Hadoop(五)搭建Hadoop客户端与Java访问HDFS集群
阅读目录(Content)
前言
上一篇详细介绍了HDFS集群,还有操作HDFS集群的一些命令,常用的命令:

hdfs dfs -ls xxx
hdfs dfs -mkdir -p /xxx/xxx
hdfs dfs -cat xxx
hdfs dfs -put local cluster
hdfs dfs -get cluster local
hdfs dfs -cp /xxx/xxx /xxx/xxx
hdfs dfs -chmod -R 777 /xxx
hdfs dfs -chown -R zyh:zyh /xxx
注意:这里要说明一下-cp,我们可以从本地文件拷贝到集群,集群拷贝到本地,集群拷贝到集群。
一、Hadoop客户端配置
其实在前面配置的每一个集群节点都可以做一个Hadoop客户端。但是我们一般都不会拿用来做集群的服务器来做客户端,需要单独的配置一个客户端。
1)安装JDK
2)安装Hadoop
3)客户端配置子core-site.xml

4)客户端配置之mapred-site.xml

5)客户端配置之yarn-site.xml

以上就搭建了一个Hadoop的客户端
二、Java访问HDFS集群
2.1、HDFS的Java访问接口
1)org.apache.hadoop.fs.FileSystem
是一个通用的文件系统API,提供了不同文件系统的统一访问方式。
2)org.apache.hadoop.fs.Path
是Hadoop文件系统中统一的文件或目录描述,类似于java.io.File对本地文件系统的文件或目录描述。
3)org.apache.hadoop.conf.Configuration
读取、解析配置文件(如core-site.xml/hdfs-default.xml/hdfs-site.xml等),或添加配置的工具类
4)org.apache.hadoop.fs.FSDataOutputStream
对Hadoop中数据输出流的统一封装
5)org.apache.hadoop.fs.FSDataInputStream
对Hadoop中数据输入流的统一封装
2.2、Java访问HDFS主要编程步骤
1)构建Configuration对象,读取并解析相关配置文件
Configuration conf=new Configuration();
2)设置相关属性
conf.set("fs.defaultFS","hdfs://1IP:9000");
3)获取特定文件系统实例fs(以HDFS文件系统实例)
FileSystem fs=FileSystem.get(new URI("hdfs://IP:9000"),conf,“hdfs");
4)通过文件系统实例fs进行文件操作(以删除文件实例)
fs.delete(new Path("/user/liuhl/someWords.txt"));
2.3、使用FileSystem API读取数据文件
有两个静态工厂方法来获取FileSystem实例文件系统。

常用的就第二个和第四个
三、实战Java访问HDFS集群
3.1、环境介绍
1)使用的是IDEA+Maven来进行测试
2)Maven的pom.xml文件
3)HDFS集群一个NameNode和两个DataNode
3.2、查询HDFS集群文件系统的一个文件将它文件内容打印出来
package com.jslg.zyh.hadoop.hdfs; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.net.URI; public class CatDemo_0010 {
public static void main(String[] args) throws IOException {
// 创建Configuration对象
Configuration conf=new Configuration();
// 创建FileSystem对象
FileSystem fs=
FileSystem.get(URI.create(args[0]),conf);
// 需求:查看/user/kevin/passwd的内容
// args[0] hdfs://1.0.0.5:9000/user/zyh/passwd
// args[0] file:///etc/passwd
FSDataInputStream is=
fs.open(new Path(args[0]));
byte[] buff=new byte[1024];
int length=0;
while((length=is.read(buff))!=-1){
System.out.println(
new String(buff,0,length));
}
System.out.println(
fs.getClass().getName());
}
}
1)需要在HDFS文件系统中有passwd.txt文件,如果没有需要自己创建
hdfs dfs -mkdir -p /user/zyh
hdfs dfs -put /etc/passwd /user/zyh/passwd.txt
2)将Maven打好的jar包发送到服务器中,这里我们就在NameNode主机中执行,每一个节点都是一个客户端。
注意:
 这里要发送第二个包,因为它把相关类也打进jar中
这里要发送第二个包,因为它把相关类也打进jar中
 查看服务器已经收到jar包
查看服务器已经收到jar包
3)执行jar包查看结果
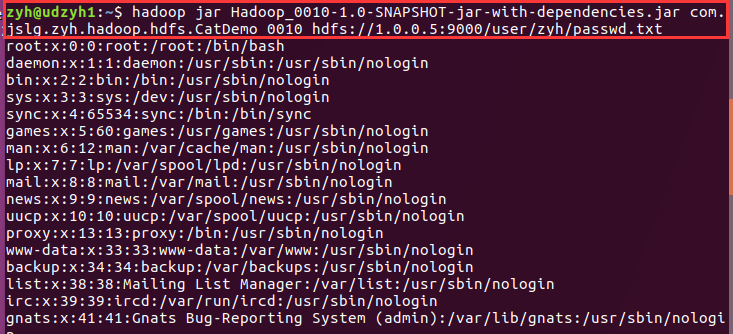
我们可以看到查询出来了passwd.txt中的内容
注意:在最后我们还查看了一下FileSystem类,因为我们知道FileSystem是抽象类,它是根据后面的URI来确定到底调用的是哪一个子类的。

