TensorFlow之多核GPU的并行运算
tensorflow多GPU并行计算
TensorFlow可以利用GPU加速深度学习模型的训练过程,在这里介绍一下利用多个GPU或者机器时,TensorFlow是如何进行多GPU并行计算的。
首先,TensorFlow并行计算分为:模型并行,数据并行。模型并行是指根据不同模型设计不同的并行方式,模型不同计算节点放在不同GPU或者机器上进行计算。数据并行是比较通用简便的实现大规模并行方式,同时使用多个硬件资源计算不同batch数据梯度,汇总梯度进行全局参数更新。
在这里我们主要介绍数据并行的多GPU并行方法。数据并行,多块GPU同时训练多个batch数据,运行在每块GPU上的模型基于同一神经网络,网络结构一样,共享模型参数。数据并行也分为两个部分,同步数据并行和异步数据并行。
在每一轮迭代中,前向传播算法会根据当前参数的取值,计算出在一小部分训练数据上的预测值,然后反向传播算法,根据loss function计算参数的梯度并且更新参数。而不同的数据并行模式的区别在于参数的更新方式不同。
1.数据异步并行
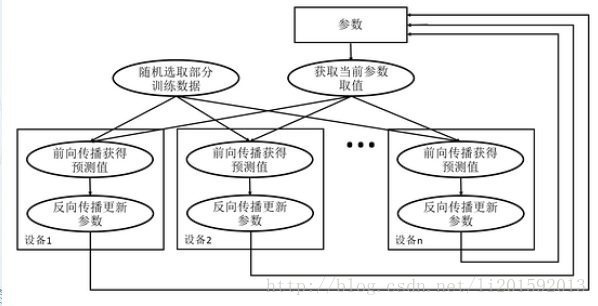
图一:数据异步并行模式流程图
从图一可以看出,在每一轮迭代时候,不同的设备会读取参数最新的取值。但是因为不同的设备,读取参数取值的时间不一样,得到的值也有可能不一样。
也就是说数据异步并行模式根据当前参数的取值和随机获取的一小部分数据数据在不同设备上各自运行,不等待所有GPU完成一次训练,哪个GPU完成训练,立即将梯度更新到共享模型参数。
2.数据同步并行
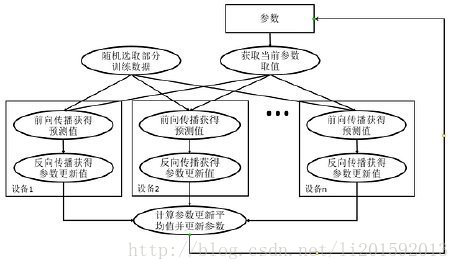
图二:数据同步并行模式流程图
与数据异步并行模式不同的是数据同步并行模式在所有设备完成反向传播的计算之后,需要计算出不同设备上参数梯度的平均值,最后在根据平均值对参数进行更新。
总结:
并行分为:模型并行和数据并行,数据并行又分为数据同步并行和数据异步并行。数据同步并行需要等所有的GPU都通过当前批次的训练语料求得损失值进而求得梯度之后对所有的GPU所得的梯度求均值,然后再以此均值进行参数的更新。而数据异步并行则不需要等待所有GPU完成一次训练,哪个GPU完成训练,立即将梯度更新到共享模型参数。
具体的分析可参考:https://blog.csdn.net/qq_29462849/article/details/81185126
优缺点的比较:
主要应用的是数据的并行化处理,因此主要是对数据的并行化处理的两种方法进行比较。数据同步并行,同步更新的信息开销很大,有时并不一定比直接利用一个GPU进行运算快,同时存在短板效应,所需的时间是由性能最差的那个GPU所决定。虽然其每个批次的计算时间由于信息开销的原因会变大,但是其每次对参数更新相当于以batch_size*GPU个数这么多的数据对参数进行更新,实际上相当于应用了更大批次的数据,这样也能解决批次的大小限制(若批次数据过大可能显存不够的情况)。数据异步并行会存在过期梯度的问题。
并行化代码的实现:
先分析下一个NLP方面的神经网络分类任务大体的流程:
一般NLP任务会输入一个三维的向量第一维mini-batch的大小,第二维人为设定的句子的最大长度,第三维词向量,数据输入之后会经过各种类型的网络(相同于前馈神经网络的功能)得到的向量是对原文的特征表示。因为NLP任务属于对序列文本的处理一般使用的网络要能够获得上下文信息也即为能够很好的对序列信息进行处理,因为学到了上下文信息,例如用LSTM,得到LSTM的输出后要把0,1维进行转换,转换为时间批次优先的形式,取结果的[-1]得到一个二维的向量第一维是批次大小,第二维是隐藏节点的个数,此时这个二维数据就是对输入原文数据的表示,对于应用较多的分类任务,随后会把对原文的特征表示做为输入,经过一个线性变换进行分类。得到二维数据pred,第一维是批次大小,第二维是类别的个数。再用精度进行结果的评估代码为:
correct_pred=tf.equal(tf.argmax(pred,1),tf.argmax(y,1))
accuracy=tf.reduce_mean(tf.cast(correct_pred,tf.float32))
