深度学习:Keras入门(一)之基础篇
1.关于Keras
1)简介
Keras是由纯python编写的基于theano/tensorflow的深度学习框架。
Keras是一个高层神经网络API,支持快速实验,能够把你的idea迅速转换为结果,如果有如下需求,可以优先选择Keras:
a)简易和快速的原型设计(keras具有高度模块化,极简,和可扩充特性)
b)支持CNN和RNN,或二者的结合
c)无缝CPU和GPU切换
2)设计原则
a)用户友好:Keras是为人类而不是天顶星人设计的API。用户的使用体验始终是我们考虑的首要和中心内容。Keras遵循减少认知困难的最佳实践:Keras提供一致而简洁的API, 能够极大减少一般应用下用户的工作量,同时,Keras提供清晰和具有实践意义的bug反馈。
b)模块性:模型可理解为一个层的序列或数据的运算图,完全可配置的模块可以用最少的代价自由组合在一起。具体而言,网络层、损失函数、优化器、初始化策略、激活函数、正则化方法都是独立的模块,你可以使用它们来构建自己的模型。
c)易扩展性:添加新模块超级容易,只需要仿照现有的模块编写新的类或函数即可。创建新模块的便利性使得Keras更适合于先进的研究工作。
d)与Python协作:Keras没有单独的模型配置文件类型(作为对比,caffe有),模型由python代码描述,使其更紧凑和更易debug,并提供了扩展的便利性。
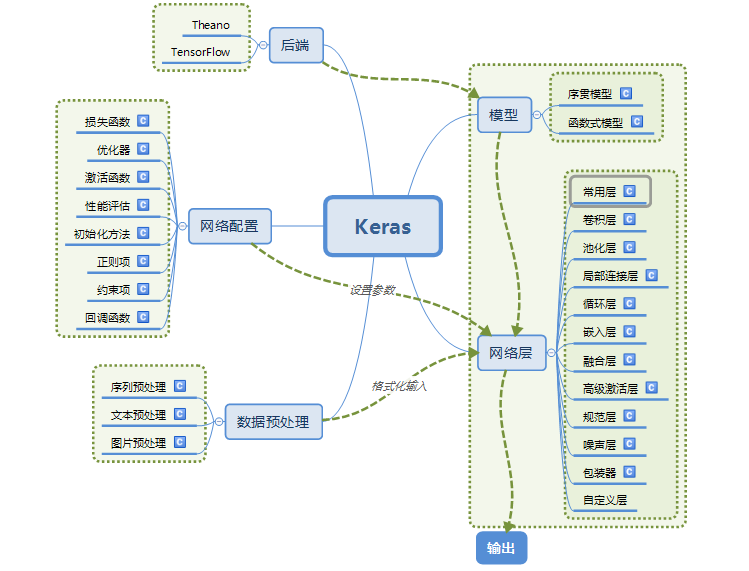
2.Keras的模块结构
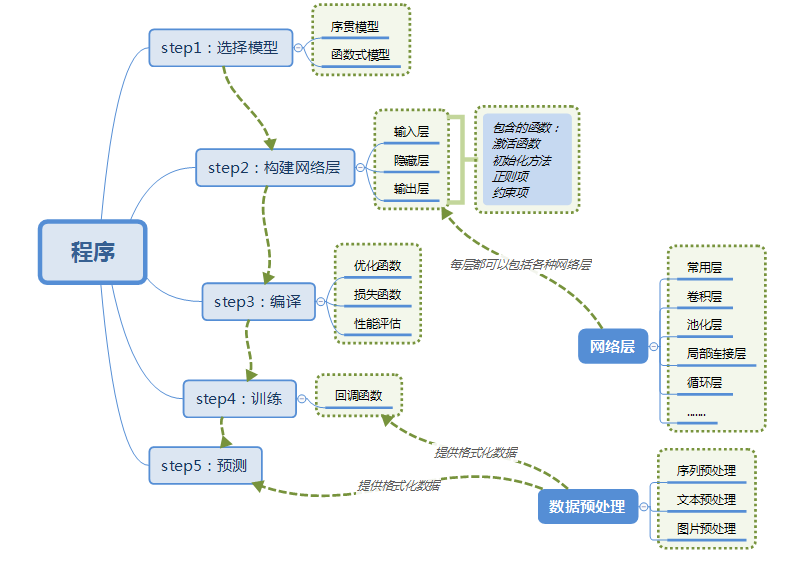
3.使用Keras搭建一个神经网络
4.主要概念
1)符号计算
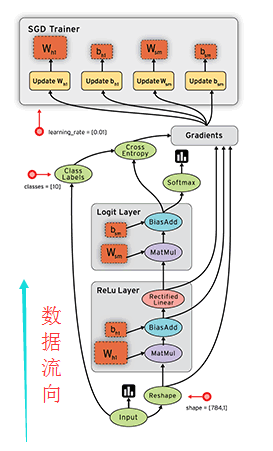
Keras的底层库使用Theano或TensorFlow,这两个库也称为Keras的后端。无论是Theano还是TensorFlow,都是一个“符号式”的库。符号计算首先定义各种变量,然后建立一个“计算图”,计算图规定了各个变量之间的计算关系。
符号计算也叫数据流图,其过程如下(gif图不好打开,所以用了静态图,数据是按图中黑色带箭头的线流动的):
2)张量
张量(tensor),可以看作是向量、矩阵的自然推广,用来表示广泛的数据类型。张量的阶数也叫维度。
0阶张量,即标量,是一个数。
1阶张量,即向量,一组有序排列的数
2阶张量,即矩阵,一组向量有序的排列起来
3阶张量,即立方体,一组矩阵上下排列起来
4阶张量......
依次类推
重点:关于维度的理解
假如有一个10长度的列表,那么我们横向看有10个数字,也可以叫做10维度,纵向看只能看到1个数字,那么就叫1维度。注意这个区别有助于理解Keras或者神经网络中计算时出现的维度问题。
