Batch Normalization原理
Batch Normalization导读
博客转载自:https://blog.csdn.net/malefactor/article/details/51476961
作者: 张俊林
为什么深度神经网络随着网络深度加深,训练起来越困难,收敛越来越慢?这是个在DL领域很接近本质的好问题。很多论文都是解决这个问题的,比如ReLU激活函数,再比如Residual Network,BN本质上也是解释并从某个不同的角度来解决这个问题的。
“Internal Covariate Shift”问题从论文名字可以看出,BN是用来解决“InternalCovariate Shift”问题的,那么首先得理解什么是“Internal Covariate Shift”?
论文首先说明Mini-Batch SGD相对于One Example SGD的两个优势:梯度更新方向更准确;并行计算速度快;(本文作者:为啥要说这些?因为BatchNorm是基于Mini-Batch SGD的,所以先夸下Mini-Batch SGD,当然也是大实话);
然后吐槽下SGD训练的缺点:超参数调起来很麻烦。(本文作者:作者隐含意思是用我大BN就能解决很多SGD的缺点:用了大BN,妈妈再也不用担心我的调参能力啦)
接着引入covariate shift的概念:如果ML系统实例集合<X,Y>中的输入值X的分布老是变,这不符合IID假设啊,那您怎么让我稳定的学规律啊,这不得引入迁移学习才能搞定吗,我们的ML系统还得去学习怎么迎合这种分布变化啊。
对于深度学习这种包含很多隐层的网络结构,在训练过程中,因为各层参数老在变,所以每个隐层都会面临covariate shift的问题,也就是在训练过程中,隐层的输入分布老是变来变去,这就是所谓的“Internal Covariate Shift”,Internal指的是深层网络的隐层,是发生在网络内部的事情,而不是covariate shift问题只发生在输入层。
然后提出了BatchNorm的基本思想:能不能让每个隐层节点的激活输入分布固定下来呢?这样就避免了“Internal Covariate Shift”问题了。
BN不是凭空拍脑袋拍出来的好点子,它是有启发来源的:之前的研究表明如果在图像处理中对输入图像进行白化(Whiten)操作的话——所谓白化,就是对输入数据分布变换到0均值,单位方差的正态分布——那么神经网络会较快收敛,那么BN作者就开始推论了:图像是深度神经网络的输入层,做白化能加快收敛,那么其实对于深度网络来说,其中某个隐层的神经元是下一层的输入,意思是其实深度神经网络的每一个隐层都是输入层,不过是相对下一层来说而已,那么能不能对每个隐层都做白化呢?这就是启发BN产生的原初想法,而BN也确实就是这么做的,可以理解为对深层神经网络每个隐层神经元的激活值做简化版本的白化操作。
BatchNorm的本质思想
BN的基本思想其实相当直观:因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致后向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因,而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正太分布而不是萝莉分布(哦,是正态分布),其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
THAT’S IT。其实一句话就是:对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。因为梯度一直都能保持比较大的状态,所以很明显对神经网络的参数调整效率比较高,就是变动大,就是说向损失函数最优值迈动的步子大,也就是说收敛地快。BN说到底就是这么个机制,方法很简单,道理很深刻。
上面说得还是显得抽象,下面更形象地表达下这种调整到底代表什么含义。
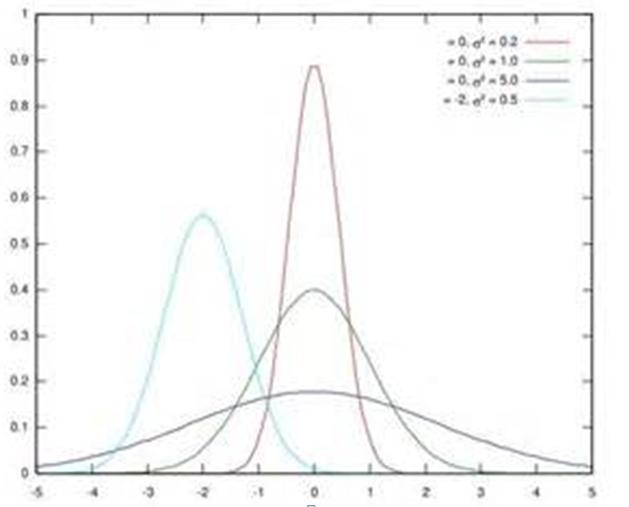
图1. 几个正态分布
假设某个隐层神经元原先的激活输入x取值符合正态分布,正态分布均值是-2,方差是0.5,对应上图中最左端的浅蓝色曲线,通过BN后转换为均值为0,方差是1的正态分布(对应上图中的深蓝色图形),意味着什么,意味着输入x的取值正态分布整体右移2(均值的变化),图形曲线更平缓了(方差增大的变化)。这个图的意思是,BN其实就是把每个隐层神经元的激活输入分布从偏离均值为0方差为1的正态分布通过平移均值压缩或者扩大曲线尖锐程度,调整为均值为0方差为1的正态分布。
那么把激活输入x调整到这个正态分布有什么用?