因为pred是二维的,第二维的数据表示预测为各个类别的概率大小,这里可以用个softmax进行概率归一化也可不用,tf.argmax(pred,1)其作用为得到第二维最大值的那个下脚标,返回的值是一维的[batch]即为预测的是何种类别,tf.equal用于对比预测类别和正确的类别标签,返回的也是一维的[batch]但是bool类型的,随后accuracy=tf.reduce_mean(tf.cast(correct_pred,tf.float32))是精度的计算,先把bool类型的转换为float类型数据,再求均值即可。直到这里正向传播结束,随后需要进行反向传播,对模型中的参数进行更新,使获得的对于原文的表示outputs(从训练文本中抽取的特征)越来越优,以便于分类的结果越来越精确。反向传播即为通过优化函数对网络模型中的参数进行更新,一般优化的过程都是通过设定的目标函数,对目标函数进行优化,对模型中的参数进行求导,以此来更新参数。对于分类问题损失函数一般选用交叉熵函数:
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=pred))
通过如上代码获得损失值,交叉熵函数是用于求两个概率分布之间的距离,因此要对pred结果通过softmax转换为概率分布的数据。获得损失值传入优化函数对模型进行优化。这里的tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=pred)获得的数据是[batch]的,然后对其求均值得到损失值,这就体现了通过一个batch的数据对参数进行更新。
#反向传播优化函数
optimizer=tf.train.AdamOptimizer(learning_rate=FLAGS.init_learning_rate).minimize(loss)
优化函数会对参数进行优化,一般都是通过设置运行优化函数的次数epoch来控制何时停止对参数进行更新,epoch的设置可以根据精度值进行判断具体的大小。这里的minimize完成了计算梯度和应用梯度的过程,AdamOptimizer是确定选取何种方法对参数进行更新,因为它在对参数进行更新的过程中会自动调节学习率,故学习率可以不设置为衰减的(这一般在SGD中使用。)
主要代码的改变在于梯度的计算相关的方面:
平均梯度的计算:
def average_grident(tower_grads):
average_grads = []
for val_and_grad in zip(*tower_grads):
grads = []
for g,_ in val_and_grad:
grad = tf.expand_dims(g, 0)
grads.append(grad)
grad = tf.concat(grads, 0)
grad = tf.reduce_mean(grad, 0)
v = val_and_grad[0][1]
grad_and_var = (grad, v)
average_grads.append(grad_and_var)
return average_grads
需要更新的是反向传播的部分:
tower_grad = []
#计算损失值选择优化器
#反向传播优化函数
global_step = tf.Variable(0, name="global_step", trainable=False)
optimizer=tf.train.AdamOptimizer(learning_rate=FLAGS.init_learning_rate)
#以下默认使用的两个GPU,batch_size是128
for i in range(2):
with tf.device('/gpu:%d' % i):
if i==0:
cur_loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=y[:64],logits=pred[:64]))
grads = optimizer.compute_gradients(cur_loss)
tower_grad.append(grads)
else:
cur_loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=y[64:], logits=pred[64:]))
grads = optimizer.compute_gradients(cur_loss)
tower_grad.append(grads)
grads = average_grident(tower_grad)
train_op = optimizer.apply_gradients(grads,global_step=global_step)
TensorFlow之多核GPU的并行运算的更多相关文章
- TensorFlow如何提高GPU训练效率和利用率
前言 首先,如果你现在已经很熟悉tf.data+estimator了,可以把文章x掉了╮( ̄▽ ̄””)╭ 但是!如果现在还是在进行session.run(..)的话!尤其是苦恼于GPU显存都塞满了利用 ...
