Spark入门级小玩
·背景
随着周边吐槽hadoop的声音渐渐多起来之后,spark也逐渐进入了大家的视野。之前,笔者有粗略的写过一篇spark的安装和性能比较[http://www.cnblogs.com/zacard-orc/p/3526007.html],加上这两天重读着大学时候的一些基础书籍,感觉IT领域大局势就像DNA的结构一样。百家齐鸣却又万象归一,就像APP与H5的战争一样,内存计算及磁盘计算在各领风骚数十年后,可能渐渐也有了一丝明朗的阳光,同时也给了一次屌丝走向高富帅的机会。这次再写一篇,不做枯燥理论的复制粘贴,就把这几天工作上碰到的一些内容更形象地与SPARK贴合起来。由于之前接触python不多,花了一天时间在上面,终于喝了两口python的汤,也正好切好本文的角度,已一个局外人的视角来解析spark的方便。写的不好之处,请拍~。
·Spark里的常用名字
pySpark.SparkContext:字面理解spark专属的上下文,承上启下。更形象的说,就像你的一份简历,上面有很多的字段(属性),方便你来告诉spark这次的 任务你想干什么。如果你忘了一些设置,或者想个性化一些设置,可以再从pySpark.conf中重新进行设定。
pySpark.SparkContext.textFile:知道了任务,总要告诉Spark你具体要处理的对象。对大多数人来说,读文件是绕不开的一些。这个函数就是读取文件的神器。虽然现在的pyspark还不支持streaming,但是预计时间上也是迟早的事。
RDD:字面理解,弹性数据集合。再粗俗点,大家把日志读到"内存",这个内存形式的会比较怪异。见下图,它可能存在的多种形式。

Partition:在一些常见的PPT介绍中,每个人对其的理解也有很大的差别,有的认为,RDD是PARTITION的一部分,多个RDD组成PARTITION。也有认为PARTITION是RDD的一部分。这个只能说,E文单词有时候还真的挺隐晦。从官网API的mapPartition上看,笔者觉得Spark更推荐上图3的使用形式。但是,有了Yarn之后,Spark立马从张辽变成了张飞。
Map+Reduce:OK。数据有了存在的形式,接下来干嘛。那就是自己改刀。在此需要提醒的时,在pyspark提示符号下,作为刚接触的同学可以多敲敲type。敲完之后,便一目了然。

spark 提供了很多API供大家发挥,唯独???需要从python中自己打造,有时候神和人的区别也许就在那???中能找到答案。PS:笔者是人。
Shared Variables:MR这就走完了,但是Spark除了内存和并行计算是主打卖点外,还有一件事情是他的卖点,就是共享变量,其重要性无论在哪种语言的API中都位于一级目录。这个还真是方便,在有些MR的任务中,往往要插入第三方数据或者乱入的数据。之前hadoop streaming 可以有conf参数提供,但是是静态,如果像中途变更,就是重启服务。正是这种情况下,Shared Variables中的broadcast发挥了强大的功能,能写能读,方便灵活,类同范围攻击。官网介绍它时,说他可以放LARGE DATA而且还能用Spark自己的算法最快地发布到每个Worker上。由于笔者未读源码,只是抓包看了一下,不是UDP的组播。另外还有一个变量叫Accumulators,这个能读不能写,字面义是"累加器",官网也是这么演示,但是笔者更看重它的另外一层E文翻译"蓄水池",除传统累加外,还能做一些MR过程中的临时统计,但又不输出到RDD结果。
·Spark入门演示
这次的演示不从官网角度出发,不从复制粘贴开始,就从最实际的工作切入。举个栗子,要基础的运维统计,统计每行日志中哪些耗时超过5100毫秒的操作记录。然后我们一步一步来。日志的样本如下所示,为了文章的效果,只显示5行,并且已经放到了hdfs://cent8:9000/input的目录下

