LinkedHashMap相关信息介绍(转)
Java中的LinkedHashMap
此实现与 HashMap 的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。
此链接列表定义了迭代顺序,该迭代顺序通常就是将键插入到映射中的顺序(插入顺序)。
LinkedHashMap和TreeMap的区别
首先2个都是map,所以用key取值肯定是没区别的,区别在于用Iterator遍历的时候
LinkedHashMap保存了记录的插入顺序,先插入的先遍历到
TreeMap默认是按升序排,也可以指定排序的比较器。遍历的时候按升序遍历。
http://blog.csdn.net/scelong/article/details/7187142
一.LinkedHashMap的存储结构

- LinkedHashMap是继承HashMap,也就继承了HashMap的结构,也就是图中的结构2,在下文中我用"Entry数组+next链表"来描述。而LinkedHashMap有其自己的变量header,也就是图中的结构1,下文中我用"header链表"来描述。
- 结构1中的Entry和结构2中的Entry本是同一个,结构1中应该就只有一个header,它指向的是结构2中的e1 e2,但这样会使结构图难画。为了说明问题的方便,我把结构2里的e1 e2在结构1中多画一个。
二.LinkedHashMap成员变量
- // LinkedHashMap维护了一个链表,header是链表头。此链表不同于HashMap里面的那个next链表
- private transient Entry<K, V> header;
- // LRU:Least Recently Used最近最少使用算法
- // accessOrder决定是否使用此算法,accessOrder=true使用
- private final boolean accessOrder;
三.LinkedHashMap里的Entry对象
- // 继承了HashMap.Entry,其他几个方法边用边分析
- rivate static class Entry<K, V> extends HashMap.Entry<K, V> {
- // 增加了两个属性,每个Entry有before Entry和after Entry,就构成了一个链表
- Entry<K, V> before, after;
- Entry(int hash, K key, V value, HashMap.Entry<K, V> next) {
- super(hash, key, value, next);
- }
- private void addBefore(Entry<K, V> existingEntry) {
- .....
- }
- void recordAccess(HashMap<K, V> m) {
- .....
- }
- void recordRemoval(HashMap<K, V> m) {
- .....
- }
- private void remove() {
- .....
- }
四.构造函数
- //默认accessOrder为false
- //调用HashMap构造函数
- public LinkedHashMap() {
- super();
- accessOrder = false;
- }
- //如果想实现LRU算法,参考这个构造函数
- public LinkedHashMap(int initialCapacity, float loadFactor,
- boolean accessOrder) {
- super(initialCapacity, loadFactor);
- this.accessOrder = accessOrder;
- }
- //模板方法模式,HashMap构造函数里面的会调用init()方法
- //初始化的时候map里没有任何Entry,让header.before = header.after = header
- void init() {
- header = new Entry<K, V>(-1, null, null, null);
- header.before = header.after = header;
- }
五.存数据
- //LinkedHashMap没有put(K key, V value)方法,只重写了被put调用的addEntry方法
- //1是HashMap里原有的逻辑,23是LinkedHashMap特有的
- void addEntry(int hash, K key, V value, int bucketIndex) {
- createEntry(hash, key, value, bucketIndex);
- Entry<K, V> eldest = header.after;
- //3.如果有必要,移除LRU里面最老的Entry,否则判断是否该resize
- if (removeEldestEntry(eldest)) {
- removeEntryForKey(eldest.key);
- } else {
- if (size >= threshold)
- resize(2 * table.length);
- }
- }
- void createEntry(int hash, K key, V value, int bucketIndex) {
- //1.同HashMap一样:在Entry数组+next链表结构里面加入Entry
- HashMap.Entry<K, V> old = table[bucketIndex];
- Entry<K, V> e = new Entry<K, V>(hash, key, value, old);
- table[bucketIndex] = e;
- //2.把新Entry也加到header链表结构里面去
- e.addBefore(header);
- size++;
- }
- //默认是false,我们可以重写此方法
- protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
- return false;
- }
- private static class Entry<K, V> extends HashMap.Entry<K, V> {
- //链表插入元素四个步骤,对着图看
- private void addBefore(Entry<K, V> existingEntry) {
- after = existingEntry; //1
- before = existingEntry.before; //2
- before.after = this; //3
- after.before = this; //4
- }
- }
- //如果走到resize,会调用这里重写的transfer