首先我们看下均值为0,方差为1的标准正态分布代表什么含义:
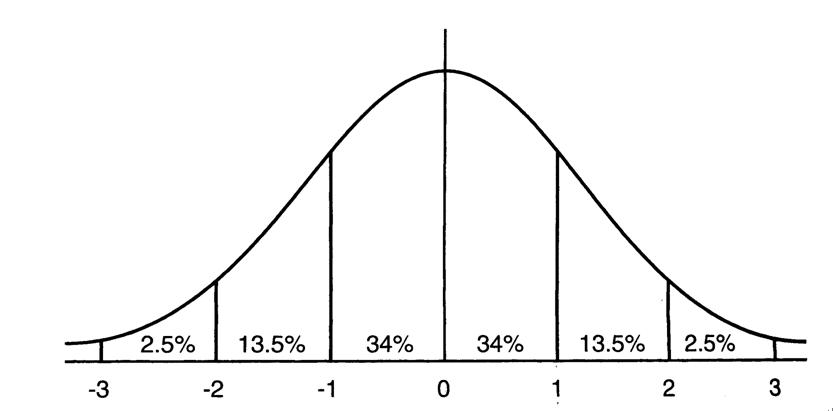
图2.均值为0方差为1的标准正态分布图
这意味着在一个标准差范围内,也就是说68%的概率x其值落在[-1,1]的范围内,在两个标准差范围内,也就是说95%的概率x其值落在了[-2,2]的范围内。那么这又意味着什么?我们知道,激活值x=WU+B,U是真正的输入,x是某个神经元的激活值,假设非线性函数是sigmoid,那么看下sigmoid(x)其图形:
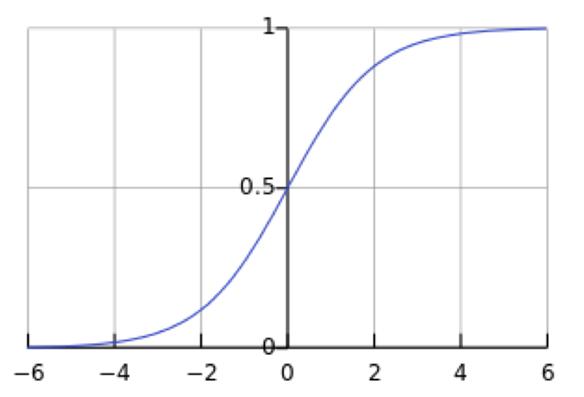
图3. Sigmoid(x)
及sigmoid(x)的导数为:G’=f(x)*(1-f(x)),因为f(x)=sigmoid(x)在0到1之间,所以G’在0到0.25之间,其对应的图如下:
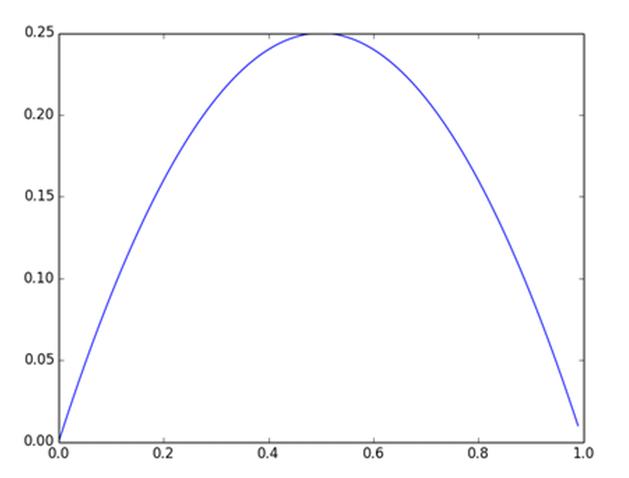
图4. Sigmoid(x)导数图(导数图x轴的范围有误,应该是负无穷到正无穷)
假设没有经过BN调整前x的原先正态分布均值是-6,方差是1,那么意味着95%的值落在了[-8,-4]之间,那么对应的Sigmoid(x)函数的值明显接近于0,这是典型的梯度饱和区,在这个区域里梯度变化很慢,为什么是梯度饱和区?请看下sigmoid(x)如果取值接近0或者接近于1的时候对应导数函数取值,接近于0,意味着梯度变化很小甚至消失。而假设经过BN后,均值是0,方差是1,那么意味着95%的x值落在了[-2,2]区间内,很明显这一段是sigmoid(x)函数接近于线性变换的区域,意味着x的小变化会导致非线性函数值较大的变化,也即是梯度变化较大,对应导数函数图中明显大于0的区域,就是梯度非饱和区。
从上面几个图应该看出来BN在干什么了吧?其实就是把隐层神经元激活输入x=WU+B从变化不拘一格的正态分布通过BN操作拉回到了均值为0,方差为1的正态分布,即原始正态分布中心左移或者右移到以0为均值,拉伸或者缩减形态形成以1为方差的图形。什么意思?就是说经过BN后,目前大部分Activation的值落入非线性函数的线性区内,其对应的导数远离导数饱和区,这样来加速训练收敛过程。
但是很明显,看到这里,稍微了解神经网络的读者一般会提出一个疑问:如果都通过BN,那么不就跟把非线性函数替换成线性函数效果相同了?这意味着什么?我们知道,如果是多层的线性函数变换其实这个深层是没有意义的,因为多层线性网络跟一层线性网络是等价的。这意味着网络的表达能力下降了,这也意味着深度的意义就没有了。所以BN为了保证非线性的获得,对变换后的满足均值为0方差为1的x又进行了scale加上shift操作(y=scale*x+shift),每个神经元增加了两个参数scale和shift参数,这两个参数是通过训练学习到的,意思是通过scale和shift把这个值从标准正态分布左移或者由移一点并长胖一点或者变瘦一点,每个实例挪动的程度不一样,这样等价于非线性函数的值从正中心周围的线性区往非线性区动了动。核心思想应该是想找到一个线性和非线性的较好平衡点,既能享受非线性的较强表达能力的好处,又避免太靠非线性区两头使得网络收敛速度太慢。当然,这是我的理解,论文作者并未明确这样说。但是很明显这里的scale和shift操作是会有争议的,因为按照论文作者论文里写的理想状态,就会又通过scale和shift操作把变换后的x调整回未变换的状态,那不是饶了一圈又绕回去原始的“Internal Covariate Shift”问题里去了吗,感觉论文作者并未能够清楚地解释scale和shift操作的理论原因。
训练阶段如何做BatchNorm
上面是对BN的抽象分析和解释,具体在Mini-Batch SGD下做BN怎么做?其实论文里面这块写得很清楚也容易理解。为了保证这篇文章完整性,这里简单说明下。
假设对于一个深层神经网络来说,其中两层结构如下:
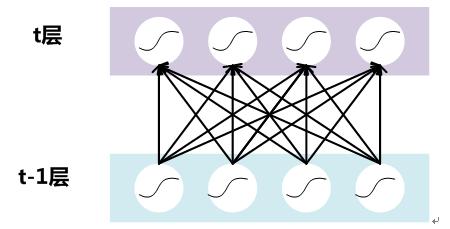
图5. DNN其中两层
要对每个隐层神经元的激活值做BN,可以想象成每个隐层又加上了一层BN操作层,它位于X=WU+B激活值获得之后,非线性函数变换之前,其图示如下:
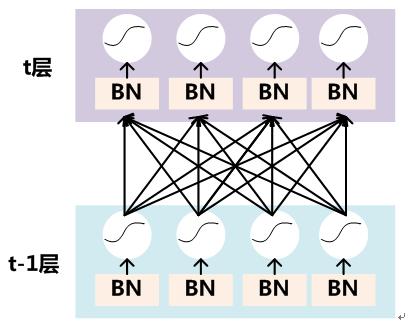
图6. BN操作
对于Mini-Batch SGD来说,一次训练过程里面包含m个训练实例,其具体BN操作就是对于隐层内每个神经元的激活值来说,进行如下变换:
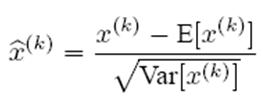
要注意,这里t层某个神经元的x(k)不是指原始输入,就是说不是t-1层每个神经元的输出,而是t层这个神经元的激活x=WU+B,这里的U才是t-1层神经元的输出。
