ML平台_Paddle参考
PaddlePaddle源自于 2013 年百度深度学习实验室创建的 “Paddle”。当时的深度学习框架大多只支持单 GPU 运算,对于百度这样需要对大规模数据进行处理的机构,这显然远远不够,极大拖慢了研究速度。百度急需一种能够支持多 GPU、多台机器并行计算的深度学习平台。而这就导致了 Paddle 的诞生。自 2013 年以来,Paddle 一直被百度内部的研发工程师们所使用。2016 年 9 月 1 日的百度世界大会上,百度首席科学家吴恩达宣布,该公司开发的异构分布式深度学习系统 PaddlePaddle 将对外开放。这标志着国内第一个机器学习开源平台的诞生。Paddle(Parallel Distributed Deep Learning 并行分布式深度学习),9 月发布时,吴恩达认为 “PaddlePaddle” (英语意为划船——“让我们荡起双~昂~桨,小船儿推开波浪。。。”)其实更郎朗上口、更好记,于是就有了这么个可爱的名字。
PaddlePaddle特点:
支持多种深度学习模型 DNN(深度神经网络)、CNN(卷积神经网络)、 RNN(递归神经网络),以及 NTM(Neural Turing Machines 神经网络图灵机) 这样的复杂记忆模型。
基于 Spark,与它的整合程度很高。
支持 Python 和 C++ 语言。支持分布式计算。作为它的设计初衷,这使得 PaddlePaddle 能在多 GPU,多台机器上进行并行计算。
相比现有深度学习框架,PaddlePaddle 优势:
- 易用性:相比偏底层的谷歌 TensorFlow,PaddlePaddle 的特点非常明显:它能让开发者聚焦于构建深度学习模型的高层部分。用 PaddlePaddle 编写的机器翻译程序只需要“其他”深度学习工具四分之一的代码。这显然考虑到该领域广大的初入门新手,为他们降低开发机器学习模型的门槛。这带来的直接好处是,开发者使用 PaddlePaddle 更容易上手。
- 更快的速度:自诞生之日起,它就专注于充分利用 GPU 集群的性能,为分布式环境的并行计算进行加速。这使得用大规模数据进行 AI 训练和推理可能要比 TensorFlow 这样的平台要快很多
- 可扩展性:PaddlePaddle很容易使用多个CPU/GPU和机器来加快你的训练,通过优化通信实现高吞吐量、高性能
- 连接产品:PaddlePaddle易于部署。在百度,PaddlePaddle已经被部署到广大用户使用的产品或服务,包括广告点击率(CTR)的预测,大型图像分类,光学字符识别(OCR),搜索排名,计算机病毒检测,推荐等。
总结起来,业内对 PaddlePaddle 的总体评价是“设计干净、简洁,稳定,速度较快,显存占用较小”。
初始PaddlePaddle
做一个形象的比喻,Paddle就好比一台3D打印机,我们设计的神经网络就好比需要打印的模型,而我们的数据集就相当于原材料,把两者同时提供给这台打印机,经过一段时间就可以得到我们预期的产品--模型(Trained Model). 简言之,paddle 做的工作就是利用我们设计的模型和我们提供的数据 通过高性能的并行技术(CPU/GPU)来完成训练。