- //HashMap里面的transfer是n * m次运算,LinkedHashtable重写后是n + m次运算
- void transfer(HashMap.Entry[] newTable) {
- int newCapacity = newTable.length;
- //直接遍历header链表,HashMap里面是遍历Entry数组
- for (Entry<K, V> e = header.after; e != header; e = e.after) {
- int index = indexFor(e.hash, newCapacity);
- e.next = newTable[index];
- newTable[index] = e;
- }
- }
下面三个图是初始化LinkedHashMap------->添加Entry e1------>添加Entry e2时,LinkedHashMap结构的变化。



六.取数据
- //重写了get(Object key)方法
- public V get(Object key) {
- //1.调用HashMap的getEntry方法得到e
- Entry<K, V> e = (Entry<K, V>) getEntry(key);
- if (e == null)
- return null;
- //2.LinkedHashMap牛B的地方
- e.recordAccess(this);
- return e.value;
- }
- // 继承了HashMap.Entry
- private static class Entry<K, V> extends HashMap.Entry<K, V> {
- //1.此方法提供了LRU的实现
- //2.通过12两步,把最近使用的当前Entry移到header的before位置,而LinkedHashIterator遍历的方式是从header.after开始遍历,先得到最近使用的Entry
- //3.最近使用是什么意思:accessOrder为true时,get(Object key)方法会导致Entry最近使用;put(K key, V value)/putForNullKey(value)只有是覆盖操作时会导致Entry最近使用。它们都会触发recordAccess方法从而导致Entry最近使用
- //4.总结LinkedHashMap迭代方式:accessOrder=false时,迭代出的数据按插入顺序;accessOrder=true时,迭代出的数据按LRU顺序+插入顺序
- // HashMap迭代方式:横向数组 * 竖向next链表
- void recordAccess(HashMap<K, V> m) {
- LinkedHashMap<K, V> lm = (LinkedHashMap<K, V>) m;
- //如果使用LRU算法
- if (lm.accessOrder) {
- lm.modCount++;
- //1.从header链表里面移除当前Entry
- remove();
- //2.把当前Entry移到header的before位置
- addBefore(lm.header);
- }
- }
- //让当前Entry从header链表消失
- private void remove() {
- before.after = after;
- after.before = before;
- }
- }
七.删数据
- // 继承了HashMap.Entry
- private static class Entry<K, V> extends HashMap.Entry<K, V> {
- //LinkedHashMap没有重写remove(Object key)方法,重写了被remove调用的recordRemoval方法
- //这个方法的设计也和精髓,也是模板方法模式
- //HahsMap remove(Object key)把数据从横向数组 * 竖向next链表里面移除之后(就已经完成工作了,所以HashMap里面recordRemoval是空的实现调用了此方法
- //但在LinkedHashMap里面,还需要移除header链表里面Entry的after和before关系
- void recordRemoval(HashMap<K, V> m) {
- remove();
- }
- //让当前Entry从header链表消失
- private void remove() {
- before.after = after;
- after.before = before;
- }
- }
八.LinkedHashMap EntrySet遍历
- private abstract class LinkedHashIterator<T> implements Iterator<T> {
- //从header.after开始遍历
- Entry<K, V> nextEntry = header.after;
- Entry<K, V> nextEntry() {
- if (modCount != expectedModCount)
- throw new ConcurrentModificationException();
- if (nextEntry == header)
- throw new NoSuchElementException();
- Entry<K, V> e = lastReturned = nextEntry;
- nextEntry = e.after;
- return e;
- }
- }
- 上图中,遍历的结果是先e1然后e2。
- accessOrder为true时,get(e1.key)或者put(e1.key, value)一下,则结构1变成e2------e1------header,遍历的结果就是先e2然后e1。
九.总结
- LinkedHashMap继承HashMap,结构2里数据结构的变化交给HashMap就行了。
- 结构1里数据结构的变化就由LinkedHashMap里重写的方法去实现。
- 简言之:LinkedHashMap比HashMap多维护了一个链表。
http://zy19982004.iteye.com/blog/1663303
LinkedHashMap保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.也可以在构造时用带参数,按照应用次数排序。在遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据较少时,遍历起来可能会比LinkedHashMap慢,因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。
如果需要输出的顺序和输入的相同,那么用LinkedHashMap 可以实现,它还可以按读取顺序来排列.
