Kafka connect快速构建数据ETL通道
摘要: 作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处
业余时间调研了一下Kafka connect的配置和使用,记录一些自己的理解和心得,欢迎指正.
一.背景介绍
Kafka connect是Confluent公司(当时开发出Apache Kafka的核心团队成员出来创立的新公司)开发的confluent platform的核心功能.
大家都知道现在数据的ETL过程经常会选择kafka作为消息中间件应用在离线和实时的使用场景中,而kafka的数据上游和下游一直没有一个
无缝衔接的pipeline来实现统一,比如会选择flume或者logstash采集数据到kafka,然后kafka又通过其他方式pull或者push数据到目标存储.
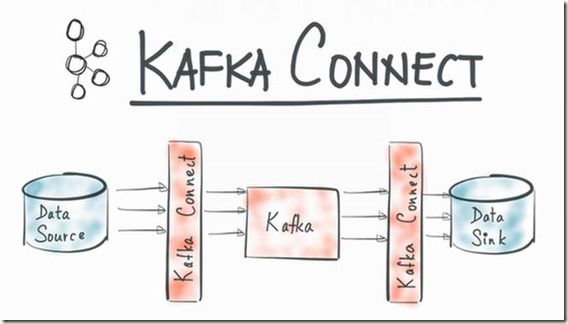
而kafka connect旨在围绕kafka构建一个可伸缩的,可靠的数据流通道,通过kafka connect可以快速实现大量数据进出kafka从而和其
他源数据源或者目标数据源进行交互构造一个低延迟的数据pipeline.给个图更直观点,大家感受下.
二.Kafka-connect快速配置
这里Confluent官方很贴心的提供了一个集成的镜像以便quickstart,如下链接
https://s3-us-west-2.amazonaws.com/confluent-files/kafka_connect_blog.ova
这是存储在Amazon S3上的,直接点击即可下载.这里我使用VMWare直接打开,刚开始会提示一个错误,不用管它直接点击重试即可
系统加载的过程中会默认初始化虚拟机的网络配置,这里我建议提前设置好桥接网络,让该虚拟机使用桥接网络初始化.
加载成功后,登录进入该Ubuntu系统,默认的用户名和密码都是:vagrant.
然后ls查看vagrant用户目录,查看几个关键的脚本内容后,我分别介绍它们的功能
1>setup.sh:自动下载mysql,mysql jdbc driver,配置好mysql以及做为hive的metastore
2>start.sh:启动confluent platform,kafka,hadoop,hive相关服务
3>clean_up.sh:和start.sh相反的,会关闭掉所有的服务,而且还会删除掉所有的数据(例如hdfs namenode和 datanode的数据,其实相当于fs format了)
那么很明显,第一步肯定是执行setup.sh,这里执行后会报错如下
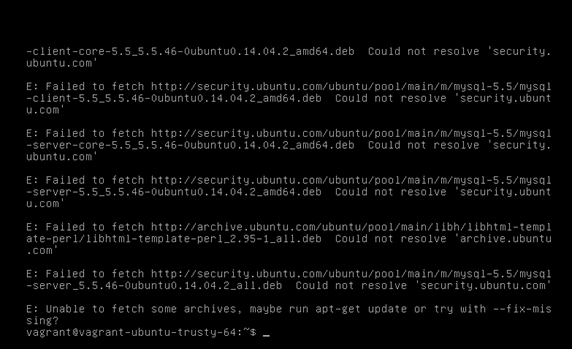
这里无法下载相关的软件包,好吧,那么我们需要更新一下下载源的索引,执行如下命令
sudo apt-get update
更新完毕后再次执行setup.sh安装好mysql,hive等服务
紧接着执行start.sh来启动上述服务,启动后应该有如下进程,这是一个伪分布式节点
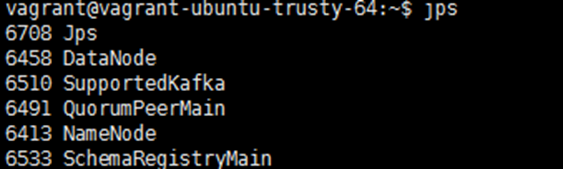
对了,虚拟机各个服务(例如hive,zookeeper等),配置文件和日志文件在路径/mnt/下,组件的安装位置位于/opt下
三.Kafka connect快速使用
配置完以后就可以准备使用kafka-connect来快速构建一个数据pipeline了,如下图所示
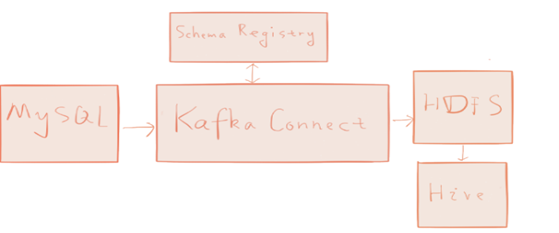
整个过程是将数据以mysql作为数据源,将数据通过kafka connect快速ETL到hive中去.注意这里图中没画kafka
但是实际上是包含在kafka connect里面的,话不多说,开始使用
1>Mysql数据准备
执行如下命令
$ mysql -u root --password="mypassword"
mysql> CREATE DATABASE demo;
mysql> USE demo;
mysql> CREATE TABLE users (
-> id serial NOT NULL PRIMARY KEY,
-> name varchar(100),
-> email varchar(200),
-> department varchar(200),
-> modified timestamp default CURRENT_TIMESTAMP NOT NULL,
-> INDEX `modified_index` (`modified`)
-> );
mysql> INSERT INTO users (name, email, department) VALUES ('alice', 'alice@abc.com', 'engineering');
mysql> INSERT INTO users (name, email, department) VALUES ('bob', 'bob@abc.com', 'sales');
mysql> exit;
注意上面第一行,--password="mypassword" ,对,你没看错,这里虚拟机mysql的root默认密码就是mypassword,
强迫症患者请自行更改.随后建库,建表,插入数据.
