SparkMLib分类算法之朴素贝叶斯分类
SparkMLib分类算法之朴素贝叶斯分类
(一)朴素贝叶斯分类理解
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。简单来说,朴素贝叶斯分类器假设样本每个特征与其他特征都不相关。举个例子,如果一种水果具有红,圆,直径大概4英寸等特征,该水果可以被判定为是苹果。尽管这些特征相互依赖或者有些特征由其他特征决定,然而朴素贝叶斯分类器认为这些属性在判定该水果是否为苹果的概率分布上独立的。尽管是带着这些朴素思想和过于简单化的假设,但朴素贝叶斯分类器在很多复杂的现实情形中仍能够取得相当好的效果。朴素贝叶斯分类器的一个优势在于只需要根据少量的训练数据估计出必要的参数(离散型变量是先验概率和类条件概率,连续型变量是变量的均值和方差)。


实例讲解:
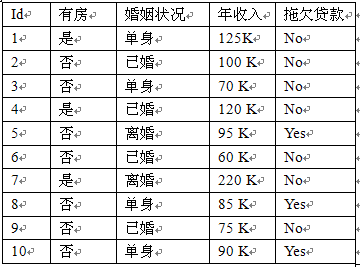
从该数据集计算得到的先验概率以及每个离散属性的类条件概率、连续属性的类条件概率分布的参数(样本均值和方差)如下:
先验概率:P(Yes)=0.3;P(No)=0.7
P(有房=是|No) = 3/7
P(有房=否|No) = 4/7
P(有房=是|Yes) = 0
P(有房=否|Yes) = 1
P(婚姻状况=单身|No) = 2/7
P(婚姻状况=离婚|No) = 1/7
P(婚姻状况=已婚|No) = 4/7
P(婚姻状况=单身|Yes) = 2/3
P(婚姻状况=离婚|Yes) = 1/3
P(婚姻状况=已婚|Yes) = 0
年收入:
如果类=No:样本均值=110; 样本方差=2975
如果类=Yes:样本均值=90; 样本方差=25
——》待预测记录:X={有房=否,婚姻状况=已婚,年收入=120K}
P(No)*P(有房=否|No)*P(婚姻状况=已婚|No)*P(年收入=120K|No)=0.7*4/7*4/7*0.0072=0.0024
P(Yes)*P(有房=否|Yes)*P(婚姻状况=已婚|Yes)*P(年收入=120K|Yes)=0.3*1*0*1.2*10-9=0
由于0.0024大于0,所以该记录分类为No。
从上面的例子可以看出,如果有一个属性的类条件概率等于0,则整个类的后验概率就等于0。仅仅使用记录比例来估计类条件概率的方法显得太脆弱了,尤其是当训练样例很少而属性数目又很多时。解决该问题的方法是使用m估计方法来估计条件概率:

(二),SparkMLlib实现朴素贝叶斯算法应用
1,数据集下载: http://www.kaggle.com/c/stumbleupon/data 中的(train.txt和test.txt
2,数据集预处理
1,去除第一行:sed 1d train.tsv >train_nohead.tsv
2,去除干扰数据及处理数据不全等情况,从而获取训练数据集:
val orig_file=sc.textFile("train_nohead.tsv")
val ndata_file=orig_file.map(_.split("\t")).map{
r =>
val trimmed =r.map(_.replace("\"",""))
val lable=trimmed(r.length-1).toDouble
val feature=trimmed.slice(4,r.length-1).map(d => if(d=="?")0.0
else d.toDouble).map(d =>if(d<0) 0.0 else d)
LabeledPoint(lable,Vectors.dense(feature))
}.randomSplit(Array(0.7,0.3),11L)//划分为训练和测试数据集
val ndata_train=ndata_file(0).cache()//训练集
val ndata_test=ndata_file(1)//测试集
3,训练贝叶斯模型,及评估模型(精确值,PR曲线,ROC曲线)
val model_NB=NaiveBayes.train(ndata_train)
/*贝叶斯分类结果的正确率*/
val correct_NB=ndata_train.map{
point => if(model_NB.predict(point.features)==point.label)
1 else 0
}.sum()/ndata_train.count()//0.565959409594096
/*准确率 - 召回率( PR )曲线*和ROC 曲线输出*/
val metricsNb=Seq(model_NB).map{
model =>
val socreAndLabels=ndata_train.map {
point => (model.predict(point.features), point.label)
}
val metrics=new BinaryClassificationMetrics(socreAndLabels)
(model.getClass.getSimpleName,metrics.areaUnderPR(),metrics.areaUnderROC())
}
metricsNb.foreach{ case (m, pr, roc) =>
println(f"$m, Area under PR: ${pr * 100.0}%2.4f%%, Area under ROC: ${roc * 100.0}%2.4f%%")
}
/*NaiveBayesModel, Area under PR: 68.0851%, Area under ROC: 58.3559%*/
4,模型调优
1,改变特征值得选取,选取文本特征使用(1-of-k)方法
