python 全栈开发,Day142(flask标准目录结构, flask使用SQLAlchemy,flask离线脚本,flask多app应用,flask-script,flask-migrate,pipreqs)
昨日内容回顾
1. 简述flask上下文管理
- threading.local
- 偏函数
- 栈 2. 原生SQL和ORM有什么优缺点? 开发效率: ORM > 原生SQL
执行效率: 原生SQL> ORM 如:SQLAlchemy依赖pymysql 3. SQLAlchemy多线程连接的情况
一、flask标准目录结构
标准flask目录结构
Project name/ # 项目名
├── Project name # 应用名,保持和项目名同名
│ ├── __init__.py # 初始化程序,用来注册蓝图
│ ├── static # 静态目录
│ ├── templates # 模板目录
│ └── views # 蓝图
└── manage.py # 启动程序
注意:应用名和项目名要保持一致
蓝图
修改manage.py
from lastday import create_app app = create_app() if __name__ == '__main__':
app.run()
进入views目录,新建文件account.py
from flask import Blueprint
account = Blueprint('account',__name__)
@account.route('/login')
def login():
return '登陆'
@account.route('/logout')
def logout():
return '注销'
修改 __init__.py,注册蓝图
from flask import Flask
from lastday.views.account import ac def create_app():
"""
创建app应用
:return:
"""
app = Flask(__name__) app.register_blueprint(ac) return app
执行manage.py,访问首页: http://127.0.0.1:5000/login
效果如下:

进入views目录,新建文件user.py
from flask import Blueprint,render_template
us = Blueprint('user',__name__) # 蓝图名
@us.route('/user_list/')
def user_list(): # 注意:不要和蓝图名重复
return "用户列表"
修改 __init__.py,注册蓝图
from flask import Flask from lastday.views.account import ac
from lastday.views.user import us def create_app():
"""
创建app应用
:return:
"""
app = Flask(__name__) # 注册蓝图
app.register_blueprint(ac)
app.register_blueprint(us) return app
进入templates目录,创建文件user_list.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title> </head>
<body>
<h1>用户列表</h1>
</body>
</html>
修改views-->user.py,渲染模板
from flask import Blueprint,render_template
us = Blueprint('user',__name__) # 蓝图名
@us.route('/user_list/')
def user_list(): # 注意:不要和蓝图名重复
return render_template('user_list.html')
重启manage.py,访问用户列表
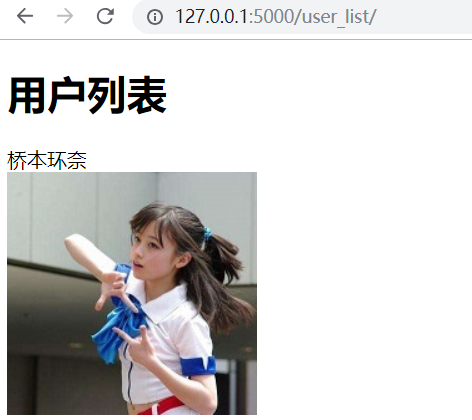
在static目录创建images文件夹,放一个图片meinv.jpg
修改 templates\user_list.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title> </head>
<body>
<h1>用户列表</h1>
<div>桥本环奈</div>
<img src="/static/images/meinv.jpg">
</body>
</html>
刷新页面,效果如下:
如果使用蓝图,上面就是官方推荐的写法!
配置文件
在项目根目录,创建settings.py
class Base(object):
SECRET_KEY = "fasdfasdf" # session加密字符串 class Product(Base):
"""
线上环境
"""
pass class Testing(Base):
"""
测试环境
"""
DEBUG = False class Development(Base):
"""
开发环境
"""
DEBUG = True # 开启调试
这里的Base表示3个环境相同的配置
为什么配置文件要用类呢?待会再说
引入配置(推荐写法)
from flask import Flask from lastday.views.account import ac
from lastday.views.user import us def create_app():
"""
创建app应用
:return:
"""
app = Flask(__name__) # 引入配置文件并应用
app.config.from_object("settings.Development") # 注册蓝图
app.register_blueprint(ac)
app.register_blueprint(us) return app
配置文件使用类之后,如果要切换环境,这里改一下,就可以了!
那么类的静态属性,就是配置!
路由都写在蓝图里面了,如果要对所有请求,做一下操作,怎么办?
加before_request,要在哪里加?
在__init__.py里面加
from flask import Flask from lastday.views.account import ac
from lastday.views.user import us def create_app():
"""
创建app应用
:return:
"""
app = Flask(__name__) # 引入配置文件并应用
app.config.from_object("settings.Development") # 注册蓝图
app.register_blueprint(ac)
app.register_blueprint(us) @app.before_request
def b1():
print('b1') return app
重启manage.py,刷新页面,查看Pycharm控制台输出:b1
那么问题来了,如果b1的视图函数,代码有很多行呢?
在create_app里面有一个b1函数。b1函数就是一个闭包!
