HDFS架构及原理
原文链接:HDFS架构及原理
引言
进入大数据时代,数据集的大小已经超过一台独立物理计算机的存储能力,我们需要对数据进行分区(partition)并存储到若干台单独的计算机上,也就出现了管理网络中跨多台计算机存储的文件系统:分布式文件系统(distributed filesystem)。基于hadoop分布式文件系统HDFS(Hadoop Distributed Filesystem)具备高容错、高吞吐量等特性,在大数据和AI时代得以广泛应用。
HDFS设计
HDFS设计初衷:
低成本:HDFS可以部署在廉价的PC机上,装机成本和故障恢复成本都比较低。
高容错:数据默认保存三份,如果有多个机架的话,同一机架的机器上保存两份,不同机架的机器上保存一份,如果副本丢失,会自动创建;
高吞吐:HDFS是“一次写入多次读写”的访问模型,除了在文件末尾追加或直接阶段文件,HDFS是不允许修改文件的,这就简化了数据一致性的问题,并且实现了高吞吐数据访问。
易扩展:HDFS可以简单的通过增加节点,实现水平扩展,存储容量可随着节点数量线性增长。
HDFS虽然有很多优点,但是在某些领域目前还是不适合的,如:
低时间延迟的数据访问:有该种需求的,建议用HBase;
大量的小文件;
多用户写入,任意修改文件。
HDFS存储架构
HDFS采用Master/Slave架构存储数据,主要由client、namenode、datanode、secondary namenode,四部分组成,其中
client:客户端,代表用户通过与namenode和datanode交互来访问整个文件系统,与namenode交互获取文件的位置信息,与datanode交互进行数据的读写。
NameNode(管理者):HDFS集群有两类节点,并以管理者-工作者模式运行,namenode(管理者,也称master节点或元数据节点)用来管理文件系统的命名空间,记录每个文件中各个块所在的数据节点信息(并不永久保存块的位置信息,这些信息会在系统启动时由数据节点进行重建),配置副本,处理客户端请求。
Datanode(工作者):数据存储节点,也称slave节点,是文件系统的工作节点。主要是根据需要存储并检索数据块(受客户端或namenode调度),并定期向namenode发送所存储的块的列表。
Secondary NameNode:分担namenode工作量,是namenode的冷备份,合并fsimage和fsedits然后再发给namenode。它不是HA,它只是阶段性的合并fedits和fsimage,以缩短集群启动的时间。当namenode失效的时候,Secondary namenode并无法立刻提供服务,Secondary namenode甚至无法保证数据完整性:如果namenode数据丢失的话,在上一次合并后的文件系统的改动会丢失(在hadoop2.x版本,当启用hdfs ha时,不在存在这一项)

HDFS构建原则:
元数据与数据分离:文件本身的属性(即元数据)与文件所持有的数据分离;
主/从架构:一个HDFS集群是由一个NameNode和多个DataNode组成;
一次写入多次读取:HDFS中的文件在任何时间只能有一个Writer。当文件被创建,接着写入数据,最后,一旦文件被关闭,就不能再修改;
移动计算比移动数据更划算:数据运算,越靠近数据,执行运算的性能就越好,由于hdfs数据分布在不同机器上,要让网络的消耗最低,并提高系统的吞吐量,最佳方式是将运算的执行移到离它要处理的数据更近的地方,而不是移动数据。
HDFS写文件
操作场景
为便于理解HDFS写文件的过程,我们假设,有一个文件FileA,100M大小。Client将FileA写入到HDFS上,HDFS按默认配置(写文件参考博客地址:http://www.cnblogs.com/laov/p/3434917.html)。
写操作流程
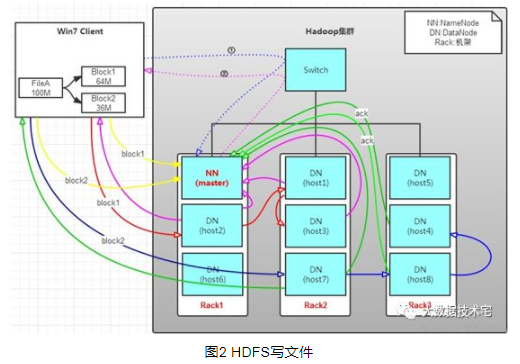
HDFS分布在三个机架上Rack1,Rack2,Rack3。
Client将FileA按64M分块。分成两块,block1和Block2;
Client向nameNode发送写数据请求,如图蓝色虚线①——>。
NameNode节点,记录block信息。并返回可用的DataNode,如粉色虚线②———>。
Block1: host2,host1,host3
Block2: host7,host8,host4
原理:NameNode具有RackAware机架感知功能,这个可以配置。若client为DataNode节点,那存储block时,规则为:副本1,同client的节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。若client不为DataNode节点,那存储block时,规则为:副本1,随机选择一个节点上;副本2,不同副本1,机架上;副本3,同副本2相同的另一个节点上;其他副本随机挑选。
