Solr 06 - Solr中配置使用IK分词器 (配置schema.xml)
1 配置中文分词器
1.1 准备IK中文分词器
(1) 复制IK解压目录中的jar包: IKAnalyzer2012FF_u1.jar. 可以在 我的GitHub 中下载, 文件是IK Analyzer 2012FF_hf1.zip.
(2) 粘贴到tomcat/webapps/solr/WEB-INF/lib目录.
(3) 复制IK解压目录中的配置文件:
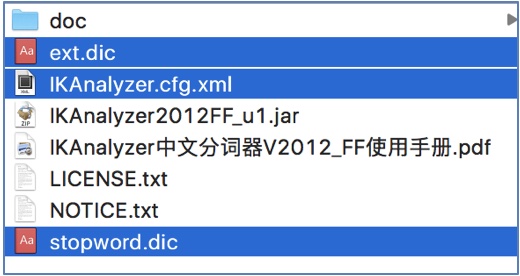
(4) 粘贴到tomcat/webapps/solr/WEB-INF/classes目录.
1.2 配置schema.xml文件
(1) 加入使用IK分词器的域类型
<!--加入使用ik分词器的域类型-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer" />
</fieldType>
(2) 加入使用IK分词器的域
<!--加入使用ik分词器的域-->
<field name="content_ik" type="text_ik"
indexed="false" stored="true" multiValued="true"/>

1.3 重启Tomcat并测试
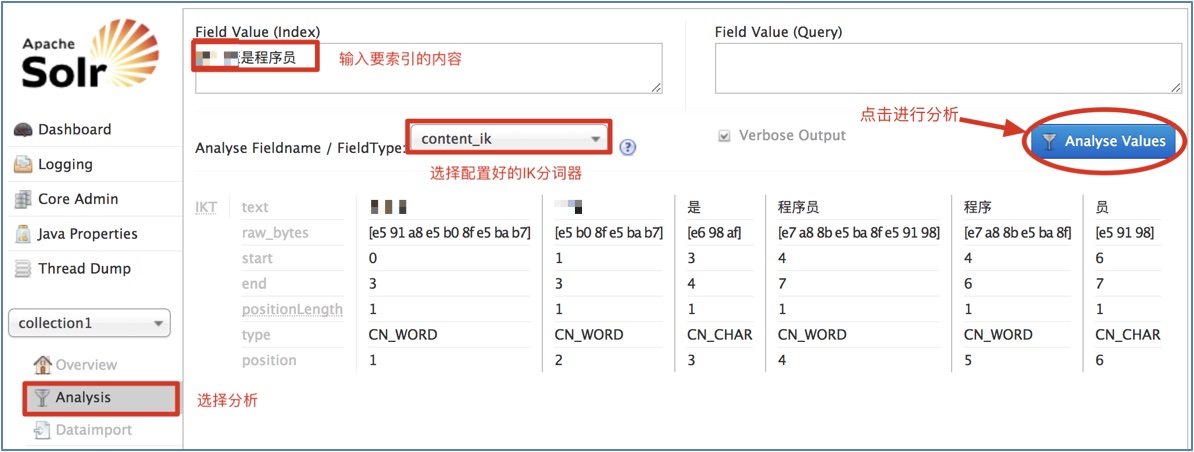
选择任意Core, 然后在菜单栏里选择[Analysis], 输入中文语句, 进行分词测试:
2 配置业务域
需求引入: 假设现在要使用Solr完成电商网站商品数据的搜索, 需要将保存在关系数据库中的商品数据导入到Solr索引库中.
2.1 准备商品数据
DROP DATABASE IF EXISTS `solr`;
CREATE DATABASE `solr`;
USE `solr`;
SET FOREIGN_KEY_CHECKS=0;
DROP TABLE IF EXISTS `products`;
CREATE TABLE `products` (
`pid` int(11) NOT NULL AUTO_INCREMENT COMMENT '商品编号',
`name` varchar(255) DEFAULT NULL COMMENT '商品名称',
`catalog` int(11) DEFAULT NULL COMMENT '商品分类ID',
`catalog_name` varchar(50) DEFAULT NULL COMMENT '商品分类名称',
`price` double DEFAULT NULL COMMENT '价格',
`number` int(11) DEFAULT NULL COMMENT '数量',
`description` longtext COMMENT '商品描述',
`picture` varchar(255) DEFAULT NULL COMMENT '图片名称',
`release_time` datetime DEFAULT NULL COMMENT '上架时间',
PRIMARY KEY (`pid`)
) ENGINE=InnoDB AUTO_INCREMENT=6126 DEFAULT CHARSET=utf8;
测试数据较大, 具体的SQL文件可以在 我的GitHub 中下载, 文件是
Solr使用IK分词器的表数据.sql.
2.2 配置商品业务域
说明: 分析商品数据库表, 确定哪些字段需要在Solr中建立索引和存储.
