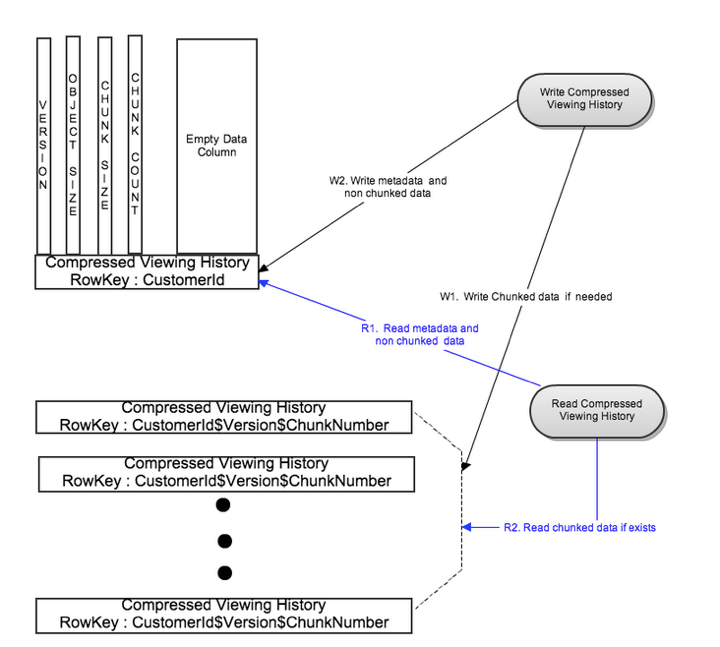
写流程
依照配置的块大小,汇总压缩的数据被拆封到多个块里。所有的块并行写到不同的行里,使用row key: CustomerId$Version$ChunkNumber. 在写完前边的块数据之后,Metadata 被写到他单独的行里,使用row key: CustomerId。
读流程
先通过CustomerId的key读metadata。每次读最多延迟成两次读。
缓存层变化
对于有很大观看记录的会员来说,把全部缓存记录保存在一个EVCache entry是不可能的。所以和CompressedVH模型类似,每个大观看记录缓存单元会被拆成多个块,metadata保存在第一个块里。
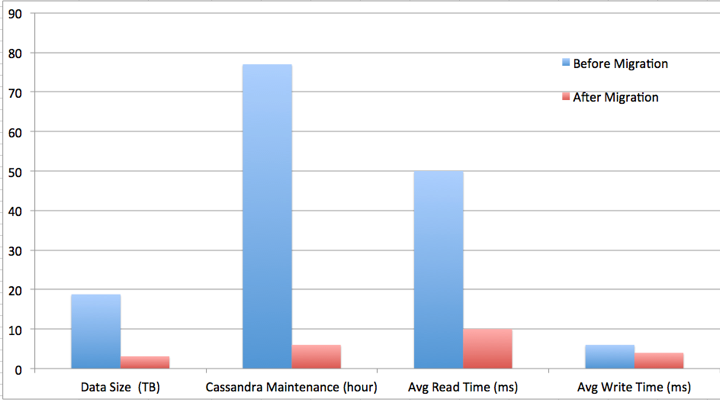
结果
在并行,压缩,和改进过的数据模型的共同作用下,这个团队完成了所有的目标。
- 通过压缩打到更小的存储空间
- 通过分块和并写读写,达到了一致性读写性能。
团队减少了6倍的数据空间,减少13倍的Cassandra的维护时间,减小了5倍的平均读延迟,和1.5倍的平均写延迟。更重要的是,给了团队一个可扩容的架构,和课协调Netflix飞速增长的观看数据的头部空间。
在下一部分,会解释最近的扩容挑战,促进了下一个观看历史数据存储架构的迭代。
增长中的时间序列存储(Scaling Time Series Data Storage) - Part I的更多相关文章
- 时间序列大数据平台建设(Time Series Data,简称TSD)
来源:https://blog.csdn.net/bluishglc/article/details/79277455 引言在大数据的生态系统里,时间序列数据(Time Series Data,简称T ...
- Java实现购物车功能:方式一:存放在session中.方式二:存储在数据库中
//将购物车产品加入到cookie中,方式同浏览记录.Java实现购物车,方式一(简易版):存储在session中.这种方式实现还不严谨,大家看的时候看思路即可.(1). JSP页面中,选择某一款产品 ...
- MySQL存储引擎的实际应用以及对MySQL数据库中各主要存储引擎的独特特点的描述
MySQL存储引擎的实际应用以及对MySQL数据库中各主要存储引擎的独特特点的描述: 1.MySQL有多种存储引擎: MyISAM.InnoDB.MERGE.MEMORY(HEAP).BDB(Berk ...
