5天2亿活跃用户,QQ“LBS+AR”天降红包活动后台揭密
作者:Dovejbwang,腾讯后台开发工程师,参与“LBS+AR”天降红包项目,其所在“2016春节红包联合项目团队”获得2016公司级业务突破奖。
商业转载请联系腾讯WeTest获得授权,非商业转载请注明出处。
WeTest 导读
上一期为您解密了8亿月活的QQ后台服务接口隔离技术《QQ18年,解密8亿月活的QQ后台服务接口隔离技术》,那你是否好奇春节期间全网渗透率高达52.9%的ARQQ红包后台是怎样的一番光景呢?本文为您揭晓。
前言
刚刚过去不久的QQ“LBS+AR”天降红包玩法在5天内达成了2.57亿用户参与、共计领取卡券和现金红包20.5亿次的成绩,得到用户的一致好评,赢得口碑、数据双丰收。

作为一个全新的项目,后台面临着许多挑战,比如:
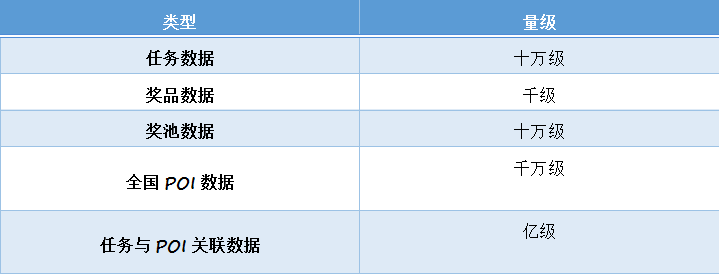
1. 海量地图活动数据管理
在全国960万平方公里土地上投放上亿的活动任务点,如何管理海量的的地图/任务数据?
2. 地图查点方案
如何根据用户地理位置快速获取附近可用的任务点?
3. 数千个行政区红包余量的实时统计
红包雨活动是在区级行政区开展的,全国有数千个区级行政区,每个行政区都有数十个不同的红包任务及奖品,实时返回数千个地区的红包剩余量是如何做到的?
本文将从总体上介绍LBS+AR红包后台系统架构,并逐步解答上述几个问题。
LBS+AR后台架构鸟瞰

1. 投放系统:活动、商户、奖品等信息的可视化配置页面
2. 静态数据层:CDB提供的MySQL服务,包含多个配置表
3. 配置同步系统:负责构建海量活动数据的缓存及同步,包含2个模块
a) 缓存构建模块:定期轮询式地从CDB中读取活动数据,如果数据发生变化,重新构建AR标准缓存格式的共享内存数据
b) 配置同步服务端:负责接收客户端请求,将共享内存数据下发到各个业务机器
4. 逻辑层:负责接受客户端请求,包含2个系统
a) 主逻辑:负责用户参加地图红包的核心逻辑,包含地图查点、抽奖等流程
b) 采集系统:负责实时获取各个活动及奖品的发放数据,用于主逻辑获取活动状态、客户端显示剩余计数、后台统计活动数据
5. 动态数据层:负责用户、活动动态数据的存储,包含4类数据
a) 发奖计数器:每个任务/奖品发放量
b) 用户历史记录:用户中奖的信息
c) 冷却与限额:用户领取的每种奖品的限制信息
d) 叠放计数器:可重复获取的奖品数量(本次活动是皇室战争卡券数)
6. 辅助模块:完成单个特定任务的模块
a) 频率控制:负责控制奖品发放速度
