note 9 列表、时间复杂度、排序
列表 List
+内建(built-in)数据结构(data structure),用来存储一系列元素(items)
如:lst = [5.4,'hello',2]

前向索引、后向索引、切片、拼接、成员、长度...
列表与字符串
+相同点
索引( [ ] 运算符)
切片( [:] )
拼接( + )和重复( * )
成员( in 运算符 )
长度( len() 函数 )
循环( for )
+不同点
使用 [ ] 生成,元素之间用逗号分隔
可以包含多种类型的对象;字符串只能是字符
内容是可变的;字符串是不可变的
列表的方法
+列表的内容是可变的
my list[0] = 'a'
my list[0:2] = [1.2,3,5.6]
my list.append()#追加元素 改变内容
my list.extend()#追加列表
my list.insert()#任意位置插入元素
my list.pop(),my list.remove()#删除元素 删除某个下标的元素
my list.remove(5)#删除元素,删除某内容
my list.sort()#排序
my list.reverse()#逆序
...
读取10个数字,并计算平均数
内建函数sum
avg = sum(nums) / len(nums)
max
min
...
nums = []
for i in range(10):
nums.append(float(raw_input()))
avg = sum(nums) / len(nums)
print avg
列表赋值
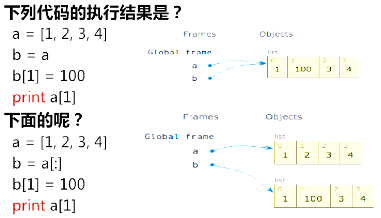
列表做函数参数
交换列表中两个元素的函数

示例:查找
1.返回下标
def search(lst,x):
for i in range(len(lst)):
if lst[i] == x:
return i
return -1
lst = [10,5,8,13]
print search(lst,8)
2.返回下标
index()方法
[1,2,3],index(2)
返回第一次的下标
要查找的元素不在列表中 会抛出异常,ValueError: 7 is not in list
lst = [10,5,8,13]
print lst.index(7)
线性查找
最坏运行时间:k0n+k1
时间复杂度
+量化一个算法的运行时间为输入长度的函数
+不需要显式的计算这些常数
如:4n+10和100n+137都与输入规模成正比
+大O表示,只保留高阶项
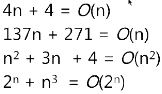
+线性查找的时间复杂度为:O(n)
+大O能告诉我们什么?
如果算法A的复杂度为O(n),算法B的复杂度为O(n^2),对于较大的输入,A总是比B快
如果算法A的复杂度为O(n),当输入规模翻倍时,运行时间也翻倍
+大O不能告诉我们什么?
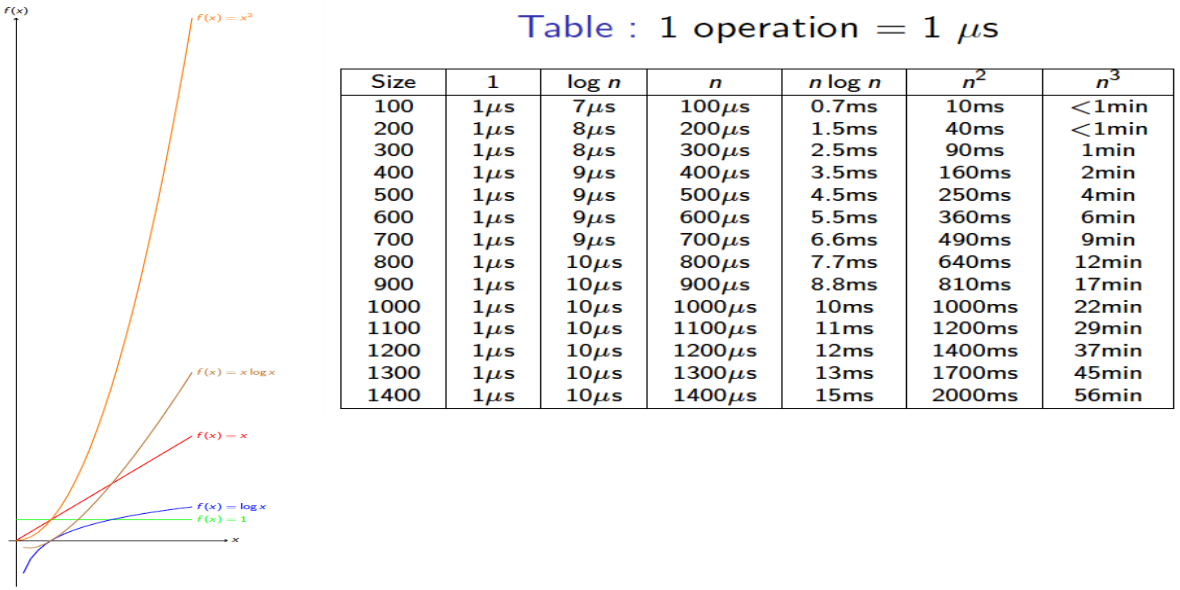
实际运行时间
对于小规模输入的行为