先来理解一下装饰器的本质,比如b1函数,加了装饰器之后,可以理解为:
b1 = app.before_request(b1)
由于赋值操作没有用到,代码缩减为
app.before_request(b1)
那么完整代码,就可以写成
from flask import Flask from lastday.views.account import ac
from lastday.views.user import us def create_app():
"""
创建app应用
:return:
"""
app = Flask(__name__) # 引入配置文件并应用
app.config.from_object("settings.Development") # 注册蓝图
app.register_blueprint(ac)
app.register_blueprint(us) app.before_request(b1) # 请求到来之前执行 return app def b1():
print('app_b1')
其实蓝图,也可以加before_request
修改 views-->account.py
from flask import Blueprint
ac = Blueprint('account',__name__)
@ac.before_request
def bb():
print('account.bb')
@ac.route('/login')
def login():
return '登陆'
@ac.route('/logout')
def logout():
return '注销'
重启 manage.py,访问登录页面,注意:后面不要带"/",否则提示Not Found

查看Pycharm控制台输出:
app_b1
account.bb
可以发现,2个before_request都执行了。注意:在__init__.py中的before_request是所有路由都生效的
而account.py中的before_request,只要访问这个蓝图的路由,就会触发!
因此,访问 http://127.0.0.1:5000/logout,也是可以触发account.py中的before_request
完整目录结构如下:
lastday/
├── lastday
│ ├── __init__.py
│ ├── static
│ │ └── images
│ │ └── meinv.jpg
│ ├── templates
│ │ └── user_list.html
│ └── views
│ ├── account.py
│ └── user.py
├── manage.py
└── settings.py
总结:
如果对所有的路由要操作,那么在app实例里面,写before_request
如果对单个的蓝图,则在蓝图里面使用before_request
二、flask使用SQLAlchemy
必须先安装模块sqlalchemy
pip3 install sqlalchemy
准备一台MySQL服务器,创建数据库db1
CREATE DATABASE db1 DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
默认的用户名为root,密码为空
非主流操作
基于上面的项目lastday,进入lastday应用目录,创建文件models.py
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index
from sqlalchemy.orm import relationship # 创建了一个基类:models.Model
Base = declarative_base() # 在数据库创建表一张表
class Users(Base):
__tablename__ = 'users' id = Column(Integer, primary_key=True)
name = Column(String(32), index=True, nullable=False) # 在数据库创建表一张表
class School(Base):
__tablename__ = 'school' id = Column(Integer, primary_key=True)
name = Column(String(32), index=True, nullable=False) def db_init():
from sqlalchemy import create_engine
# 创建数据库连接
engine = create_engine(
# 连接数据库db1
"mysql+pymysql://root:@127.0.0.1:3306/db1?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
) Base.metadata.create_all(engine) # 创建操作
# Base.metadata.drop_all(engine) # 删除操作 if __name__ == '__main__': db_init()
此时目录结构如下:
lastday/
├── lastday
│ ├── __init__.py
│ ├── models.py
│ ├── static
│ │ └── images
│ │ └── meinv.jpg
│ ├── templates
│ │ └── user_list.html
│ └── views
│ ├── account.py
│ └── user.py
├── manage.py
└── settings.py
执行models.py,注意:它会输出一段警告
Warning: (1366, "Incorrect string value: '\\xD6\\xD0\\xB9\\xFA\\xB1\\xEA...' for column 'VARIABLE_VALUE' at row 484")
result = self._query(query)
这个异常是mysql问题,而非python的问题,这是因为mysql的字段类型是utf-xxx, 而在mysql中这些utf-8数据类型只能存储最多三个字节的字符,而存不了包含四个字节的字符。
这个警告,可以直接忽略,使用Navicat软件查看,发现表已经创建完成
修改 user.py,插入一条记录
from flask import Blueprint,render_template
from lastday.models import Users us = Blueprint('user',__name__) # 蓝图名 @us.route('/user_list/')
def user_list(): # 注意:不要和蓝图名重复
# 创建连接
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
engine = create_engine("mysql+pymysql://root:@127.0.0.1:3306/s11day139?charset=utf8", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
session = Session() # 添加一条记录
session.add_all([
Users(name='xiao')
])
session.commit() return render_template('user_list.html')
可以发现,这种操作很麻烦。视图函数每次都需要创建mysql连接!
使用flask_sqlalchemy(推荐)
安装模块flask_sqlalchemy
pip3 install flask_sqlalchemy
修改__init__.py,实例化SQLAlchemy,执行db.init_app(app)
from flask import Flask
from flask_sqlalchemy import SQLAlchemy # 1. 必须放在引入蓝图的上方
db = SQLAlchemy() from lastday.views.account import ac
from lastday.views.user import us def create_app():
"""
创建app应用
:return:
"""
app = Flask(__name__) # 引入配置文件并应用
app.config.from_object("settings.Development") # 2. 执行init_app,读取配置文件SQLAlchemy中相关的配置文件,用于以后:生成数据库/操作数据库(依赖配置文件)
db.init_app(app) # 注册蓝图
app.register_blueprint(ac)
app.register_blueprint(us) app.before_request(b1) # 请求到来之前执行 return app def b1():
print('app_b1')
查看init_app的源码,大量用到了app.config.setdefault
def init_app(self, app):
"""This callback can be used to initialize an application for the
use with this database setup. Never use a database in the context
of an application not initialized that way or connections will
leak.