优点:可前后查询
缺点:效率没有hashmap高
LinkedHashMap是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.也可以在构造时用带参数,按照应用次数排序。
在遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据较少时,遍历起来可能会比LinkedHashMap慢,因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关
LinkedHashMap输出时其元素是有顺序的,而HashMap输出时是随机的,如果Map映射比较复杂而又要求高效率的话,最好使用LinkedHashMap,但是多线程访问的话可能会造成不同步,所以要用Collections.synchronizedMap来包装一下,从而实现同步。其实现一般为:
Map<String String> map = Collections.synchronizedMap(new LinkedHashMap(<String String));
LinkedHashMap和HashMap的区别在于它们的基本数据结构上,看一下LinkedHashMap的基本数据结构,也就是Entry:
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
...
}
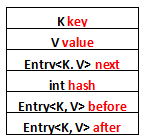
列一下Entry里面有的一些属性吧:
1、K key
2、V value
3、Entry<K, V> next
4、int hash
5、Entry<K, V> before
6、Entry<K, V> after
其中前面四个,也就是红色部分是从HashMap.Entry中继承过来的;后面两个,也就是蓝色部分是LinkedHashMap独有的。不要搞错了next和before、After,next是用于维护HashMap指定table位置上连接的Entry的顺序的,before、After是用于维护Entry插入的先后顺序的。
还是用图表示一下,列一下属性而已:
public LinkedHashMap (int initialCapacity, float loadFactor, boolean accessOrder);
initialCapacity 初始容量
loadFactor 加载因子,一般是 0.75f
accessOrder false 基于插入顺序 true 基于访问顺序(get一个元素后,这个元素被加到最后,使用了LRU 最 近最少被使用的调度算法)
如 boolean accessOrder = true;
Map<String, String> m = new LinkedHashMap<String, String>(20, .80f, accessOrder );
m.put("1", "my"));
m.put("2", "map"));
m.put("3", "test"));
m.get("1");
m.get("2");
Log.d("tag", m);
若 accessOrder == true; 输出 {3=test, 1=my, 2=map}
accessOrder == false; 输出 {1=my, 2=map,3=test}
顾名思义,LRUCache就是基于LRU算法的Cache(缓存),这个类继承自LinkedHashMap,而类中看到没有什么特别的方法,这说明LRUCache实现缓存LRU功能都是源自LinkedHashMap的。LinkedHashMap可以实现LRU算法的缓存基于两点:
1、LinkedList首先它是一个Map,Map是基于K-V的,和缓存一致
2、LinkedList提供了一个boolean值可以让用户指定是否实现LRU
那么,首先我们了解一下什么是LRU:LRU即Least Recently Used,最近最少使用,也就是说,当缓存满了,会优先淘汰那些最近最不常访问的数据。比方说数据a,1天前访问了;数据b,2天前访问了,缓存满了,优先会淘汰数据b。
我们看一下LinkedList带boolean型参数的构造方法:
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
就是这个accessOrder,它表示:
(1)false,所有的Entry按照插入的顺序排列
(2)true,所有的Entry按照访问的顺序排列
第二点的意思就是,如果有1 2 3这3个Entry,那么访问了1,就把1移到尾部去,即2 3 1。每次访问都把访问的那个数据移到双向队列的尾部去,那么每次要淘汰数据的时候,双向队列最尾的那个数据不就是最不常访问的那个数据了吗?换句话说,双向链表最尾的那个数据就是要淘汰的数据。
"访问",这个词有两层意思:
1、根据Key拿到Value,也就是get方法
2、修改Key对应的Value,也就是put方法
http://www.mamicode.com/info-detail-1154295.html
LinkedHashMap相关信息介绍(转)的更多相关文章
- Cordova各个插件使用介绍系列(六)—$cordovaDevice获取设备的相关信息
详情请看:Cordova各个插件使用介绍系列(六)—$cordovaDevice获取设备的相关信息 在项目中需要获取到当前设备,例如手机的ID,联网状态,等,然后这个Cordova里有这个插件可以用, ...