/*新特征,选取第三列文本特征*/
val categories = orig_file.map(_.split("\t")).map(r => r(3)).distinct.collect.zipWithIndex.toMap
val dataNB = orig_file.map(_.split("\t")).map { r =>
val trimmed = r.map(_.replaceAll("\"", ""))
val label = trimmed(r.length - 1).toInt
val categoryIdx = categories(r(3))
val categoryFeatures = Array.ofDim[Double](categories.size)
categoryFeatures(categoryIdx) = 1.0
LabeledPoint(label, Vectors.dense(categoryFeatures))
}.randomSplit(Array(0.7,0.3),11L)
val dataNB_train=dataNB(0)
val dataNB_test=dataNB(1)/*训练朴素贝叶斯*/
val model_NB=NaiveBayes.train(dataNB_train)
/*贝叶斯分类结果的正确率*/
val correct_NB=dataNB_test.map{
point => if(model_NB.predict(point.features)==point.label)
1 else 0
}.sum()/dataNB_test.count()//0.6111623616236163
/*PR曲线和AOC曲线*/
val metricsNb=Seq(model_NB).map{
model =>
val socreAndLabels=dataNB_test.map {
point => (model.predict(point.features), point.label)
}
val metrics=new BinaryClassificationMetrics(socreAndLabels)
(model.getClass.getSimpleName,metrics.areaUnderPR(),metrics.areaUnderROC())
}
MetricsNb.foreach{ case (m, pr, roc) =>
println(f"$m, Area under PR: ${pr * 100.0}%2.4f%%, Area under ROC: ${roc * 100.0}%2.4f%%")
}
/*NaiveBayesModel, Area under PR: 74.8977%, Area under ROC: 60.1735%*/
2,修改参数,效果不是很明显
/*改变label值*/
def trainNBWithParams(input: RDD[LabeledPoint], lambda: Double) = {
val nb = new NaiveBayes
nb.setLambda(lambda)
nb.run(input)
}
val nbResults = Seq(0.001, 0.01, 0.1, 1.0, 10.0).map { param =>
val model = trainNBWithParams(dataNB_train, param)
val scoreAndLabels = dataNB_test.map { point =>
(model.predict(point.features), point.label)
}
val metrics = new BinaryClassificationMetrics(scoreAndLabels)
(s"$param lambda", metrics.areaUnderROC)
}
nbResults.foreach { case (param, auc) => println(f"$param, AUC = ${auc * 100}%2.2f%%")
}
/*results
0.001 lambda, AUC = 60.17%
0.01 lambda, AUC = 60.17%
0.1 lambda, AUC = 60.17%
1.0 lambda, AUC = 60.17%
10.0 lambda, AUC = 60.17%
*/
参考网址:
http://blog.csdn.net/han_xiaoyang/article/details/50629608
SparkMLib分类算法之朴素贝叶斯分类的更多相关文章
- 算法杂货铺——分类算法之朴素贝叶斯分类(Naive Bayesian classification)
算法杂货铺——分类算法之朴素贝叶斯分类(Naive Bayesian classification) 0.写在前面的话 我个人一直很喜欢算法一类的东西,在我看来算法是人类智慧的精华,其中蕴含着无与伦比 ...
- 分类算法之朴素贝叶斯分类(Naive Bayesian classification)
分类算法之朴素贝叶斯分类(Naive Bayesian classification) 0.写在前面的话 我个人一直很喜欢算法一类的东西,在我看来算法是人类智慧的精华,其中蕴含着无与伦比的美感.而每次 ...
- (ZT)算法杂货铺——分类算法之朴素贝叶斯分类(Naive Bayesian classification)
https://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html 0.写在前面的话 我个人一直很喜欢算 ...