函数的增长率
二分查找
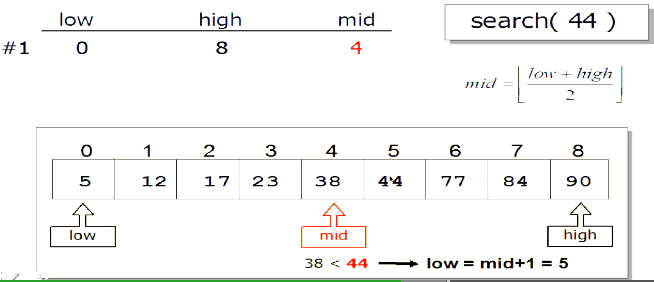
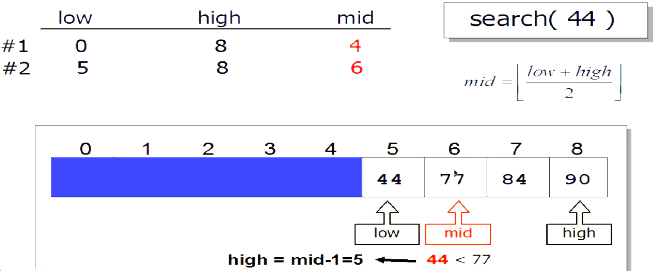
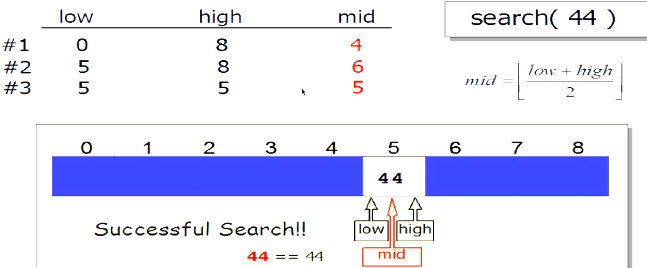
不一定是元素第一次出现位置的下标
def bi_search(lst,x):
low = 0
high = len(lst) - 1
while low <= high:
mid = (low + high) / 2
if lst[mid] == x:
return mid
elif lst[mid] > x:
high - mid - 1
else :
low = mid + 1
return - 1
lst = [5,8,10,13]
print bi_search(lst,5)
二分查找的时间复杂度:

排序 Sort
+将一个无序列表,按照某一顺序(由小到大或由大到小)排列
+是计算机科学中常见而且重要的任务
+有许多不同的算法,最简单直观的为以下两种
选择排序 selection sort
冒泡排序 bubble sort
选择排序
找到最小的元素
删除它,然后将其插入相应的位置
对于剩余元素,重复步骤1
def selection_sort(lst):
for i in range(len(lst)):
min_index = i
for j in range(i + 1,len(lst)):
if lst[j] < lst[min_index]:
min_index = j
lst.insert(i,lst.pop(min_index))
lst = [10,8,5,13]
selection_sort(lst)
print lst
找到最小的元素
和第一个元素交换
对于剩余的元素,重复步骤1和2
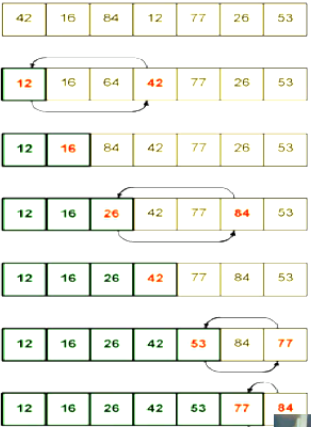
def swap(lst,i,j):
tmp = lst[i]
lst[i] = lst[j]
lst[j] = tmp
def selection_sort(lst):
for i in range(len(lst)):
min_index = i
for j in range(i + 1,len(lst)):
if lst[j] < lst[min_index]:
min_index = j
swap(lst,i,min_index)
lst = [10,8,5,13]
selection_sort(lst)
print lst
选择排序的时间复杂度