- 67.Android中的数据存储总结
转载:http://mp.weixin.qq.com/s?__biz=MzIzMjE1Njg4Mw==&mid=2650117688&idx=1&sn=d6c73f9f04d0 ...
- 彻底了解android中的内部存储与外部存储
我们先来考虑这样一个问题: 打开手机设置,选择应用管理,选择任意一个App,然后你会看到两个按钮,一个是清除缓存,另一个是清除数据,那么当我们点击清除缓存的时候清除的是哪里的数据?当我们点击清除数据的 ...
- Android笔记——Android中数据的存储方式(二)
我们在实际开发中,有的时候需要储存或者备份比较复杂的数据.这些数据的特点是,内容多.结构大,比如短信备份等.我们知道SharedPreferences和Files(文本文件)储存这种数据会非常的没有效 ...
- Android笔记——Android中数据的存储方式(一)
Android中数据的存储方式 对于开发平台来讲,如果对数据的存储有良好的支持,那么对应用程序的开发将会有很大的促进作用. 总体的来讲,数据存储方式有三种:一个是文件,一个是数据库,另一个则是网络.其 ...
- ArcGIS Engine开发之旅07---文件地理数据库、个人地理数据库和 ArcSDE 地理数据库中的栅格存储加以比较 、打开栅格数据
原文:ArcGIS Engine开发之旅07---文件地理数据库.个人地理数据库和 ArcSDE 地理数据库中的栅格存储加以比较 .打开栅格数据 对文件地理数据库.个人地理数据库和 ArcSDE 地理 ...
- 彻底理解android中的内部存储与外部存储
我们先来考虑这样一个问题: 打开手机设置,选择应用管理,选择任意一个App,然后你会看到两个按钮,一个是清除缓存,另一个是清除数据,那么当我们点击清除缓存的时候清除的是哪里的数据?当我们点击清除数据的 ...
随机推荐
- SQL反模式学习笔记21 SQL注入
目标:编写SQL动态查询,防止SQL注入 通常所说的“SQL动态查询”是指将程序中的变量和基本SQL语句拼接成一个完整的查询语句. 反模式:将未经验证的输入作为代码执行 当向SQL查询的字符串中插入别 ...
- json,HTTP协议
JSON 语法规则 JSON 语法是 JavaScript 对象表示语法的子集. 数据在名称/值对中 数据由逗号分隔 大括号保存对象 中括号保存数组 JSON 对象 JSON 对象使用在大括号({}) ...
- PSO:利用PSO+ω参数实现对一元函数y = sin(10*pi*x) ./ x进行求解优化,找到最优个体适应度—Jason niu
x = 1:0.01:2; y = sin(10*pi*x) ./ x; figure plot(x, y) title('绘制目标函数曲线图—Jason niu'); hold on c1 = 1. ...
- VsCode创建第一个vue项目
使用vue-cli快速构建项目 vue-cli 是vue.js的脚手架,用于自动生成vue.js模板工程的. 安装vue-cli之前,需要先安装了vue和webpack · node -v ...
- js为什么是单线程的?10分钟了解js引擎的执行机制
深入理解JS引擎的执行机制 1.JS为什么是单线程的? 为什么需要异步? 单线程又是如何实现异步的呢? 2.JS中的event loop(1) 3.JS中的event loop(2) 4.说说setT ...
- Django——图书管理系统
基于Django的图书管理系统 1.主体功能 1.列出图书列表.出版社列表.作者列表 2.点击作者,会列出其出版的图书列表 3.点击出版社,会列出旗下图书列表 4.可以创建.修改.删除 图书.作者.出 ...
- Urozero Autumn 2016. BAPC 2016
A. Airport Logistics 根据光路最快原理以及斯涅尔定律,可以得到从定点$P$进入某条直线的最佳入射角. 求出每个端点到每条线段的最佳点,建图求最短路即可. 时间复杂度$O(n^2\l ...
- Nested Dolls 贪心 + dp
G: Nested Dolls Time Limit: 1 Sec Memory Limit: 128 Mb Submitted: 99 Solved: 19 Descript ...
- 查看Linux系统软硬件信息
查看Linux系统软硬件信息 查看计算机CPU信息 cat /proc/cpuinfo 查看文件系统信息 cat /proc/filesystems 查看主机中断信息 cat /proc/interr ...
- Codechef August Challenge 2018 : Chef at the River
传送门 (要是没有tjm(Sakits)的帮忙,我还真不知道啥时候能做出来 结论是第一次带走尽可能少的动物,使未带走的动物不冲突,带走的这个数量就是最优解. 首先这个数量肯定是下界,更少的话连第一次都 ...