在使用 Paddle 做深度学习时最基本的工作就是设计一个完美的模型并准备好数据。也就是要有以下几个文件:

- trainer_config.py : 配置神经网络模型
- data_provider.py : 数据提供
- train.sh : 配置paddle训练的参数
关于PaddlePaddle整体架构
PaddlePaddle 是2013年启动时比较流行的架构是 Pserver 和 Trainer 的架构。PaddlePaddle 的整体架构,主要从这几个方面入手:
- 多机并行架构、
- 多 GPU 并行架构、
- Sequence 序列模型
- 大规模稀疏训练
多机并行架构:首先是数据,数据分配到不同节点,就是简单的数据并行。如下图:灰色方框是一个机器,PServer和Trainer分布在两个独立的进程里,中间划线的部分是网络通信连接,可以看到PServer之间是没有连接的
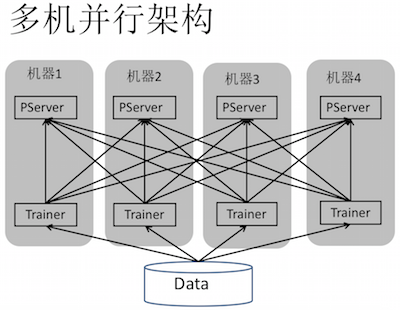
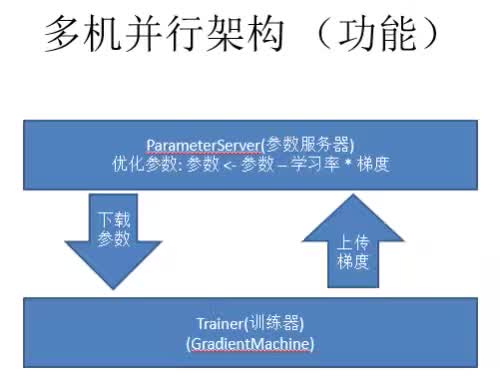
多机并行架构流程:多机并行架构的大致流程如下图,就是Trainer首先计算梯度,Pserver接收上传的梯度,然后通过一个优化方法去学习参数的优化,然后Trainer在下一个mini-batch上直接从Parmeterserver上下载一个参数过来,这个算法就是一个简单的SGD(Stochastic Gradient Descent-随机梯度下降)
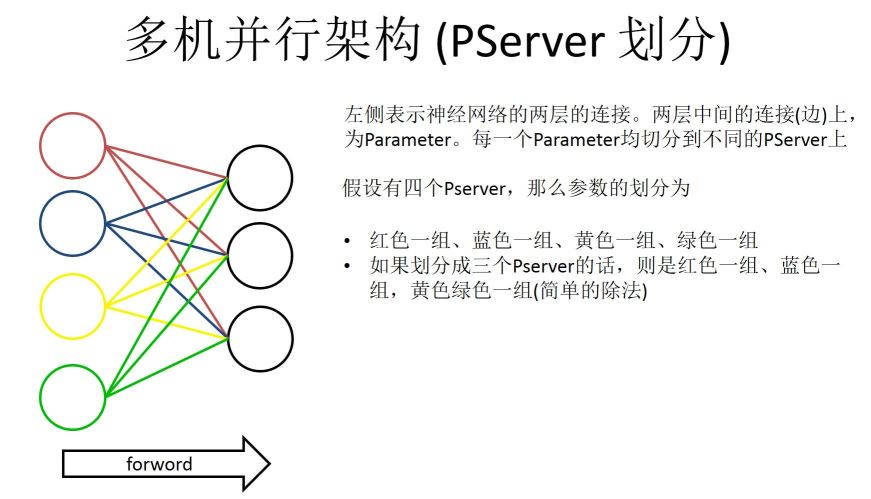
PServer划分:如下图左边是一个神经网络,它会把神经网络每一层参数分割开,具体怎么分割,这也是一个比较有技巧的地方。左边表示两层神经网络中间的连接,每个连接上是有一个参数的。我们要做的就是把中间这些连接参数均匀的分配到不同的PServer上。如果假设我们有四个PServer,那么参数分的话,Paddle的实现是这么做的,就是在左边靠数据那边是做切割的。红色一组蓝色一组,红黄蓝绿四组,如果是四个PServer的话就是每一组放一个PServer,如果划分为三个,最小粒度是左侧彩色的粒度。第一组是红色第二组是蓝色第三是黄色和绿色,这么做其实就可以实现一个稀疏训练的神经网络。
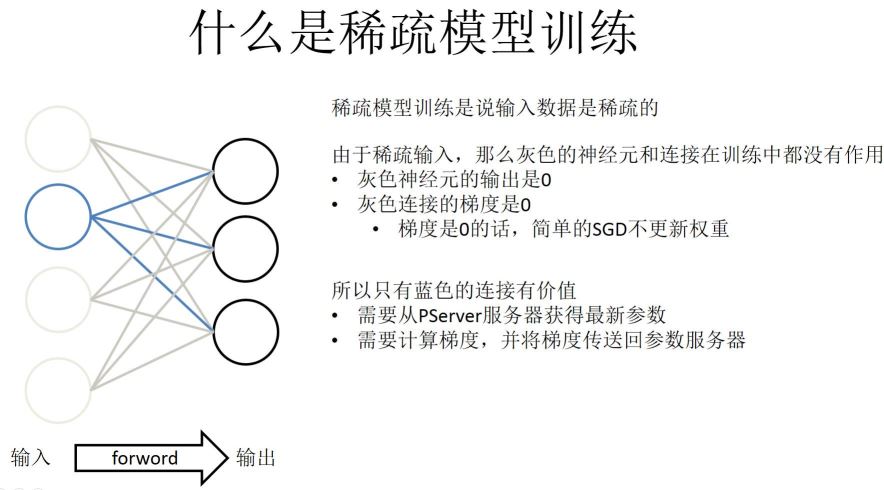
稀疏模型训练: 首先输入数据是稀疏的,如下图:左侧(输入)到右侧(输出),左侧是稀疏的话就是左侧有一些是实心的,剩下全是虚的。所以对稀疏来讲灰色神经元就是输出是0,简单来讲就是梯度是0,通过简单的SGD可以推出权重是不更新的。所以图中只有蓝色的是有价值的,需要计算的梯度是蓝色部分。所以按右侧划分PServer参数的时候,右侧划分三组这个功能不能实现,所以一般来说是从左侧划分成一些Parmeter block给PServer。稀疏训练的话,PaddlePaddle的实现分两个部分。第一个部分就是做预取,预取就是读一遍训练数据标记好哪些神经元是有用的,哪些是稀疏的,然后从服务器上查询最新的参数。第二部分就是经典的神经网络方式,就是前馈和反向传播,先计算梯度,然后逐层返回梯度给服务器。这两个部分实现的时候是并行的,就是异步的。