"""
if (
'SQLALCHEMY_DATABASE_URI' not in app.config and
'SQLALCHEMY_BINDS' not in app.config
):
warnings.warn(
'Neither SQLALCHEMY_DATABASE_URI nor SQLALCHEMY_BINDS is set. '
'Defaulting SQLALCHEMY_DATABASE_URI to "sqlite:///:memory:".'
) app.config.setdefault('SQLALCHEMY_DATABASE_URI', 'sqlite:///:memory:')
app.config.setdefault('SQLALCHEMY_BINDS', None)
app.config.setdefault('SQLALCHEMY_NATIVE_UNICODE', None)
app.config.setdefault('SQLALCHEMY_ECHO', False)
app.config.setdefault('SQLALCHEMY_RECORD_QUERIES', None)
app.config.setdefault('SQLALCHEMY_POOL_SIZE', None)
app.config.setdefault('SQLALCHEMY_POOL_TIMEOUT', None)
app.config.setdefault('SQLALCHEMY_POOL_RECYCLE', None)
app.config.setdefault('SQLALCHEMY_MAX_OVERFLOW', None)
app.config.setdefault('SQLALCHEMY_COMMIT_ON_TEARDOWN', False)
track_modifications = app.config.setdefault(
'SQLALCHEMY_TRACK_MODIFICATIONS', None
)
那么就需要将数据库属性,写到settings.py中
class Base(object):
SECRET_KEY = "fasdfasdf" # session加密字符串 SQLALCHEMY_DATABASE_URI = "mysql+pymysql://root:@127.0.0.1:3306/db1?charset=utf8"
SQLALCHEMY_POOL_SIZE = 5
SQLALCHEMY_POOL_TIMEOUT = 30
SQLALCHEMY_POOL_RECYCLE = -1
# 追踪对象的修改并且发送信号
SQLALCHEMY_TRACK_MODIFICATIONS = False class Product(Base):
"""
线上环境
"""
pass class Testing(Base):
"""
测试环境
"""
DEBUG = False class Development(Base):
"""
开发环境
"""
DEBUG = True # 开启调试
因此,只要执行了db.init_app(app),它就会读取settings.py中的配置信息
修改models.py,引入__init__.py中的db变量,优化代码
from lastday import db # 在数据库创建表一张表
class Users(db.Model):
__tablename__ = 'users' id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(32), index=True, nullable=False) # 在数据库创建表一张表
class School(db.Model):
__tablename__ = 'school' id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(32), index=True, nullable=False)
修改 views-->user.py,导入db,插入一条记录
from flask import Blueprint,render_template
from lastday.models import Users
from lastday import db us = Blueprint('user',__name__) # 蓝图名us @us.route('/user_list/')
def user_list(): # 注意:不要和蓝图名重复
# 添加一条记录
db.session.add(Users(name='xiao'))
db.session.commit() return render_template('user_list.html')
重启 manage.py ,访问用户列表,使用Navicat查看用户表
发现多了一条记录
如果需要关闭连接,使用 db.session.remove()
修改 views-->user.py,在commit下面加一行即可!
但是这样没有必要!为什么?因为在settings.py,使用了数据库连接池。
关闭之后,再次开启一个线程,是需要消耗cpu的。
三、flask离线脚本
前戏
流程图

注意:核心就是配置,通过db对象,操作models,为蓝图提供数据!
现在有一个需求,需要将数据库中的表删除或者生成数据库中的表,必须通过脚本来完成!
配置文件加载之后,将setttings.py中的属性添加到app.config对象中。如果有app对象,那么就可以得到以下信息:
- 应用上下文中的有:app/g
- flask的配置文件:app.config中
- app中包含了:SQLAlchemy相关的数据。
web runtime
启动网站,等待用户请求到来。走 __call__/wsig_app/........
注意:上面这些,必须是flask启动的情况下,才能获取。有一个专有名词,叫做web runtime,翻译过来就是:web 运行时!
它是一个web运行状态。某些操作,必须基于它才能实现!
离线脚本
离线脚本,就是非 web 运行时(web服务器停止)的状态下,也能执行的脚本!
正式开始
先关闭flask项目

在项目根目录创建文件table.py,导入create_app和db,这是关键点
from lastday import create_app,db app = create_app()
with app.app_context():
db.drop_all() # 删除
执行弹出一个警告,这不用管。
查看db1数据库,发现表已经没有了!

修改table.py,执行创建方法
from lastday import create_app,db app = create_app()
with app.app_context():
# db.drop_all() # 删除
db.create_all() # 创建
再次执行,发现表出现了

注意:网站并没有启动,但是实现了删表以及创建表操作!