冒泡排序
与选择排序类似,但是每次遍历不止交换一次
每次遍历,将最大的值排在最后
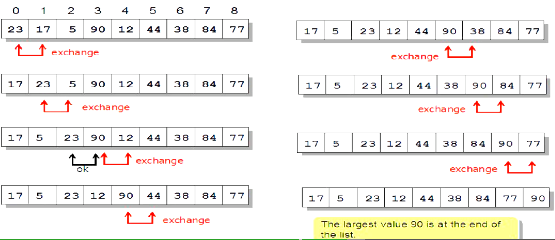
+提示:一单列表排好序,算法可以停止
def swap(lst,i,j):
tmp = lst[i]
lst[i] = lst[j]
lst[j] = tmp
def bubble_sort(lst):
top = len(lst) - 1
is_exchanged = True
while is_exchanged:
is_exchanged = False
for i in range(top):
if lst[i] > lst[i + 1]:
is_exchanged = True
swap(lst,i,i + 1)
top -= 1
lst = [12,10,8,5,13]
bubble_sort(lst)
print lst
时间复杂度 O(n^2),与选择排序相同,但是通常速度更快
内建排序函数
sorted()函数
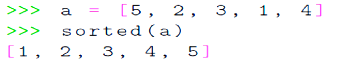
list.sort()方法

算法:quicksort
时间复杂度:
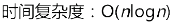
比选择和冒泡排序更快
嵌套列表
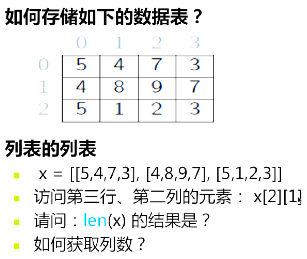
计算所有学生平均分
students = [['Zhang',84],['Wang',98],['Li',76]]
s = 0
for student in students:
s += student[1]
print float(s) / len(students)
列表的解析或列表的推导 List Comprehension
+一种有原列表创建新列表的简洁方法
[表达式 for 变量 in 列表 if 条件]

lst = [x**2 for x in range(1,10)]
列表推导实现求平均分
students = [['Zhang',84],['Wang',98],['Li',76]]
print float(sum([x[1] for x in students])) / len(students)
使用列表解析对所输入数字x的因素求和
如:如果输入6,应该显示12,即1+2+3+6 = 12
sum([i for i in range(1,x + 1)if x % i == 0])
按照成绩由高到低排序
1.
students = [['Zhang',84],['Wang',98],['Li',76]]
def f(a):
return a[1]
students.sort(key = f , reverse = True)
print students
2.使用 lambda 函数
+定义匿名函数