变换的意思是:某个神经元对应的原始的激活x通过减去mini-Batch内m个实例获得的m个激活x求得的均值E(x)并除以求得的方差Var(x)来进行转换。
上文说过经过这个变换后某个神经元的激活x形成了均值为0,方差为1的正态分布,目的是把值往后续要进行的非线性变换的线性区拉动,增大导数值,增强反向传播信息流动性,加快训练收敛速度。但是这样会导致网络表达能力下降,为了防止这一点,每个神经元增加两个调节参数(scale和shift),这两个参数是通过训练来学习到的,用来对变换后的激活反变换,使得网络表达能力增强,即对变换后的激活进行如下的scale和shift操作,这其实是变换的反操作:
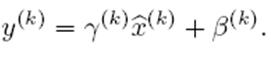
BN其具体操作流程,如论文中描述的一样:

过程非常清楚,就是上述公式的流程化描述,这里不解释了,直接应该能看懂。
|BatchNorm的推理过程
BN在训练的时候可以根据Mini-Batch里的若干训练实例进行激活数值调整,但是在推理(inference)的过程中,很明显输入就只有一个实例,看不到Mini-Batch其它实例,那么这时候怎么对输入做BN呢?因为很明显一个实例是没法算实例集合求出的均值和方差的。这可如何是好?这可如何是好?这可如何是好?
既然没有从Mini-Batch数据里可以得到的统计量,那就想其它办法来获得这个统计量,就是均值和方差。可以用从所有训练实例中获得的统计量来代替Mini-Batch里面m个训练实例获得的均值和方差统计量,因为本来就打算用全局的统计量,只是因为计算量等太大所以才会用Mini-Batch这种简化方式的,那么在推理的时候直接用全局统计量即可。
决定了获得统计量的数据范围,那么接下来的问题是如何获得均值和方差的问题。很简单,因为每次做Mini-Batch训练时,都会有那个Mini-Batch里m个训练实例获得的均值和方差,现在要全局统计量,只要把每个Mini-Batch的均值和方差统计量记住,然后对这些均值和方差求其对应的数学期望即可得出全局统计量,即:
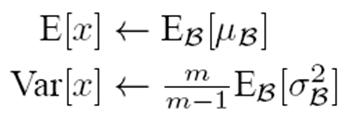
有了均值和方差,每个隐层神经元也已经有对应训练好的Scaling参数和Shift参数,就可以在推导的时候对每个神经元的激活数据计算NB进行变换了,在推理过程中进行NB采取如下方式:
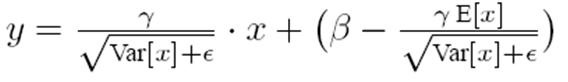
这个公式其实和训练时

是等价的,通过简单的合并计算推导就可以得出这个结论。那么为啥要写成这个变换形式呢?我猜作者这么写的意思是:在实际运行的时候,按照这种变体形式可以减少计算量,为啥呢?因为对于每个隐层节点来说:

都是固定值,这样这两个值可以事先算好存起来,在推理的时候直接用就行了,这样比原始的公式每一步骤都现算少了除法的运算过程,乍一看也没少多少计算量,但是如果隐层节点个数多的话节省的计算量就比较多了。
BatchNorm的好处
BatchNorm为什么NB呢,关键还是效果好。不仅仅极大提升了训练速度,收敛过程大大加快,还能增加分类效果,一种解释是这是类似于Dropout的一种防止过拟合的正则化表达方式,所以不用Dropout也能达到相当的效果。另外调参过程也简单多了,对于初始化要求没那么高,而且可以使用大的学习率等。总而言之,经过这么简单的变换,带来的好处多得很,这也是为何现在BN这么快流行起来的原因。
tensorflow代码:
https://github.com/yongyehuang/Tensorflow-Tutorial/tree/master/models/m01_batch_normalization
1.mnist_cnn.py
# -*- coding:utf-8 -*- """网络结构定义。
关于 tf.layers.batch_normalization() 的理解参考: [tensorflow中batch normalization的用法](https://www.cnblogs.com/hrlnw/p/7227447.html)
""" from __future__ import print_function, division, absolute_import import tensorflow as tf class Model(object):
def __init__(self, settings):
self.model_name = settings.model_name
self.img_size = settings.img_size
self.n_channel = settings.n_channel
self.n_class = settings.n_class
self.drop_rate = settings.drop_rate
