[Oracle]高水位标记(HWM)
(一)高水位标记(High Water Mark,HWM)的概念
所谓高水位标记,是指一个已经分配的段中,已经使用的空间与未使用的空间的分界线。在表的使用过程中,随着数据的不断增多(insert),HWM不断向数据段未使用部分方向移动,而在删除数据(delete)的过程中,HWM并不会向反方向移动,即使删除全部数据,HWM依然不会改变。但是如果使用了truncate命令,则表的HWM会被重置为0。
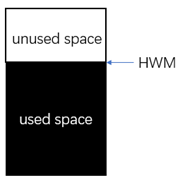
图1.segment
(二)高水位标记的影响
- 全表扫描要读出直到HWM标记的所有的属于该表的数据块(used space),即使该表中没有任何数据;
- 即使HWM下有空闲的数据块,如果在插入数据时使用了append参数,则在插入数据时使用HWM以上的数据块,HWM会自动增大。
(三)如何知道一个表的HWM
1.首先对表进行分析
SQL > ANALYZE TABLE table_name ESTIMATE/COMPUTE STATISTICS;
2.查看水线
SELECT
blocks, --该表曾经使用过的数据块的数目,即水线
empty_blocks, --代表分配给该表,但是在水位线以上的数据块,即从来没有使用过的数据块
num_rows
FROM
user_tables
WHERE
table_name = ‘table_name’;
*注:在Oracle 11g中,收集数据库对象信息的最好方法,不再是使用带ESTIMATE或COMPUTE的ANALYSE语句,而是使用最新的DBMS_STATS包。但是,如果要收集数据库对象存储格式的有效性以及收集表与簇中的行迁移、行链接情况,还得使用ANALYSE。
(四)Oracle表段中的高水位线
每个Oracle数据块在ASSM段中都属于下面的一种状态:
- 高水位线以上
这些块未被格式化且从来没有被使用过。
- 高水位线以下(3类)
--已经分配,但是未格式化和未使用;
--格式化,且含有数据;
--格式化,不含有数据,因为数据被删除了。
(1)在创建表的时候,HWM位于segment左边的起始处,因为没有数据插入,segment中全部的block未被格式化和从未被使用。
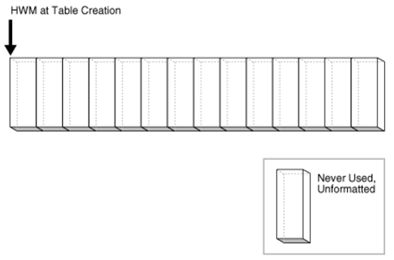
(2)假设一个事务将行数据插入到segmnet中,数据库必须分配一组数据块去保存行信息,被分配的数据块全在HWM之下,数据库格式化一个位图块来保存元数据,但是没有指定是哪一个数据块。
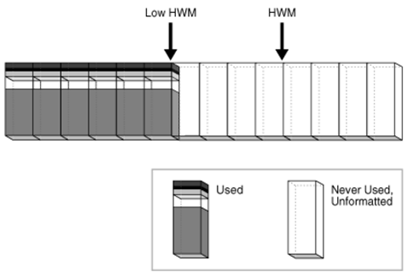
在HWM以下的数据块是被分配的,在HWM以上的数据块从未被分配和格式化。当insert时,数据可以写到有可用空间的任何块中。low HWM以下的部分,所有的块都被格式化,因为它们要么含有数据,要么以前包含数据。
(3)当insert时,数据库选择在HWM和low HWM之间的任意一个块进行写入,或者是HWM以下的一个有空闲空间的块进行写入。下图中,在Low HWM与HWM之间已写满块的两侧的数据块还未格式化。
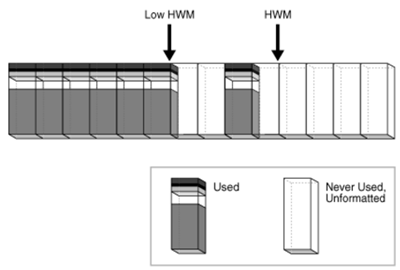
(4)low HWM对于全表扫描是非常重要的。因为HWM以下的数据块只有在要使用时才格式化,有一些块还未格式化。基于这个原因,数据库会去bitmap块查询low HWM的位置,然后会去读low HWM以下的全部数据块,因为数据库已经知道这些块全部被格式化了,对于在low HWM和HWM之间的数据块,数据库会挑选那些已经格式化了的数据块进行读操作。
(5)假设一个新的事务进行插入操作,但是bitmap指示目前在HWM以下已经没有足够的空间了,数据库会向右移动该segment的HWM,分配一组新的未格式化的数据块。
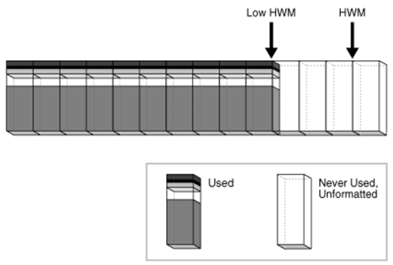
(五)降低HWM
降低HWM可以使用rebuild、truncate、shrink、move等操作。
(5.1)SHRINK
shrink技术是一种段收缩技术,可将表与索引高水位以下的碎片进行有效压缩,并将高水位进行回退。
使用方法如下:
step1. 启用行移动
SQL > ALTER TABLE table_name ENABLE ROW MOVEMENT;
step2. 压缩数据及下调HWM
SQL > ALTER TABLE table_name SHRINK SPACE CASCADE; --压缩表及相关数据段并下调HWM
或
SQL > ALTER TABLE table_name SHRINK SPACE COMPACT; --只压缩数据不下调HWM SQL > ALTER TABLE table_name SHRINK SPACE; --下调HWM
即该技术可以一次性压缩数据及下调HWM,也可以分两个阶段进行,第一阶段:在业务高峰,只压缩数据不下调HWM,第二阶段:在业务空闲时,下调HWM。
(5.2)MOVE Tablespace
语法为:
SQL > ALTER TABLE table_name MOVE TABLESPACE tablepsace_name;
需要注意:
--MOVE后不跟参数也行,不跟参数还是原来的表空间;
--MOVE后需要重建索引;
--如果以后还要网表里插入数据,没必要MOVE。MOVE释放出来的空间,只能这个表使用,其它的表或者segment无法使用。
(5.3)CTAS技术
即重建表技术。
SQL > CREATE TABLE new_table_name
AS