2>关键概念准备
这里我快速普及一下参考官方文档理解的一些关键概念.
kafka connector:kafka connector是kafka connect的关键组成部分,它是一个逻辑上的job,用于在kafka和其他系统之间拷贝数据,比如
从上游系统拷贝数据到kafka,或者从kafka拷贝数据到下游系统
Tasks:每个kafka connector可以初始化一组task进行数据的拷贝
Workers:逻辑上包含kafka connector和tasks用来调度执行具体任务的进程,具体执行时分为standalone模式和distributed模式
见下图,这个是kafka上游的数据stream过来后,定义好对应的kafka connector后,分解为一组tasks然后push数据到kafka的不同topic

3>利用Kafka-connect摄取数据
主要是通过配置来实现从mysql摄取数据到kafka,然后按照topic来获取数据写入hdfs,命令如下
connect-standalone /mnt/etc/connect-avro-standalone.properties \
/mnt/etc/mysql.properties /mnt/etc/hdfs.properties &
注意上面这些properties文件是虚拟机已经事先配置好的,可以直接执行实现数据的摄取
当前使用的kafka connect的standalone模式,当然还有distributed模式后续可以尝试
上面的那条命令的格式是这样:
connect-standalone worker.properties connector1.properties [connector2.properties connector3.properties ...]
主要解释一下connect-standalone后面的参数
worker.properties:就是上面提到过的worker进程的配置文件,可以定义kafka cluster的相关信息以及数据序列化的格式.
随后的一些参数就是kafka connector的配置参数了,比如上面的mysql.properties定义了一个kafka jdbc connector,用来同步mysql数据到kafka
最后一个hdfs.properties是kafka hdfs connector的配置文件,用来消费kafka topic数据push到hdfs.
那么执行这条命令后就可以将mysql的数据通过kafka connect快速ETL到hdfs了.
最后可以通过hive创建外表映射hdfs上的数据文件,然后在hive中查看对应数据,如下
$ hive
hive> SHOW TABLES;
OK
test_jdbc_users
hive> SELECT * FROM test_jdbc_users;
OK
1 alice alice@abc.com engineering 1450305345000
2 bob bob@abc.com sales 1450305346000
四.Kafka connect使用总结
1>Kafka connect的使用其实就是配置不同的kafka connectors,这里大家可以把kafka作为中间组件,然后可以类比flume理解,kafka上游的
connector其实就是fllume的source从上游数据源sink到kafka,kafka的下游connector其实就是flume的source是kafka,sink到下游系统.
2>Kafka connect的数据pipeline要打通,它要求数据遵守confluent自己的一套通用的schema机制,细心的同学会发现上面jps后会有个进程名
SchemaRegistryMain,这里官方默认使用Avro格式进出Kafka,所以要留意worker.properties文件的配置信息.
3>我在使用中没有发现Flume 相关的connector,因此很好奇它应该是没有实现上游flume conector的属性配置。问题应该出在Flume的数据是基
于event的,而和上面2中所说的schema定义格式没有很好的兼容.
4>kafka connect的distributed模式应该更实用,随后会尝试,以及confluent所支持的实时处理流kafka streams.
参考资料:http://docs.confluent.io/2.0.0/platform.html
Kafka connect快速构建数据ETL通道的更多相关文章
- 以Kafka Connect作为实时数据集成平台的基础架构有什么优势?