self.global_step = tf.Variable(0, trainable=False, name='Global_Step')
self.learning_rate = tf.train.exponential_decay(settings.learning_rate,
self.global_step, settings.decay_step,
settings.decay_rate, staircase=True) self.conv_weight_initializer = tf.contrib.layers.xavier_initializer(uniform=True)
self.conv_biases_initializer = tf.zeros_initializer()
# 最后一个全连接层的初始化
self.fc_weight_initializer = tf.truncated_normal_initializer(0.0, 0.005)
self.fc_biases_initializer = tf.constant_initializer(0.1) # placeholders
with tf.name_scope('Inputs'):
self.X_inputs = tf.placeholder(tf.float32, [None, self.img_size, self.img_size, self.n_channel],
name='X_inputs')
self.y_inputs = tf.placeholder(tf.int64, [None], name='y_input') self.logits_train = self.inference(is_training=True, reuse=False)
self.logits_test = self.inference(is_training=False, reuse=True) # 预测结果
self.pred_lables = tf.argmax(self.logits_test, axis=1)
self.pred_probas = tf.nn.softmax(self.logits_test)
self.test_loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=tf.cast(self.y_inputs, dtype=tf.int32), logits=self.logits_test))
self.test_acc = tf.reduce_mean(tf.cast(tf.equal(self.pred_lables, self.y_inputs), tf.float32)) # 训练结果
self.train_lables = tf.argmax(self.logits_train, axis=1)
self.train_loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=tf.cast(self.y_inputs, dtype=tf.int32), logits=self.logits_train))
self.train_acc = tf.reduce_mean(tf.cast(tf.equal(self.train_lables, self.y_inputs), tf.float32)) self.optimizer = tf.train.AdamOptimizer(learning_rate=self.learning_rate)
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
"""
**注意:** 下面一定要使用这样的方式来写。
with tf.control_dependencies(update_ops) 这句话的意思是当运行下面的内容(train_op) 时,一定先执行 update_ops 的所有操作。
这里的 update_ops 在这里主要是更新 BN 层的滑动平均值和滑动方差。
除了 BN 层外,还有 center loss 中也采用这样的方式,在 center loss 中,update_ops 操作主要更新类中心向量。
因为之前在 center loss 犯过没更新 center 的错误,所以印象非常深刻。
"""
with tf.control_dependencies(update_ops): # 这句话的意思是当运行下面的内容(train_op) 时,一定先执行 update_ops 的所有操作
self.train_op = self.optimizer.minimize(self.train_loss, global_step=self.global_step) def inference(self, is_training, reuse=False):