SELECT * FROM old_table_name; --将表的数据写入到一张新的表里 SQL > DROP TABLE old_table_name; --删除旧表 SQL > RENAME table new_table_name TO old_table_name --将新表名更改为旧表名
(5.4)EXP/IMP或EXPDP/IMPDP技术
与CTAS技术相当。
(5.5)DEALLOCATE技术
利用DEALLOCATE技术可以回收HWM以上从未使用过的数据块。语法如下
SQL > ALTER TABLE table_name DEALLOCATE UNUSED [KEEP integer]; --回收表段HWM以上的空间 SQL > ALTER INDEX index_name DEALLOCATE UNUSED [KEEP integer]; --回收索引段HWM以上的空间
(六)MOVE与SHRINK的区别
|
MOVE |
SHRINK(仅对ASSM有效) |
|
|
本质 |
move实际上是block级别的数据块拷贝,对表进行move后,该表所在blockid会发生改变数据的rowid自然也会发生改变,但是数据在table中的存储顺序并没有发生改变 |
shrink是对行数据进行移动。对表进行shrink后,部分行数据的rowid发生了变化,而table所位于的block区域的位置却没有发生变化。 |
|
重建索引 |
需要重建 |
可以通过cascade关键字重建 |
|
锁 |
TM(exclusive) |
TM(SX) |
|
空间要求 |
需要有原表大的空闲空间 |
不需要额外的空间 |
|
效果 |
压缩后会回收空间 |
压缩后会回收空间 |
详细例子见下面测试。
(七)高水位问题测试
(8.1)测试目的:
1.了解Oracle统计信息的概念;
2.测试使用delete与truncate删除数据对HWM的影响[主要目的]
(8.2)主要步骤
(1)创建表test01
create table test01
(
id number,
name varchar(15)
);
这个时候,去查看表与段的参数
SQL> select
2 dt.table_name,
3 dt.blocks,
4 dt.empty_blocks
5 from
6 dba_tables dt
7 where
8 dt.table_name = 'TEST01'; TABLE_NAME BLOCKS EMPTY_BLOCKS
------------------------------ ---------- ------------
TEST01 0 0 SQL>
SQL> select
2 ds.segment_name,
3 ds.segment_type,
4 ds.header_file,
5 ds.header_block,
6 ds.bytes,
7 ds.blocks,
8 ds.extents
9 from
10 dba_segments ds
11 where
12 ds.segment_name = 'TEST01'; SEGMENT_NAME SEGMENT_TYPE HEADER_FILE HEADER_BLOCK BYTES BLOCKS EXTENTS
------------- ------------------ ----------- ------------ ---------- ---------- ---------- SQL> exec dbms_stats.gather_table_stats('LIJIAMAN','TEST01'); PL/SQL procedure successfully completed SQL>
SQL> select
2 dt.table_name,
3 dt.blocks,
4 dt.empty_blocks
5 from
6 dba_tables dt
7 where
8 dt.table_name = 'TEST01'; TABLE_NAME BLOCKS EMPTY_BLOCKS
------------------------------ ---------- ------------
TEST01 0 0 SQL>
SQL> select
2 ds.segment_name,
3 ds.segment_type,
4 ds.header_file,
5 ds.header_block,
6 ds.bytes,
7 ds.blocks,
8 ds.extents
9 from
10 dba_segments ds
11 where
12 ds.segment_name = 'TEST01'; SEGMENT_NAME SEGMENT_TYPE HEADER_FILE HEADER_BLOCK BYTES BLOCKS EXTENTS
------------- ------------- ----------- ------------ ---------- ---------- ----------
通过以上结构可以看出,我在创建表后,去查看表信息,发现表拥有的blocks=0,以为是统计信息的问题,使用dbms_stats去重新收集表的基础信息,结果依然相同。然后查看该表段的信息,发现这个段并不存在。可以说明,数据库在创建表后,只存储了表的基本结构信息,只有在插入数据的时候,才会去分配区。
此时由于未分配数据块,也就不存在高水位线的问题。
(2)我们往test01里面插入10000条数据
SQL> declare
2 i number :=1;
3 begin
4 loop
5 if i > 10000
6 then
7 exit;
8 end if;