除了上面所提到的,还有两外两种情况下的稀疏模型:
- 大规模稀疏模型(多机器)——每个 Trainer Prefetch 出自身需要的参数和服务器通信。
- 大规模稀疏模型(正则化)——简单的 SGD 确实在梯度为0的时候,不去更新参数,但是加上正则化就不一定了;比如L2正则化,就要求参数的2范数持续减小。
大规模稀疏模型(多机器):前面是单机的模型,多机的大规模稀疏模型就是每一个Trainer找自身需要的参数给服务器,所以参数不存在单点上,这个集群里有整体所有的参数。这样设计还有一个特点,我们可以训练出来一个模型,这个模型占的内存比每个节点大。比如在百度我们用的机器内存有200G,但是训练得到的网络占据的空间大于200G。所以我们把参数所有的操作都放在PServer上,Trainer没有任何参数,每次都是从server上直接获取。

大规模稀疏模型(正则化):正则化是大规模稀疏模型的另一个问题。简单的SGD在梯度是0的时候,是不需要更新参数,但是如果加上正则化就不一样,比如L2正则化的时候,就要求参数的L2范数持续减小。稀疏模型正则化,第一点是从PServer上查参数,第二点Trainer去计算梯度然后发送给PServer,第三点是做参数优化,这个优化是不包括正则化的优化。我们在查询参数之前去做正则化,用这个参数的时候正则化再开始做。正则化是每一轮都要做,要持续的让这个参数越来越好。因为是一个稀疏模型,不一定每一次都会访问这个参数,所以我们就会记录下来访问的次数,然后最后一次访问的时候把之前没有做的正则化补齐,这个就是大规模稀疏模型正则化的做法,如下图:
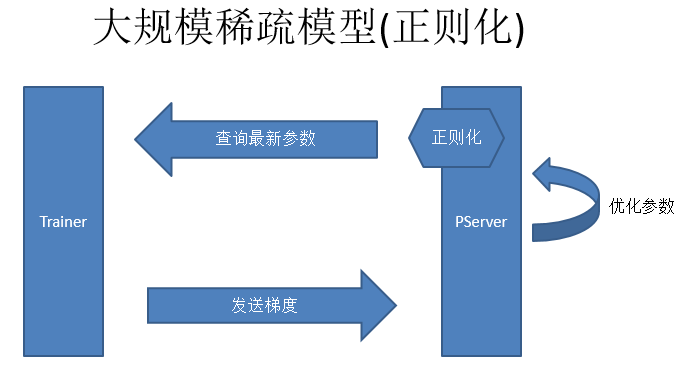
以上是2013年的趋势,目前有一个流行趋势就是不需要PServer这个架构,而是完全P2P的更新。P2P的更新一般是用一个环形网络,这个框架主要针对语言或者图像任务。
多GPU架构:PaddlePaddle的单机多GPU通信是环形通信,这比别的计算框架要快的一点,比如caffe的算法快一倍到两倍。单机多GPU的时候是环形通信,那为什么是环形呢?因为GPU是一个SPMD((Single Program/Multiple Data))的设备,一次会处理很多数据,但是处理很多数据和处理很少的数据对于GPU来讲是一样,GPU一般训练时都是稠密的数据。但是单机多GPU一般也不会做异步SGD,这与多GPU通信和网络多节点通信不一样,不需要把参数聚合到CPU,而是用一个逻辑的对外参数即可。

多GPU架构,如上图,左侧是对外参数,是可以被PaddlePaddle其他的程序访问,然后这一个对外参数分成三个参数块,把三个参数块分别放到三个不同的主卡上

多GPU架构的参数分发采用的是从主设备分发给下一个设备,再由下一个设备分发给下下个设备,依次往最远端分发的方式
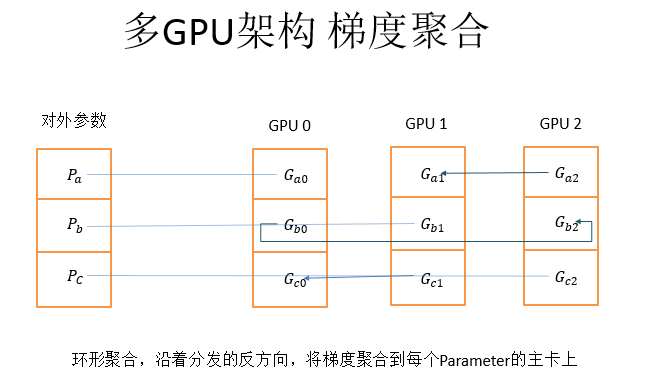
而梯度聚合就是沿着分发的反方向,将计算得到的梯度聚合到每个参数的主卡上。这样做的好处就是只利用显卡之间的P2P通信,没有经过CPU和内存。
