2017-6-6&6-8/大型网站架构总结
- 峰值每秒钟3万个 HTTP 请求
- 每秒钟 3Gbit 流量, 近乎375MB
- 350 台 PC 服务器
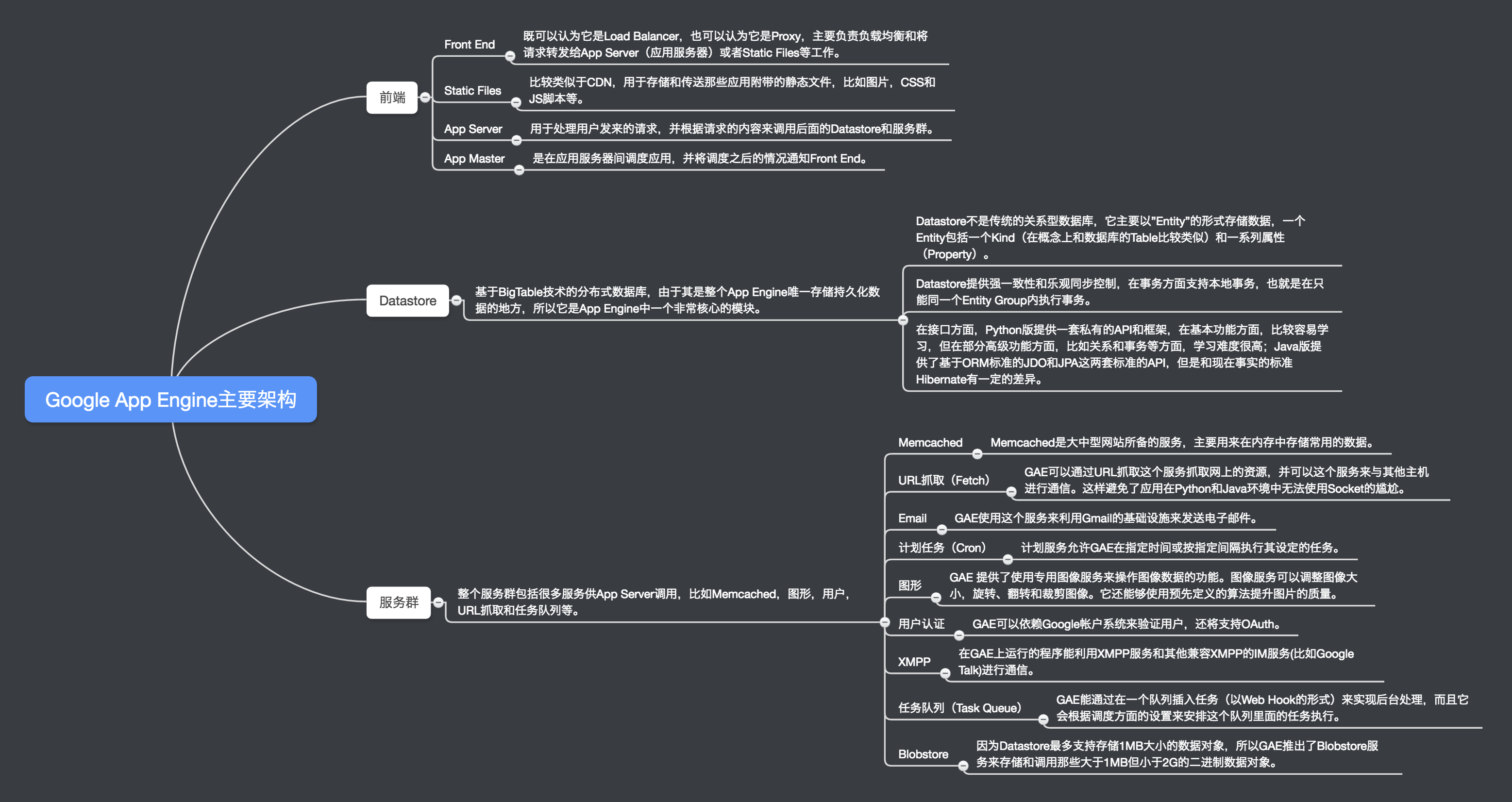
2、WikiPedia的主要架构
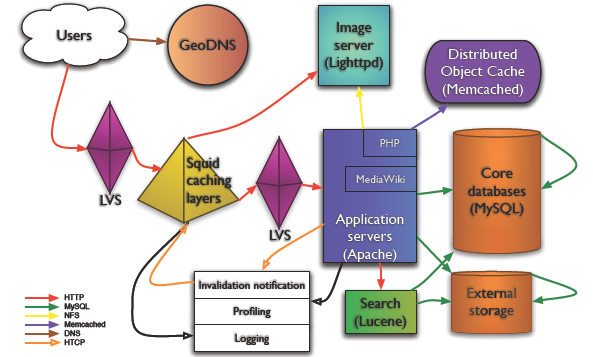
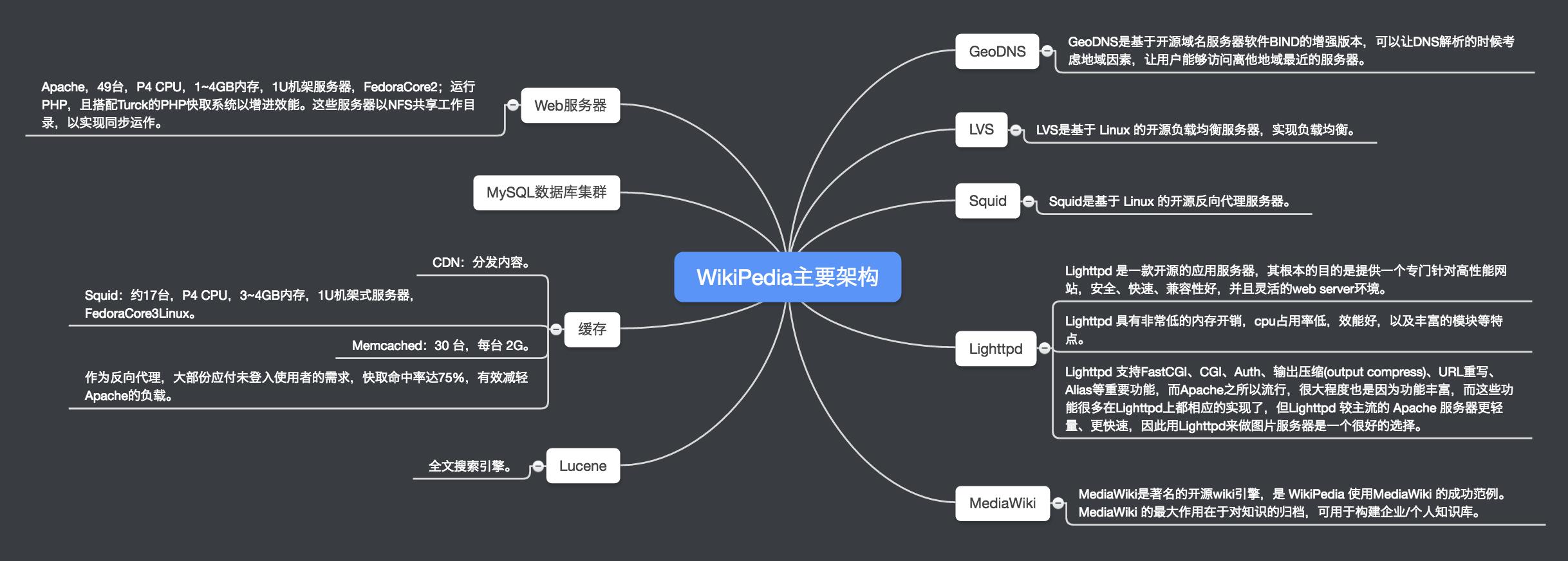
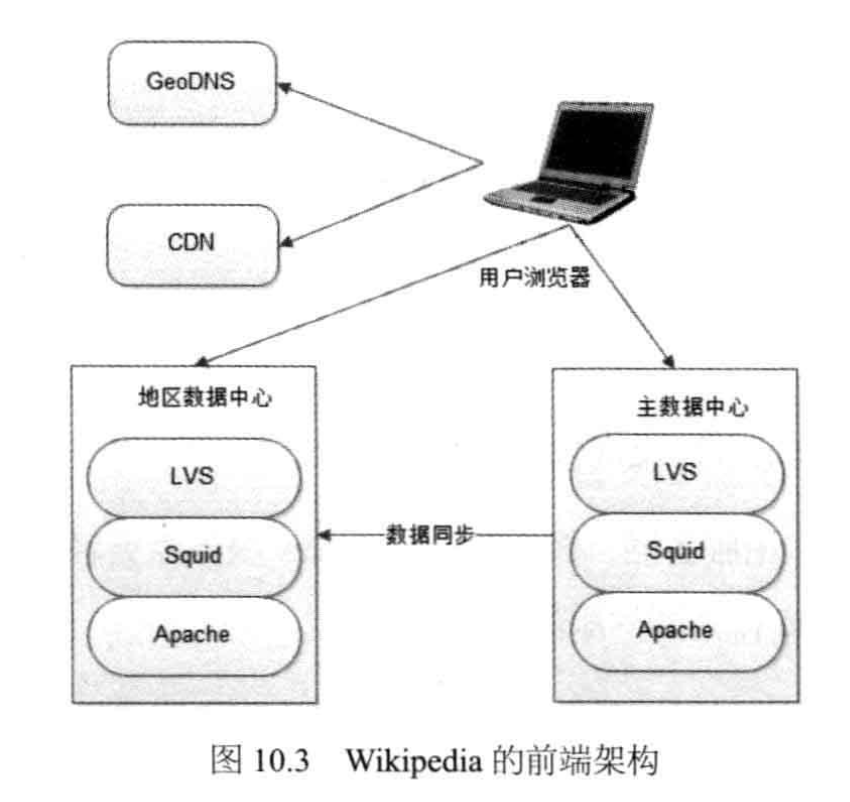
- 每月的页面浏览量:570000000000 (5700亿)