9 insert into test01 values(i,'euvcg');
10 i:=i+1;
11 end loop;
12 commit;
13 end;
14 / PL/SQL procedure successfully completed
再去看一下表与段的统计信息
SQL> select
2 dt.table_name,
3 dt.blocks,
4 dt.empty_blocks
5 from
6 dba_tables dt
7 where
8 dt.table_name = 'TEST01'; TABLE_NAME BLOCKS EMPTY_BLOCKS
----------- ---------- ------------
TEST01 0 0 SQL>
SQL> select
2 ds.segment_name,
3 ds.segment_type,
4 ds.header_file,
5 ds.header_block,
6 ds.bytes,
7 ds.blocks,
8 ds.extents
9 from
10 dba_segments ds
11 where
12 ds.segment_name = 'TEST01'; SEGMENT_NAME SEGMENT_TYPE HEADER_FILE HEADER_BLOCK BYTES BLOCKS EXTENTS
------------ ------------------ ----------- ------------ ---------- ---------- ----------
TEST01 TABLE 6 162 262144 32 4
表test01的blocks依然为0,我们使用dbms_stats重新收集统计信息,
SQL> exec dbms_stats.gather_table_stats('LIJIAMAN','TEST01');
PL/SQL procedure successfully completed
SQL> select
2 dt.table_name,
3 dt.blocks,
4 dt.empty_blocks
5 from
6 dba_tables dt
7 where
8 dt.table_name = 'TEST01'; TABLE_NAME BLOCKS EMPTY_BLOCKS
------------------------------ ---------- ------------
TEST01 28 0 SQL> select
2 ds.segment_name,
3 ds.segment_type,
4 ds.header_file,
5 ds.header_block,
6 ds.bytes,
7 ds.blocks,
8 ds.extents
9 from
10 dba_segments ds
11 where
12 ds.segment_name = 'TEST01'; SEGMENT_NAME SEGMENT_TYPE HEADER_FILE HEADER_BLOCK BYTES BLOCKS EXTENTS
------------ ------------------ ----------- ------------ ---------- ---------- ----------
TEST01 TABLE 6 162 262144 32 4
收集统计信息后,我们对段进行分析,插入10000条数据,oracle一共分配了4个区,每个区包含8个数据块,每个数据块大小为8KB。此时,表的统计数据已经有了,但是表的Blocks与段的Blocks数量不同,这是什么引起的呢?通过查看两个blocks栏位的定义,可以看到:
dba_tables.blocks:该表已经使用的数据块的数量(Number of used data blocks in the table);
dba_segments.blocks:该段中数据块的总数(Size, in Oracle blocks, of the segment)。
也就是说还有4个数据块还未使用。
可以使用ANALYZE进行统计
SQL> analyze table TEST01 compute statistics; Table analyzed SQL>
SQL> select
2 dt.table_name,
3 dt.blocks,
4 dt.empty_blocks
5 from
6 dba_tables dt
7 where
8 dt.table_name = 'TEST01'; TABLE_NAME BLOCKS EMPTY_BLOCKS
------------------------------ ---------- ------------
TEST01 28 4
经过分析,dba_tables统计的数据块与dba_segments统计的数据块数量相同了。
此时的高水位线应该如下:
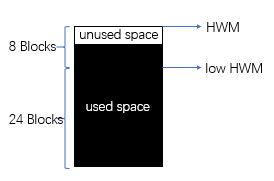
(3)删除test01里面的全部数据,重新统计信息,发现数据块并没有被回收释放。这些数据块(dba_tables.blocks=28)曾经拥有过数据,但是现在数据已被删除。
SQL> delete from test01; 10000 rows deleted SQL> commit; Commit complete SQL> analyze table test01 compute statistics; Table analyzed SQL>
SQL> select
2 dt.table_name,
3 dt.blocks,