3.3、我们在IEDA中执行来获取文件系统的内容并打印在控制台和相应的本地文件中
1)主要代码
public static void main(String[] args) throws IOException {
//创建configuration对象
Configuration conf = new Configuration();
//创建FileSystem对象
//需求:查看hdfs集群服务器/user/zyh/passwd.txt的内容
FileSystem fs = FileSystem.get(URI.create("hdfs://1.0.0.5:9000/user/zyh/passwd.txt"), conf);
// args[0] hdfs://1.0.0.3:9000/user/zyh/passwd.txt
// args[0] file:///etc/passwd.txt
FSDataInputStream is = fs.open(new Path("hdfs://1.0.0.5:9000/user/zyh/passwd.txt"));
OutputStream os=new FileOutputStream(new File("D:/a.txt"));
byte[] buff= new byte[1024];
int length = 0;
while ((length=is.read(buff))!=-1){
System.out.println(new String(buff,0,length));
os.write(buff,0,length);
os.flush();
}
System.out.println(fs.getClass().getName());
//这个是根据你传的变量来决定这个对象的实现类是哪个
}
2)Maven重新编译,并执行
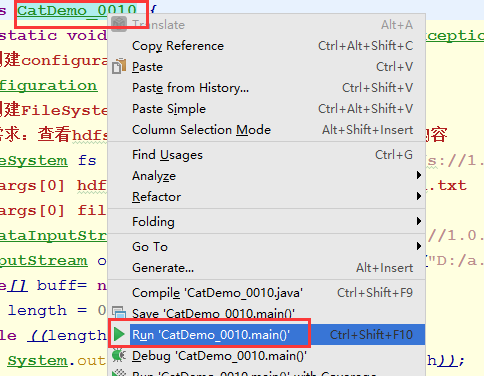
3)结果
在控制台中:
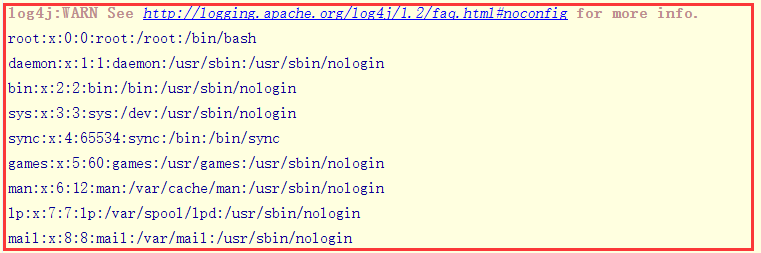
在本地文件中:

3.4、获取HDFS集群文件系统中的文件到本地文件系统
1)主要代码
public class GetDemo_0010 {
public static void main(String[] args) throws IOException {
Configuration conf=
new Configuration();
// 获取从集群上读取文件的文件系统对象
// 和输入流对象
FileSystem inFs=
FileSystem.get(
URI.create(args[0]),conf);
FSDataInputStream is=
inFs.open(new Path(args[0]));
// 获取本地文件系统对象
//当然这个你也可以用FileOutputStream
LocalFileSystem outFs=
FileSystem.getLocal(conf);
FSDataOutputStream os=
outFs.create(new Path(args[1]));
byte[] buff=new byte[1024];
int length=0;
while((length=is.read(buff))!=-1){
os.write(buff,0,length);
os.flush();
}
System.out.println(
inFs.getClass().getName());
System.out.println(
is.getClass().getName());
System.out.println(
outFs.getClass().getName());
System.out.println(
os.getClass().getName());
os.close();
is.close();
}
}
2)结果