b) 订单:负责管理财付通现金订单
c) 一致接口:负责一致性路由,将同一个用户的请求路由到同一台机器的指定进程
7. 发奖相关系统:负责奖品发放的外部系统
LBS+AR后台系统探微
下面主要为大家介绍海量配置管理、地图打点查点和实时的余量采集系统。
一、海量配置数据管理
LBS+AR红包与以往的红包最大的不同在于多了一重地理位置关联,全国有上千万的地理位置信息,结合活动的任务奖品数据产生了海量的配置数据,而这些数据都需要快速地实时读取(详细数据结构见后文)。这是后台遇到的第一个挑战。
总体思路
配置数据有如下特点:
1. 数据量可能很大,数据间有紧密的关联
2. “一次配好,到处使用”,读量远高于写量
根据第一个特性,由于我们有Web投放系统的可视化配置能力,而公司内部的CDB能提供可靠的MySQL服务,有自动容灾和备份的功能,故选择CDB作为静态数据存储。
根据第二个特性,我们需要开发一种缓存,放弃写性能,将读性能优化到极致。
第一代缓存系统——写性能换读性能

缓存系统将数据读取方式从“远端磁盘读取”改为“本地内存读取”,读性能提高好几个数量级,它具有如下特点:
1. 缓存构建模块定时轮询数据库,在共享内存中构建缓存,配置变动可在分钟级时间内完成
2. 每张表使用2块共享内存,一块用于实时读,另一块用于更新,数据更新无感知,对业务零影响
3. 使用二分法查询数据,O(logN)的复杂度,性能较优
第二代缓存系统——O(logN)算法部分变O(1)
由于在地图查点流程中要执行数十至上百次的“任务与POI关联数据”查询,而对亿级数据进行二分查找每次要做将近30次的字符串比较,严重影响了系统性能。
为了解决这个问题,第二代系统针对POI数据离散化的特点,对量大的数据进行了前缀哈希,将一半的O(logN)操作转换成O(1),进一步用写性能换读性能,性能得到有效提升,字符串比较的最大次数减少了将近一半。
算法流程:
1. 根据经验设置前缀长度
2. 遍历数据构造映射表,映射表存储了前缀及其对应的起始/末尾序号
3. 以前缀为Key,将映射表记在多阶哈希中(指定大小,枚举阶数搜索可行的压缩方案)
下面是一个构造映射表的例子:
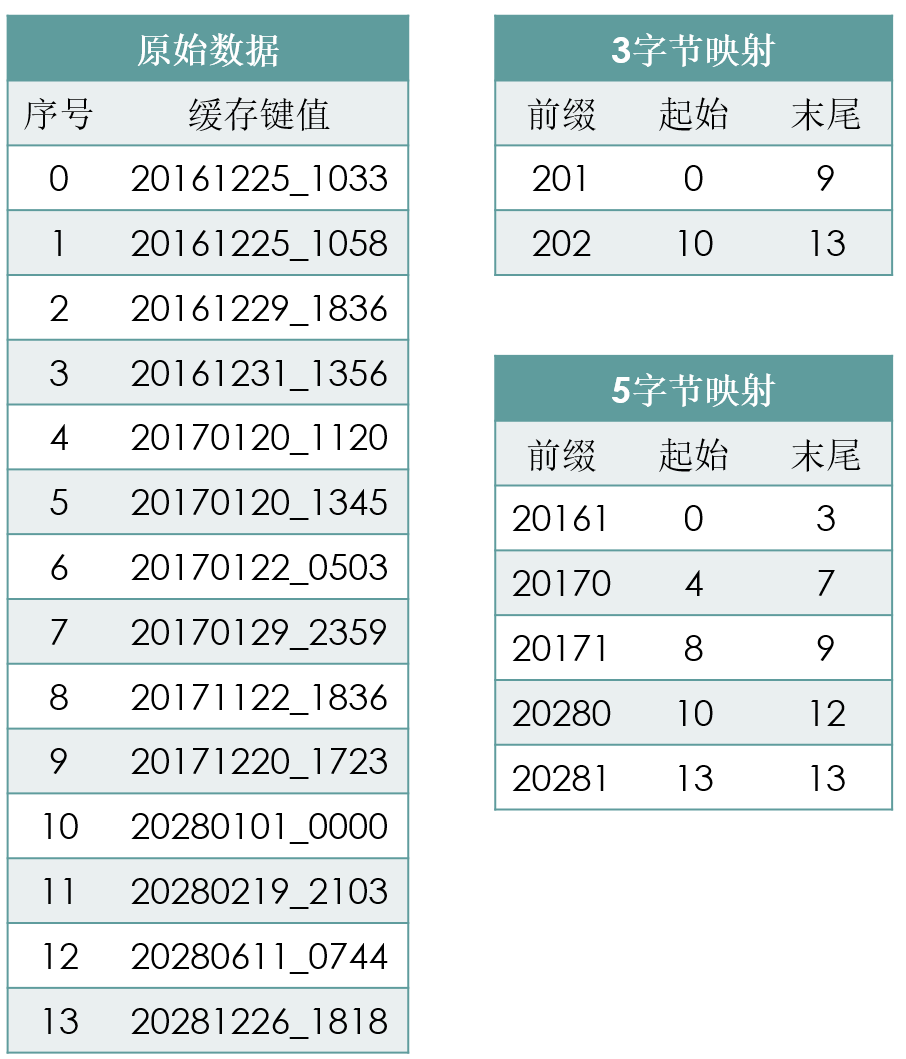
对于样例数据
● 如果取3字节前缀,只有2个结果,产生的映射表比较容易构造哈希,但最大单条映射的记录长度是9,二分的次数仍然较多。
● 如果取5字节前缀,最大单条映射的记录长度是4,二分次数较少,但条目较多,哈希构造较难。
总结如下

一些可能的问题:
● 为什么不全部哈希呢?