4 dt.empty_blocks
5 from
6 dba_tables dt
7 where
8 dt.table_name = 'TEST01'; TABLE_NAME BLOCKS EMPTY_BLOCKS
------------------------------ ---------- ------------
TEST01 28 4
SQL> select
2 ds.segment_name,
3 ds.segment_type,
4 ds.header_file,
5 ds.header_block,
6 ds.bytes,
7 ds.blocks,
8 ds.extents
9 from
10 dba_segments ds
11 where
12 ds.segment_name = 'TEST01'; SEGMENT_NAME SEGMENT_TYPE HEADER_FILE HEADER_BLOCK BYTES BLOCKS EXTENTS
------------- ------------------ ----------- ------------ ---------- ---------- ----------
TEST01 TABLE 6 162 262144 32 4
此时的高水位线应该如下:
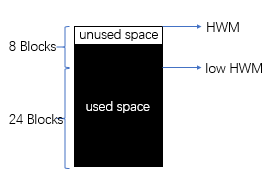
黑色(used space)里面目前并没有数据,它仅仅代表曾经被使用过,白色(unused space)代表这些块已经分配给了test01段,但是还未使用过。
(4)测试完了delete,接下来测试truncate
SQL> truncate table test01; Table truncated --truncate后直接查询,发现表的统计信息依然未变化,而段的数据块已经回收了
SQL> select
2 dt.table_name,
3 dt.blocks,
4 dt.empty_blocks
5 from
6 dba_tables dt
7 where
8 dt.table_name = 'TEST01'; TABLE_NAME BLOCKS EMPTY_BLOCKS
------------------------------ ---------- ------------
TEST01 28 4
SQL> select
2 ds.segment_name,
3 ds.segment_type,
4 ds.header_file,
5 ds.header_block,
6 ds.bytes,
7 ds.blocks,
8 ds.extents
9 from
10 dba_segments ds
11 where
12 ds.segment_name = 'TEST01'; SEGMENT_NAME SEGMENT_TYPE HEADER_FILE HEADER_BLOCK BYTES BLOCKS EXTENTS
-------------- ------------------ ----------- ------------ ---------- ---------- ----------
TEST01 TABLE 6 162 65536 8 1 --执行dbms_stats重新收集统计信息,发现表的blocks已经为0,但是表的blocks与段的blocks并不相等
SQL> exec dbms_stats.gather_table_stats('LIJIAMAN','TEST01'); PL/SQL procedure successfully completed SQL> select
2 dt.table_name,
3 dt.blocks,
4 dt.empty_blocks
5 from
6 dba_tables dt
7 where
8 dt.table_name = 'TEST01'; TABLE_NAME BLOCKS EMPTY_BLOCKS
------------------------------ ---------- ------------
TEST01 0 4
SQL> select
2 ds.segment_name,
3 ds.segment_type,
4 ds.header_file,
5 ds.header_block,
6 ds.bytes,
7 ds.blocks,
8 ds.extents
9 from
10 dba_segments ds
11 where
12 ds.segment_name = 'TEST01'; SEGMENT_NAME SEGMENT_TYPE HEADER_FILE HEADER_BLOCK BYTES BLOCKS EXTENTS
------------- ------------------ ----------- ------------ ---------- ---------- ----------
TEST01 TABLE 6 162 65536 8 1 --再使用ANALYZE进行分析,表的empty blocks为8,与段的blocks相等
SQL> analyze table test01 compute statistics; Table analyzed SQL> select
2 dt.table_name,
3 dt.blocks,
4 dt.empty_blocks
5 from
6 dba_tables dt
7 where
8 dt.table_name = 'TEST01'; TABLE_NAME BLOCKS EMPTY_BLOCKS