字段:
pid, name, catalog, catalog_name, price, description, picture
(1) 商品Id(直接使用Solr的id域):
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="true"/>
(2) 商品名称(若要用于高亮显示, 必须设置stored="true"):
<field name="product_name" type="text_ik" indexed="true" stored="true" />
(3) 商品分类id:
<field name="product_catalog" type="int" indexed="true" stored="true" />
(4) 商品分类名称(String类型, 表示整体匹配, 不作分词):
<field name="product_catalog_name" type="string" indexed="true" stored="true" />
(5) 商品价格:
<field name="product_price" type="double" indexed="true" stored="true" />
(6) 商品描述:
<field name="product_description" type="text_ik" indexed="true" stored="false" />
(7) 商品图片:
<field name="product_picture" type="string" indexed="false" stored="true" />
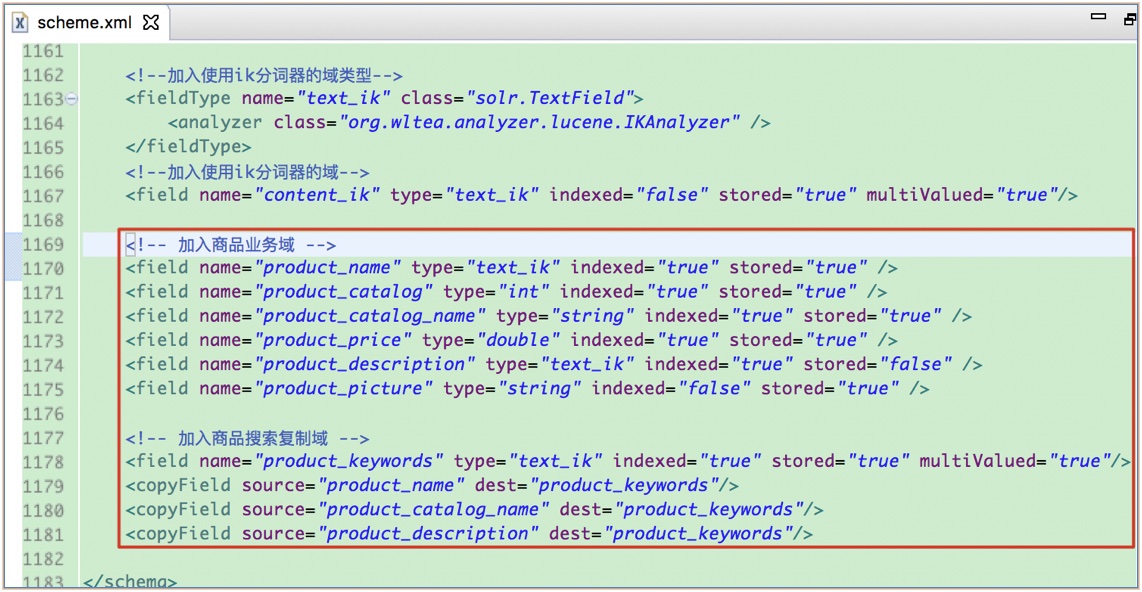
(8) 配置商品复制域(stored="true", 实际开发中multiValued="true"的field不需要存储, 这里存储便于观察效果):
<!-- 加入商品搜索复制域, 即将商品名、商品类型和描述都作为搜索关键词提供搜索 -->
<field name="product_keywords" type="text_ik" indexed="true" stored="true" multiValued="true"/>
<copyField source="product_name" dest="product_keywords"/>
<copyField source="product_catalog_name" dest="product_keywords"/>
<copyField source="product_description" dest="product_keywords"/>
2.3 配置schema.xml文件
注意: 这里id使用Solr默认的id域(一定要有主键, 没有则需要将默认的id域删除, 也可更改id生成策略. 尝试过未在库中设置主键而此文件中的id域未删除也未重写, 此时可以建立索引, 却无法检索到结果(⊙﹏⊙)):
2.4 重新启动Tomcat并查看配置
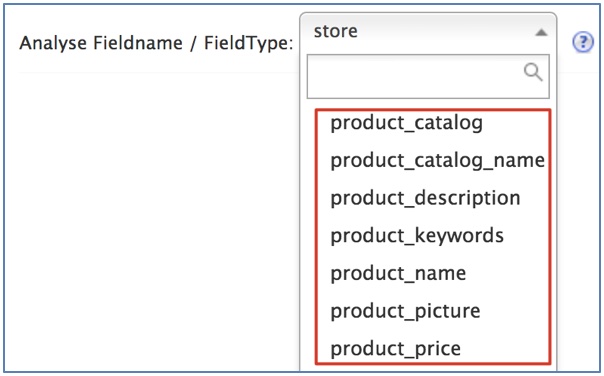
选中任意一个core, 选择Analysis, 在 [Fieldname / FieldType] 处查看, 观察配置是否成功:
版权声明
作者: 马瘦风
出处: 博客园 马瘦风的博客
您的支持是对博主的极大鼓励, 感谢您的阅读.