上亿条数据每次改动都做全部哈希,耗费的时间和空间恐怕是天文数字。虽然我们舍弃写性能换取读性能,但用几个小时(几天)写耗时换几纳秒的读耗时,边际效用已经降到负数了。实践中做一半即可达到不错的读写平衡。
● 如果映射的记录长度十分不均匀怎么办?
这是此项优化的命门所在。幸运的是我们要优化的数据是POI相关的,而实践发现POI数据离散性极好,得出的映射记录数量非常均匀
● 如果哈希一直构造失败怎么办?
此项配置数据改动不多,如果对于某一版本数据构造失败,一般会有足够的时间根据数据特性调整前缀长度、增加哈希表大小、扩大阶数搜索范围来确保成功。如果时间比较紧急,也可以放弃此项优化,程序如果检测到哈希失败,会自动使用全部二分的方式读取。即便没有这项优化,我们还有许多柔性调控策略防止系统过载。
第三代缓存系统——中间层加速同步
上一代系统扩容后的结构如下图:
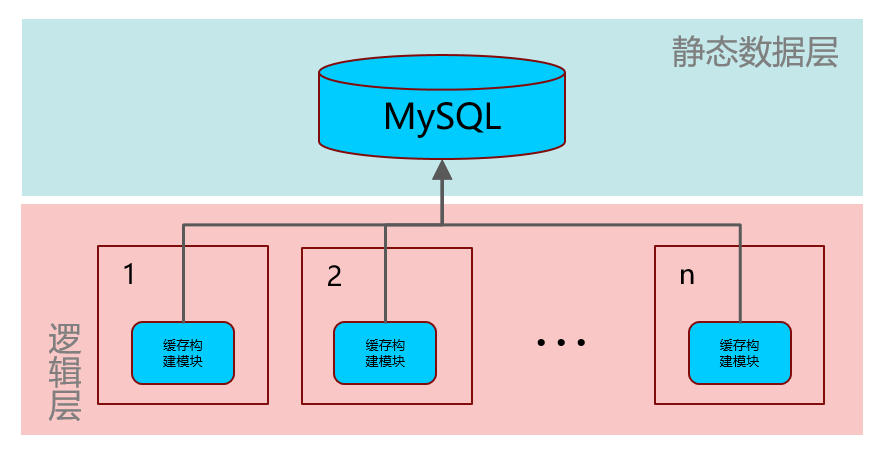
每台机器构建数据时都要去数据库读一次全量数据并排序,同时要在本地生成,每次大约耗时5分钟。而在这种架构下,所有机器的读数据库操作实际上就是串行的,当逻辑层扩容到100台机器时,完成全部任务将耗费好几个小时,考虑到配置修改的风险,这种架构在实践上是不可行的。
第三代架构图如下(箭头指数据流向):

在数据层和逻辑层中间添加一个配置同步系统,先让少部分配置中心机器优先完成构建,再去带动数量较多的逻辑层机器,最终达到共同完成。有效解决了上一代平行扩容的问题,效果拔群。
实践效果
1. 极致读性能
2. 海量静态缓存数据的快速构建:完成全部机器近20G不同类型静态数据的构建和同步只需要30分钟
3. 数据同步无感知,实现无缝切换,对业务零影响
二、地图打点与查点
基于LBS的活动离不开地理位置相关的业务交互。在本次活动中,用户打开地图会定期向后台上报坐标,后台需要根据坐标获取周围可用的活动任务点,此节介绍打点与查点相关内容。
