IEEE Trans 2009 Stagewise Weak Gradient Pursuits论文学习

1 SWOMP重构算法流程


2 分段弱正交匹配追踪(SWOMP)Matlab代码(CS_SWOMP.m)
function [ theta ] = CS_SWOMP( y,A,S,alpha )
%CS_SWOMP Summary of this function goes here
%Version: 1.0 written by jbb0523 @2015-05-11
% Detailed explanation goes here
% y = Phi * x
% x = Psi * theta
% y = Phi*Psi * theta
% 令 A = Phi*Psi, 则y=A*theta
% S is the maximum number of SWOMP iterations to perform
% alpha is the threshold parameter
% 现在已知y和A,求theta
% Reference:Thomas Blumensath,Mike E. Davies.Stagewise weak gradient
% pursuits[J].IEEE Transactions on Signal Processing,2009,57(11):4333-4346.
if nargin < 4
alpha = 0.5;%alpha范围(0,1),默认值为0.5
end
if nargin < 3
S = 10;%S默认值为10
end
[y_rows,y_columns] = size(y);
if y_rows<y_columns
y = y';%y should be a column vector
end
[M,N] = size(A);%传感矩阵A为M*N矩阵
theta = zeros(N,1);%用来存储恢复的theta(列向量)
Pos_theta = [];%用来迭代过程中存储A被选择的列序号
r_n = y;%初始化残差(residual)为y
for ss=1:S%最多迭代S次
product = A'*r_n;%传感矩阵A各列与残差的内积
sigma = max(abs(product));
Js = find(abs(product)>=alpha*sigma);%选出大于阈值的列
Is = union(Pos_theta,Js);%Pos_theta与Js并集
if length(Pos_theta) == length(Is)
if ss==1
theta_ls = 0;%防止第1次就跳出导致theta_ls无定义
end
break;%如果没有新的列被选中则跳出循环
end
%At的行数要大于列数,此为最小二乘的基础(列线性无关)
if length(Is)<=M
Pos_theta = Is;%更新列序号集合
At = A(:,Pos_theta);%将A的这几列组成矩阵At
else%At的列数大于行数,列必为线性相关的,At'*At将不可逆
if ss==1
theta_ls = 0;%防止第1次就跳出导致theta_ls无定义
end
break;%跳出for循环
end
%y=At*theta,以下求theta的最小二乘解(Least Square)
theta_ls = (At'*At)^(-1)*At'*y;%最小二乘解
%At*theta_ls是y在At列空间上的正交投影
r_n = y - At*theta_ls;%更新残差
if norm(r_n)<1e-6%Repeat the steps until r=0
break;%跳出for循环
end
end
theta(Pos_theta)=theta_ls;%恢复出的theta
end
3 SWOMP单次重构测试代码
%压缩感知重构算法测试
clear all;close all;clc;
M = 128;%观测值个数
N = 256;%信号x的长度
K = 30;%信号x的稀疏度
Index_K = randperm(N);
x = zeros(N,1);
x(Index_K(1:K)) = 5*randn(K,1);%x为K稀疏的,且位置是随机的
Psi = eye(N);%x本身是稀疏的,定义稀疏矩阵为单位阵x=Psi*theta
Phi = randn(M,N)/sqrt(M);%测量矩阵为高斯矩阵
A = Phi * Psi;%传感矩阵
y = Phi * x;%得到观测向量y
%% 恢复重构信号x
tic
theta = CS_SWOMP( y,A);
x_r = Psi * theta;% x=Psi * theta
toc
%% 绘图
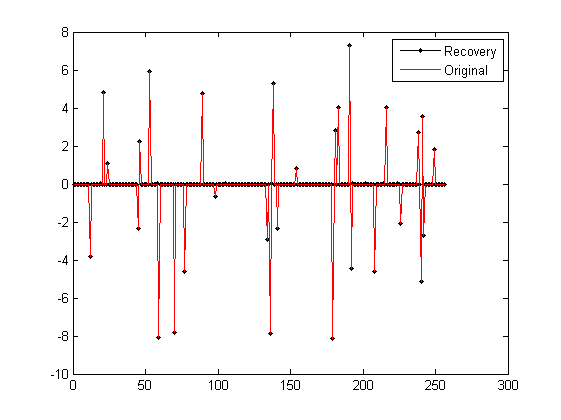
figure;
plot(x_r,'k.-');%绘出x的恢复信号
hold on;
plot(x,'r');%绘出原信号x
hold off;
legend('Recovery','Original')
fprintf('\n恢复残差:');
