python3 爬虫---爬取糗事百科
这次爬取的网站是糗事百科,网址是:http://www.qiushibaike.com/hot/page/1
分析网址,参数'page/'后面的数字''指的是页数,第二页就是'/page/2',以此类推。。。
一、分析网页

然后明确要爬取的元素:作者名、内容、好笑数、以及评论数量
每一个段子的信息存放在'div id="content-left"'下的div中
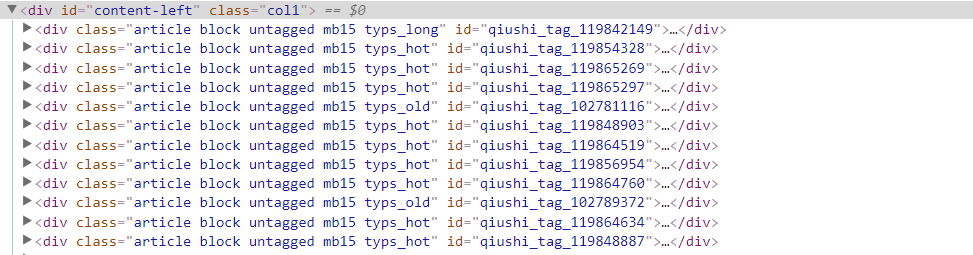
爬取元素的所在位置
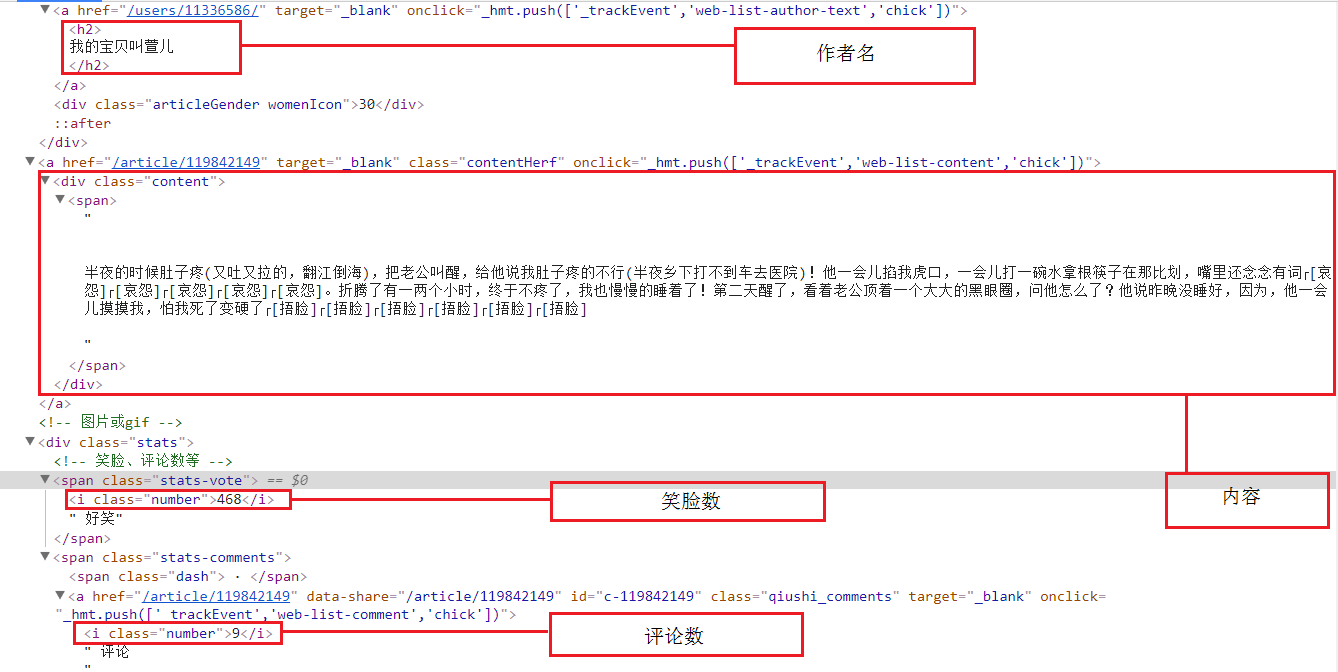
二、爬取部分
工具:
Python3
requests
xpath
1、获取每一个段子
# 返回页面的div_list
def getHtmlDivList(self, pageIndex):
pageUrl = 'http://www.qiushibaike.com/hot/page/' + str(pageIndex)
html = requests.get(url=pageUrl, headers=self.headers).text
selector = etree.HTML(html)
divList = selector.xpath('//div[@id="content-left"]/div')
return divList
每一个段子都在div中,这里用xpath,筛选出来后返回的是一个列表,每一个div都在里面
2、获取每一个段子中的元素
def getHtmlItems(self, divList):
items = []
for div in divList:
item = []
# 发布人
name = div.xpath('.//h2/text()')[0].replace("\n", "")
item.append(name)
# 内容(阅读全文)
contentForAll = div.xpath('.//div[@class="content"]/span[@class="contentForAll"]')
if contentForAll:
contentForAllHref = div.xpath('.//a[@class="contentHerf"]/@href')[0]
contentForAllHref = "https://www.qiushibaike.com" + contentForAllHref
contentForAllHrefPage = requests.get(url=contentForAllHref).text
selector2 = etree.HTML(contentForAllHrefPage)
content = selector2.xpath('//div[@class="content"]/text()')
content = "".join(content)
content = content.replace("\n", "")
else:
content = div.xpath('.//div[@class="content"]/span/text()')
content = "".join(content)
content = content.replace("\n", "")
item.append(content)
# 点赞数
love = div.xpath('.//span[@class="stats-vote"]/i[@class="number"]/text()')
love = love[0]
item.append(love)
# 评论人数
num = div.xpath('.//span[@class="stats-comments"]//i[@class="number"]/text()')
num = num[0]
item.append(num)
items.append(item)
return items
这里需要注意的是,xpath返回的是一个列表,筛选出来后需要用[0]获取到字符串类型
上面的代码中,爬取的内容里,有的段子是这样的,如下图: 
内容中会有标签<br>,那么用xpath爬取出来后,里面的内容都会成一个列表(这里的div就是列表),
那div[0]就是"有一次回老家看姥姥,遇到舅妈说到表弟小时候的事~",所以需要将div转换成字符串
其他的部分就xpath语法的使用
3、保存进文本
# 保存入文本
def saveItem(self, items):
f = open('F:\\Pythontest1\\qiushi.txt', "a", encoding='UTF-8') for item in items:
name = item[0]
content = item[1]
love = item[2]
num = item[3] # 写入文本
f.write("发布人:" + name + '\n')
f.write("内容:" + content + '\n')
f.write("点赞数:" + love + '\t')
f.write("评论人数:" + num)
f.write('\n\n') f.close()
4、全部代码
import os
import re
import requests
from lxml import etree # 糗事百科爬虫
class QSBK:
# 初始化方法,定义变量
def __init__(self):
self.pageIndex = 1
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36"
}
self.enable = False # 返回页面的div_list
def getHtmlDivList(self, pageIndex):
pageUrl = 'http://www.qiushibaike.com/hot/page/' + str(pageIndex)
html = requests.get(url=pageUrl, headers=self.headers).text
selector = etree.HTML(html)
divList = selector.xpath('//div[@id="content-left"]/div')
return divList # 获取文本中要截取的元素
def getHtmlItems(self, divList): items = [] for div in divList:
item = []
# 发布人
name = div.xpath('.//h2/text()')[0].replace("\n", "")
item.append(name) # 内容(阅读全文)
contentForAll = div.xpath('.//div[@class="content"]/span[@class="contentForAll"]')
if contentForAll:
contentForAllHref = div.xpath('.//a[@class="contentHerf"]/@href')[0]
contentForAllHref = "https://www.qiushibaike.com" + contentForAllHref
contentForAllHrefPage = requests.get(url=contentForAllHref).text
selector2 = etree.HTML(contentForAllHrefPage)
content = selector2.xpath('//div[@class="content"]/text()')
content = "".join(content)
content = content.replace("\n", "")
else:
content = div.xpath('.//div[@class="content"]/span/text()')
content = "".join(content)
content = content.replace("\n", "")
item.append(content) # 点赞数
love = div.xpath('.//span[@class="stats-vote"]/i[@class="number"]/text()')
love = love[0]
item.append(love) # 评论人数
num = div.xpath('.//span[@class="stats-comments"]//i[@class="number"]/text()')
num = num[0]
item.append(num) items.append(item) return items # 保存入文本
def saveItem(self, items):
f = open('F:\\Pythontest1\\qiushi.txt', "a", encoding='UTF-8') for item in items:
name = item[0]
content = item[1]
love = item[2]
num = item[3] # 写入文本
f.write("发布人:" + name + '\n')
f.write("内容:" + content + '\n')
f.write("点赞数:" + love + '\t')
f.write("评论人数:" + num)
f.write('\n\n') f.close() # 判断文本是否已创建,添加路径
def judgePath(self):
if os.path.exists('F:\\Pythontest1') == False:
os.mkdir('F:\\Pythontest1')
if os.path.exists("F:\\Pythontest1\\qiushi.txt") == True:
os.remove("F:\\Pythontest1\\qiushi.txt") def start(self):
self.judgePath()
print("正在读取糗事百科,按回车继续保存下一页,Q退出")
self.enable = True
while self.enable:
divList = self.getHtmlDivList(self.pageIndex)
data = self.getHtmlItems(divList)
self.saveItem(data)
print('已保存第%d页的内容' % self.pageIndex)
pan = input('是否继续保存:')
if pan != 'Q':
self.pageIndex += 1
self.enable = True
else:
print('程序运行结束!!')