那么这个with,到底执行了什么呢?查看AppContext源代码,看这2个方法
def __enter__(self):
self.push()
return self def __exit__(self, exc_type, exc_value, tb):
self.pop(exc_value) if BROKEN_PYPY_CTXMGR_EXIT and exc_type is not None:
reraise(exc_type, exc_value, tb)
实际上,with是调用了这2个方法。
写一个类测试一下
class Foo(object):
pass obj = Foo()
with obj:
print(123)
执行报错:
AttributeError: __enter__
提示没有__enter__方法
修改代码,增加__enter__方法
class Foo(object):
def __enter__(self):
pass obj = Foo()
with obj:
print(123)
执行报错:
AttributeError: __exit__
再增加__exit__方法
class Foo(object):
def __enter__(self):
print('__enter__') def __exit__(self, exc_type, exc_val, exc_tb):
print('__exit__') obj = Foo()
with obj:
print(123)
执行输出:
__enter__
123
__exit__
也就是说,在执行print(123)之前,先执行了__enter__方法。之后,执行了__exit__。
之前学习的python基础中,打开文件操作,使用了with open方法,也是一个道理!
在__enter__执行了打开文件句柄操作,在__exit__执行了关闭文件句柄操作!
总结:
以后写flask,要么是web运行时,要么是离线脚本。
应用场景
1. 夜间定时操作数据库的表时
2. 数据导入。比如网站的三级联动功能,将网上下载的全国城市.txt文件,使用脚本导入到数据库中。
还有敏感词,网上都有现成的。下载txt文件后,导入到数据库中。限制某些用户不能发送敏感词的内容!
3. 数据库初始化,比如表的创建,索引创建等等
4. 银行信用卡,到指定月的日期还款提醒。使用脚本将用户的还款日期遍历处理,给用户发送一个短信提醒。每天执行一次!
5. 新写一个项目时,数据库没有数据。用户第一次使用时,无法直接看效果。写一个脚本,自动录入示例数据,方便用户观看!
四、flask多app应用
flask支持多个app应用,那么它们之间,是如何区分的呢?
是根据url前缀来区分,django多app也是通过url前缀来区分的。
由于url都在蓝图中,为蓝图加前缀,使用url_prefix。
语法:
xxx = Blueprint('account',__name__,url_prefix='/xxx')
修改 views-->account.py,增加前缀
from flask import Blueprint
ac = Blueprint('account',__name__,url_prefix='/xxx')
@ac.before_request
def bb():
print('account.bb')
@ac.route('/login')
def login():
return '登陆'
@ac.route('/logout')
def logout():
return '注销'
也可以在__init__.py里面的app.register_blueprint里面加url_prefix,但是不推荐
在项目根目录创建目录other,在里面创建 multi_app.py,不能使用__name__
from flask import Flask
app1 = Flask('app1')
# app1.config.from_object('xxx') # db1
@app1.route('/f1')
def f1():
return 'f1'
app2 = Flask('app2')
# app2.config.from_object('xxx') # db2
@app1.route('/f2')
def f2():
return 'f2'
上面2个应用,可以连接不同的数据库。
目录结构如下:
./
├── lastday
│ ├── __init__.py
│ ├── models.py
│ ├── static
│ │ └── images
│ │ └── meinv.jpg
│ ├── templates
│ │ └── user_list.html
│ └── views
│ ├── account.py
│ └── user.py
├── manage.py
├── other
│ └── multi_app.py
└── settings.py
multi_app.py有2套程序,没有必要写在一起,使用DispatcherMiddleware
查看源码
class DispatcherMiddleware(object):
"""Allows one to mount middlewares or applications in a WSGI application.
This is useful if you want to combine multiple WSGI applications::
app = DispatcherMiddleware(app, {
'/app2': app2,
'/app3': app3
})
"""
def __init__(self, app, mounts=None):
self.app = app
self.mounts = mounts or {}
def __call__(self, environ, start_response):
script = environ.get('PATH_INFO', '')
path_info = ''
while '/' in script:
if script in self.mounts:
app = self.mounts[script]
break
script, last_item = script.rsplit('/', 1)
path_info = '/%s%s' % (last_item, path_info)
else:
app = self.mounts.get(script, self.app)
original_script_name = environ.get('SCRIPT_NAME', '')
environ['SCRIPT_NAME'] = original_script_name + script
environ['PATH_INFO'] = path_info
return app(environ, start_response)
它可以将2个app结合在一起,使用run_simple启动
修改 other\multi_app.py
from flask import Flask
from werkzeug.wsgi import DispatcherMiddleware
from werkzeug.serving import run_simple app1 = Flask('app1')
# app1.config.from_object('xxx') # db1 @app1.route('/f1')
def f1():
return 'f1' app2 = Flask('app2')
# app1.config.from_object('xxx') # db2
@app2.route('/f2')
def f2():
return 'f2' dispachcer = DispatcherMiddleware(app1, {
'/admin':app2, # app2指定前缀admin
}) if __name__ == '__main__':
run_simple('127.0.0.1',8009,dispachcer)
执行multi_app.py,访问url
http://127.0.0.1:8009/f1
效果如下:
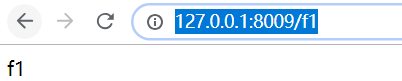
访问f2,会出现404
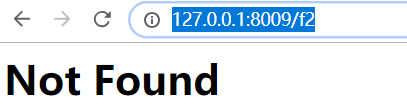
因为它规定了前缀 admin,使用下面访问访问,就不会出错了!