norm(x_r-x)%恢复残差
4 门限参数α、测量数M与重构成功概率关系曲线绘制例程代码
%压缩感知重构算法测试
clear all;close all;clc;
M = 128;%观测值个数
N = 256;%信号x的长度
K = 30;%信号x的稀疏度
Index_K = randperm(N);
x = zeros(N,1);
x(Index_K(1:K)) = 5*randn(K,1);%x为K稀疏的,且位置是随机的
Psi = eye(N);%x本身是稀疏的,定义稀疏矩阵为单位阵x=Psi*theta
Phi = randn(M,N)/sqrt(M);%测量矩阵为高斯矩阵
A = Phi * Psi;%传感矩阵 clear all;close all;clc;
%% 参数配置初始化
CNT = 1000;%对于每组(K,M,N),重复迭代次数
N = 256;%信号x的长度
Psi = eye(N);%x本身是稀疏的,定义稀疏矩阵为单位阵x=Psi*theta
alpha_set = 0.1:0.1:1;
K_set = [4,12,20,28,36];%信号x的稀疏度集合
Percentage = zeros(N,length(K_set),length(alpha_set));%存储恢复成功概率
%% 主循环,遍历每组(alpha,K,M,N)
tic
for tt = 1:length(alpha_set)
alpha = alpha_set(tt);
for kk = 1:length(K_set)
K = K_set(kk);%本次稀疏度
%M没必要全部遍历,每隔5测试一个就可以了
M_set=2*K:5:N;
PercentageK = zeros(1,length(M_set));%存储此稀疏度K下不同M的恢复成功概率
for mm = 1:length(M_set)
M = M_set(mm);%本次观测值个数
fprintf('alpha=%f,K=%d,M=%d\n',alpha,K,M);
P = 0;
for cnt = 1:CNT %每个观测值个数均运行CNT次
Index_K = randperm(N);
x = zeros(N,1);
x(Index_K(1:K)) = 5*randn(K,1);%x为K稀疏的,且位置是随机的
Phi = randn(M,N)/sqrt(M);%测量矩阵为高斯矩阵
A = Phi * Psi;%传感矩阵
y = Phi * x;%得到观测向量y
theta = CS_SWOMP(y,A,10,alpha);%恢复重构信号theta
x_r = Psi * theta;% x=Psi * theta
if norm(x_r-x)<1e-6%如果残差小于1e-6则认为恢复成功
P = P + 1;
end
end
PercentageK(mm) = P/CNT*100;%计算恢复概率
end
Percentage(1:length(M_set),kk,tt) = PercentageK;
end
end
toc
save SWOMPMtoPercentage1000 %运行一次不容易,把变量全部存储下来
%% 绘图
for tt = 1:length(alpha_set)
S = ['-ks';'-ko';'-kd';'-kv';'-k*'];
figure;
for kk = 1:length(K_set)
K = K_set(kk);
M_set=2*K:5:N;
L_Mset = length(M_set);
plot(M_set,Percentage(1:L_Mset,kk,tt),S(kk,:));%绘出x的恢复信号
hold on;
end
hold off;
xlim([0 256]);
legend('K=4','K=12','K=20','K=28','K=36');
xlabel('Number of measurements(M)');
ylabel('Percentage recovered');
title(['Percentage of input signals recovered correctly(N=256,alpha=',...
num2str(alpha_set(tt)),')(Gaussian)']);
end
for kk = 1:length(K_set)
K = K_set(kk);
M_set=2*K:5:N;
L_Mset = length(M_set);
S = ['-ks';'-ko';'-kd';'-k*';'-k+';'-kx';'-kv';'-k^';'-k<';'-k>'];
figure;
for tt = 1:length(alpha_set)
plot(M_set,Percentage(1:L_Mset,kk,tt),S(tt,:));%绘出x的恢复信号
hold on;
end
hold off;
xlim([0 256]);
legend('alpha=0.1','alpha=0.2','alpha=0.3','alpha=0.4','alpha=0.5',...