专业的地图服务会使用一种树形数据结构来进行空间查询,但LBS+AR红包活动的场景比较简单,故而选用了一种粒度较粗性能更好的打点查点方案,查询附近地理信息只需要进行四则运算,再一次用O(1)的方法解决O(logN)的问题。
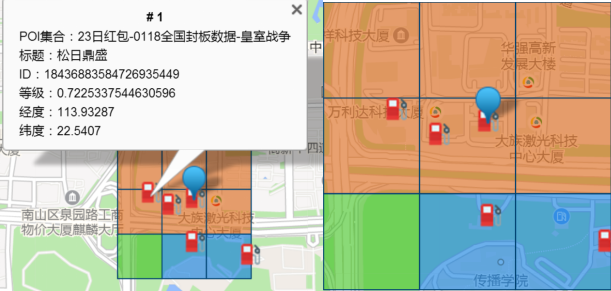
地图格子方法介绍
将整个二位平面根据坐标分成一个个边长相等的正方形格子,根据用户的坐标用简单的数学运算即可获取相应的格子ID,时间复杂度O(1)。一个格子是一次查询的最小粒度。
在本次活动中,我们使用约200米边长的格子,每次查询会返回以用户为中心周围共计25个格子的任务点。
格子与任务点示例如下:
打点流程介绍
活动的投放是以任务的维度投放,每个任务关联一个POI集合,每个POI集合中包含几个到上百万不等的POI点,每个POI点都有一个经纬度信息(详细情况见下文数据结构设计)。
打点的责任是将任务为索引的数据重构为以格子ID为索引的数据,通过遍历缓存系统中的POI/POI集合/任务分片来实现。最终的格式如下:
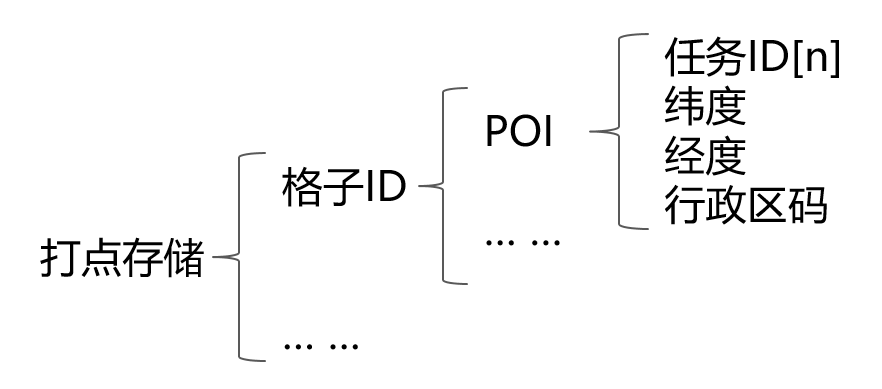
查点流程介绍
1. 客户端上报经纬度
2. 根据经纬度计算中心格子ID
3. 根据中心格子ID及半径配置,获取全部格子列表
4. 在打点系统中获得此片区域全部Poi和Task信息
5. 检查任务状态后返回给客户端
三、采集系统进化之路
采集系统的主要职责是:
1. 实时返回区级行政区红包计数
2. 实时接受主逻辑的查询,返回奖品发放状态。
3. 返回活动预告以及参数配置等辅助信息。
这里面临的主要的挑战是区级行政区的红包余量计数,本文将着重介绍余量计数方案的演化思路。
朴素方案
来一个请求就去读一次!