"""带 BN 层的CNN """
with tf.variable_scope('cnn', reuse=reuse):
# 第一个卷积层 + BN + max_pooling
conv1 = tf.layers.conv2d(self.X_inputs, filters=32, kernel_size=5, strides=1, padding='same',
kernel_initializer=self.conv_weight_initializer, name='conv1')
bn1 = tf.layers.batch_normalization(conv1, training=is_training, name='bn1')
bn1 = tf.nn.relu(bn1) # 一般都是先经过 BN 层再加激活函数的
pool1 = tf.layers.max_pooling2d(bn1, pool_size=2, strides=2, padding='same', name='pool1') # 第二个卷积层 + BN + max_pooling
conv2 = tf.layers.conv2d(pool1, filters=64, kernel_size=5, strides=1, padding='same',
kernel_initializer=self.conv_weight_initializer, name='conv2')
bn2 = tf.layers.batch_normalization(conv2, training=is_training, name='bn2')
bn2 = tf.nn.relu(bn2) # 一般都是先经过 BN 层再加激活函数的
pool2 = tf.layers.max_pooling2d(bn2, pool_size=2, strides=2, padding='same', name='pool2') # 全连接,使用卷积来实现
_, k_height, k_width, k_depth = pool2.get_shape().as_list()
fc1 = tf.layers.conv2d(pool2, filters=1024, kernel_size=k_height, name='fc1')
bn3 = tf.layers.batch_normalization(fc1, training=is_training, name='bn3')
bn3 = tf.nn.relu(bn3) # dropout, 如果 is_training = False 就不会执行 dropout
fc1_drop = tf.layers.dropout(bn3, rate=self.drop_rate, training=is_training) # 最后的输出层
flatten_layer = tf.layers.flatten(fc1_drop)
out = tf.layers.dense(flatten_layer, units=self.n_class)
return out def inference2(self, is_training, reuse=False):
"""不带 BN 层的 CNN。"""
with tf.variable_scope('cnn', reuse=reuse):
# 第一个卷积层 + BN + max_pooling
conv1 = tf.layers.conv2d(self.X_inputs, filters=32, kernel_size=5, strides=1, padding='same',
activation=tf.nn.relu,
kernel_initializer=self.conv_weight_initializer, name='conv1')
pool1 = tf.layers.max_pooling2d(conv1, pool_size=2, strides=2, padding='same', name='pool1') # 第二个卷积层 + BN + max_pooling
conv2 = tf.layers.conv2d(pool1, filters=64, kernel_size=5, strides=1, padding='same',
activation=tf.nn.relu,
kernel_initializer=self.conv_weight_initializer, name='conv2')
pool2 = tf.layers.max_pooling2d(conv2, pool_size=2, strides=2, padding='same', name='pool2') # 全连接,使用卷积来实现