'alpha=0.6','alpha=0.7','alpha=0.8','alpha=0.9','alpha=1.0');
xlabel('Number of measurements(M)');
ylabel('Percentage recovered');
title(['Percentage of input signals recovered correctly(N=256,K=',...
num2str(K),')(Gaussian)']);
end
y = Phi * x;%得到观测向量y
%% 恢复重构信号x
tic
theta = CS_SWOMP( y,A);
x_r = Psi * theta;% x=Psi * theta
toc
%% 绘图
figure;
plot(x_r,'k.-');%绘出x的恢复信号
hold on;
plot(x,'r');%绘出原信号x
hold off;
legend('Recovery','Original')
fprintf('\n恢复残差:');
norm(x_r-x)%恢复残差
本程序在联想ThinkPadE430C笔记本(4GBDDR3内存,i5-3210)上运行共耗时8430.877154秒(时间较长,运行时可以干点别的事情了),程序中将所有数据均通过“save SWOMPMtoPercentage1000”存储了下来,以后可以再对数据进行分析,只需“load SWOMPMtoPercentage1000”即可。
程序运行结束会出现10+5=11幅图,前10幅图分别是α分别为0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9和1.0时的测量数M与重构成功概率关系曲线(类似于OMP此部分,这里只是对每一个不同的α画出一幅图),后5幅图是分别将稀疏度K为4、12、20、28、32时将十种α取值的测量数M与重构成功概率关系曲线绘制在一起以比较α对重构结果的影响。
以下是α分别为0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9和 1.0时的测量数M与重构成功概率关系曲线:
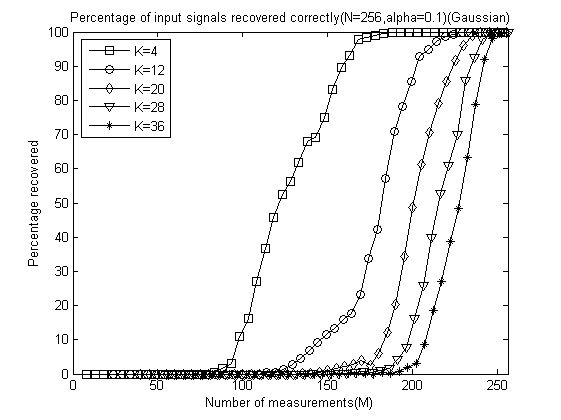

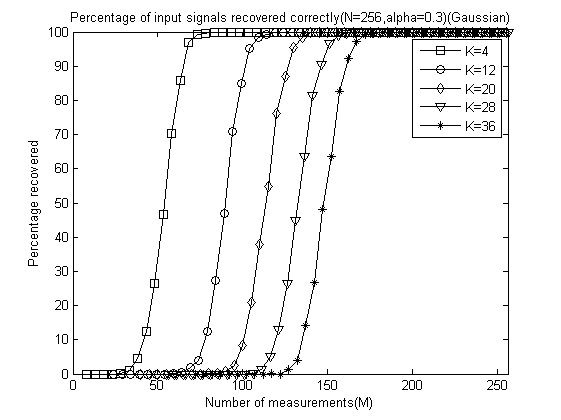
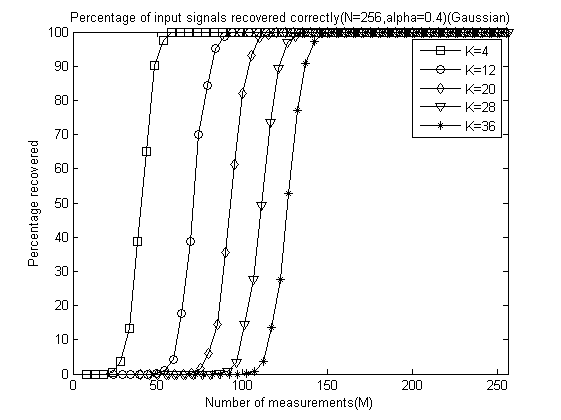
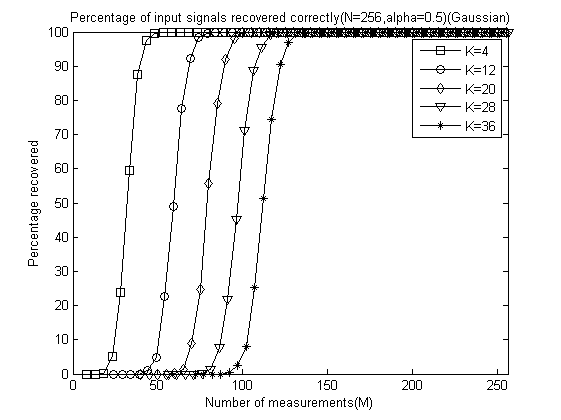
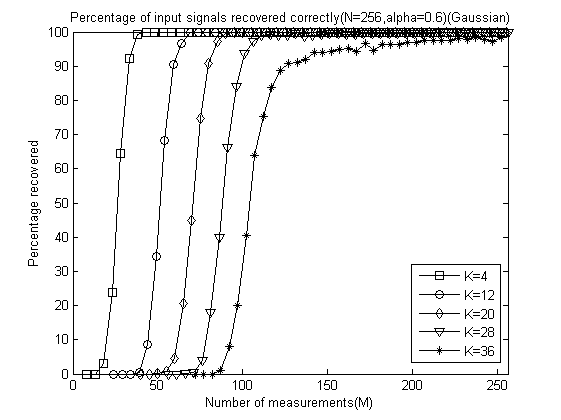
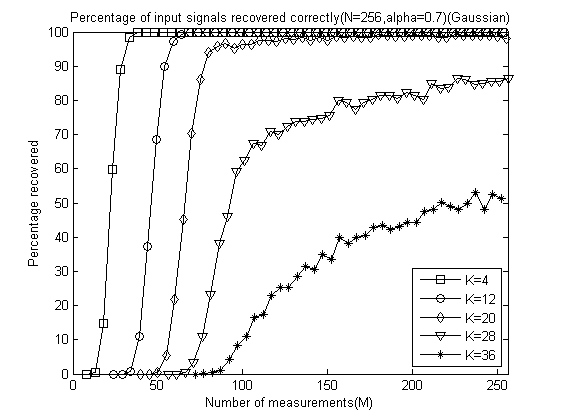

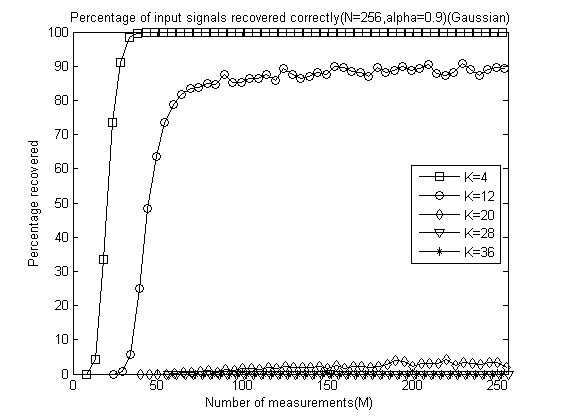
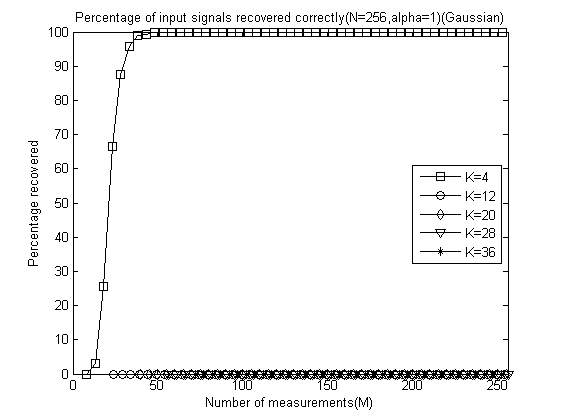
以下是稀疏度K为4、12、20、28、32时将十种α取值的测量数M与重构成功概率关系曲线放在一起的五幅图:
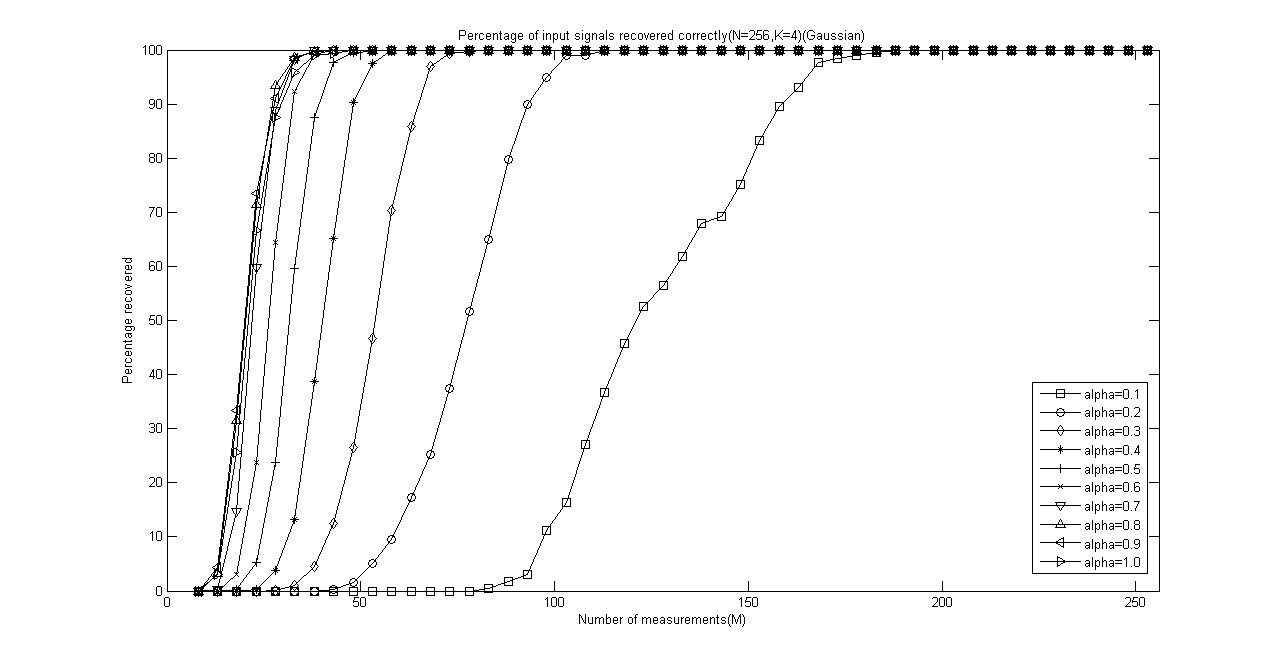