多app应用的场景很少见,了解一下,就可以了!
维护栈的目的
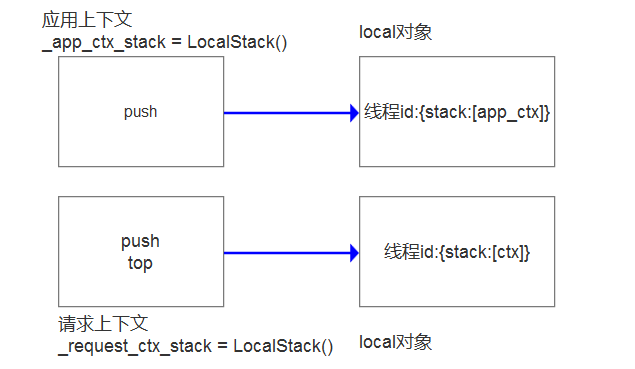
在local对象中,存储的数据是这样的。app_ctx是应用上下文
线程id:{stack:[app_ctx]}
它永远存储的是单条数据,它不是真正的栈。如果搞一个字段,直接让stack=app_ctx,照样可以执行。
那么它为什么要维护一个栈呢?因为它要考虑:
在离线脚本和多app应用的情况下特殊代码的实现。
只有这2个条件满足的情况下,才会用到栈!
web运行时
看上图,是web运行时。本质上,要么开多进程,要么开多线程。那么local对象中维护的栈,永远都只有一条数据。
即使是多app应用,也是一样的。一个请求过来,只能选择一个app。比如上面的f1和f2,要么带前缀,要么不带。带前缀,访问f2,否则访问f1
离线脚本
单app应用
在离线脚本中,单app应用,先来看table.py,它就是离线脚本。
from lastday import create_app,db app = create_app() # app_ctx.push()
with app.app_context():
db.create_all() # 创建
它创建了app_ctx对象,调用了push方法。将数据放到Local对象中,注意:只放了一次!
local的数据,如果是一个字典,大概是这个样子
{
stack:[app_ctx,]
}
多app应用
修改table.py,注意:下面的是伪代码,直接运行会报错
from lastday import create_app,db app1 = create_app1() # db1
app2 = create_app2() # db2 # app_ctx.push()
"""
{
stack:[app1_ctx,]
}
"""
with app1.app_context():
# 取栈中获取栈顶的app_ctx,使用top方法取栈顶
db.create_all() # 创建
如果app1要获取配置文件,从db1种获取
如果加一行代码with呢?
from lastday import create_app,db
from flask import globals app1 = create_app1() # db1
app2 = create_app2() # db2 # app_ctx.push()
"""
{
stack:[app1_ctx,]
}
"""
with app1.app_context():
# 取栈中获取栈顶的app_ctx,使用top方法取栈顶
db.create_all() # 创建 with app2.app_context():
它们都调用了app_context
看globals源码,看最后一行代码
_request_ctx_stack = LocalStack()
_app_ctx_stack = LocalStack()
这2个静态变量,用的是同一个LocalStack(),那么会用同一个Local()。也就是说放到同一个地方去了
修改table.py
from lastday import create_app,db
from flask import globals app1 = create_app1() # db1
app2 = create_app2() # db2 # app_ctx.push()
"""
{
stack:[app1_ctx,app2_ctx,]
}
"""
with app1.app_context():
# 取栈中获取栈顶的app_ctx,使用top方法取栈顶
db.create_all() # 创建 with app2.app_context():
db.create_all()
执行到with这一行时,stack里面有2个对象,分别是app1_ctx和app2_ctx。
那么执行到with下面的db.create_all()时,它会连接哪个数据库?
答案是: 取栈顶的app2_ctx,配置文件是db2
修改 table.py,增加db.drop_all(),它会删除哪个数据库?
from lastday import create_app,db
from flask import globals app1 = create_app1() # db1
app2 = create_app2() # db2 # app_ctx.push()
"""
{
stack:[app1_ctx,app2_ctx,]
}
"""
with app1.app_context():
# 取栈中获取栈顶的app_ctx,使用top方法取栈顶
db.create_all() # 创建 with app2.app_context():
db.create_all() db.drop_all()
答案是:db1
为什么呢?因为执行with时,进来时调用了__enter__方法,将app2_ctx加进去了。此时位于栈顶!
结束时,调用__exit__方法,取栈顶,将app2_ctx给pop掉了!也就是删除!
那么执行db.drop_all()时,此时栈里面只有一个数据app1_ctx,取栈顶,就是app1_ctx
这就它设计使用栈的牛逼之处!
通过栈顶的数据不一样,来完成多app操作!