Kafka Connect是一种用于在Kafka和其他系统之间可扩展的.可靠的流式传输数据的工具,可以更快捷和简单地将大量数据集合移入和移出Kafka的连接器.Kafka Connect为DataPi ...
- 使用kafka connect,将数据批量写到hdfs完整过程
版权声明:本文为博主原创文章,未经博主允许不得转载 本文是基于hadoop 2.7.1,以及kafka 0.11.0.0.kafka-connect是以单节点模式运行,即standalone. 首先, ...
- SQL Server CDC配合Kafka Connect监听数据变化
写在前面 好久没更新Blog了,从CRUD Boy转型大数据开发,拉宽了不少的知识面,从今年年初开始筹备.组建.招兵买马,到现在稳定开搞中,期间踏过无数的火坑,也许除了这篇还很写上三四篇. 进入主题, ...
- 打造实时数据集成平台——DataPipeline基于Kafka Connect的应用实践
导读:传统ETL方案让企业难以承受数据集成之重,基于Kafka Connect构建的新型实时数据集成平台被寄予厚望. 在4月21日的Kafka Beijing Meetup第四场活动上,DataPip ...
- Apache Kafka Connect - 2019完整指南
今天,我们将讨论Apache Kafka Connect.此Kafka Connect文章包含有关Kafka Connector类型的信息,Kafka Connect的功能和限制.此外,我们将了解Ka ...
- Kafka Connect Architecture
Kafka Connect's goal of copying data between systems has been tackled by a variety of frameworks, ma ...
- 基于Kafka Connect框架DataPipeline在实时数据集成上做了哪些提升?
在不断满足当前企业客户数据集成需求的同时,DataPipeline也基于Kafka Connect 框架做了很多非常重要的提升. 1. 系统架构层面. DataPipeline引入DataPipeli ...
- Kafka笔记7(构建数据管道)
构建数据管道需要考虑的问题: 及时性 可靠性 高吞吐量和动态吞吐量 数据格式 转换 安全性 故障处理能力 耦合性与灵活性 数据管道的构建分为2个阵营,ETL和ELT ETL:提取- ...
- 使用Asp.net WebAPI 快速构建后台数据接口
现在的互联网应用,无论是web应用,还是移动APP,基本都需要实现非常多的数据访问接口.其实对一些轻应用来说Asp.net WebAPI是一个很快捷简单并且易于维护的后台数据接口框架.下面我们来快速构 ...
随机推荐
- struts2 <s: select 标签值
JSP页面: <s:select label="家长导航" value="id" name="navson.pid" list=&q ...
- Wookmark-jQuery-master 瀑布流插件
Wookmark-jQuery-master 瀑布流插件使用介绍,含个人测试DEMO 要求 必备知识 本文要求基本了解 Html/CSS, JavaScript/JQuery. 开发环境 Dream ...
- IOS UI 第十一篇: UITABLEVIEW
DIY a tableviewcell : - (id)initWithStyle:(UITableViewCellStyle)style reuseIdentifier:(NSString *) ...
- SZU:A12 Jumping up and down
Judge Info Memory Limit: 32768KB Case Time Limit: 10000MS Time Limit: 10000MS Judger: Number Only Ju ...
- centos安装及配置
centos安装 从网上下载最新的版本,用ultraiso做好系统盘,启动.安装过程没有什么可以说的,与其他发行版有点不同的是需要将安装包放到u盘根目录下(u盘容量最好大点,8~16G最好).开始没注 ...
- SQL Server的数据加密简介
防止开发人员获取到敏感数据(SQL Server的数据加密简介) 背景 有时候,我们还真的会碰到这样的需求:防止开发人员获取到敏感数据.也许你觉得很简单,把开发和运营分开不就可以了吗?是的,如果公司有 ...
- Orchard学习计划
http://esshs.cnblogs.com/ http://orchardproject.net/http://www.orchardch.com/Documenthttps://orchard ...
- 在html中使用javascript显示本地图片的
<html> <head> <script type="text/javascript"> function getFullPath(obj){ ...
- 编程实战——电影管理器之界面UI及动画切换
编程实战——电影管理器之界面UI及动画切换 在前文“编程实战——电影管理器之利用MediaInfo获取高清视频文件的相关信息”中提到电影管理器的目的是方便播放影片,在想看影片时不需要在茫茫的文件夹下找 ...
- eclipse中报错:Errors running builder “Integrated External Tool Builder” on project
在eclipse构建项目的时候,一直报如下错误: Errors during build. Errors running builder "Integrated External Tool ...