------------------------------ ---------- ------------
TEST01 0 8
SQL> select
2 ds.segment_name,
3 ds.segment_type,
4 ds.header_file,
5 ds.header_block,
6 ds.bytes,
7 ds.blocks,
8 ds.extents
9 from
10 dba_segments ds
11 where
12 ds.segment_name = 'TEST01'; SEGMENT_NAME SEGMENT_TYPE HEADER_FILE HEADER_BLOCK BYTES BLOCKS EXTENTS
-------------- ------------------ ----------- ------------ ---------- ---------- ----------
TEST01 TABLE 6 162 65536 8 1
可以发现,truncate后,表的空间已经回收,但是并不等于0,而是一个extent的大小。此时高水位线为:
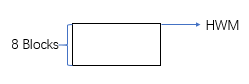
至于8个数据块是否有一个被使用(segment header),由于个人能力有限,无法进行分析 –_-
(8.3)结论:通过测试,delete无法降低高水位线,truncate可以。
(八)shrink与move测试
(9.1)测试目的:
1.测试shrink与move的区别,主要是第(七)点列出的区别
(9.2)测试步骤
(1)创建测试表,插入数据,分析表,查看统计信息
--创建表
SQL> create table test02
2 (
3 id number,
4 name varchar(15)
5 ); Table created --插入1000万条数据
SQL> declare
2 i number :=1;
3 begin
4 loop
5 if i > 10000000
6 then
7 exit;
8 end if;
9 insert into test02 values(i,'euvcg');
10 i:=i+1;
11 end loop;
12 commit;
13 end;
14 / PL/SQL procedure successfully completed Executed in 185.125 seconds --创建索引
SQL> create index test02_idx on test02 (id,name); Index created Executed in 17.172 seconds --分析表
SQL> exec dbms_stats.gather_table_stats('LIJIAMAN','TEST02'); PL/SQL procedure successfully completed Executed in 3.921 seconds SQL> analyze table test02 compute statistics; Table analyzed Executed in 39.11 seconds --查看分析结果
SQL> select
2 dt.table_name,
3 dt.blocks,
4 dt.empty_blocks
5 from
6 dba_tables dt
7 where
8 dt.table_name = 'TEST02'; TABLE_NAME BLOCKS EMPTY_BLOCKS
------------------------------ ---------- ------------
TEST02 23357 195 Executed in 0.078 seconds
SQL> select
2 ds.segment_name,
3 ds.segment_type,
4 ds.header_file,
5 ds.header_block,
6 ds.bytes,
7 ds.blocks,
8 ds.extents
9 from
10 dba_segments ds
11 where
12 ds.segment_name = 'TEST02'; SEGMENT_NAME SEGMENT_TYPE HEADER_FILE HEADER_BLOCK BYTES BLOCKS EXTENTS
------------- ------------------ ----------- ------------ ---------- ---------- ----------
TEST02 TABLE 6 130 192937984 23552 94 Executed in 0.078 seconds
可以看到。test02一共占用了94个extents,23552个数据块。其中23357个数据块有数据,195个数据块空闲。
接下来,我们先查看表的信息,这里截取了部分结果。在这里,我们需要了解ROWID的作用,rowid是数据在oracle储存中的具体位置,1-6位为object id,7-9位为file_id,10-15位代表block id,16-18位为row number。在下面结果中,前5条数据在AAAACD块中,后6条数据在AAAACE块中。我们取出一个block,查看其数据:
SQL> select * from test02 where rowid like 'AAASNnAAGAAAACM%';
ID NAME
---------- ---------------
2912 euvcg
2913 euvcg
2914 euvcg
2915 euvcg
... ...