- 照片数量超过其他图片网站的总和(包括诸如Flickr等网站)
- 每个月有超过30亿张照片上传
- 每秒可以处理120万张照片,这还不包括CDN处理的照片
- 每月处理超过25亿条内容 (状态更新,评论等)
- 服务器超过30,000台(此数据为2009年的数据)
2、Facebook的主要架构
Facebook使用LAMP(Linux、Apache、MySQL、PHP)作为技术构架,为了配合其他大量的组件和服务,Facebook对已有的方法做了必要的改变、拓展和修改。比如:
- Facebook依然使用PHP,但已重建新的编译器,以满足在其Web服务器上加载本地代码,从而提升性能;
- Facebook使用Linux系统,但为了自身目的,也已做了必要的优化,尤其是在网络吞吐量方面;
- Facebook使用MySQL,也对其做优化;
- 还有定制的系统,比如:
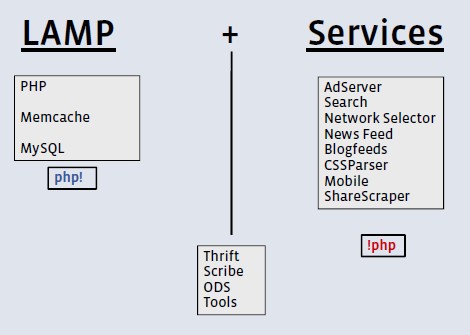
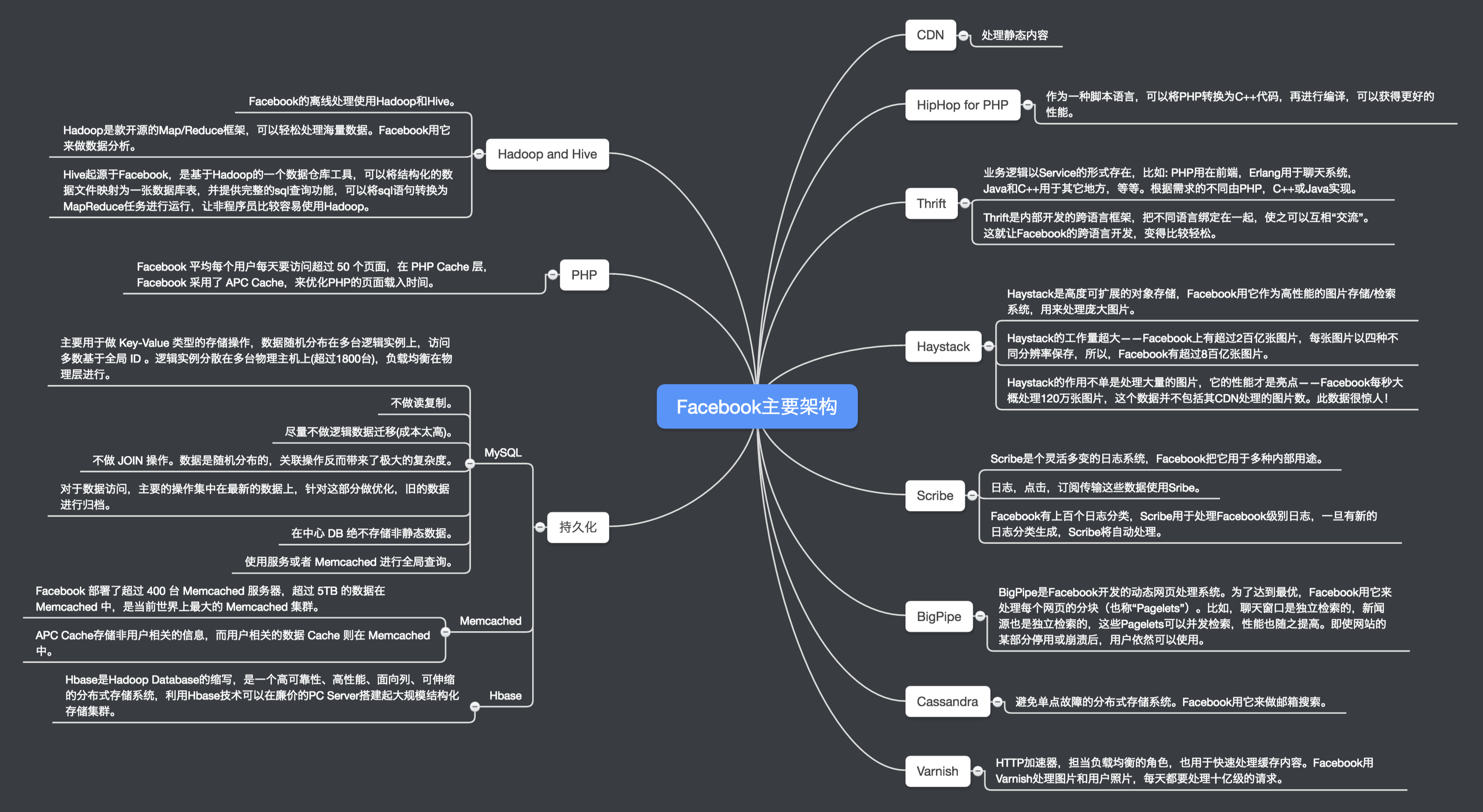

- Linux、Oracle、C++、Perl、Mason、Java、Jboss、Servlets
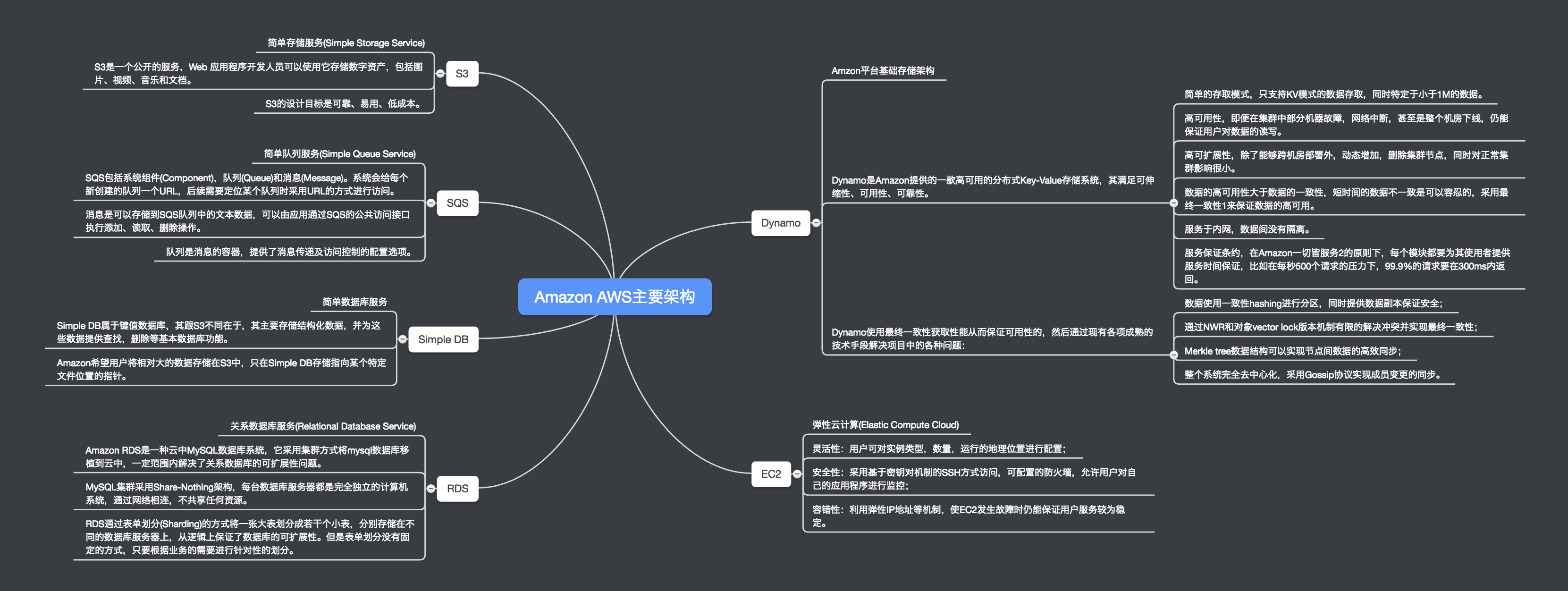