3)数据格式(data_format)
目前主要有两种方式来表示张量:
a) th模式或channels_first模式,Theano和caffe使用此模式。
b)tf模式或channels_last模式,TensorFlow使用此模式。
下面举例说明两种模式的区别:
对于100张RGB3通道的16×32(高为16宽为32)彩色图,
th表示方式:(100,3,16,32)
tf表示方式:(100,16,32,3)
唯一的区别就是表示通道个数3的位置不一样。
4)模型
Keras有两种类型的模型,序贯模型(Sequential)和函数式模型(Model),函数式模型应用更为广泛,序贯模型是函数式模型的一种特殊情况。
a)序贯模型(Sequential):单输入单输出,一条路通到底,层与层之间只有相邻关系,没有跨层连接。这种模型编译速度快,操作也比较简单
b)函数式模型(Model):多输入多输出,层与层之间任意连接。这种模型编译速度慢。
5.第一个示例
这里也采用介绍神经网络时常用的一个例子:手写数字的识别。
在写代码之前,基于这个例子介绍一些概念,方便大家理解。
PS:可能是版本差异的问题,官网中的参数和示例中的参数是不一样的,官网中给出的参数少,并且有些参数支持,有些不支持。所以此例子去掉了不支持的参数,并且只介绍本例中用到的参数。
1)Dense(500,input_shape=(784,))
a)Dense层属于网络层-->常用层中的一个层
b) 500表示输出的维度,完整的输出表示:(*,500):即输出任意个500维的数据流。但是在参数中只写维度就可以了,比较具体输出多少个是有输入确定的。换个说法,Dense的输出其实是个N×500的矩阵。
c)input_shape(784,) 表示输入维度是784(28×28,后面具体介绍为什么),完整的输入表示:(*,784):即输入N个784维度的数据
2)Activation('tanh')
a)Activation:激活层
b)'tanh' :激活函数
3)Dropout(0.5)
在训练过程中每次更新参数时随机断开一定百分比(rate)的输入神经元,防止过拟合。
4)数据集
数据集包括60000张28×28的训练集和10000张28×28的测试集及其对应的目标数字。如果完全按照上述数据格式表述,以tensorflow作为后端应该是(60000,28,28,3),因为示例中采用了mnist.load_data()获取数据集,所以已经判断使用了tensorflow作为后端,因此数据集就变成了(60000,28,28),那么input_shape(784,)应该是input_shape(28,28,)才对,但是在这个示例中这么写是不对的,需要转换成(60000,784),才可以。为什么需要转换呢?