self.enable = False spider = QSBK()
spider.start()
python3 爬虫---爬取糗事百科的更多相关文章
- python学习(十六)写爬虫爬取糗事百科段子
原文链接:爬取糗事百科段子 利用前面学到的文件.正则表达式.urllib的知识,综合运用,爬取糗事百科的段子先用urllib库获取糗事百科热帖第一页的数据.并打开文件进行保存,正好可以熟悉一下之前学过 ...
- Python爬虫爬取糗事百科段子内容
参照网上的教程再做修改,抓取糗事百科段子(去除图片),详情见下面源码: #coding=utf-8#!/usr/bin/pythonimport urllibimport urllib2import ...
- Python爬虫-爬取糗事百科段子
闲来无事,学学python爬虫. 在正式学爬虫前,简单学习了下HTML和CSS,了解了网页的基本结构后,更加快速入门. 1.获取糗事百科url http://www.qiushibaike.com/h ...
- python爬虫之爬取糗事百科并将爬取内容保存至Excel中
本篇博文为使用python爬虫爬取糗事百科content并将爬取内容存入excel中保存·. 实验环境:Windows10 代码编辑工具:pycharm 使用selenium(自动化测试工具)+p ...
- python_爬虫一之爬取糗事百科上的段子
目标 抓取糗事百科上的段子 实现每按一次回车显示一个段子 输入想要看的页数,按 'Q' 或者 'q' 退出 实现思路 目标网址:糗事百科 使用requests抓取页面 requests官方教程 使用 ...
- 8.Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- python网络爬虫--简单爬取糗事百科
刚开始学习python爬虫,写了一个简单python程序爬取糗事百科. 具体步骤是这样的:首先查看糗事百科的url:http://www.qiushibaike.com/8hr/page/2/?s=4 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
随机推荐
- zookeeper分布式搭建
1下载并解压zookeeper安装包 2进入zookeeper配置文件目录,找到zoo_sample.cfg,执行cp zoo_sample.cfg zoo.cfg 3打开zoo.cfg文件,修改d ...
- $.grep()函数
定义和用法 $.grep() 函数使用指定的函数过滤数组中的元素,并返回过滤后的数组. 提示:源数组不会受到影响,过滤结果只反映在返回的结果数组中. 语法 $.grep( array, functio ...
- 使用 Rust 构建分布式 Key-Value Store
欢迎大家前往腾讯云社区,获取更多腾讯海量技术实践干货哦~ 引子 构建一个分布式 Key-Value Store 并不是一件容易的事情,我们需要考虑很多的问题,首先就是我们的系统到底需要提供什么样的功能 ...
- 插入排序-Python与PHP实现版
插入排序Python实现 import random a=[random.randint(1,999) for x in range(0,36)] # 直接插入排序算法 def insertionSo ...
- python paramiko模块 用密钥传输
VM_129_78_suse:/home/remote_paramiko # cat remote.py #!/usr/bin/env python import paramiko linux_cmd ...
- CVE-2017-11882漏洞利用
CVE-2017-11882漏洞利用 最新Office的CVE-2017-11882的poc刚刚发布出来,让人眼前一亮,完美无弹窗,无视宏,影响Ms offcie全版本,对于企业来说危害很大.在此简单 ...
- lumen 中间件详解
我来给大家,讲解一下lumen中的中间件,高手勿喷. 首先,我们看下lumen中文档中的写法,我这里看的是5.3中文文档.https://lumen.laravel-china.org/docs/5. ...
- 五、Hadoop学习笔记————调优之硬件选择
ResourceManageer服务器需要选择性能较好的 若有1TB数据,每天增量为10GB,则需要预留17.8TB,*3是因为有三分备份,*1.3是因为还需要预留出空间给操作系统等等 若集群在三十台 ...
- 【续】抓个Firefox的小辫子,jQuery表示不背这黑锅,Chrome,Edge,IE8-11继续围观中
引子 昨天我发了一篇文章[抓个Firefox的小辫子,围观群众有:Chrome.Edge.IE8-11],提到了一个Firefox很多版本都存在的问题,而相同的测试页面在Chrome.Edge.IE8 ...
- C#Winform窗体 DataGridView全选按钮的实现方式
最近,在做CS程序遇到一个头疼的问题,datagridview列表的全选按钮遇到各种问题,做的是自适应窗体大小,当窗体最大化导致全选按钮出现与列表数据不一致,特别不搭配,试了很久,网上也找了好多资料各 ...