- 超过5500万活动顾客帐号
- 世界范围内超过100万活动零售合作商
- 构建一个页面所需访问的服务介于100至150个之间
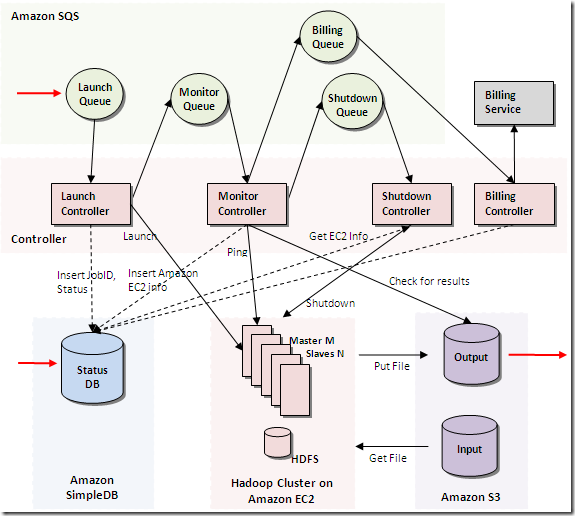
- twitter每月有180万独立访问用户数,并且75%的流量来自twitter.com以外的网站。
- 每天通过API有30亿次请求
- 每天平均产生5500次tweet,37%活跃用户为手机用户,约60%的tweet来自第三方的应用。

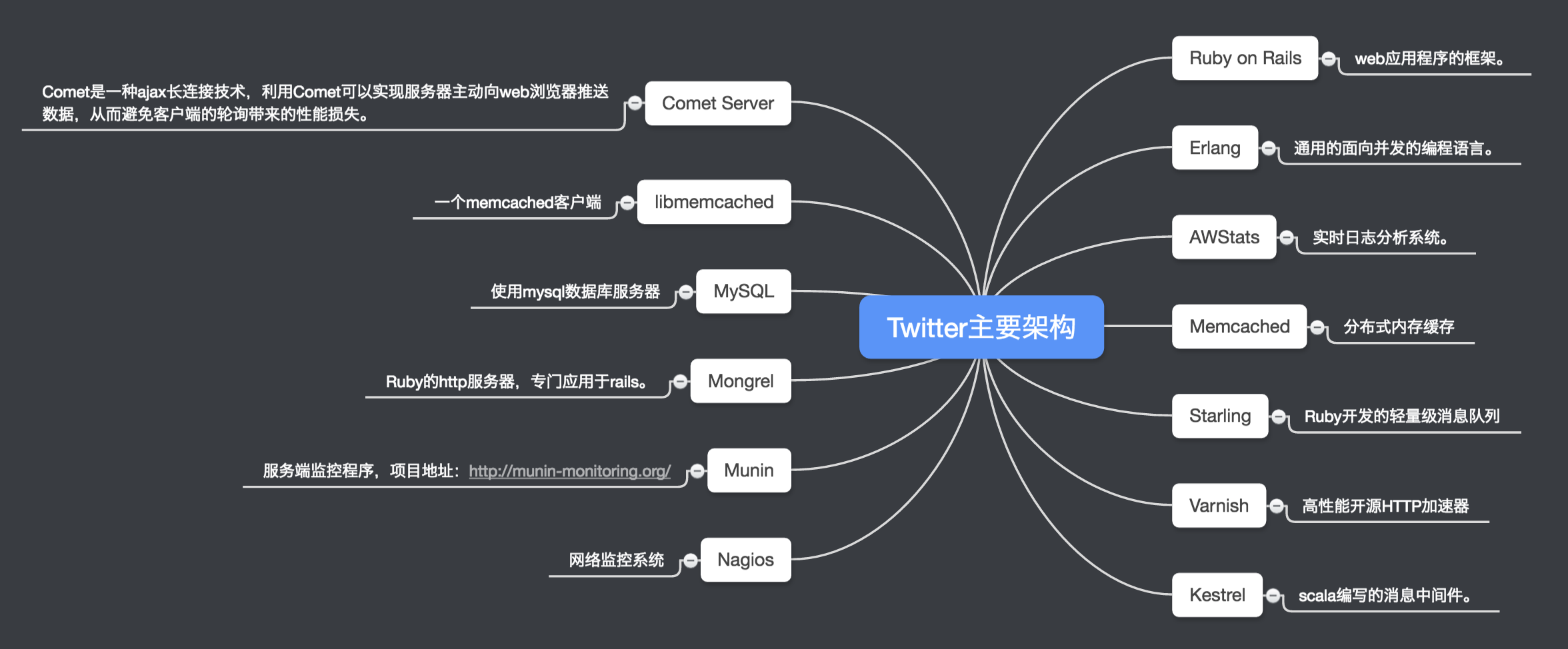
- 日均独立访问人数(uv)达到了8900万(2010年数据)
- 日均访问量(pv)达到了17亿,凭借这一数据成为google榜单中国内视频网站排名最高的厂商(2010年数据)
- 1000多台服务器(2007年数据)

2017-6-6&6-8/大型网站架构总结的更多相关文章
- Drupal与大型网站架构(译)- Large-Scale Web Site Infrastructure and Drupal
Drupal与大型网站架构(译)- Large-Scale Web Site Infrastructure and Drupal Linuxjournal 网站经典文章翻译,原文地址: Large-S ...
- 《大型网站系统与JAVA中间件实践》读书笔记-大型网站架构演进
大型网站架构演进 大型网站是一种很常见的分布式系统,除了海量数据和高并发的访问量,本身业务和系统也复杂. 大型网站的架构演进 我们现在常用的大型网站都是从小网站一步一步发展起来的,这个过程中会 有一些 ...
- Java程序员的职业发展道路 附:大型网站 -- 架构技能图谱(Java版)
职业发展道路基本有3条: 第一条路线(技术专精): 初级Java开发---中级--高级---项目主管--Java项目经理---网站架构师----资深专家 第二条路线(技术转产品):初级Java开发-- ...