3394 euvcg
3395 euvcg
484 rows selected
(2)删除test02的一半数据,数据块并没有释放,执行shrink操作
--删除500万条数据
SQL> declare
2 i number :=1;
3 begin
4 loop
5 if i > 10000000
6 then
7 exit;
8 end if;
9 delete test02 where id = i;
10 i:=i+2;
11 end loop;
12 commit;
13 end;
14 /
--经过查看,数据块未释放 --激活行移动
SQL> alter table test02 enable row movement; Table altered Executed in 0.078 seconds --执行shrink操作
SQL> alter table test02 shrink space cascade; Table altered Executed in 234.593 seconds
需要注意的是,在执行shrink的过程中,在表上是有锁存在的,在表上存在3级锁(SX)
SQL> select * from v$lock where type in ('TM','TX');
SID TYPE ID1 ID2 LMODE REQUEST CTIME BLOCK
--- ---- ---------- ---------- ---------- ---------- ---------- ----------
30 TM 74597 0 3 0 178 0
30 TX 327684 1294 6 0 0 0
30 TX 327699 994 6 0 178 0
(3)分析数据,查看表信息
SQL> analyze table test02 compute statistics;
Table analyzed SQL> select
2 dt.table_name,
3 dt.blocks,
4 dt.empty_blocks
5 from
6 dba_tables dt
7 where
8 dt.table_name = 'TEST02'; TABLE_NAME BLOCKS EMPTY_BLOCKS
---------- ---------- ------------
TEST02 11648 152
SQL> select
2 ds.segment_name,
3 ds.segment_type,
4 ds.header_file,
5 ds.header_block,
6 ds.bytes,
7 ds.blocks,
8 ds.extents
9 from
10 dba_segments ds
11 where
12 ds.segment_name = 'TEST02'; SEGMENT_NAME SEGMENT_TYPE HEADER_FILE HEADER_BLOCK BYTES BLOCKS EXTENTS
------------- ------------------ ----------- ------------ ---------- ---------- ----------
TEST02 TABLE 6 130 96665600 11800 83
在执行shrink之后,我们的数据块使用量由原来的23552减少为11800。
(4)再次查看上面数据块中的数据,可以看出在执行了shrink之后,该数据块中的数据发生了变化。对于该块,原来的数据保持不变,但是在已经删除数据的空间中,有其它块的数据插入了进来。
SQL> select * from test02 where rowid like 'AAASNnAAGAAAACM%';
ID NAME
---------- ---------------
2912 euvcg
4050 euvcg
2914 euvcg
4052 euvcg
2916 euvcg
4054 euvcg
3388 euvcg
3390 euvcg
3392 euvcg
3394 euvcg
399 rows selected
(9.3)结论
1.shrink是对行数据进行移动。对表进行shrink后,部分行数据的rowid发生了变化,而table所位于的block区域的位置却没有发生变化;
2.shrink产生TM(SX)锁及TX锁。
(9.4)对shrink有了一定的了解,我们再来看一下move
--创建表
create table test03
(
id number,
name varchar(15)
); --插入数据
SQL> declare
2 i number :=1;
3 begin
4 loop
5 if i > 10000
6 then
7 exit;
8 end if;
9 insert into test03 values(i,'euvcg');
10 i:=i+1;
11 end loop;
12 commit;
13 end;
14 / PL/SQL procedure successfully completed --统计信息
SQL> analyze table test03 compute statistics; Table analyzed --查看统计信息
SQL> select
2 dt.table_name,
3 dt.blocks,
4 dt.empty_blocks
5 from
6 dba_tables dt
7 where
8 dt.table_name = 'TEST03'; TABLE_NAME BLOCKS EMPTY_BLOCKS
------------------------------ ---------- ------------
TEST03 28 4
SQL> select
2 ds.segment_name,
3 ds.segment_type,
4 ds.header_file,
5 ds.header_block,
6 ds.bytes,
7 ds.blocks,
8 ds.extents
9 from
10 dba_segments ds
11 where
12 ds.segment_name = 'TEST03'; SEGMENT_NAME SEGMENT_TYPE HEADER_FILE HEADER_BLOCK BYTES BLOCKS EXTENTS
------------ ------------------ ----------- ------------ ---------- ---------- ----------