- ubuntu16.04 安装cuda9.0+cudnn7.0.5+tensorflow+nvidia-docker配置GPU服务
[摘要] docker很好用,但是在GPU服务器上使用docker却比较复杂,需要一些技巧,下面将介绍一下在ubuntu16.04环境下的GPU-docker环境搭建过程. 第一步: 删除之前的nvi ...
- 极简安装 TensorFlow 2.0 GPU
前言 之前写了几篇关于 TensorFlow 1.x GPU 版本安装的博客,但几乎没怎么学习过.之前基本在搞 Machine Learning 和 Data Mining 方面的东西,极少用到 NN ...
- Hello TensorFlow 二 (GPU)
官方说明:https://www.tensorflow.org/install/ 环境: 操作系统 :Windows 10 家庭中文版 处理器 : Intel(R) Core(TM) i7-7700 ...
- Running Tensorflow on AMD GPU
keras+tensorflow: based on AMD GPU https://rustyonrampage.github.io/deep-learning/2018/10/18/tensorf ...
- keras & tensorflow 列出可用GPU 和 切换CPU & GPU
列出可用GPU from tensorflow.python.client import device_lib print(device_lib.list_local_devices()) from ...
- tensorflow 指定使用gpu处理,tensorflow占用多个GPU但只有一个在跑
我们在刚使用tensorflow的过程中,会遇到这个问题,通常我们有多个gpu,但是 在通过nvidia-smi查看的时候,一般多个gpu的资源都被占满,但是只有一个gpu的GPU-Util 和 21 ...
- 7 Recursive AutoEncoder结构递归自编码器(tensorflow)不能调用GPU进行计算的问题(非机器配置,而是网络结构的问题)
一.源代码下载 代码最初来源于Github:https://github.com/vijayvee/Recursive-neural-networks-TensorFlow,代码介绍如下:“This ...
- tf.device()指定tensorflow运行的GPU或CPU设备
在tensorflow中,我们可以使用 tf.device() 指定模型运行的具体设备,可以指定运行在GPU还是CUP上,以及哪块GPU上. 设置使用GPU 使用 tf.device('/gpu:1' ...
随机推荐
- js重点--原型链
通过将一个构造函数的原型对象指向父类的实例,就可以调用父类中的实例属性及父类的原型对象属性,实现继承. function animals(){ this.type = "animals&qu ...
- \t \r \n \f
\t 的意思是 :水平制表符.将当前位置移到下一个tab位置. \r 的意思是: 回车.将当前位置移到本行的开头. \n 的意思是:回车换行.将当前位置移到下一行的开头. \f的意思是:换页.将当前位 ...
- (四) 虚拟摄像头vivi体验
目录 虚拟摄像头vivi体验 源码下载 修改Makefile 安装xawtv 测试体验 title: 虚拟摄像头vivi体验 date: 2019/4/23 19:20:00 toc: true -- ...
- [译]asp-net-core-mvc-ajax-form-requests-using-jquery-unobtrusive
原文 全文源码 开始项目 项目使用了package.json'文件,添加需要的前端package到项目中.在这我们添加了jquery-ajax-unobstrusive`. { "versi ...
- linux_systemctl介绍
声明:本文转载自:systemd (中文简体) systemd 是 Linux 下的一款系统和服务管理器,兼容 SysV 和 LSB 的启动脚本.systemd 的特性有:支持并行化任务:同一时候採用 ...
- [C++]类成员返回语句 return *this 的理解
经常会在类似 copy-assignment 的成员函数看到返回语句 return *this ,这类函数通常返回类型是所属类的引用. 类成员函数的隐式指针 class *this const 经过 ...
- Java(20)file i/o
1 I/0: input/output 1.1.java.io.File 1.2 表示:文件或者文件夹(目录) 1.3 File f = new File("文件路径"); 1. ...
- vue keep-alive内置缓存组件
1.当组件在keep-alive被切换时将会执行activeted和deactiveted两个生命周期 2.inlude 正则表达式或字符串 ,只有符合条件的组件会被缓存 exclude正则表达式或字 ...
- css 实现加载中3个点跳动
<style type="text/css">.loading:after { overflow: hidden; display: inline-block; ver ...
- LeetCode 解题总结
1. 最长合法括号串 给定只包含'('和')'的字符串,找出最长合法括号串的长度. Example 1: Input: "(()" Output: 2 Explanatio ...