序列模型是指训练数据是一个序列(sequence),具有一定的顺序(order)的概念。就是序列模型的特征是a vector of features而不是a set of features,比较常见的序列模型任务就是自然语言处理或者说音视频的处理。

PaddlePaddle中对于序列模型的处理也和其他的神经网络框架不一样。具体实现是这样的,在其他层来看,sequence都是一整条输入,但是对于某些特定的层,PaddlePaddle会将输入序列打散成不同的时间步,然后在这个层内部对每个时间步进行处理,当然这个处理都是自定义的。这个时间部处理完了以后我们再用一个GatherLayer将拆解的时间步重新组合成一个sequence再输出出来,就是一个打散再聚合的过程。
每个时间步之间是有通信的,比如做语音识别前一秒的语音和后一秒的语音有一定关系,这种通信Paddle是采用一种叫Memory的机制,就是在特殊的RNN的层里,定义一种Memory,上一个时间步的神经网络,可以将需要记住的东西放到Memory中,下一个时间步可以引用这个Memory,这样就实现了Memory的共享。Paddle是支持任意复杂的RNN结构,你知道的任何的RNN结构都是支持的,当然也可以自己搭配不同的结构。
Sepuence序列模型最难的一点在于batch计算,为什么要做batch计算呢?因为矩阵维度要足够大,才能充分发挥GPU的能力,才能加速运算 (SPMD)。但是Sepuence序列模型有一个问题就是输入是参差不齐的。那么怎么对这种输入进行计算?
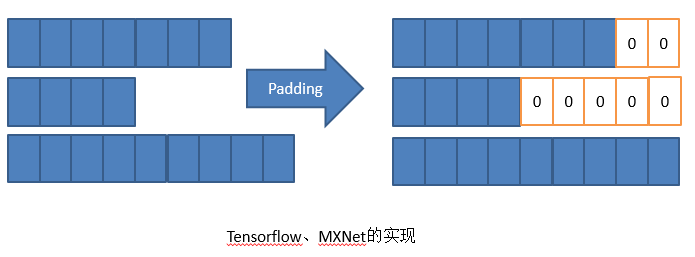
不同的网络框架的做法不一样,Tensorflow和MXNet会做Padding,将三个Sepuence全部Pading一样长,不够的后面补0,然后再依次计算。当然Padding非常有技巧,比如把Sepuence和相近长度的Padding起来,使补0补得最少。但是本质上这种实现还是一个需要多计算的方法。

而PaddlePaddle的实现是做一个排序,不是物理排序,而是一个逻辑排序。逻辑上排序成右侧的形式我们依次去计算。但是计算到一定程度以后,空间可能会变少。这是PaddlePaddle的实现,这个优点就是没有Padding不会增加计算量,但是缺点就是排序需要时间。这两个实现并不能说谁比谁,因为是这个问题终究没有非常好的解决,目前还在探索这个问题。
一些思考
目前主流的神经网络框架可以分为两种,如下:
- 基于 OP——从矩阵乘法配起,一步一步对应一个一个数学运算。
- 基于层——直接写一个全连接层,LSTM 层。
- 基于 OP 的优势 Tensorflow——更灵活,更可以让研究人员构造新的东西
- 基于 Layer 的优势 Caffe——更易用,让细节暴露的更少;更容易优化。
那么PaddlePaddle是基于OP还是基于layer?PaddlePaddle是一个混合的系统,首先PaddlePaddle支持大部分Layer,但是也支持从OP开始配网络(比如矩阵乘法,加法,激活等等)。对于一些成型的layer,比如LSTM,我们使用C++对其进行重新优化。我们刚开始做的时候LSTM还没有一个专门的Layer,是从OP开始配,但是配完以后发现LSTM使用的非常广泛,所以就将其作为一个Layer重新在C++实现一遍。