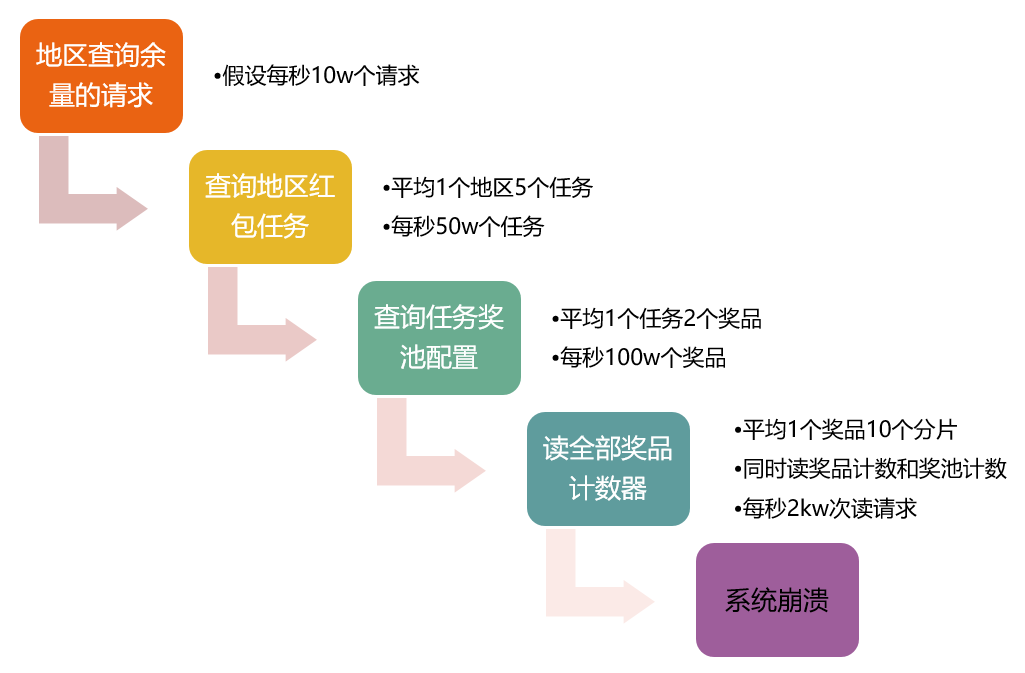
进程级缓存方案
上一个方案显然不可行,而进程级缓存是最初使用的方案。这时采集功能并未单独成为一个独立模块,而是嵌在主逻辑里的。
主逻辑定期地扫描配置中全部有效任务,读计数器,将计数存储在STLMAP中。

假如每次数据缓存5秒,实际活动中约有8w条数据需要处理,每天活动分8场,100台逻辑层机器,对数据层的压力是400w次每秒,这个级别的读量几乎占满了全部Grocery性能。虽然方案比较成熟,但还是决定优化。
机器级缓存方案
这个方案做了两件事:
1. 将进程级的缓存上升到机器级,节省40倍进程访问开销
2. 将采集流程从主逻辑解耦,单独部署,减轻100台主逻辑机器绑定的访问开销

本方案使用有序的拼接索引+范围二分查找的方式替代STLMAP进行查询,使用sf1框架实现,服务与构造进程一体。由于sf1不支持并发外部调用,构造进程使用简单逐个查询的方法处理。
(sf1是后台较为常用的一种服务框架,性能较好,但不支持天然异步开发)
夹缝求生的最终优化
上一方案功能上确实可行,但性能上仍然存在问题:sf1框架不好做并发外部调用,用串行的方式查询数万条数据,完成一轮更新的时间是分钟级的,影响产品体验。
为了优化此问题,我们做了两级并发:
1. 利用Grocery提供的MultiKeyBatch方法,让Grocery接口机并发(详情请参见Grocery API,调用此接口格外注意业务数据大小及打包数量,轻易不要使用!)。示意图如下:
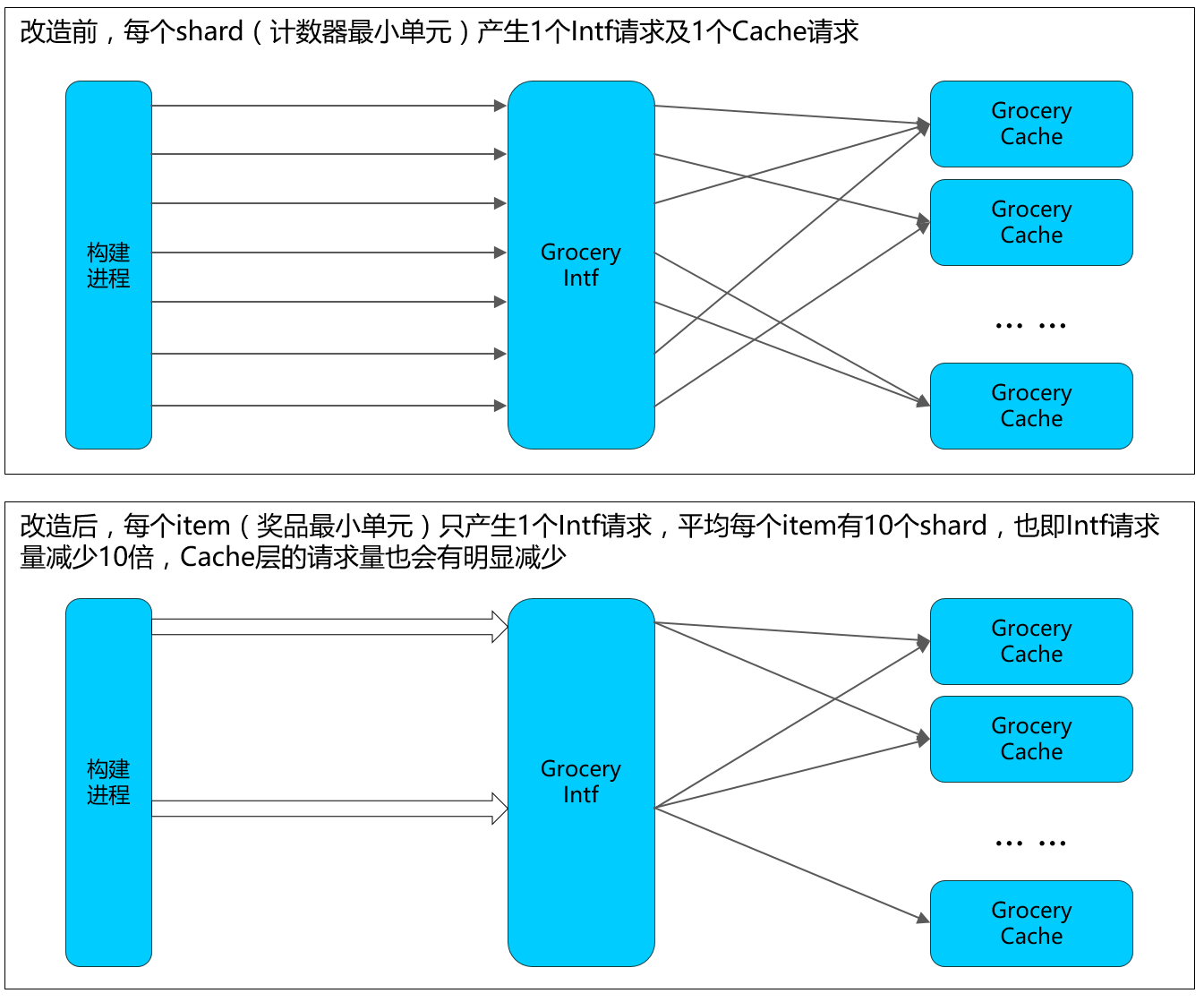