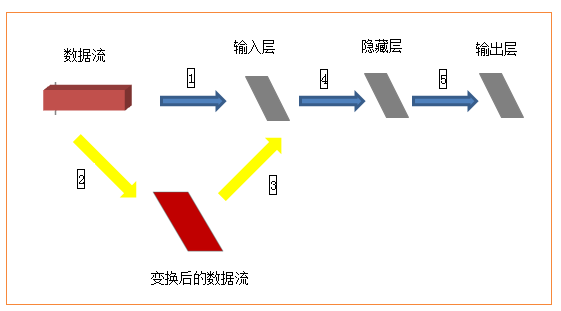
如上图,训练集(60000,28,28)作为输入,就相当于一个立方体,而输入层从当前角度看就是一个平面,立方体的数据流怎么进入平面的输入层进行计算呢?所以需要进行黄色箭头所示的变换,然后才进入输入层进行后续计算。至于从28*28变换成784之后输入层如何处理,就不需要我们关心了。(喜欢钻研的同学可以去研究下源代码)。
并且,Keras中输入多为(nb_samples, input_dim)的形式:即(样本数量,输入维度)。
5)示例代码
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.optimizers import SGD
from keras.datasets import mnist
import numpy
'''
第一步:选择模型
'''
model = Sequential()
'''
第二步:构建网络层
'''
model.add(Dense(500,input_shape=(784,))) # 输入层,28*28=784
model.add(Activation('tanh')) # 激活函数是tanh
model.add(Dropout(0.5)) # 采用50%的dropout model.add(Dense(500)) # 隐藏层节点500个
model.add(Activation('tanh'))
model.add(Dropout(0.5)) model.add(Dense(10)) # 输出结果是10个类别,所以维度是10
model.add(Activation('softmax')) # 最后一层用softmax作为激活函数 '''
第三步:编译
'''
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True) # 优化函数,设定学习率(lr)等参数
model.compile(loss='categorical_crossentropy', optimizer=sgd, class_mode='categorical') # 使用交叉熵作为loss函数 '''
第四步:训练
.fit的一些参数
batch_size:对总的样本数进行分组,每组包含的样本数量
epochs :训练次数
shuffle:是否把数据随机打乱之后再进行训练
validation_split:拿出百分之多少用来做交叉验证
verbose:屏显模式 0:不输出 1:输出进度 2:输出每次的训练结果
'''
(X_train, y_train), (X_test, y_test) = mnist.load_data() # 使用Keras自带的mnist工具读取数据(第一次需要联网)
# 由于mist的输入数据维度是(num, 28, 28),这里需要把后面的维度直接拼起来变成784维
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1] * X_train.shape[2])
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1] * X_test.shape[2])
Y_train = (numpy.arange(10) == y_train[:, None]).astype(int)
Y_test = (numpy.arange(10) == y_test[:, None]).astype(int) model.fit(X_train,Y_train,batch_size=200,epochs=50,shuffle=True,verbose=0,validation_split=0.3)
model.evaluate(X_test, Y_test, batch_size=200, verbose=0) '''
第五步:输出
'''
print("test set")
scores = model.evaluate(X_test,Y_test,batch_size=200,verbose=0)
print("")
print("The test loss is %f" % scores)
result = model.predict(X_test,batch_size=200,verbose=0) result_max = numpy.argmax(result, axis = 1)
test_max = numpy.argmax(Y_test, axis = 1) result_bool = numpy.equal(result_max, test_max)
true_num = numpy.sum(result_bool)
print("")
print("The accuracy of the model is %f" % (true_num/len(result_bool)))
深度学习:Keras入门(一)之基础篇的更多相关文章
- 深度学习:Keras入门(一)之基础篇【转】
本文转载自:http://www.cnblogs.com/lc1217/p/7132364.html 1.关于Keras 1)简介 Keras是由纯python编写的基于theano/tensorfl ...
- 深度学习:Keras入门(一)之基础篇(转)
转自http://www.cnblogs.com/lc1217/p/7132364.html 1.关于Keras 1)简介 Keras是由纯python编写的基于theano/tensorflow的深 ...