_, k_height, k_width, k_depth = pool2.get_shape().as_list()
fc1 = tf.layers.conv2d(pool2, filters=1024, kernel_size=k_height, activation=tf.nn.relu, name='fc1') # dropout, 如果 is_training = False 就不会执行 dropout
fc1_drop = tf.layers.dropout(fc1, rate=self.drop_rate, training=is_training) # 最后的输出层
flatten_layer = tf.layers.flatten(fc1_drop)
out = tf.layers.dense(flatten_layer, units=self.n_class)
return out
2.train.py
# -*- coding:utf-8 -*- from __future__ import print_function, division, absolute_import import tensorflow as tf
import os
import time from mnist_cnn import Model class Settings(object):
def __init__(self):
self.model_name = 'mnist_cnn'
self.img_size = 28
self.n_channel = 1
self.n_class = 10
self.drop_rate = 0.5
self.learning_rate = 0.001
self.decay_step = 2000
self.decay_rate = 0.5
self.training_steps = 10000 # 耗时 90s
self.batch_size = 100 self.summary_path = 'summary/' + self.model_name + '/'
self.ckpt_path = 'ckpt/' + self.model_name + '/' if not os.path.exists(self.summary_path):
os.makedirs(self.summary_path)
if not os.path.exists(self.ckpt_path):
os.makedirs(self.ckpt_path) def main():
"""模型训练。"""
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("../../data/MNIST_data", one_hot=False)
print(mnist.test.labels.shape)
print(mnist.train.labels.shape) my_setting = Settings()
with tf.variable_scope(my_setting.model_name):
model = Model(my_setting) # 模型要保存的变量
var_list = tf.trainable_variables()
if model.global_step not in var_list:
var_list.append(model.global_step)
# 添加 BN 层的均值和方差
global_vars = tf.global_variables()
bn_moving_vars = [v for v in global_vars if 'moving_mean' in v.name]
bn_moving_vars += [v for v in global_vars if 'moving_variance' in v.name]
var_list += bn_moving_vars
# 创建Saver
saver = tf.train.Saver(var_list=var_list) config = tf.ConfigProto()
config.gpu_options.allow_growth = True
with tf.Session(config=config) as sess:
print("initializing variables.")
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
if os.path.exists(my_setting.ckpt_path + 'checkpoint'):
print("restore checkpoint.")