先进入pyspark目录
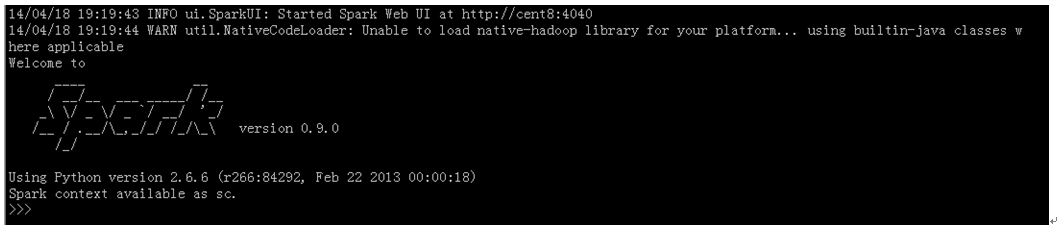
由于pyspark启动时默认加载了spark许多类库,所以原本写在脚本中的import xxx from sparkxxx都可以省略
先试着打开文件,很EAYS,打开的同时就已经分布式地加载到了内存中,此时words就是RDD类。
words = sc.textFile("/input/2.txt")

看下words里面是什么,words.collect(),而且它返回了一个列表。

知道它是一个列表后,python同学的发挥空间就打开了,接下来我们继续。把日志明细拆开,这里会开启MAP,当然不开也可以。
def f(x):
a=x.split(' ')
b=a[8].split(':')
return int(b[0]) words.map(f).collect()

一样的拆完之后,它返回了一个列表,我们稍加改动一下,把耗时大于5100的记录展示出来,它就变成了。
def f(x):
a=x.split(' ')
b=a[8].split(':')
if(int(b[0])>5100):
print x
return x words.map(f).collect()
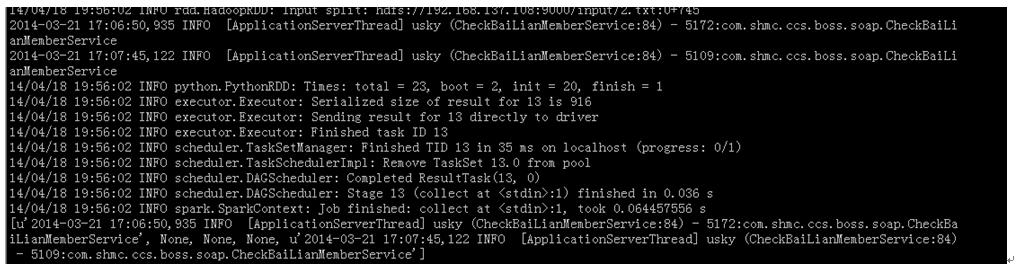
找日志的活就结束了,前面我们还说到了一个broadcast变量,官网给的例子太短了,让人理解困难。我来把它重新改造一下。
bv = sc.broadcast([13,23,33]) 设置了broadcast,然后就可以在自定义函数中自己饮用了。
def f(x):
a=x.split(' ')
b=a[8].split(':')
if(int(b[0])>5100):
print x
return int(b[0])+int(bv.value[2]) words.map(f).collect()