client向DataNode发送block1;发送过程是以流式写入,过程如下:
将64M的block1按64k的package划分;
然后将第一个package发送给host2;
host2接收完后,将第一个package发送给host1,同时client想host2发送第二个package;
host1接收完第一个package后,发送给host3,同时接收host2发来的第二个package;
以此类推,如图红线实线所示,直到将block1发送完毕;
host2,host1,host3向NameNode,host2向Client发送通知,说“消息发送完了”。如图粉红颜色实线所示;
client收到host2发来的消息后,向namenode发送消息,说我写完了。这样就真完成了。如图黄色粗实线;
发送完block1后,再向host7,host8,host4发送block2,如图蓝色实线所示;
发送完block2后,host7,host8,host4向NameNode,host7向Client发送通知,如图浅绿色实线所示;
client向NameNode发送消息,说我写完了,如图黄色粗实线,这样就完毕了。
HDFS读文件

HDFS读取文件的主要顺序:
客户端调用FileSystem对象的open()方法打开希望读取的文件,即获取DistributedFileSystem的实例;
DistributedFileSystem通过RPC调用namenode,用于确定文件起始块(block)的位置,对于每一个block,namenode返回存有该块复本的datanode地址,这些datanode是根据他们与客户端的距离进行排序的;
前2步返回一个FSDataInputStream对象(一个支持文件定位的输入流)给client客户端并读取数据,该对象会封装为DFSInputStream对象,该对象管理datanode和namenode的I/O。客户端对这个输入流调用read()方法,DFSInputStream找出距离最近的datanode;
对数据流反复调用read()方法,将数据从datanode传输到客户端;
到达第一个block的末端时,DFSInputStream会关闭与datanode的连接,寻找下一个block的最佳datanode;
客户端从流中读取数据时,block是按照打开DFSInputStream与datanode新建连接的顺序读取的,一旦客户端完成读取,就会对FSDataInputStream调用close()方法,关闭掉所有的流。
Hadoop2.x新特性:HDFS
Hadoop2.x由HDFS、MapReduce和Yarn三个分支构成,在hadoop2.x版本中,引入NameNode Federation和HA。
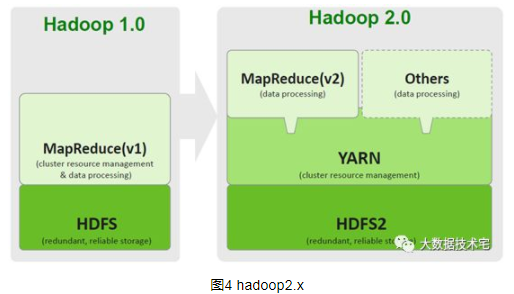
在hadoop1.x时,存在单namenode容量和性能限制,一方面受制于java内存管理能力,另一方面,由于所有元数据信息的读取和操作都要与namenode进行通信,当集群规模变大后,namenode将成为性能瓶颈。
于是,在hadoop2.x时,引入了NameNode Federation和HA,NameNode Federation由多个nameservice组成,每个nameservice由一个或两个namenode组成,每个namenode分管一部分目录,多个namenode共用集群datanode的存储资源。这样当namenode内存受限时就能够方便的扩展内存,而且每个namenode独立工作,一个namenode的挂掉并不会影响其他namenode提供服务。同时,使用HA来解决特定namenode因为缺少热备存在的单点故障问题。
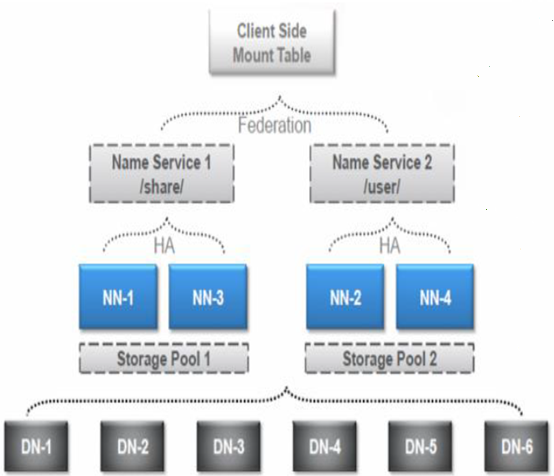
图5 NameNode Federation
全文详细内容,请点击链接:http://mp.weixin.qq.com/s/QyOyIIb5SFKSHxVIUBrqlw
更多精彩内容,欢迎扫码关注以下微信公众号:大数据技术宅。大数据、AI从关注开始

HDFS架构及原理的更多相关文章
- HDFS架构与原理
HDFS HDFS 全称hadoop分布式文件系统,其最主要的作用是作为 Hadoop 生态中各系统的存储服务 特点 优点 • 高容错.高可用.高扩展 -数据冗余多副本,副本丢失后自动恢复 -Name ...