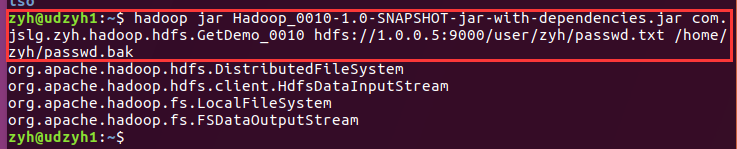
我们可以看到对于HDFS集群中获取的FileSystem对象是分布式文件系统,而输入流是HdfsDataInputStream主要用来做数据的传输。
对于本地来说获取到的FileSystem对象时本地文件系统,而输出流就是FSDataOutputStream。
将HDFS中的文件拿到windows中:
//创建configuration对象
Configuration conf = new Configuration();
// 获取从集群上读取文件的文件系统对象
// 和输入流对象
FileSystem inFs=
FileSystem.get(
URI.create("file://1.0.0.5:9000/user/kevin/passwd"),conf);
FSDataInputStream is=
inFs.open(new Path("hdfs://1.0.0.5:9000/user/kevin/passwd"));
// 获取本地文件系统对象
LocalFileSystem outFs=
FileSystem.getLocal(conf);
FSDataOutputStream os=
outFs.create(new Path("C:\\passwd"));
byte[] buff=new byte[1024];
int length=0;
while((length=is.read(buff))!=-1){
os.write(buff,0,length);
os.flush();
}
System.out.println(
inFs.getClass().getName());
System.out.println(
is.getClass().getName());
System.out.println(
outFs.getClass().getName());
System.out.println(
os.getClass().getName());
os.close();
is.close();
3.5、通过设置命令行参数变量来编程
这里需要借助Hadoop中的一个类Configured、一个接口Tool、ToolRunner(主要用来运行Tool的子类也就是run方法)
分析:
1)我们查看API可以看到ToolRunner中有一个run方法:

里面需要一个Tool的实现类和使用args用来传递参数的String类型的数据
2)分析Configured
这是Configurable接口中有一个getConf()方法
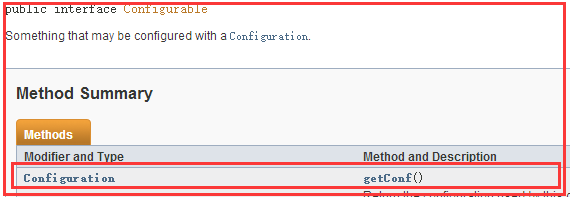
而在Configured类中实现了Configurable接口

所以Configured类中实现了Configurable接口的getConf()方法,使用它来获得一个Configuration对象
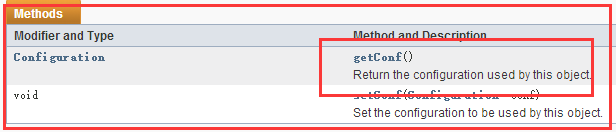
3)细说Configuration对象
可以获取Hadoop的所有配置文件中的数据
还可以通过使用命令行中使用-D(-D是一个标识)使用的变量以及值
1)主要代码
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class GetDemo_0011
extends Configured
implements Tool{
@Override
public int run(String[] strings) throws Exception{
//我们所有的代码都写在这个run方法中
Configuration conf=
getConf();
String input=conf.get("input");
String output=conf.get("output");
FileSystem inFs=
FileSystem.get(
URI.create(input),conf);
FSDataInputStream is=
inFs.open(new Path(input));
FileSystem outFs=
FileSystem.getLocal(conf);
FSDataOutputStream os=
outFs.create(new Path(output));
IOUtils.copyBytes(is,os,conf,true);
return 0;
} public static void main(String[] args) throws Exception{
//ToolRunner中的run方法中需要一个Tool的实现类,和
System.exit(
ToolRunner.run(
new GetDemo_0011(),args));
}
}
分析:
1)介绍IOUtils
它是Hadoop的一个IO流的工具类,查看API中可知!
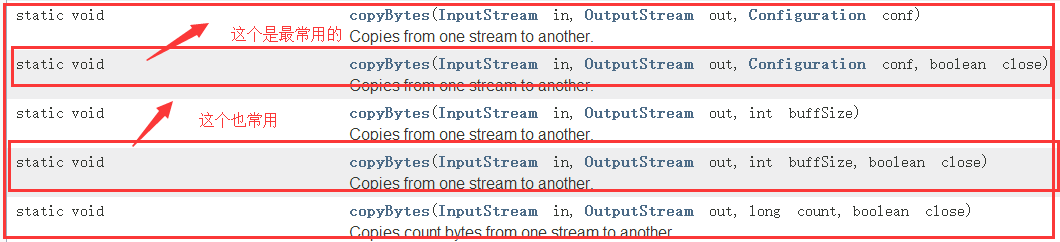
2)打包jar发送给服务器执行