我们把BV的值再改一次改成[100,200,300]看会发生什么

OK,这次为此,Spark应用大门就此彻底打开了。当然这个spark的世界很大很大,包括很多屌丝逆袭高富帅的ML类,此文仅仅沧海一藕。如果想深入进去,涉及的知识面可谓覆盖了几乎整个时下流行的计算机体系的边边角角。
Spark入门级小玩的更多相关文章
- 【原】小玩node+express爬虫-2
上周写了一个node+experss的爬虫小入门.今天继续来学习一下,写一个爬虫2.0版本. 这次我们不再爬博客园了,咋玩点新的,爬爬电影天堂.因为每个周末都会在电影天堂下载一部电影来看看. talk ...
- hugo小玩
hugo小玩 1. 安装 install from source by brew install pre-built-binary 2. 下载源码 $ go get github.com/magefi ...
- Spark SQL 小文件问题处理
在生产中,无论是通过SQL语句或者Scala/Java等代码的方式使用Spark SQL处理数据,在Spark SQL写数据时,往往会遇到生成的小文件过多的问题,而管理这些大量的小文件,是一件非常头疼 ...
- 【原】小玩node+express爬虫-1
最近开始重新学习node.js,之前学的都忘了.所以准备重新学一下,那么,先从一个简单的爬虫开始吧. 什么是爬虫 百度百科的解释: 爬虫即网络爬虫,是一种自动获取网页内容的程序.是搜索引擎的重要组成部 ...
- canvas入门级小游戏《开关灯》思路讲解
游戏很简单,10行10列布局,每行每列各10盏灯,游戏初始化时随机点亮其中一些灯,点击某盏灯,其上下左右的灯及本身状态反转,如果点击前是灭着的,点击后即点亮,将所有灯全部点亮才算过关.游戏试玩: 下面 ...
- spark+kafka 小案例
(1)下载kafka的jar包 http://kafka.apache.org/downloads spark2.1 支持kafka0.8.2.1以上的jar,我是spark2.0.2,下载的kafk ...
- Spark原理小总结
1.spark是什么? 快速,通用,可扩展的分布式计算引擎 2.弹性分布式数据集RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据 ...
- Git小玩
早就听说了GitHub的强大. 一直没有机会去看, 在公司实习的几个月里也没机会接触SVN和Git, 可是抱着对Linus大神的崇敬, 和开源的崇敬之情. 趁着不忙的几天, 来学习一下Git. 希 ...
- hadoop spark合并小文件
一.输入文件类型设置为 CombineTextInputFormat hadoop job.setInputFormatClass(CombineTextInputFormat.class) sp ...
随机推荐
- spring常规任务(轻便易)
spring提供了定时任务功能.我们不需要第三者jar包支持.spring够了. 代码: package com.inth.product.web.task; import java.util.Dat ...
- aauto攫http数据
说明:灵巧使用上述数据的抓取网页简单的例子. 样例:想把某站点的数据抓回来.然后保存在数据库里边. 步骤:1.打开sql.new一个数据库Test.新建一个表test. 2.打开快手.准备抓数据,以这 ...
- 马云收购UC你,至于到底是谁宣战
近日,阿里巴巴官方正式宣布,UC优视全资融入阿里巴巴集团,并组建阿里UC移动事业群. 据阿里方面表示,整个交易对UC的估值远超百度对91无线的估值,外界推測估值近50美元.是中国互联网最大一笔交易.业 ...
- 使用JMX实现的内存监控(转)
public final class MemoryWarningSystem { private static MemoryWarningSystem m_instance = null; /** * ...
- 新RSS reader
阅读之前采取正确的方法,但是非常不介意,没有收到订阅很大. 走到今天 http://www.feedspot.com 2014/11/8追加:用下来感觉不错. feedspot 的相关快捷键例如以下: ...
- HDU2647(拓扑排序+反向建图)
题意不说了,说下思路. 给出的关系是a要求的工资要比b的工资多,因为尽可能的让老板少付钱,那么a的工资就是b的工资+1.能够确定关系为a>b,依据拓扑排序建边的原则是把"小于" ...
- Codeforces 327B-Hungry Sequence(素数筛)
B. Hungry Sequence time limit per test 1 second memory limit per test 256 megabytes input standard i ...
- 【MySQL案件】ERROR 1418
1.1.1. ERROR 1418 [环境的叙述性说明] mysql5.0.67 [问题叙述性说明] 当它来到创建存储过程ERROR 1418一个错误. # 创建函数SQL声明 CREATE FUNC ...
- oracle的分页查询碰到的一个小问题
订单表.与订单信息表(多个订单信息列有同一个订单id) 查出全部订单以及其信息并依照订单分页 select * from( select a. * , (DENSE_RANK() OVER(ORDER ...
- DICOM:DICOM3.0网络通信协议(延续)
题记: 在过去的一年中一直坚持周末博客,整理工作与休闲比的点点滴滴. 新知识点.新技术的涉猎会单独成文,对于与DICOM相关的知识统一放在了DICOM医学图像处理 专栏里,事实上DICOM英文全称是D ...