2. 将构造进程从sf1改为spp,利用mt_task方法并发请求。我们使用了宏定义IMTTask的简便用法。
需要注意的是,理论上可以只用第二种并发方式即可满足“采集模块”的需求,但从整个系统的角度看,防止数据层过载更加重要,第一种并发方式减少了10倍Grocery Intf请求量和一部分Cache请求量,虽然开发量较大,却是不可或缺的。
经过两级并发,分钟级的构建间隔被缩短到了1秒。但是不能发布!因为遇到了夹缝问题。
采集模块夹在客户端和Grocery之间,加速采集会影响Grocery,而减少机器又会影响客户端更新计数的效果,三个条件互相制约,需要想办法突破这个夹缝难题。
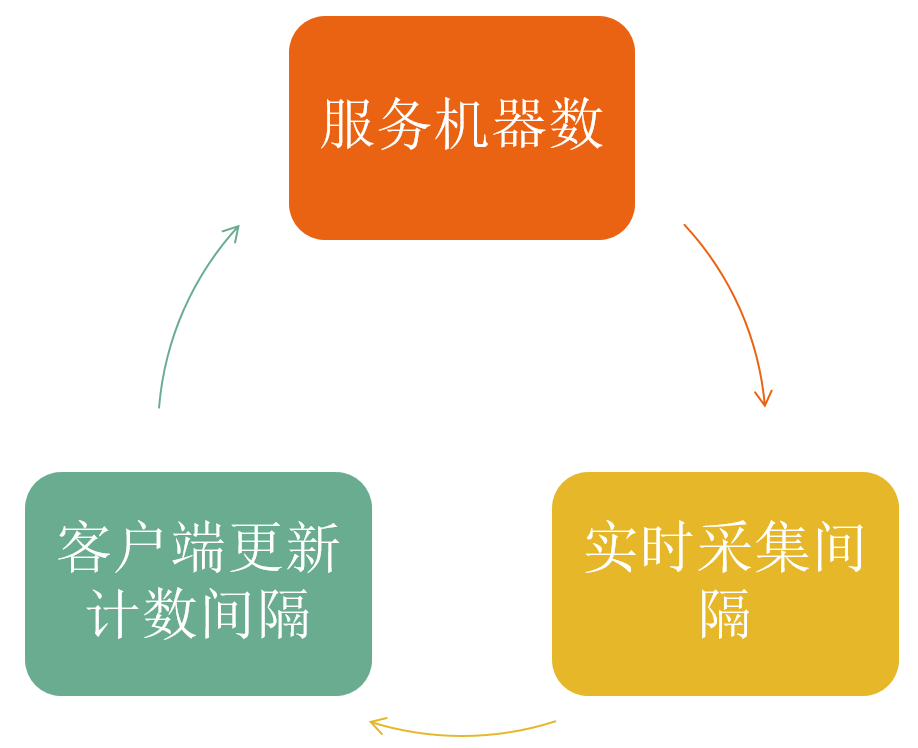
解决方法是:将查余量过程的O(logN)流程变成O(1),性能提升10倍即可。
采集系统的主要业务逻辑是返回地区红包计数,之前的方案1秒内的数万次请求每次都会执行包括二分查找在内的全套逻辑,而事实上只有第一次是有必要的(地区的余量等信息1秒内的变化微乎其微)。那么答案就呼之欲出了,只需要给每个地区的结果做1秒钟的缓存即可。
最终把可以做缓存的流程全都加上了合理的缓存结构,单机性能成功提升10倍。
后记
本次项目总结的后台开发基本法:
1. 架构问题可以通过读写转换、时空转换的方式变成算法问题
2. O(logN)问题总有办法变成O(1)问题
3. 没人能预知未来。开发海量数据/海量请求的系统时,多用上面两个方法,从一开始就要尽力做到最好。