TEST03 TABLE 6 146 262144 32 4
取其中一个数据块,查看存储的信息
SQL> select rowid,id,name from test03 where rowid like 'AAASNxAAGAAAACY%'; ROWID ID NAME
------------------ ---------- ---------------
AAASNxAAGAAAACYAAA 3880 euvcg
AAASNxAAGAAAACYAAC 3882 euvcg
AAASNxAAGAAAACYAAE 3884 euvcg
AAASNxAAGAAAACYAAG 3886 euvcg
AAASNxAAGAAAACYAAI 3888 euvcg
AAASNxAAGAAAACYAAK 3890 euvcg
AAASNxAAGAAAACYAAM 3892 euvcg
AAASNxAAGAAAACYAAO 3894 euvcg
AAASNxAAGAAAACYAAQ 3896 euvcg
… … …
执行move操作
SQL> alter table test03 move; Table altered SQL> analyze table test03 compute statistics; Table analyzed SQL> select
2 dt.table_name,
3 dt.blocks,
4 dt.empty_blocks
5 from
6 dba_tables dt
7 where
8 dt.table_name = 'TEST03'; TABLE_NAME BLOCKS EMPTY_BLOCKS
------------------------------ ---------- ------------
TEST03 14 2
SQL> select
2 ds.segment_name,
3 ds.segment_type,
4 ds.header_file,
5 ds.header_block,
6 ds.bytes,
7 ds.blocks,
8 ds.extents
9 from
10 dba_segments ds
11 where
12 ds.segment_name = 'TEST03'; SEGMENT_NAME SEGMENT_TYPE HEADER_FILE HEADER_BLOCK BYTES BLOCKS EXTENTS
-------------- ------------------ ----------- ------------ ---------- ---------- ----------
TEST03 TABLE 6 186 131072 16 2
在move之前我们查看了数据块AAASNxAAGAAAACY的信息,一共有242行,在move之后,我们再去查看该数据块,发现没有数据存在。经过查看,id=4340的行信息之前存在该数据块,我们可以去看一下目前该行数据存在哪个数据块,找到新的数据块之后查看数据。
--查看了数据块AAASNxAAGAAAACY的信息,发现没有数据,说明数据已经转移到新的数据块中去了
SQL> select rowid,id,name from test03 where rowid like 'AAASNxAAGAAAACY%'; ROWID ID NAME
------------------ ---------- --------------- --先前的数据块中存在id=4340这一行数据,我们看一下该行数据目前的rowid
SQL> select rowid,id,name from test03 where id=4340; ROWID ID NAME
------------------ ---------- ---------------
AAASNyAAGAAAAC9AHf 4340 euvcg
--通过rowid,我们可以确定该行数据的新的数据块id,查询该数据块信息
SQL> select rowid,id,name from test03 where rowid like 'AAASNyAAGAAAAC9%';
ROWID ID NAME
------------------ ---------- ---------------
... ... ...
AAASNyAAGAAAAC9ADz 480 euvcg
AAASNyAAGAAAAC9AD0 482 euvcg
AAASNyAAGAAAAC9AD1 484 euvcg
AAASNyAAGAAAAC9AD2 486 euvcg
AAASNyAAGAAAAC9AD3 488 euvcg
AAASNyAAGAAAAC9AD4 490 euvcg
AAASNyAAGAAAAC9AD5 3880 euvcg
AAASNyAAGAAAAC9AD6 3882 euvcg
AAASNyAAGAAAAC9AD7 3884 euvcg
AAASNyAAGAAAAC9AD8 3886 euvcg
AAASNyAAGAAAAC9AD9 3888 euvcg
AAASNyAAGAAAAC9AD+ 3890 euvcg
AAASNyAAGAAAAC9AD/ 3892 euvcg
... ... ...
结论:1.move之后,与先前数据块信息进行对比,发现数据块信息发生了改变,数据已经移到了其它数据块中。多个数据块的信息合并到了同一个数据块,但是数据的顺序并没有发生改变,即数据在原块中的顺序是怎么样的,迁移到新数据块中还是这样的;
2.move之后,数据块的使用量减少了,说明move收缩空间,降低高水位;
参考文档:http://docs.oracle.com/cd/E11882_01/server.112/e40540/logical.htm#CNCPT89026
Oracle运维最佳实践-上
http://blog.csdn.net/wyzxg/article/details/5631721
[Oracle]高水位标记(HWM)的更多相关文章
- Oracle 高水位说明和释放表空间,加快表的查询速度
高水位的介绍 数据库运行了一段时间,经过一些列的删除.插入.更改操作有些表的高水位线就有可能和实际的表存储数据的情况相差特别多,为了提高检索该表的效率,建议对这些表进行收缩: 查找高水位线的表 查找表 ...
- 探究 Oracle 高水位对数据库性能影响
在开始深入分析之前,让我们先来了解一下高水位线 HWM. 一. HWM 的基本原理 (概念) 在 Oracle 中,高水位线(High-warter mark, HWM)被用来形容数据块的使用位置,即 ...