- ManagementClass类解析和C#如何获取硬件的相关信息
在.NET的项目中,有时候需要获取计算机的硬件的相关信息,在C#语言中需要利用ManagementClass这个类来进行相关操作. 现在先来介绍一下ManagementClass类,首先看一下类的继承 ...
- 学习NGUI前的准备NGUI的相关信息
学习NGUI前的准备NGUI的相关信息 第1章 学习NGUI前的准备 NGUI是Unity最重要的插件,在Unity资源商店(Asset Store)的付费排行榜中始终名列前茅,如图1-1所示.本章 ...
- 流媒体相关知识介绍 及其 RTP 应用
一.流媒体简介 随着Internet的日益普及,在网络上传输的数据已经不再局限于文字和图形,而是逐渐向声音和视频等多媒体格式过渡.目前在网络上传输音频/视频(Audio/Video,简称A/V)等多媒 ...
- 使用C语言获取linux系统相关信息
最近在写shell的时候,涉及到了获取环境变量参数和本地计算机相关信息,包括计算机设备名,用户名的信息,在这里简单总结一下.获取环境变量各项参数,可以直接使用getenv函数.man中关于getenv ...
- Spring Security——核心类简介——获得登录用户的相关信息
核心类简介 目录 1.1 Authentication 1.2 SecurityContextHolder 1.3 AuthenticationManager和Authenti ...
- opensslBIO系列之2---BIO结构和BIO相关文件介绍
BIO结构和BIO相关文件介绍 (作者:DragonKing Mail:wzhah@263.net 公布于:http://gdwzh.126.com openssl专业论坛) ...
- Linux系统CPU相关信息查询
Linux系统CPU相关信息查询 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.lscpu常用参数介绍 1>.查看帮助信息 [root@node105 ~]# lscpu ...
- 编程实战——电影管理器之利用MediaInfo获取高清视频文件的相关信息
随着高速(20M)宽带.HTPC.大容量硬盘(3T)的普及,下载高清片并利用大屏幕观看也成为普通的事情. 随着下载影片的增多,管理就有了问题,有时在茫茫文件夹下找寻一个影片也是一件费时费力的事. 于是 ...
随机推荐
- MinGW开发工具的安装
MinGW是Minimalist GNU for Windows的缩写,是把linux下的GNU开发工具包移植到windows的项目之一.和Cygwin不一样的是,MinGW不提供linux的posi ...
- 用定时器T0查询方式P0口8位控制LED闪烁
#include<reg52.h> #define uchar unsigned char #define uint unsigned int void main (void) { uch ...
- 当JAVA集合移除自身集合元素时发生的诸多问题
一段代码目的是想删除集合中包括"a"字符串的集合项: public class TestForeach { public static void main(String[] arg ...
- DateTime.ParseExact
今天一个项目到我的机器上后,一句代码:DateTime.Parse("02/10/2014")一直报错,invaild datetime string,猜测是系统时间问题,但是将系 ...
- input标签的hidden属性的应用及作用
定义:传输关于客户端/服务器交互的状态信息. Transmits state information about client/server interaction. 解释: 此元素在页面中不显示,在 ...
- VC 无标题栏对话框移动
操作系统:Windows 7软件环境:Visual C++ 2008 SP1本次目的:实现无框移动 所谓的无标题栏对话框,是基于对话框的工程,对话框属性Border设置为None,对话框如下所示: 为 ...
- Hadoop: the definitive guide 第三版 拾遗 第十三章 之HBase起步
指南上这一章的开篇即提出:HBase是一个分布式的.面向列的开源数据库.如果需要实时的随机读/写超大规模数据集,HBase无疑是一个好的选择. 简介 HBase 是一个高可靠性.高性能.面向列.可伸缩 ...
- HDU 5046 Airport(DLX反复覆盖)
HDU 5046 Airport 题目链接 题意:给定一些机场.要求选出K个机场,使得其它机场到其它机场的最大值最小 思路:二分+DLX反复覆盖去推断就可以 代码: #include <cstd ...
- java运行脚本语言demo
public class Test { /** * @param args * @throws IOException */ public static void main(String[] arg ...
- 用Delphi进行word开发
使用以CreateOleObjects方式调用Word 实际上还是Ole,但是这种方式能够真正做到完全控制Word文件,能够使用Word的所有属性,包括自己编写的VBA宏代码.------------ ...