saver.restore(sess, tf.train.latest_checkpoint(my_setting.ckpt_path))
tic = time.time()
for step in range(my_setting.training_steps):
if 0 == step % 100:
X_batch, y_batch = mnist.train.next_batch(my_setting.batch_size, shuffle=True)
X_batch = X_batch.reshape([-1, 28, 28, 1])
_, g_step, train_loss, train_acc = sess.run(
[model.train_op, model.global_step, model.train_loss, model.train_acc],
feed_dict={model.X_inputs: X_batch, model.y_inputs: y_batch})
X_batch, y_batch = mnist.test.next_batch(my_setting.batch_size, shuffle=True)
X_batch = X_batch.reshape([-1, 28, 28, 1])
test_loss, test_acc = sess.run([model.test_loss, model.test_acc],
feed_dict={model.X_inputs: X_batch, model.y_inputs: y_batch})
print(
"Global_step={:.2f}, train_loss={:.2f}, train_acc={:.2f}; test_loss={:.2f}, test_acc={:.2f}; pass {:.2f}s".format(
g_step, train_loss, train_acc, test_loss, test_acc, time.time() - tic
))
else:
X_batch, y_batch = mnist.train.next_batch(my_setting.batch_size, shuffle=True)
X_batch = X_batch.reshape([-1, 28, 28, 1])
sess.run([model.train_op], feed_dict={model.X_inputs: X_batch, model.y_inputs: y_batch})
if 0 == (step + 1) % 1000:
path = saver.save(sess, os.path.join(my_setting.ckpt_path, 'model.ckpt'),
global_step=sess.run(model.global_step))
print("Save model to {} ".format(path)) if __name__ == '__main__':
main()
3.predict.py
# -*- coding:utf-8 -*- from __future__ import print_function, division, absolute_import import tensorflow as tf
import numpy as np
import os
import time from mnist_cnn import Model class Settings(object):
def __init__(self):
self.model_name = 'mnist_cnn'
self.img_size = 28
self.n_channel = 1
self.n_class = 10
self.drop_rate = 0.5
self.learning_rate = 0.001
self.decay_step = 2000
self.decay_rate = 0.5
self.training_steps = 10000
self.batch_size = 100 self.summary_path = 'summary/' + self.model_name + '/'
self.ckpt_path = 'ckpt/' + self.model_name + '/' if not os.path.exists(self.summary_path):
os.makedirs(self.summary_path)
if not os.path.exists(self.ckpt_path):
os.makedirs(self.ckpt_path) def main():
"""模型训练。"""
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("../../data/MNIST_data", one_hot=False)
print(mnist.test.labels.shape)
print(mnist.train.labels.shape) my_setting = Settings()
with tf.variable_scope(my_setting.model_name):
model = Model(my_setting) # 模型要保存的变量
var_list = tf.trainable_variables()
if model.global_step not in var_list:
var_list.append(model.global_step)
# 添加 BN 层的均值和方差
global_vars = tf.global_variables()
bn_moving_vars = [v for v in global_vars if 'moving_mean' in v.name]
bn_moving_vars += [v for v in global_vars if 'moving_variance' in v.name]
var_list += bn_moving_vars
# 创建Saver
saver = tf.train.Saver(var_list=var_list) config = tf.ConfigProto()
config.gpu_options.allow_growth = True
with tf.Session(config=config) as sess:
if not os.path.exists(my_setting.ckpt_path + 'checkpoint'):
print("There is no checkpoit, please check out.")
exit()
saver.restore(sess, tf.train.latest_checkpoint(my_setting.ckpt_path))
tic = time.time()
n_batch = len(mnist.test.labels) // my_setting.batch_size
predict_labels = list()
true_labels = list()
for step in range(n_batch):
X_batch, y_batch = mnist.test.next_batch(my_setting.batch_size, shuffle=False)
X_batch = X_batch.reshape([-1, 28, 28, 1])
pred_label, test_loss, test_acc = sess.run([model.pred_lables, model.test_loss, model.test_acc],
feed_dict={model.X_inputs: X_batch, model.y_inputs: y_batch})
predict_labels.append(pred_label)
true_labels.append(y_batch)
predict_labels = np.hstack(predict_labels)
true_labels = np.hstack(true_labels)
acc = np.sum(predict_labels == true_labels) / len(true_labels)
print("Test sample number = {}, acc = {:.4f}, pass {:.2f}s".format(len(true_labels), acc, time.time() - tic)) if __name__ == '__main__':
main()
Batch Normalization原理的更多相关文章
- Batch Normalization原理及其TensorFlow实现——为了减少深度神经网络中的internal covariate shift,论文中提出了Batch Normalization算法,首先是对”每一层“的输入做一个Batch Normalization 变换
批标准化(Bactch Normalization,BN)是为了克服神经网络加深导致难以训练而诞生的,随着神经网络深度加深,训练起来就会越来越困难,收敛速度回很慢,常常会导致梯度弥散问题(Vanish ...