本文版权归博主所有, 欢迎转载, 但请保留此段声明, 并在文章页面明显位置给出原文链接, 否则博主保留追究相关人员法律责任的权利.
Solr 06 - Solr中配置使用IK分词器 (配置schema.xml)的更多相关文章
- Solr IK分词器配置
下载地址:https://search.maven.org/search?q=com.github.magese 分词器配置: 参考:https://www.cnblogs.com/mengjinlu ...
- Solr入门之(8)中文分词器配置
Solr中虽然提供了一个中文分词器,但是效果很差,可以使用IKAnalyzer或Mmseg4j 或其他中文分词器. 一.IKAnalyzer分词器配置: 1.下载IKAnalyzer(IKAnalyz ...
- solr配置相关:约束文件及引入ik分词器
schema.xml: solr约束文件 Solr中会提前对文档中的字段进行定义,并且在schema.xml中对这些字段的属性进行约束,例如:字段数据类型.字段是否索引.是否存储.是否分词等等 < ...
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例二.
为了更好的排版, 所以将IK分词器的安装重启了一篇博文, 大家可以接上solr的安装一同查看.[Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一: http://ww ...
- Solr4.4入门,介绍Solr的安装、IK分词器的配置及高亮查询结果(转)
一.Windows下安装solr-4.4.0 1. 下载solr.4.4 2. 下载绿色版tomcat6.0.18 3. 解压下载的solr到d:\study\solr,将dist目录下的sol ...
- solr-6.4.2安装+分词器配置
一.solr安装 solr下载地址:http://archive.apache.org/dist/lucene/solr/6.4.2/ 1.解压solr软件包:tar xf solr-6.4.2.tg ...
- 2.IKAnalyzer 中文分词器配置和使用
一.配置 IKAnalyzer 中文分词器配置,简单,超简单. IKAnalyzer 中文分词器下载,注意版本问题,貌似出现向下不兼容的问题,solr的客户端界面Logging会提示错误. 给出我配置 ...
- Solr6.5.0配置中文分词器配置
准备工作: solr6.5.0安装成功 1.去官网https://github.com/wks/ik-analyzer下载IK分词器 2.Solr集成IK a)将ik-analyzer-solr6.x ...
- SpringBoot整合Elasticsearch+ik分词器+kibana
话不多说直接开整 首先是版本对应,SpringBoot和ES之间的版本必须要按照官方给的对照表进行安装,最新版本对照表如下: (官网链接:https://docs.spring.io/spring-d ...
随机推荐
- MDK的一些小应用
一:MDK生成bin文件 Options(魔术棒) -> User -> After Build/rebuild -> Run#1(前边打钩) (后边的方框输入一段内容) ...
- 图论之最短路径floyd算法
Floyd算法是图论中经典的多源最短路径算法,即求任意两点之间的最短路径. 它可采用动态规划思想,因为它满足最优子结构性质,即最短路径序列的子序列也是最短路径. 举例说明最优子结构性质,上图中1号到5 ...
- LevelDB C API 整理分类
// 结构体列表 typedef struct leveldb_t leveldb_t; // 数据库 typedef struct leveldb_cache_t leveldb_cache_t; ...
- Kafka 安装配置
1. 下载安装kafka 下载地址:http://apache.fayea.com/kafka/ 解压安装包 tar zxvf kafka_版本号.tgz 2. 配置 修改kafka的config/s ...
- 微信跳转,手机WAP浏览器一键超级跳转微信指定页面
微信跳转,手机WAP浏览器一键超级跳转微信指定页面 这篇文章主要介绍了如何在手机浏览器wap网页中点击链接跳转到微信界面,需要的朋友可以参考下 先说第一种,最简单的唤起微信协议,weixin://主流 ...
- Oracle ctl模版
将txt数据装载到数据库 数据无”” LOAD DATA CHARACTER-SET ZHS16GBK truncate into table a FIELDS TERMINATED BY ‘,’ T ...
- Spring源码Gradle
Microsoft Windows [版本 10.0.17134.590](c) 2018 Microsoft Corporation.保留所有权利. D:\Workspaces\idea\sprin ...
- NOIP-Vigenère密码
题目描述 16 世纪法国外交家 Blaise de Vigenère 设计了一种多表密码加密算法―― Vigenère 密码. Vigenère 密码的加密解密算法简单易用,且破译难度比较高,曾在美国 ...
- 用cmd命令执行SQL脚本
1.简单说明 osql 为SQL Server的命令 2.要在cmd中执行该命令,一般安装SQL Server后该命令对应的路径会自动添加到系统环境变量中. 3.-S 表示要连接的数据库 -U表示登录 ...
- redis消息队列,tp5.0,高并发,抢购
redis处理抢购,并发,防止超卖,提速 1.商品队列(List列表),goods_list 控制并发,防止超卖 2.订单信息(Hash集合),order_info ...