- 各大型网站架构分析收集-原网址http://blog.csdn.net/lovingprince/article/details/3379710
1. PlentyOfFish 网站架构学习http://www.dbanotes.net/arch/plentyoffish_arch.html 采取 Windows 技术路线的 Web 2.0 站 ...
- 大型网站架构之JAVA中间件
中间件就是在大型网站中,帮助各子模块间实现互相访问,消息共享或统一访问等功能的软件产品.常见的有: 远程服务框架中间件:主要解决各子模块之间互相访问的问题. 消息队列中间件:主要解决各子模之间消息共享 ...
- 大型网站架构演进(6)使用NoSQL和搜索引擎
随着网站业务越来越复杂,对数据存储和检索的需求也越来越复杂,网站需要采用一些非关系型数据库技术(即NoSQL)和非数据库查询技术如搜索引擎.NoSQL数据库一般使用MongoDb,搜索引擎一般使用El ...
- 大型网站架构演化(八)——使用NoSQL和搜索引擎
随着网站业务越来越复杂,对数据存储和检索的需求也越来越复杂,网站需要采用一些非关系数据库技术如NoSQL和非数据库查询技术如搜索引擎,如图. NoSQL和搜索引擎都是源自互联网的技术手段,对可伸缩的分 ...
- 大型网站架构演化(六)——使用反向代理和CDN加速网站响应
随着网站业务不断发展,用户规模越来越大,由于中国复杂的网络环境,不同地区的用户访问网站时,速度差别也极大.有研究表明,网站访问延迟和用户流失率正相关,网站访问越慢,用户越容易失去耐心而离开.为了提供更 ...
- 大型网站技术架构(四)--核心架构要素 开启mac上印象笔记的代码块 大型网站技术架构(三)--架构模式 JDK8 stream toMap() java.lang.IllegalStateException: Duplicate key异常解决(key重复)
大型网站技术架构(四)--核心架构要素 作者:13GitHub:https://github.com/ZHENFENG13版权声明:本文为原创文章,未经允许不得转载.此篇已收录至<大型网站技 ...
随机推荐
- mysql分区分表讲解
为什么要分表和分区? 日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表.这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询的情况,性能 ...
- FI CO 常用表
FI CO 常用表 最近写FICO的报表写得有点多,许多Table记不住,用F1查找又有点费事,不如把表单写下来,以后用到,直接在这上面找得了. 1,账目表主数据 SKA1 SKB1 S ...
- HDU 3047 Zjnu Stadium(带权并查集)
http://acm.hdu.edu.cn/showproblem.php?pid=3047 题意: 给出n个座位,有m次询问,每次a,b,d表示b要在a右边d个位置处,问有几个询问是错误的. 思路: ...
- go 一波走起
$ go run helloworld.go 运行 $ go build helloworld.go 编译 该命令生成一个名为helloworld的可执行的二进制文件,可以随时运行它 $ ./hell ...
- super()、this属性与static静态方法的执行逻辑
1.super的构造顺序:永远优先构造父类的方法 2.static永远在类实例之前执行,this的使用范围为实例之后
- 提高R语言速度--转载
1. 参考<R语言编程艺术>(Norman Matloff) chapter 14 & chapter 15 2. 方法 (1)向量化 与非向量化-循环做个对比: ...
- SPOJ QTREE Query on a tree 树链剖分+线段树
题目链接:http://www.spoj.com/problems/QTREE/en/ QTREE - Query on a tree #tree You are given a tree (an a ...
- java常用技术名词解析
1.1 token Token是服务端生成的一串字符串,以作客户端进行请求的一个令牌,当第一次登录后,服务器生成一个Token便 将此Token返回给客户端,以后客户端只需带上这个Token前来请求数 ...
- 【C#】采用OleDB读取Excel文件转DataTable
using System; using System.Data; using System.Data.OleDb; using System.IO; using System.Linq; using ...
- SpringMVC获取页面表单参数的几种方式
以下几种方式只有在已搭好的SpringMVC环境中,才能执行成功! 首先,写一个登陆页面和一个Bean类 <%@ page language="java" co ...