横截面数据分类——基于R
参考资料:
《复杂数据统计方法》&网络&帮助文件
适用情况:在因变量为分类变量而自变量含有多个分类变量或分类变量水平较多的情况。
一.
(一)概论和例子
数据来源:http://archive.ics.uci.edu/ml/datasets/Cardiotocography
自变量:LB - FHR baseline (beats per minute)
AC - # of accelerations per second
FM - # of fetal movements per second
UC - # of uterine contractions per second
DL - # of light decelerations per second
DS - # of severe decelerations per second
DP - # of prolongued decelerations per second
ASTV - percentage of time with abnormal short term variability
MSTV - mean value of short term variability
ALTV - percentage of time with abnormal long term variability
MLTV - mean value of long term variability
Width - width of FHR histogram
Min - minimum of FHR histogram
Max - Maximum of FHR histogram
Nmax - # of histogram peaks
Nzeros - # of histogram zeros
Mode - histogram mode
Mean - histogram mean
Median - histogram median
Variance - histogram variance
Tendency - histogram tendency
CLASS - FHR pattern class code (1 to 10)
因变量:
NSP - fetal state class code (N=normal; S=suspect; P=pathologic)
(二)产生交叉验证数据集
1.十折交叉验证 概念(百度百科)
英文名叫做10-fold cross-validation,用来测试算法准确性。是常用的测试方法。将数据集分成十分,轮流将其中9份作为训练数据,1份作为测试数据,进行试验。每次试验都会得出相应的正确率(或差错率)。10次的结果的正确率(或差错率)的平均值作为对算法精度的估计,一般还需要进行多次10折交叉验证(例如10次10折交叉验证),再求其均值,作为对算法准确性的估计。
之所以选择将数据集分为10份,是因为通过利用大量数据集、使用不同学习技术进行的大量试验,表明10折是获得最好误差估计的恰当选择,而且也有一些理论根据可以证明这一点。但这并非最终诊断,争议仍然存在。而且似乎5折或者20折与10折所得出的结果也相差无几。
Fold=function(Z=,w,D,seed=){
n=nrow(w)
d=:n
dd=list()
e=levels(w[,D])
T=length(e)
set.seed(seed)
for(i in :T){
d0=d[w[,D]==e[i]]
j=length(d0)
ZT=rep(:Z,ceiling(j/Z))[:j]
id=cbind(sample(ZT,length(ZT)),d0)
dd[[i]]=id}
mm=list()
for(i in :Z){u=NULL;
for(j in :T)u=c(u,dd[[j]][dd[[j]][,]==i,])
mm[[i]]=u}
return(mm)}
#读入数据
w=read.csv("CTG.NAOMIT.csv")
#因子化最后三个哑元变量
F=: #三个分类变量的列数
for(i in F)
w[,i]=factor(w[,i])
D= #因变量的位置
Z= #折数
n=nrow(w)#行数
mm=Fold(Z,w,D,)
二.决策树分类(分类树)
library(rpart.plot)
(a=rpart(NSP~.,w))#用决策树你和全部数据并打印输出
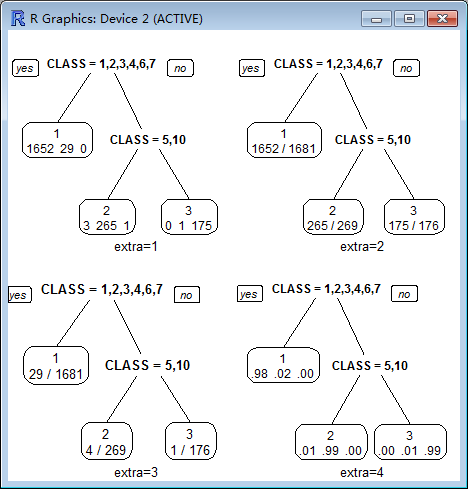
rpart.plot(a,type=,extra=)
rpart.plot参数解释:
x :
An rpart object. The only required argument.