- 分类算法之朴素贝叶斯分类(Naive Bayesian classification)
1.1.摘要 贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类.本文作为分类算法的第一篇,将首先介绍分类问题,对分类问题进行一个正式的定义.然后,介绍贝叶斯分类算法的基 ...
- 分类算法之朴素贝叶斯分类(Naive Bayesian Classification)
1.什么是分类 分类是一种重要的数据分析形式,它提取刻画重要数据类的模型.这种模型称为分类器,预测分类的(离散的,无序的)类标号.例如医生对病人进行诊断是一个典型的分类过程,医生不是一眼就看出病人得了 ...
- 数据挖掘十大经典算法(9) 朴素贝叶斯分类器 Naive Bayes
贝叶斯分类器 贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类.眼下研究较多的贝叶斯分类器主要有四种, ...
- 十大经典数据挖掘算法(9) 朴素贝叶斯分类器 Naive Bayes
贝叶斯分类器 贝叶斯分类分类原则是一个对象的通过先验概率.贝叶斯后验概率公式后计算,也就是说,该对象属于一类的概率.选择具有最大后验概率的类作为对象的类属.现在更多的研究贝叶斯分类器,有四个,每间:N ...
- 文本分类(TFIDF/朴素贝叶斯分类器/TextRNN/TextCNN/TextRCNN/FastText/HAN)
目录 简介 TFIDF 朴素贝叶斯分类器 贝叶斯公式 贝叶斯决策论的理解 极大似然估计 朴素贝叶斯分类器 TextRNN TextCNN TextRCNN FastText HAN Highway N ...
- 【分类算法】朴素贝叶斯(Naive Bayes)
0 - 算法 给定如下数据集 $$T=\{(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)\},$$ 假设$X$有$J$维特征,且各维特征是独立分布的,$Y$有$K$种取值.则 ...
随机推荐
- Arduino String.h库函数详解
此库中包含 1 charAT() 2 compareTo() 3 concat() 4 endsWith() 5 equals() 6 equalslgnoreCase() 7 getBytes() ...
- 【原创】Octovis在Ubuntu16.04下运行出现core dump的解决方案
本人SLAM研究新手,使用系统为Ubuntu16.04.本文原址:http://www.cnblogs.com/hitlrk/p/6667253.html 在学习SLAM的过程中,使用Octomap进 ...
- 老李分享:loadrunner 的86401错误
老李分享:loadrunner 的86401错误 系统和软件配置: os:windows 2003loadruner版本:LoadRunner11loadrunner:协议:SMTP协议并发数:2 ...
- ORA-00918: 未明确定义列
ORA-00918: 未明确定义列 出现问题原因及解决办法. --正常写,结果带上表名的字段在处理后表头名称相同,在进行下一次嵌套时就会出现问题 select au.userxm,au01.user ...
- html+css底部自动固定底部
前端在切图过程中,肯定遇见过这种情况. 页面结构由三个部分组成,头部.内容.底部. 当一个页面的内容没撑满屏幕时,底部是跟着内容而并列存在的. 这个时候如果是大屏的话,底部下面会有多余的空白区域,而网 ...
- 【HDOJ 2150】线段交叉问题
Pipe Time Limit : 1000/1000ms (Java/Other) Memory Limit : 32768/32768K (Java/Other) Total Submissi ...
- 100_remove-duplicates-from-sorted-array
/*@Copyright:LintCode@Author: Monster__li@Problem: http://www.lintcode.com/problem/remove-duplica ...
- 【 js 模块加载 】深入学习模块化加载(node.js 模块源码)
一.模块规范 说到模块化加载,就不得先说一说模块规范.模块规范是用来约束每个模块,让其必须按照一定的格式编写.AMD,CMD,CommonJS 是目前最常用的三种模块化书写规范. 1.AMD(Asy ...
- MSMQ队列学习记录
微软消息队列-MicroSoft Message Queue(MSMQ) 使用感受:简单. 一.windows安装MSMQ服务 控制面板->控制面板->所有控制面板项->程序和功能- ...
- java线程控制安全
synchronized() 在线程运行的时候,有时会出现线程安全问题例如:买票程序,有可能会出现不同窗口买同一张编号的票 运行如下代码: public class runable implement ...