看下面的动态图,就是栈的变化
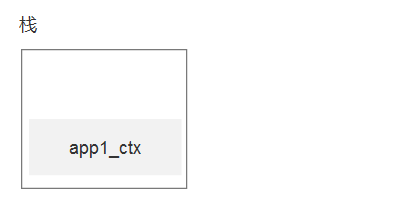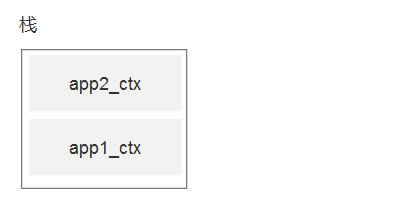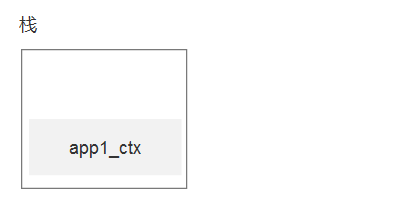
关于flask维护栈的详细信息,请参考链接:
https://blog.csdn.net/u010301542/article/details/78302450
五、flask_script
Flask Script扩展提供向Flask插入外部脚本的功能,包括运行一个开发用的服务器,一个定制的Python shell,设置数据库的脚本,cronjobs,及其他运行在web应用之外的命令行任务;使得脚本和系统分开;
Flask Script和Flask本身的工作方式类似,只需定义和添加从命令行中被Manager实例调用的命令;
官方文档:http://flask-script.readthedocs.io/en/latest/
安装模块
pip3 install flask_script
修改 manage.py
from flask_script import Manager
from lastday import create_app app = create_app()
manager = Manager(app) if __name__ == '__main__':
manager.run()
执行 manage.py,报错
optional arguments:
-?, --help show this help message and exit
是因为不能用原来的方式调用了。
使用以下方式执行
python manage.py runserver -h 127.0.0.1 -p 8009
访问登录页面

自定义命令
flask_script还可以做一些自定义命令,列如:
修改 manage.py
from flask_script import Manager
from lastday import create_app app = create_app()
manager = Manager(app) @manager.command
def c1(arg):
"""
自定义命令login
python manage.py custom 123
:param arg:
:return:
"""
print(arg) @manager.option('-n', '--name', dest='name')
@manager.option('-u', '--url', dest='url')
def c2(name, url):
"""
自定义命令
执行: python manage.py cmd -n wupeiqi -u http://www.oldboyedu.com
:param name:
:param url:
:return:
"""
print(name, url) if __name__ == '__main__':
manager.run()
在终端执行c1命令
python manage.py c1 22
执行输出:22
注意:这里的c1,指的是manage.py中的c1函数
在终端执行c2命令
python manage.py c2 -n 1 -u 9
执行输出:
1 9
以上,可以看到,它和django启动方式很像
六、flask_migrate
flask-migrate是flask的一个扩展模块,主要是扩展数据库表结构的.
官方文档:http://flask-migrate.readthedocs.io/en/latest/
安装模块
pip3 install flask_migrate
使用
修改 manage.py
# 1.1
from flask_script import Manager
# 2.1
from flask_migrate import Migrate, MigrateCommand from lastday import db
from lastday import create_app app = create_app()
# 1.2
manager = Manager(app) # 2.2
Migrate(app, db) # 2.3
"""
# 数据库迁移命名
python manage.py db init
python manage.py db migrate -> makemigrations
python manage.py db upgrade -> migrate
"""
manager.add_command('db', MigrateCommand) @manager.command
def c1(arg):
"""
自定义命令
python manage.py custom 123
:param arg:
:return:
"""
print(arg) @manager.option('-n', '--name', dest='name')
@manager.option('-u', '--url', dest='url')
def c2(name, url):
"""
自定义命令
执行: python manage.py cmd -n wupeiqi -u http://www.oldboyedu.com
:param name:
:param url:
:return:
"""
print(name, url) if __name__ == '__main__':
# python manage.py runserver -h 127.0.0.1 -p 8999
# 1.3
manager.run()
执行init
必须先执行init,只需要执行一次就可以了!
python manage.py db init
它会在项目根目录创建migrations文件夹
执行migrate
python manage.py db migrate
执行upgrade
python manage.py db upgrade
测试
修改 models.py,去掉School中的name属性
from lastday import db # 在数据库创建表一张表
class Users(db.Model):
__tablename__ = 'users' id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(32), index=True, nullable=False) # 在数据库创建表一张表
class School(db.Model):
__tablename__ = 'school' id = db.Column(db.Integer, primary_key=True)
# name = db.Column(db.String(32), index=True, nullable=False)
先执行migrate,再执行upgrade
使用Navicat查看school表,发现name字段没有了!

它是如何实现的呢?在migrations-->versions目录里面,有一个xx.py,它记录的models.py的修改。
那么它和django也是同样,有一个文件记录变化。
那么因此,当flask的插件越装越多时,它和django是一样的
七、pipreqs
介绍
pipreqs可以通过对项目目录的扫描,自动发现使用了那些类库,自动生成依赖清单。缺点是可能会有些偏差,需要检查并自己调整下。
假设一个场景:小a刚去新公司入职。领导让它做2件事情,1. 安装python环境,安装django 2. 看项目代码,一周之后,写需求。
安装django之后,运行项目代码报错了,提示没有安装xx模块!