- 论文笔记:Batch Normalization
在神经网络的训练过程中,总会遇到一个很蛋疼的问题:梯度消失/爆炸.关于这个问题的根源,我在上一篇文章的读书笔记里也稍微提了一下.原因之一在于我们的输入数据(网络中任意层的输入)分布在激活函数收敛的区域 ...
- 深度解析Droupout与Batch Normalization
Droupout与Batch Normalization都是深度学习常用且基础的训练技巧了.本文将从理论和实践两个角度分布其特点和细节. Droupout 2012年,Hinton在其论文中提出Dro ...
- [CS231n-CNN] Training Neural Networks Part 1 : activation functions, weight initialization, gradient flow, batch normalization | babysitting the learning process, hyperparameter optimization
课程主页:http://cs231n.stanford.edu/ Introduction to neural networks -Training Neural Network ________ ...
- 深度学习网络层之 Batch Normalization
Batch Normalization Ioffe 和 Szegedy 在2015年<Batch Normalization: Accelerating Deep Network Trainin ...
- 【深度学习】深入理解Batch Normalization批标准化
这几天面试经常被问到BN层的原理,虽然回答上来了,但还是感觉答得不是很好,今天仔细研究了一下Batch Normalization的原理,以下为参考网上几篇文章总结得出. Batch Normaliz ...
- 深度学习之Batch Normalization
在机器学习领域中,有一个重要的假设:独立同分布假设,也就是假设训练数据和测试数据是满足相同分布的,否则在训练集上学习到的模型在测试集上的表现会比较差.而在深层神经网络的训练中,当中间神经层的前一层参数 ...
- [转] 深入理解Batch Normalization批标准化
转自:https://www.cnblogs.com/guoyaohua/p/8724433.html 郭耀华's Blog 欲穷千里目,更上一层楼项目主页:https://github.com/gu ...
- 神经网络之 Batch Normalization
知乎 csdn Batch Normalization 学习笔记 原文地址:http://blog.csdn.net/hjimce/article/details/50866313 作者:hjimce ...
随机推荐
- HTML和CSS前端教程03-CSS文本样式
目录 1.CSS颜色-建议就用十六进制 2.CSS长度的度量单位-建议就用px 3.CSS文本样式 3.1. 字体属性 3.1. 文本样式 1.CSS颜色-建议就用十六进制 p{ color: #ff ...
- TextView走马灯
设置textView走马灯形式显示: android:marqueeRepeatLimit="marquee_forever" android:scrollHorizontally ...
- Easyui 修改|新增jquery-easyui icon图标
修改|新增jquery-easyui icon图标 by:授客 QQ:1033553122 测试环境 jquery-easyui-1.5.3 修改配置文件 打开jquery-easyui-1.5.3\ ...
- MongoDB:数据库介绍与基础操作
二.部署在本地服务器 在上次的学习过程中,我们主要进行了MongoDB运行环境的搭建和可视化工具的安装.此次我们将学习MongoDB有关的基本概念和在adminmongo上的基本操作.该文档中的数据库 ...
- Git:八、Git自定义:忽略特殊文件&配置别名
1..gitignore配置文件 1)防止加入Git或输入git status时显示,需要让Git忽略的文件: 程序编译生成的非原代码的文件 存放密码的文件 2)配置文件:.gitignore Git ...
- Maven替换为国内仓库
<mirror> <id>nexus-aliyun</id> <mirrorOf>central</mirrorOf> <name&g ...
- Python编写脚本(输出三星形状的‘*’符号)
环境:python3.* 心得:个人认为脚本非我强项,以下效果可以有更简单解决方案,纯属练习逻辑. 方案一: s=1 while s<=10: #这是决定多少列,起始为1,大循环一圈即加一,就是 ...
- Windows 下安装drozer(Windows 10),连接手机(红米note4X)
Windows 下安装drozer(Windows 10),连接手机(红米note4X) 首先下载drozer(http://mwr.to/drozer). 红米手机开发者模式 遇到第一个问题,红米手 ...
- SQLServer约束介绍
约束定义 对于数据库来说,基本表的完整性约束分为列级约束条件和表级约束条件: 列级约束条件 列级约束条件是对某一个特定列的约束,包含在列定义中,可以直接跟在该列的其他定义之后,用空格分隔 ...
- window.open模拟表单POST提交
解决地址栏长度限制,隐藏参数,不在地址栏显示 项目 excel 导出中用到 将form的target设置成和open的name参数一样的值,通过浏览器自动识别实现了将内容post到新窗口中 var u ...