- 『深度应用』NLP机器翻译深度学习实战课程·零(基础概念)
0.前言 深度学习用的有一年多了,最近开始NLP自然处理方面的研发.刚好趁着这个机会写一系列NLP机器翻译深度学习实战课程. 本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内 ...
- Java入门到精通——基础篇之多线程实现简单的PV操作的进程同步
Java入门到精通——基础篇之多线程实现简单的PV操作的进程同步 一.概述 PV操作是对信号量进行的操作. 进程同步是指在并发进程之间存在一种制约关系,一个进程的执行依赖另一个进程的消 ...
- Tensorflow深度学习之十二:基础图像处理之二
Tensorflow深度学习之十二:基础图像处理之二 from:https://blog.csdn.net/davincil/article/details/76598474 首先放出原始图像: ...
- 深度学习Keras框架笔记之AutoEncoder类
深度学习Keras框架笔记之AutoEncoder类使用笔记 keras.layers.core.AutoEncoder(encoder, decoder,output_reconstruction= ...
- 深度学习Keras框架笔记之TimeDistributedDense类
深度学习Keras框架笔记之TimeDistributedDense类使用方法笔记 例: keras.layers.core.TimeDistributedDense(output_dim,init= ...
- 深度学习Keras框架笔记之Dense类(标准的一维全连接层)
深度学习Keras框架笔记之Dense类(标准的一维全连接层) 例: keras.layers.core.Dense(output_dim,init='glorot_uniform', activat ...
- (转)Deep Learning深度学习相关入门文章汇摘
from:http://farmingyard.diandian.com/post/2013-04-07/40049536511 来源:十一城 http://elevencitys.com/?p=18 ...
随机推荐
- 2、Java应用中常见的JDBC连接字符串(SQLite、MySQL、Oracle、Sybase、SQLServer、DB2)
2.Java应用中常见的JDBC连接字符串 Java应用中连接数据库是不可或缺的,于是便整理一些可能用到的JDBC的jar包及其相匹配的URL,以备日后查阅. 1)SQLite Class.forNa ...
- 028hibernate缓存(性能优化策略)
一级缓存 二级缓存 查询缓存 缓存是为了提高性能 变化不是很大,相对静态的对象放入缓存 对象的创建比较耗时
- Building Particle Filters and Particle MCMC in NIMBLE
This example shows how to construct and conduct inference on a state space model using particle filt ...
- node--更新数据库问题
昨天测试blog的comment功能,在新增comment相关的代码之后,重启应用,出现Cannot call method 'forEach' of undefined .反复核对代码,都没发现异常 ...
- ASP.NET Web API 自定义 HttpParameterBinding
背景 问题的起因是这样的.群里面一个哥们儿发现在使用 ASP.NET WebAPI 时,不能在同一个方法签名中使用多次 FromBodyAttribute 这个 Attribute .正好我也在用 W ...
- python爬虫从入门到放弃(九)之 实例爬取上海高级人民法院网开庭公告数据
通过前面的文章已经学习了基本的爬虫知识,通过这个例子进行一下练习,毕竟前面文章的知识点只是一个 一个单独的散知识点,需要通过实际的例子进行融合 分析网站 其实爬虫最重要的是前面的分析网站,只有对要爬取 ...
- iOS项目评估报告
1.整体项目无分层概念,结构混乱,代码耦合严重. 影响:后期扩展困难,维护困难. 解决方案:1.整体采用mvc模式. 2.在原来的基础再抽离出业务层 3.业务层按模块管理,合理分层分包. 4.做好共用 ...
- POI使用:解析xls/xlsx文件(兼容office2003/2007/2010版本)
package cn.eguid; import java.io.Closeable; import java.io.File; import java.io.FileInputStream; imp ...
- Qt自定义标签按钮
当你接触到Qt时,你会为它极为方便的跨平台方面感到吃惊,从而想尝试着使用Qt.渐渐地你会发现Qt自带的一些控件不能满足自己的需要,此时就需要我们自己定义一个属于自己的控件.总所周知,标签的风格设置类比 ...
- Java中SimpleDateFormat用法详解
所有已实现的接口: Serializable, Cloneable SimpleDateFormat 是一个以与语言环境有关的方式来格式化和解析日期的具体类.它允许进行格式化(日期 -> 文本) ...