- 2本Hadoop技术内幕电子书百度网盘下载:深入理解MapReduce架构设计与实现原理、深入解析Hadoop Common和HDFS架构设计与实现原理
这是我收集的两本关于Hadoop的书,高清PDF版,在此和大家分享: 1.<Hadoop技术内幕:深入理解MapReduce架构设计与实现原理>董西成 著 机械工业出版社2013年5月出 ...
- 2、Hdfs架构设计与原理分析
文章目录 1.Hadoop架构 2.HDFS体系架构 2.1NameNode 2.1.1元数据信息 2.1.2NameNode文件操作 2.1.3NameNode副本 2.1.4NameNode心跳机 ...
- HBase的基本架构及其原理介绍
1.概述:最近,有一些工程师问我有关HBase的基本架构的问题,其实这个问题仅仅说架构是非常简单,但是需要理解.在这里,我觉得可以用HDFS的架构作为借鉴.(其实像Hadoop生态系统中的大部分组建的 ...
- 大数据技术hadoop入门理论系列之二—HDFS架构简介
HDFS简单介绍 HDFS全称是Hadoop Distribute File System,是一个能运行在普通商用硬件上的分布式文件系统. 与其他分布式文件系统显著不同的特点是: HDFS是一个高容错 ...
- HDFS 架构简述
HDFS 架构简述 Hadoop分布式文件系统(HDFS)是一个分布式的文件系统,运行在廉价的硬件上.它与现有的分布式文件系统有很多相似之处.然而与其他的分布式文件系统的差异也是显着的.HDFS是高容 ...
- Hbase架构与原理
Hbase架构与原理 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就 ...
- Spark基本架构及原理
Hadoop 和 Spark 的关系 Spark 运算比 Hadoop 的 MapReduce 框架快的原因是因为 Hadoop 在一次 MapReduce 运算之后,会将数据的运算结果从内存写入到磁 ...
- storm架构及原理
storm 架构与原理 1 storm简介 1.1 storm是什么 如果只用一句话来描述 storm 是什么的话:分布式 && 实时 计算系统.按照作者 Nathan Marz 的说 ...
随机推荐
- 理解pytorch中的softmax中的dim参数
import torch import torch.nn.functional as F x1= torch.Tensor( [ [1,2,3,4],[1,3,4,5],[3,4,5,6]]) y11 ...
- esxi 精简置备只增不减问题解决方法(转)
esxi 精简置备只增不减问题解决方法 众所周知Thin Provisioning模式下的虚拟机磁盘的空间会随需增长,可以很大程度上帮助我们节约空间,可是,凡增长过后的空间,即使清除了导致增长的文件后 ...
- centos7搭建本地 Remix
由于最近要弄加入某联盟链,是基于ETH 所以要弄一个开发环境 一.准备 安装 nodejs,npm,git 二.安装 git clone https://github.com/ethereum/rem ...
- 实现webservice过滤器,请求日志和权限等
过滤webservice的请求日志,做权限验证功能等. 1. namespace WebApplication1 { public class SimpleWSInvokeMonitorExtensi ...
- Hive 本地调试方法
关键词:hive, debug 本地调试(local debug) Hive 可分为 exec (hive-exec,主要对应源码里的ql目录) 和 metastore 两部分,其中exec对外有两种 ...
- A_B_Good Bye 2018_cf
A. New Year and the Christmas Ornament time limit per test 1 second memory limit per test 256 megaby ...
- anaconda安装opencv(python)
1.win10 win10没有安装python,只安装了anaconda,然后使用pip安装opencv-python,版本很新,opencv_python4.0.0的. 网速有点莫名其妙,时快时慢 ...
- springmvc的日期类型转换
springmvc的日期类型转换 # spring mvc绑定参数之类型转换有三种方式: ## 1.实体类中加日期格式化注解 @DateTimeFormat(pattern="yyyy- ...
- vue-router路径计算问题
简书原文 昨天刚刚发表了一个前端跨域新方案尝试,今天在开发中就遇到的了问题. 起因 前端使用的是vue-router组件的history模式,但是由于我们的整个页面都是从static(静态资源站)lo ...
- [Swift]LeetCode1003. 检查替换后的词是否有效 | Check If Word Is Valid After Substitutions
We are given that the string "abc" is valid. From any valid string V, we may split V into ...