type:
Type of plot. Five possibilities:
0 The default. Draw a split label at each split and a node label at each leaf.
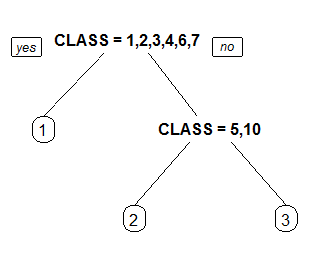
1 Label all nodes, not just leaves. Similar to text.rpart's all=TRUE.

2 Like 1 but draw the split labels below the node labels. Similar to the plots in the CART book.
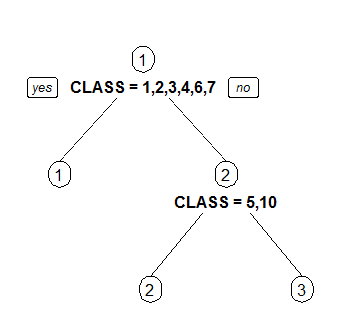
3 Draw separate split labels for the left and right directions.
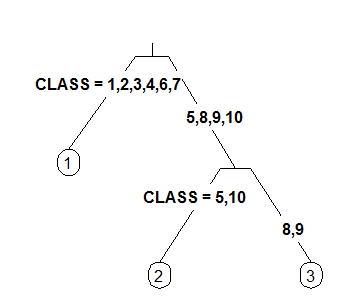
4 Like 3 but label all nodes, not just leaves. Similar to text.rpart's fancy=TRUE. See also clip.right.labs.
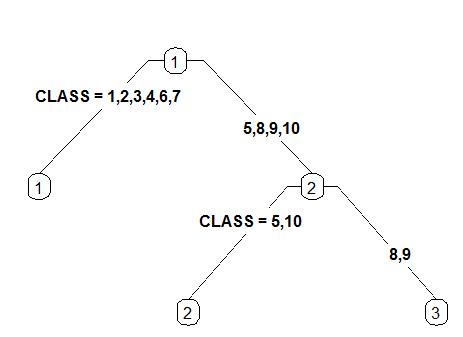
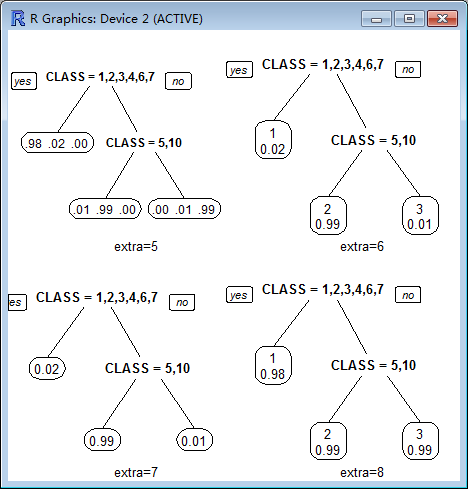
extra :
Display extra information at the nodes. Possible values:
0 No extra information (the default).
1 Display the number of observations that fall in the node (per class for class objects; prefixed by the number of events for poisson and exp models). Similar to text.rpart's use.n=TRUE.
2 Class models: display the classification rate at the node, expressed as the number of correct classifications and the number of observations in the node. Poisson and exp models: display the number of events.
3 Class models: misclassification rate at the node, expressed as the number of incorrect classifications and the number of observations in the node.
4 Class models: probability per class of observations in the node (conditioned on the node, sum across a node is 1).
5 Class models: like 4 but do not display the fitted class.
6 Class models: the probability of the second class only. Useful for binary responses.
7 Class models: like 6 but do not display the fitted class.
8 Class models: the probability of the fitted class.
9 Class models: the probabilities times the fraction of observations in the node (the probability relative to all observations, sum across all leaves is 1).
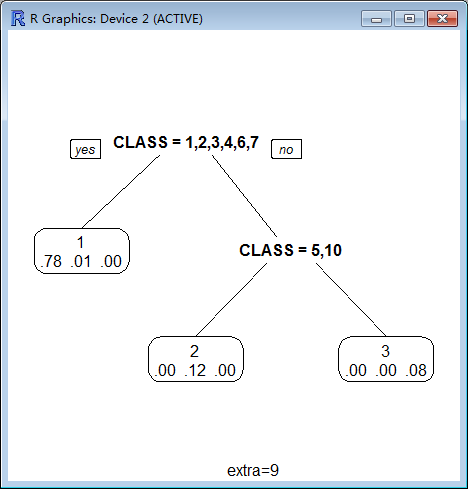
branch:
Controls the shape of the branch lines. Specify a value between 0 (V shaped branches) and 1 (square shouldered branches). Default is if(fallen.leaves) 1 else .2.

branch=0
branch=1
digits :
The number of significant digits in displayed numbers. Default 2.
rpart.plot(a,extra=,digits=)

横截面数据分类——基于R的更多相关文章
- 统计学习导论:基于R应用——第二章习题
目前在看统计学习导论:基于R应用,觉得这本书非常适合入门,打算把课后习题全部做一遍,记录在此博客中. 第二章习题 1. (a) 当样本量n非常大,预测变量数p很小时,这样容易欠拟合,所以一个光滑度更高 ...