另外不能忘了,在海量用户来袭的前夕,对自己的产品承载能力进行一个测试,及时做好调整和优化。任何企业都是一样,不要万事俱备,却忽略了这个环节,让用户乘兴而来,败兴而归···
腾讯提供了一个可以自主进行服务器性能测试的环境,用户只需要填写域名和简单的几个参数就可以获知自己的服务器性能情况,目前在腾讯WeTest平台可以免费使用。
腾讯WeTest服务器性能测试运用了沉淀十多年的内部实践经验总结,通过基于真实业务场景和用户行为进行压力测试,帮助游戏开发者发现服务器端的性能瓶颈,进行针对性的性能调优,降低服务器采购和维护成本,提高用户留存和转化率。
功能目前免费对外开放中,点击链接:http://WeTest.qq.com/gaps可立即体验!
如果对使用当中有任何疑问,欢迎联系腾讯WeTest企业qq:800024531
关注“腾讯WeTest”公众号,获取更多干货。
5天2亿活跃用户,QQ“LBS+AR”天降红包活动后台揭密的更多相关文章
- 支撑5亿用户、1.5亿活跃用户的Twitter最新架构详解及相关实现
如果你对项目管理.系统架构有兴趣,请加微信订阅号"softjg",加入这个PM.架构师的大家庭 摘要:Twitter出道之初只是个奋斗在RoR上的小站点,而如今已拥有1.5亿的活跃 ...
- 转帖 支撑4.5亿活跃用户的WhatsApp架构概览
http://www.csdn.net/article/2014-02-27/2818559-an-overview-at-whatsapp's-19b-architecture/2 写的很好,确实牛 ...