- oracle高水位问题
转自:https://blog.csdn.net/cnham/article/details/5987999 说到HWM,我们首先要简要的谈谈ORACLE的逻辑存储管理.我们知道,ORACLE在逻辑存 ...
- Oracle高水位2
--Oracle高水位2---------------------2013/11/24 一.什么是水线(High Water Mark)? 所有的oracle段(segments,在此,为了理解方便, ...
- oracle高水位
oracle高水位http://www.cnblogs.com/chuyuhuashi/p/3548260.htmlhttp://blog.csdn.net/wyzxg/article/details ...
- oracle高水位降低法
1.什么是高水位?(high water mark 简称:HWM) 所有的oracle段(segments,在此,为了理解方便,建议把segment作为表的一个同义词)都有一个在段内存放数据的 ...
- Oracle 高水位(HWM: High Water Mark)
http://blog.itpub.net/31397003/viewspace-2137246/ http://blog.itpub.net/12778571/viewspace-582695/ h ...
- Oracle降低高水位先(转载)
Oracle 降低高水位线的方法 高水位(HIGH WARTER MARK,HWM)好比水库中储水的水位,用于描述数据库中段的扩展方式.高水位对全表扫描方式有着至关重要的影响.当使用DELETE删除 ...
- oralce move和shrink释放高水位
转自:https://blog.51cto.com/fengfeng688/1955137 move和shrink的共同点: 收缩段,消除部分行迁移,消除空间碎片,使数据更紧密 shrink用法: 语 ...
随机推荐
- LiteIDE灰调配色方案
说明 本文写于2017-04-03,使用LiteIDE X31(基于Qt 4.8.5),操作系统为Windows. 使用 LiteIDE下载后解压即可使用.配色方案的所有配置文件都位于liteide/ ...
- 利刃 MVVMLight
已经很久没有写系列文章了,上一次是2012年写的HTLM5系列,想想我们应该是较早一批使用HTML5做项目的人. 相比我当时动不动100+的粉丝增长和两天3000+的阅读量,MVVM Light只能算 ...
- 编写原生Node.js模块
导语:当Javascript的性能需要优化,或者需要增强Javascript能力的时候,就需要依赖native模块来实现了. 应用场景 日常工作中,我们经常需要将原生的Node.js模块做为依赖并在项 ...
- WebSocket+MSE——HTML5 直播技术解析
作者 | 刘博(又拍云多媒体开发工程师) 当前为了满足比较火热的移动 Web 端直播需求,一系列的 HTML5 直播技术迅速的发展起来. 常见的可用于 HTML5 的直播技术有 HLS.WebSock ...
- 腾讯AlloyTeam发布AlloyLever - 开发调试发布错误监控上报用户问题定位尽在1kb代码
AlloyLever [官网][Giuhub] 1kb(gzip)代码搞定开发调试发布,错误监控上报,用户问题定位. 支持错误监控和上报 支持 vConsole错误展示 支持开发阶段使用 vConso ...
- android 定时器(Handler Timer Thread AlarmManager CountDownTimer)
Android实现定时任务一般会使用以上(Handler Timer Thread AlarmManager CountDownTimer)五种方式.当然还有很多组合使用(比如Handler+Thre ...
- Java web中常见编码乱码问题(二)
根据上篇记录Java web中常见编码乱码问题(一), 接着记录乱码案例: 案例分析: 2.输出流写入内容或者输入流读取内容时乱码(内容中有中文) 原因分析: a. 如果是按字节写入或读取时乱码, ...
- vscode中使用markdown
vscode中使用markdown vscode 是微软推出一款轻量级的文本编辑工具,类似于sublime,由于其拥有丰富的插件,安装使用也非常简单,所以深受广大程序员的喜爱. markdown 是一 ...
- .Net中的AOP系列之《将AOP作为架构工具》
返回<.Net中的AOP>系列学习总目录 本篇目录 编译时初始化和验证 编译时初始化 切面验证的正确用法 真实案例:复习线程 架构约束 强制架构 真实案例:NHibernate 多播 类级 ...
- C++判断一个数字是否为质数
关于素数的算法是程序竞赛比较重要的数论知识,我们来看通常会使用的几个算法. 我们先来复习几个基本概念: 质数:对于大于1的自然数,若除了1和它本身,没有别的因数,则称这个数为质数,质数也叫素数.反之, ...