然后默默的安装了一下xx模块,再次运行,又报错了。再安装....,最后发现安装了30个安装包!
最后再运行,发现还是报错了!不是xx模块问题,是xx语法报错!
这个时候问领导,这些模块,都是什么版本啊?
一般代码上线,交给运维。你要告诉它,这个项目,需要安装xx模块,版本是多少。写一个文件,甩给运维!这样太麻烦了!
为了避免上述问题,出现了pipreps模块,它的作用是: 自动找到程序中应用的包和版本
安装模块
pip3 install pipreqs
使用pipreqs
注意:由于windows默认是gbk编码,必须指定编码为utf-8,否则报错!
E:\python_script\Flask框架\day5\lastday> pipreqs ./ --encoding=utf-8
执行输出:
INFO: Successfully saved requirements file in E:\python_script\Flask框架\day5\lastday\requirements.txt
它会在当前目录中,生成一个requirements.txt文件
查看文件内容
Flask_SQLAlchemy==2.3.2
Flask==1.0.2
左边是模块名,右边是版本
那么有了这个requirements.txt文件,就可以自动安装模块了
pip3 install -r requirements.txt
它会根据文件内容,自动安装!
因此,写python项目时,一定要有requirements.txt文件才行!
github项目也是一样的!
今日内容总结:
内容详细:
1. flask & SQLAlchemy
安装:
flask-sqlalchemy
使用:
a. 在配置文件中设置连接字符串
SQLALCHEMY_DATABASE_URI = "mysql+pymysql://root:@127.0.0.1:3306/s11lastday?charset=utf8"
SQLALCHEMY_POOL_SIZE = 5
SQLALCHEMY_POOL_TIMEOUT = 30
SQLALCHEMY_POOL_RECYCLE = -1
# 追踪对象的修改并且发送信号
SQLALCHEMY_TRACK_MODIFICATIONS = False
b. __init__.py
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
# 1. 必须放在引入蓝图的上方
db = SQLAlchemy()
from lastday.views.user import user
def create_app():
app = Flask(__name__)
app.config.from_object("settings.Development")
# 2. 执行init_app,读取配置文件SQLAlchemy中相关的配置文件,用于以后:生成数据库/操作数据库(依赖配置文件)
db.init_app(app)
app.register_blueprint(user)
return app
c. models.py
from lastday import db
# 在数据库创建表一张表
class Users(db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(32), index=True, nullable=False)
# 在数据库创建表一张表
class School(db.Model):
__tablename__ = 'school'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(32), index=True, nullable=False)
d. 蓝图
from flask import Blueprint,render_template
from lastday.models import Users
from lastday import db
user = Blueprint('user',__name__)
@user.route('/user_list/')
def user_list():
db.session.add(Users(name='王超'))
db.session.commit()
db.session.remove()
return render_template('user_list.html')
疑问:将数据库中的表删除 或 生成数据库中的表。
通过脚本完成。
前戏:
- 应用上下文中的有:app/g
- flask的配置文件:app.config中
- app中包含了:SQLAlchemy相关的数据。
代码:
from lastday import create_app,db
app = create_app()
with app.app_context():
# db.drop_all()
db.create_all()
名词:
web runtime :启动网站,等待用户请求到来。走 __call__/wsig_app/........
离线脚本:
from lastday import create_app,db
app = create_app()
with app.app_context():
# db.drop_all()
db.create_all()
应用场景:
1. 录入基础数据
2. 定时数据处理(定时任务)
赠送:多app应用
from flask import Flask
from werkzeug.wsgi import DispatcherMiddleware
from werkzeug.serving import run_simple
app1 = Flask('app1')
# app1.config.from_object('xxx') # db1
@app1.route('/f1')
def f1():
return 'f1'
app2 = Flask('app2')
# app1.config.from_object('xxx') # db2
@app2.route('/f2')
def f2():
return 'f2'
dispachcer = DispatcherMiddleware(app1, {
'/admin':app2,
})
if __name__ == '__main__':
run_simple('127.0.0.1',8009,dispachcer)
问题:为什么Flask中要在上下文管理中将Local中的数据:ctx/app_ctx维护成一个栈?
应用flask要考虑,在离线脚本和多app应用的情况下特殊代码的实现。
在web运行时中:Local对象中维护的栈 [ctx, ]
在离线脚本中:
- 单app应用:
from lastday import create_app,db
app = create_app()
# app_ctx.push()
"""
{
stack:[app_ctx, ]
}
"""
with app.app_context():
db.create_all()
- 多app应用:
from lastday import create_app,db
app1 = create_app1() # db1
app2 = create_app2() # db2
from flask import globals
# app_ctx.push()
"""
{
stack:[app1_ctx,app2_ctx ]
}
"""
with app1.app_context():
# 去栈中获取栈顶的app_ctx: app1_ctx,配置文件:db1
db.create_all()
with app2.app_context():
db.create_all() # 去栈中获取栈顶的app_ctx: app2_ctx,配置文件:db2
db.drop_all() # 去栈中获取栈顶的app_ctx: app1_ctx,配置文件:db1
总结:
1. flask-sqlalchemy,帮助用户快速实现Flask中应用SQLAlchemy
2. 多app应用
3. 离线脚本
4. 为什么Flask中要在上下文管理中将Local中的数据:ctx/app_ctx维护成一个栈?