- 通向高可扩展性之路(推特篇) ---- 一个推特用来支撑1亿5千万活跃用户、30万QPS、22MB每秒Firehose、以及5秒内推送信息的架构
原文链接:http://highscalability.com/blog/2013/7/8/the-architecture-twitter-uses-to-deal-with-150m-active ...
- 亿级用户下的新浪微博平台架构 前端机(提供 API 接口服务),队列机(处理上行业务逻辑,主要是数据写入),存储(mc、mysql、mcq、redis 、HBase等)
https://mp.weixin.qq.com/s/f319mm6QsetwxntvSXpKxg 亿级用户下的新浪微博平台架构 炼数成金前沿推荐 2014-12-04 序言 新浪微博在2014年3月 ...
- 05 redis中的Setbit位图法统计活跃用户
一:场景=>>>长轮询Ajax,在线聊天时,能够用到 Setbit 的实际应用 场景: 1亿个用户, 每个用户 登陆/做任意操作 ,记为 今天活跃,否则记为不活跃 每周评出: 有奖活 ...
- Redis-统计活跃用户
Bitmap(即Bitset)Bitmap是一串连续的2进制数字(0或1),每一位所在的位置为偏移(offset),在bitmap上可执行AND,OR,XOR以及其它位操作. package test ...
- 用Redis bitmap统计活跃用户、留存
Spool的开发者博客,描述了Spool利用Redis的bitmaps相关的操作,进行网站活跃用户统计工作. 原文:http://blog.getspool.com/2011/11/29/fast-e ...
- QQ会员2018春节红包抵扣券项目背后的故事
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 1. 活动数据 截止3月1日手Q运动红包会员礼包发放核销数据 参与红包活动用户数:2亿+ 发券峰值:52w/min 2. 需求背景 2.1 ...
- 日请求亿级的 QQ 会员 AMS 平台 PHP7 升级实践
QQ会员活动运营平台(AMS),是QQ会员增值运营业务的重要载体之一,承担海量活动运营的Web系统.AMS是一个主要采用PHP语言实现的活动运营平台, CGI日请求3亿左右,高峰期达到8亿.然而,在之 ...
随机推荐
- 11、手把手教你Extjs5(十一)模块界面的总体设计
上一节中设计了一些模块自定义中用到的要素,为了直观起见,这一节先建立一个模块的主界面.看过我 模块管理常规功能自定义系统的设计与实现 博客的人应该会有所了解了.一个模块的主界面是一个Grid,在其上方 ...
- linux分区-df
转自:http://baike.baidu.com/link?url=tyonI3NCB3F-ytIQz72PY-8uAaUQgfFFXbyKAea1e2NiB_t5AsE0MLOLc2LcqOiS ...
- 在IOS应用中从竖屏模式强制转换为横屏模式
http://www.cnblogs.com/mrhgw/archive/2012/07/18/2597218.html 在 iPhone 应用里,有时我们想强行把显示模式从纵屏改为横屏(反之亦然), ...
- PHPCMS快速建站系列之搜索功能
默认模板的搜索功能代码 <div class="bd"> <form action="{APP_PATH}index.php" method= ...
- 分布式数据库Google Spanner原理分析
Spanner 是Google的全球级的分布式数据库 (Globally-Distributed Database) .Spanner的扩展性达到了令人咋舌的全球级,可以扩展到数百万的机器,数已百计的 ...
- OpenGL ES
前言 OpenGL ES是Khronos Group创建的一系列API中的一种(官方组织是:http://www.khronos.org/).在桌面计算机上有两套标准的 3DAPI:Direct3D和 ...
- Object修改链表
以前学习过链表的时候由于类型的接收不同,每次要重写链表 下面修改可用链表 class Link{ private class Node{ private Object data ; private N ...
- 把div 当文字来进行布局控制
两边对齐 text-align: justify; text-justify: distribute-all-lines;/*ie6-8*/ text-align-last: justify;/* i ...
- JDK8新特性面试
java8:http://ifeve.com/java-8-features-tutorial/ 一.Lambda表达式和函数式接口 Lambda表达式(也叫做闭包) 它允许我们将一个函数当作方法的参 ...
- iOS 编程小知识 之 本地化
1. 使用本地化多语言 有时候,在网上下载的Demo,有本地化的处理,默认的本地化都是英文,这时候,可以考虑这么处理: info.plist->Infomation Property List ...