没法直接调用,需要赋值给变量
students = [['Zhang',84],['Wang',98],['Li',76]]
students.sort(key = lambda x: x[1] , reverse = True)
print studentsnote 9 列表、时间复杂度、排序的更多相关文章
- 2019年6月12日——开始记录并分享学习心得——Python3.7中对列表进行排序
Python中对列表的排序按照是排序是否可以恢复分为:永久性排序和临时排序. Python中对列表的排序可以按照使用函数的不同可以分为:sort( ), sorted( ), reverse( ). ...
- Python要如何实现(列表)排序?
排序,是许多编程语言中经常出现的问题.同样的,在Python中,如何是实现排序呢?(以下排序都是基于列表来实现) 一.使用Python内置函数进行排序 Python中拥有内置函数实现排序,可以直接调用 ...
- easyui datagrid 点击列表头排序出现错乱的原因
之前我的导师,也就是带我的同事,使用datagrid,发现点击列表头排序出现乱序,按理说只有顺序和逆序两种排序结果.因为他比较忙,当时没解决,把排序禁掉了,后来又要求一定要排序,所以他交给我. 一开始 ...
- Python list列表的排序
当我们从数据库中获取一写数据后,一般对于列表的排序是经常会遇到的问题,今天总结一下python对于列表list排序的常用方法: 第一种:内建函数sort() 这个应该是我们使用最多的也是最简单的排序函 ...
- python内置数据类型-字典和列表的排序 python BIT sort——dict and list
python中字典按键或键值排序(我转!) 一.字典排序 在程序中使用字典进行数据信息统计时,由于字典是无序的所以打印字典时内容也是无序的.因此,为了使统计得到的结果更方便查看需要进行排序. Py ...
- [转载]EF或LINQ 查询时使用IN并且根据列表自定义排序方法
原文地址:EF或LINQ 查询时使用IN并且根据列表自定义排序方法作者:李明川 EF和LINQ改变了原有的手写SQL时期的一些编码方法,并且增强了各数据库之间的移植性简化了开发时的代码量和难度,由于很 ...
- iRSF快速简单易用的实现列表、排序、过滤功能
IRSF 是由javascript编写,iRSF快速简单易用的实现列表.排序.过滤功能(该三种操作以下简称为 RSF ). iRSF由三个类组成. iRSFSource 数据源 iRSFFilter ...
- Python 列表元素里面含有字典或者列表进行排序
示例1:列表里面含有列表进行排序 s = [[1, 2], [100, 2], [33, 3], [25, 6]] s.sort(key=lambda k: k[0]) print(s) 结果: [[ ...
- Java对数组和列表的排序1.8新特性
Java对数组列表的排序 数组 Integer[] a = new Integer[] { 1, 2, 3, 4, 5, 6, 9, 8, 7, 4, 5, 5, 6, 6 }; Arrays.sor ...
随机推荐
- 易语言Dns缓存
一些与DNS解析有关的命令: ipconfig/displaydns -查看被缓存的域名解析 ipconfig/flushdns -清空DNS缓存 .版本 .DLL命令 DnsFlushR ...
- python之路之简单介绍:
python介绍: a. python 基础 - 基础 - 基本的数据类型 - 函数 - 面向对象 python 安装 python 安装在os上 执行操作: 写一个文件,文件中按照python规则写 ...
- ubuntu16.04微信安装
1.下载: git clone https://github.com/geeeeeeeeek/electronic-wechat/releases 2.移动微信客户端(下载解压重命名为wechat)到 ...
- ionic3/4 使用NavController 返回两层的方式
ionic3/4 使用NavController 返回两层的方式: this.navCtrl.popTo(this.navCtrl.length() - 3);
- flashback_scn导出
1.应用场景2.oracle实现该技术的原理理论,及限制3.实操及与scn时间相关的函数查询 一.flashback_scn导出1) OGG同步,对表的数据进行同步,第一次可以完全导出,中途如果由于某 ...
- UML第一次作业:UML用例图绘制
UML用例图绘制 一.plantuml用例图语法小结 1.用例 用法:用例用圆括号(),或者使用关键字来定义用例 示例1: @startuml (First UML) (Another UML)a ...
- string 迭代器
#include <iostream>#include <string>#include<algorithm>#define m 10000000using nam ...
- java-16习题
编写程序,产生10组彩票的“35选7”玩法的7个随机数.(-)随机数不能重复. 范围[,) import java.util.Iterator; import java.util.Random; im ...
- java-15习题
通过键盘分别输入年份.月份.日把它存储到日期时间对象中,然后计算1000天以后的日期并输出. import java.util.Calendar; import java.util.Scanner; ...
- 如何使用 Pylint 来规范 Python 代码风格
如何使用 Pylint 来规范 Python 代码风格 转载自https://www.ibm.com/developerworks/cn/linux/l-cn-pylint/ Pylint 是什么 ...