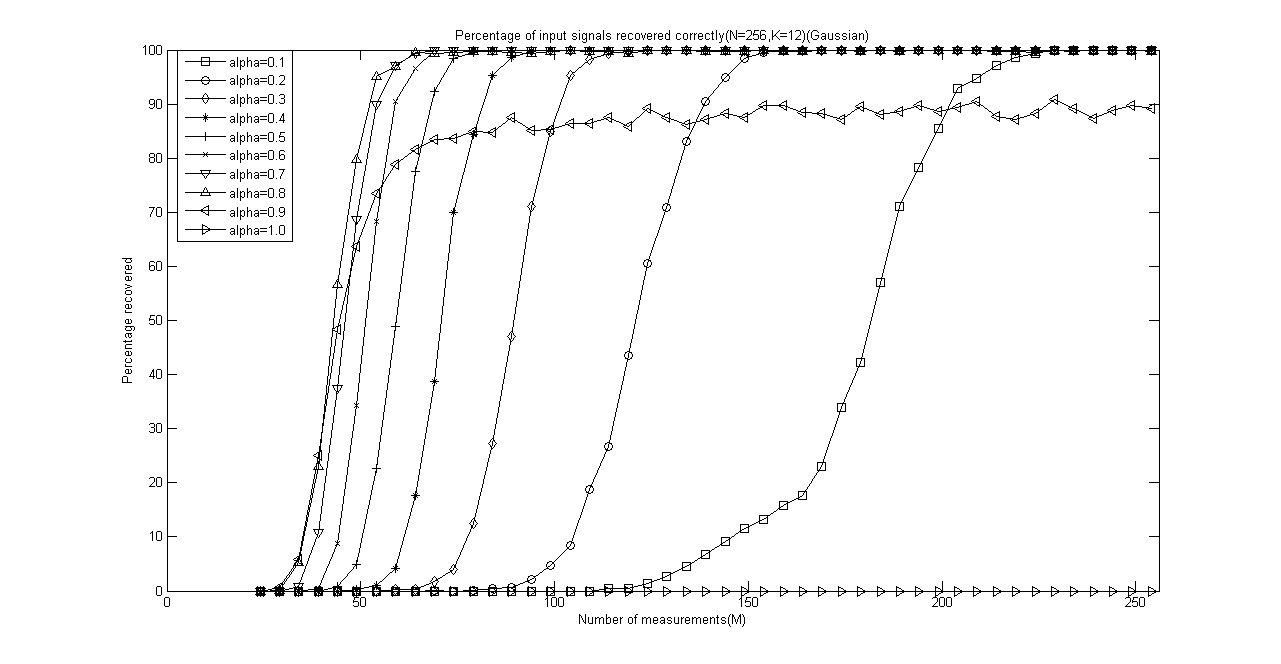


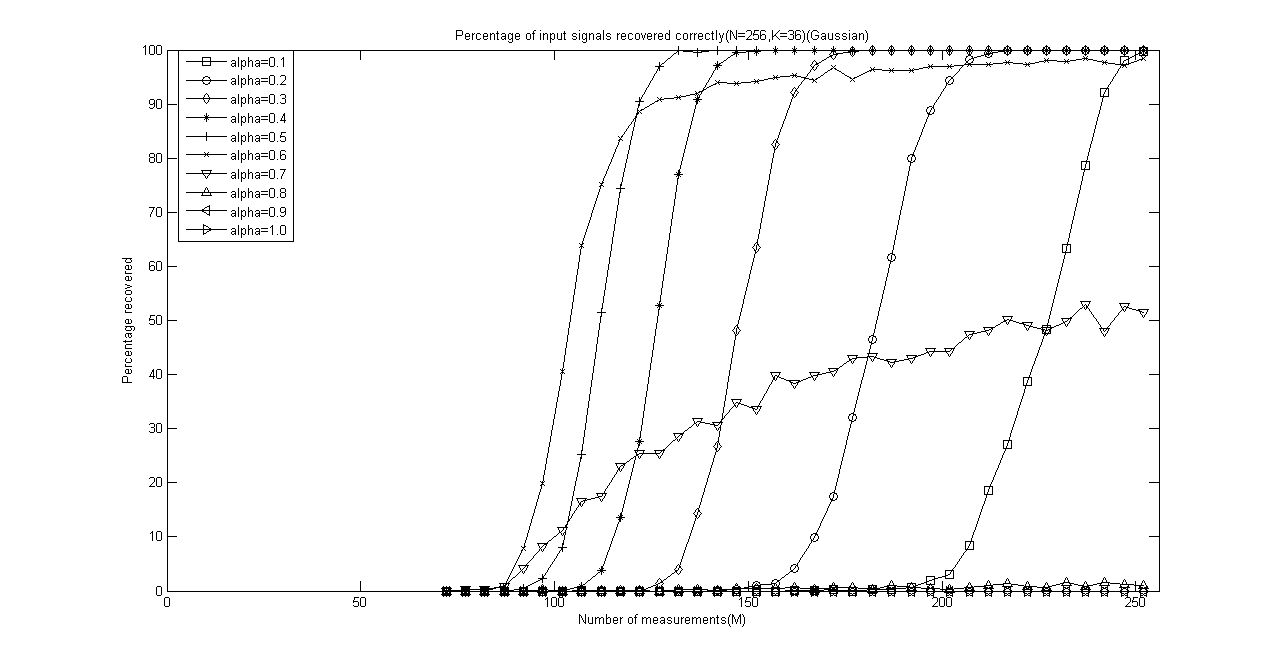
IEEE Trans 2009 Stagewise Weak Gradient Pursuits论文学习的更多相关文章
- IEEE Trans 2008 Gradient Pursuits论文学习
之前所学习的论文中求解稀疏解的时候一般采用的都是最小二乘方法进行计算,为了降低计算复杂度和减少内存,这篇论文梯度追踪,属于贪婪算法中一种.主要为三种:梯度(gradient).共轭梯度(conjuga ...
- IEEE Trans 2007 Signal Recovery From Random Measurements via OMP
看了一篇IEEE Trans上的关于CS图像重构的OMP算法的文章,大部分..看不懂,之前在看博客的时候对流程中的一些标号看不太懂,看完论文之后对流程有了一定的了解,所以在这里解释一下流程,其余的如果 ...