所以在PaddlePaddle中我们把这些常用的OP的组合再优化成一个Layer,这样做的好处就是可以兼顾灵活性,但是最重要的还是性能。这样做的好处就是PaddlePaddle的LSTM是业界最快的,而且是从原理上就比其他框架快。
还有一个实现思考的话就是,PaddlePaddle的多机通信到底是基于MPI 还是 Spark 还是 k8s + Docker?首先PaddlePaddle的任务比较简单,因为我们不是一个网站,或者说要求很高的东西,如果运行几周挂一次还是可以接受的。比如说每个小时存一个数据点,再恢复的话并不是耗费非常大的事情。所以PaddlePaddle的网络任务需求相对简单,我们可以自己做,并不依赖于任何网络框架。
第二点就是PaddlePaddle的网络是需要高性能的网络,从头手写网络库更方便性能调优,并且RDMA可以更好的支持。同理,PaddlePaddle底层不依赖任何GPU通信框架。当然,我们未来会提供一些配置脚本,比如说在多机上更容易实现的配置脚本。
通用集群示意图
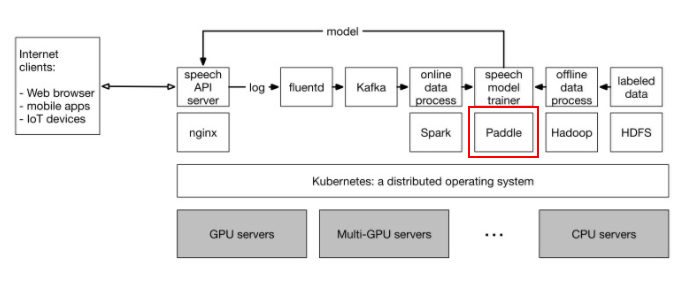
下图是一个通用集群的简单示意图,这个集群里有很多GPU的服务器,也有很多CPU的服务器,他们都部署在一个集群里。在这个集群的机器之上运行着Kubernetes。Kubernetes是一个谷歌开源的分布式的操作系统。在2007年的时候,谷歌就使用集群操作系统Borg,通过混合部署各种来源的各种任务,将CPU的利用率一直维持在75%到80%左右。而Kubernetes开发之前是Borg开发团队中的一部分,Kubernetes的设计继承了Borg项目多年总结的经验,是目前最先进集群操作系统。
百度深度学习平台
百度深度学习平台是一个面向海量数据的深度学习平台,基于PaddlePaddle和TensorFlow开源计算框架,支持GPU运算,为深度学习技术的研发和应用提供可靠性高、扩展灵活的云端托管服务。通过百度深度学习平台,不仅可以轻松训练神经网络,实现情感分析、机器翻译、图像识别,也可以利用百度云的存储和虚拟化产品直接将模型部署至应用环境。
参考资料:
- https://news.cnblogs.com/n/560638/
- http://www.tmtpost.com/2584884.html
- http://www.jianshu.com/p/699692fdd446
- https://sdk.cn/news/5551
- http://www.sohu.com/a/123254498_470008
- http://www.36dsj.com/archives/98977
ML平台_Paddle参考的更多相关文章
- ML平台_Angel参考
Angel 是腾讯开源基于参数服务器(Parameter Server)理念的机器学习框架(为支持超大维度机器学习模型运算而生).核心设计理念围绕模型,它将高维度的大模型切分到多个参数服务器节点,并通 ...
- ML平台_PAI参考
阿里云机器学习PAI(Platform of Artificial Intelligence)是一款一站式的机器学习平台,包含数据预处理.特征工程.常规机器学习算法.深度学习框架.模型的评估以及预测这 ...