- 基于R树索引的点面关系判断以及效率优化统计
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1.背景 在之前的博客中,我分别介绍了基于网格的空间索引(http:// ...
- 概率图模型 基于R语言 这本书中的第一个R语言程序
概率图模型 基于R语言 这本书中的第一个R语言程序 prior <- c(working =0.99,broken =0.01) likelihood <- rbind(working = ...
- 基于R语言的时间序列指数模型
时间序列: (或称动态数列)是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列.时间序列分析的主要目的是根据已有的历史数据对未来进行预测.(百度百科) 主要考虑的因素: 1.长期趋势(Lon ...
- 基于R语言的ARIMA模型
A IMA模型是一种著名的时间序列预测方法,主要是指将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型.ARIMA模型根据原序列是否平稳以及 ...
- Twitter基于R语言的时序数据突变检测(BreakoutDetection)
Twitter开源的时序数据突变检测(BreakoutDetection),基于无参的E-Divisive with Medians (EDM)算法,比传统的E-Divisive算法快3.5倍以上,并 ...
- (数据科学学习手札10)系统聚类实战(基于R)
上一篇我们较为系统地介绍了Python与R在系统聚类上的方法和不同,明白人都能看出来用R进行系统聚类比Python要方便不少,但是光介绍方法是没用的,要经过实战来强化学习的过程,本文就基于R对2016 ...
- 递归函数之阶乘和字符串反转-基于R和Python
Python课第五周开始讲函数了.递归函数.递归在python中不能超过900多层,否则报错内存溢出什么的.同样在R中递归太深也会报错,阈值和python中大概一样,900多次就报错了. error ...
- R学习:《机器学习与数据科学基于R的统计学习方法》中文PDF+代码
当前,机器学习和数据科学都是很重要和热门的相关学科,需要深入地研究学习才能精通. <机器学习与数据科学基于R的统计学习方法>试图指导读者掌握如何完成涉及机器学习的数据科学项目.为数据科学家 ...
随机推荐
- 关于XML(可扩展标记语言)的基础知识与写法
XML(Extensible Markup Language) HTML:超文本标记语言,主要用来展示 XML:可扩展标记语言,用来做数据传输XML特点:1.树状结构,有且只有一个根2.标签名自定 ...
- Python3 面向对象程序设计(类)
一.自定义类 1.属性与方法 格式: class classname: def __init__(self,a,b): self.a=a self.b=b def ... >一般都有一个__ ...
- 学会git玩转github,结尾有惊喜!有惊喜!有惊喜!
一.什么是Github Github是全球最大的社交编程及代码托管网站(https://github.com/). Github可以托管各种git库,并提供一个web界面(用户名.github.io/ ...
- CSS学习(页外引用还不懂)
CSS的语法结构为 选择符 {属性:值:} Selector {Property : Value:} 选择符:通配 *{....} , 元素 body{....} .h1{....}.p ...
- geotrellis使用(二十九)迁移geotrellis至1.1.1版
目录 前言 升级过程 总结 一.前言 由于忙着安装OpenStack等等各种事情,有半年的时间没有再亲密的接触geotrellis,甚至有半年的时间没能畅快的写代码.近来OpenStac ...
- html之结构化标记
1.什么是结构化标记 对布局使用的div 进行升级 , 根据页面的不同区域而提供的不同标签.作用与div几乎一致 专门用于搭建网站结构而用 2.结构标记详解 1.<header>元素 作用 ...
- wampserver2.5局域网IP访问配置
wampserver2.5集成环境的安装和使用就不多说了,网上有很多教材.安装好后找到apache的配置文件httpd.conf.默认位置是: swap安装目录\wamp\bin\apache\apa ...
- Mac终端查看sqlite3数据库、表数据等
背景: 我们在用FMDB处理iOS数据库时,沙盒里保存的数据库格式为.sqlite3. 当我们需要在模拟器上调试或查看数据库内容时,我们可以直接在终端里查看到. 正文: 1.在沙盒路径找到需要查看到文 ...
- C++学习(五)入门篇——基本类型
面向对象编程的本质是设计并扩展自己的数据类型,让类型和数据匹配. 内置C++分成两种类型:基本类型和复合类型 1.简单变量 程序需要存储信息时,必须记录三个基本属性 (1)信息将存储在哪 (2)要存储 ...
- 51nod_1417:天堂里的游戏
题目链接: https://www.51nod.com/onlineJudge/questionCode.html#!problemId=1417 假设 ans=n/m,C=(A+B)/2 若出正面 ...