- 对比学习下的跨模态语义对齐是最优的吗?---自适应稀疏化注意力对齐机制 IEEE Trans. MultiMedia
论文介绍:Unified Adaptive Relevance Distinguishable Attention Network for Image-Text Matching (统一的自适应相关性 ...
- 《Explaining and harnessing adversarial examples》 论文学习报告
<Explaining and harnessing adversarial examples> 论文学习报告 组员:裴建新 赖妍菱 周子玉 2020-03-27 1 背景 Sz ...
- 论文学习笔记 - 高光谱 和 LiDAR 融合分类合集
A³CLNN: Spatial, Spectral and Multiscale Attention ConvLSTM Neural Network for Multisource Remote Se ...
- Faster RCNN论文学习
Faster R-CNN在Fast R-CNN的基础上的改进就是不再使用选择性搜索方法来提取框,效率慢,而是使用RPN网络来取代选择性搜索方法,不仅提高了速度,精确度也更高了 Faster R-CNN ...
- Apache Calcite 论文学习笔记
特别声明:本文来源于掘金,"预留"发表的[Apache Calcite 论文学习笔记](https://juejin.im/post/5d2ed6a96fb9a07eea32a6f ...
- IEEE Trans 2006 使用K-SVD构造超完备字典以进行稀疏表示(稀疏分解)
K-SVD可以看做K-means的一种泛化形式,K-means算法总每个信号量只能用一个原子来近似表示,而K-SVD中每个信号是用多个原子的线性组合来表示的. K-SVD算法总体来说可以分成两步 ...
- ieee trans pami latex模板
https://www.computer.org/cms/Computer.org/transactions/templates/ https://www.computer.org/web/tpami ...
随机推荐
- 基于树莓派的智能家居项目的设想与实现 Hestia
注:本人内容的准确性仅限于笔者写该篇文章时的情况,不保证后续与实际项目代码一致.实时内容还请关注Github项目托管页面:https://github.com/GenialX/hestia-serve ...
- Python crawler access to web pages the get requests a cookie
Python in the process of accessing the web page,encounter with cookie,so we need to get it. cookie i ...
- 在动态链接库dll中弹出对话框
在动态链接库dll中弹出对话框步骤: 1.添加Dialog资源,然后在资源视图的对话框界面右击添加类,输入类名MyDlg,使得其继承与CDialogEx.(继承CDialog应该也可以)2.在新生成的 ...
- kafka原理和实践(六)总结升华
系列目录 kafka原理和实践(一)原理:10分钟入门 kafka原理和实践(二)spring-kafka简单实践 kafka原理和实践(三)spring-kafka生产者源码 kafka原理和实践( ...
- 理解MVC入门基础原理
今天,我将开启一个崭新的话题:ASP.NET MVC框架的探讨.首先,我们回顾一下ASP.NET Web Form技术与ASP.NET MVC的异同点,并展示各自在Web领域的优劣点.在讨论之前,我对 ...
- 两天快速开发一个自己的微信小程序
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 12.0px "Songti SC" } p.p2 { margin: 0.0px 0. ...
- Innodb中的锁
Innodb中的锁 共享锁和排它锁(Shared and Exclusive Locks)共享锁和排它锁是行级锁,有两种类型的行级锁 共享锁(s lock)允许持有锁的事务对行进行读取操作 排它锁(x ...
- 在Eclipse中写web工程 发现import javax.servlet.http.HttpSession无法引入
解决方法 得加入tomcat的jar包,右击项目->build path-add libraries->server Runtime->选择要导入的tomcat 就可以了,如果没有选 ...
- 自动化运维工具——ansible详解(二)
Ansible playbook 简介 playbook 是 ansible 用于配置,部署,和管理被控节点的剧本. 通过 playbook 的详细描述,执行其中的一系列 tasks ,可以让远端主机 ...
- P2024食物链
题目描述 动物王国中有三类动物 A,B,C,这三类动物的食物链构成了有趣的环形.A 吃 B,B 吃 C,C 吃 A. 现有 N 个动物,以 1 - N 编号.每个动物都是 A,B,C 中的一种,但是我 ...