3)查看结果
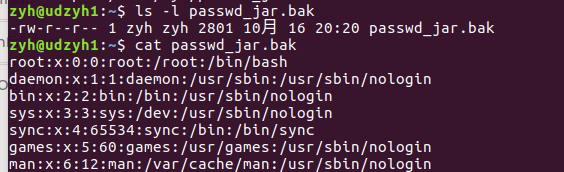
3.6、从HDFS集群中下载文件到本地
1)普通版
2)可以观察到写入了多少
Hadoop(五)搭建Hadoop客户端与Java访问HDFS集群的更多相关文章
- Hadoop(五)搭建Hadoop与Java访问HDFS集群
前言 上一篇详细介绍了HDFS集群,还有操作HDFS集群的一些命令,常用的命令: hdfs dfs -ls xxx hdfs dfs -mkdir -p /xxx/xxx hdfs dfs -cat ...
- 大数据学习笔记03-HDFS-HDFS组件介绍及Java访问HDFS集群
HDFS组件概述 NameNode 存储数据节点信息及元文件,即:分成了多少数据块,每一个数据块存储在哪一个DataNode中,每一个数据块备份到哪些DataNode中 这个集群有哪些DataNode ...
- Hadoop(八)Java程序访问HDFS集群中数据块与查看文件系统
前言 我们知道HDFS集群中,所有的文件都是存放在DN的数据块中的.那我们该怎么去查看数据块的相关属性的呢?这就是我今天分享的内容了 一.HDFS中数据块概述 1.1.HDFS集群中数据块存放位置 我 ...
- Hadoop基础-HDFS集群中大数据开发常用的命令总结
Hadoop基础-HDFS集群中大数据开发常用的命令总结 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本盘博客仅仅列出了我们在实际生成环境中常用的hdfs命令,如果想要了解更多, ...
- Hadoop学习笔记1 - 使用Java API访问远程hdfs集群
转载请标注原链接 http://www.cnblogs.com/xczyd/p/8570437.html 2018年3月从新司重新起航了.之前在某司过了的蛋疼三个月,也算给自己放了个小假了. 第一个小 ...
- Hadoop(四)HDFS集群详解
前言 前面几篇简单介绍了什么是大数据和Hadoop,也说了怎么搭建最简单的伪分布式和全分布式的hadoop集群.接下来这篇我详细的分享一下HDFS. HDFS前言: 设计思想:(分而治之)将大文件.大 ...
- 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作(转)
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- hadoop+yarn+hbase+storm+kafka+spark+zookeeper)高可用集群详细配置
配置 hadoop+yarn+hbase+storm+kafka+spark+zookeeper 高可用集群,同时安装相关组建:JDK,MySQL,Hive,Flume 文章目录 环境介绍 节点介绍 ...
随机推荐
- 【学习笔记】非监督学习-k-means
目录 k-means k-means API k-means对Instacart Market用户聚类 Kmeans性能评估指标 Kmeans性能评估指标API Kmeans总结 无监督学习,顾名思义 ...
- vue 如何点击按钮返回上一页
1,vue 如何点击按钮返回上一页呢? 这是vue挂载的范围html代码 <div @click="goOff()">返回</div> 下面是点击返回的方法 ...
- 使用newtonsoft序列化
如果将字符串序列化为datatable 时,字符串中包含null,序列化会报错,此时将datatabel 添加到dataset 中,在序列化成字符串,然后在将字符串反序列化成dataset
- AI时代大点兵-国内外知名AI公司2018年最新盘点
AI时代大点兵-国内外知名AI公司2018年最新盘点 导言 据腾讯研究院统计,截至2017年6月,全球人工智能初创企业共计2617家.美国占据1078家居首,中国以592家企业排名第二,其后分别是英国 ...
- MyCat | 分库分表实践
引言 先给大家介绍2个概念:数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式. 切分模式 一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切可以称之 ...
- 36.Odoo产品分析 (四) – 工具板块(6) – 午餐管理(2)
查看Odoo产品分析系列--目录 接上一篇Odoo产品分析 (四) – 工具板块(6) – 午餐管理(1) 4 查看订单 点击"之前的订单",可以看到刚才的订单信息: 点击右边的 ...
- 总结:当静态路由和BGP同时存在时路由优选BGP的两种方法
结论: 方法一.配置BGP协议的外部优先级比静态路由的优先级高,优选BGP. 优点:配置简单. 缺点:全局生效,如果用户有针对某个静态路由想提高优先级,不受动态路由影响,则针对每个静态路由都需要人为提 ...
- Tomcat安装教程
Tomcat安装教程 文档下载:https://files-cdn.cnblogs.com/files/yocichen/Tomcat安装教程.rar 注意:本教程适用Windows平台安装Tomca ...
- 南京邮电大学java程序设计作业在线编程第八次作业
程序设计类课程作业平台 王利国 主页 教学资源 我的作业列表 程序设计课 账户 王利国的"Java语言程序设计第8次作业(2018)"详细 主页 我的作业列表 作业结果详细 总分: ...
- Linux LVM学习总结——Insufficient Free Extents for a Logical Volume
如下所示,在创建LV的时候,偶尔会遇到"Volume group "xxxx" has insufficient free space (xxxx extents): x ...