- ML平台_设计要点
如果说机器是人类手的延伸.交通工具是人类腿的延伸,那么人工智能就是人类大脑的延伸,甚至可以帮助人类自我进化,超越自我.人工智能也是计算机领域最前沿和最具神秘色彩的学科,科学家希望制造出代替人类思考的智 ...
- ML平台_小米深度学习平台的架构与实践
(转载:http://www.36dsj.com/archives/85383)机器学习与人工智能,相信大家已经耳熟能详,随着大规模标记数据的积累.神经网络算法的成熟以及高性能通用GPU的推广,深度学 ...
- ML平台_微博深度学习平台架构和实践
( 转载至: http://www.36dsj.com/archives/98977) 随着人工神经网络算法的成熟.GPU计算能力的提升,深度学习在众多领域都取得了重大突破.本文介绍了微博引入深度学 ...
- ML平台_饿了么实践
(转载至:https://zhuanlan.zhihu.com/p/28592540) 说到机器学习.大数据,大家听到的是 Hadoop 和 Spark 居多,它们跟 TensorFlow 是一个什么 ...
- <转>ML 相关算法参考
转自 国内外网站如果你想搜索比较新颖的机器学习资料或是文章,可以到以下网站中搜索,里面不仅包括了机器学习的内容,还有许多其它相关领域内容,如数据科学和云计算等.InfoWord:http://www. ...
- How To Build Kubernetes Platform (构建Kubernetes平台方案参考)
Architecture Architecture Diagram Non-Prod Environment Prod Environment Cluster Networking Container ...
- API 开发平台 dreamfactory,参考SAWAGGER,国外厂家,开源,本地与云部署
API 开发平台,参考SAWAGGER,国外厂家,本地与云部署:参考 http://swagger.io/commercial-tools/ 1.dreamfactory 梦工厂公司 https: ...
随机推荐
- 引用google字体
1.很简单直接 @import url(http://fonts.font.im/css?family=Shadows+Into+Light); 引入页面即可 2. 使用: font-fami ...
- L1-028. 判断素数
本题的目标很简单,就是判断一个给定的正整数是否素数. 输入格式: 输入在第一行给出一个正整数N(<=10),随后N行,每行给出一个小于231的需要判断的正整数. 输出格式: 对每个需要判断的正整 ...
- hadoop day 1
hadoop是什么? 解决的问题: 海量数据的存储(HDFS):供hbase,mapreduce进行处理 海量数据的分析(MapReduce) 资源管理调度(YARN) 搜索引擎: 爬虫系统+站内搜索 ...
- 【转载】 强化学习(七)时序差分离线控制算法Q-Learning
原文地址: https://www.cnblogs.com/pinard/p/9669263.html ------------------------------------------------ ...
- bash & vi
更高效的使用. 选中全文 ggVG 文件头:gg,文档尾:G redo: CTRL+r 折叠代码/打开折叠: zf ,进行折叠 zo, 打开折叠 zc,关闭折叠 跳到匹配{或}处: % 标记当前单词: ...
- 百练6183-人民币支付-2014正式A题
A:人民币支付 总时间限制: 1000ms 内存限制: 65536kB 描述 从键盘输入一指定金额(以元为单位,如345),然后输出支付该金额的各种面额的人民币数量,显示100元,50元,20元, ...
- Container(容器)
容器可以管理对象的生命周期.对象与对象之间的依赖关系,您可以使用一个配置文件(通常是XML),在上面定义好对象的名称.如何产生(Prototype 方式或Singleton 方式). 哪个对象产生之后 ...
- lesson3-神经序列模型I-小象
优化目标函数: batch gradient descent:必须便利all训练数据 -->随机梯度下降,但不稳定~一个数据点就更新,快但不稳定-->minibatch,取m个随机数据点, ...
- NYOJ 12:喷水装置(二)(贪心,区间覆盖问题)
12-喷水装置(二) 内存限制:64MB 时间限制:3000ms 特判: No 通过数:28 提交数:109 难度:4 题目描述: 有一块草坪,横向长w,纵向长为h,在它的橫向中心线上不同位置处装有n ...
- windows错误:错误0x80070091 目录不是空的
错误: Window 下目录无法删除,提示 “ 错误0x80070091 目录不是空的 ” 解决: 1.开始菜单>附件>命令提示符>右键>以管理员身份运行 2.删除文件:(如 ...