- 离线脚本+多app应用才会在栈中存多个上下文对象: [ctx1,ctx2,]
- 其他:[ctx, ]
2. flask-script
安装:flask-script
作用:制作脚本启动
3. flask-migrate(依赖flask-script )
安装:flask-migrate
使用:
# 1.1
from flask_script import Manager
# 2.1
from flask_migrate import Migrate, MigrateCommand
from lastday import db
from lastday import create_app
app = create_app()
# 1.2
manager = Manager(app)
# 2.2
Migrate(app, db)
# 2.3
"""
# 数据库迁移命名
python manage.py db init
python manage.py db migrate -> makemigrations
python manage.py db upgrade -> migrate
"""
manager.add_command('db', MigrateCommand)
@manager.command
def c1(arg):
"""
自定义命令
python manage.py custom 123
:param arg:
:return:
"""
print(arg)
@manager.option('-n', '--name', dest='name')
@manager.option('-u', '--url', dest='url')
def c2(name, url):
"""
自定义命令
执行: python manage.py cmd -n wupeiqi -u http://www.oldboyedu.com
:param name:
:param url:
:return:
"""
print(name, url)
if __name__ == '__main__':
# python manage.py runserver -h 127.0.0.1 -p 8999
# 1.3
manager.run()
4. pipreqs
安装:pipreqs
作用:自动找到程序中应用的包和版本。
pipreqs ./ --encoding=utf-8
pip3 install -r requirements.txt
重点:
1. 使用(*)
- flask-sqlalchemy
- flask-migrate
- flask-script
2. flask上下文相关 (*****)
- 对象关键字:LocalStack、Local
- 离线脚本 & web 运行时
- 多app应用
- Local中为什么维护成栈?
python 全栈开发,Day142(flask标准目录结构, flask使用SQLAlchemy,flask离线脚本,flask多app应用,flask-script,flask-migrate,pipreqs)的更多相关文章
- python全栈开发学习_内容目录及链接
python全栈开发学习_day1_计算机五大组成部分及操作系统 python全栈开发学习_day2_语言种类及变量 python全栈开发_day3_数据类型,输入输出及运算符 python全栈开发_ ...
- python 全栈开发,Day48(标准文档流,块级元素和行内元素,浮动,margin的用法,文本属性和字体属性)
昨日内容回顾 高级选择器: 后代选择 : div p 子代选择器 : div>p 并集选择器: div,p 交集选择器: div.active 属性选择器: [属性~='属性值'] 伪类选择器 ...
- Win10构建Python全栈开发环境With WSL
目录 Win10构建Python全栈开发环境With WSL 启动WSL 总结 对<Dev on Windows with WSL>的补充 Win10构建Python全栈开发环境With ...
- Python 全栈开发【第0篇】:目录
Python 全栈开发[第0篇]:目录 第一阶段:Python 开发入门 Python 全栈开发[第一篇]:计算机原理&Linux系统入门 Python 全栈开发[第二篇]:Python基 ...
- python全栈开发目录
python全栈开发目录 Linux系列 python基础 前端~HTML~CSS~JavaScript~JQuery~Vue web框架们~Django~Flask~Tornado 数据库们~MyS ...
- Python全栈开发【模块】
Python全栈开发[模块] 本节内容: 模块介绍 time random os sys json & picle shelve XML hashlib ConfigParser loggin ...
- python全栈开发中级班全程笔记(第二模块、第四章)(常用模块导入)
python全栈开发笔记第二模块 第四章 :常用模块(第二部分) 一.os 模块的 详解 1.os.getcwd() :得到当前工作目录,即当前python解释器所在目录路径 impor ...
- Python全栈开发【面向对象进阶】
Python全栈开发[面向对象进阶] 本节内容: isinstance(obj,cls)和issubclass(sub,super) 反射 __setattr__,__delattr__,__geta ...
- Python全栈开发【面向对象】
Python全栈开发[面向对象] 本节内容: 三大编程范式 面向对象设计与面向对象编程 类和对象 静态属性.类方法.静态方法 类组合 继承 多态 封装 三大编程范式 三大编程范式: 1.面向过程编程 ...
随机推荐
- 即将上线的Kafka 集群(用CM部署的)无法使用“--bootstrap-server”进行消费,怎么破?
即将上线的Kafka 集群(用CM部署的)无法使用“--bootstrap-server”进行消费,怎么破? 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.报错:org.a ...
- 基于报错的SQL注入整理
SQLServer 一.利用错误消息提取信息 输入 'having 1=1 --(having一般要与group by一起来使用,group by是用来进行分组的,having后面是用来进行判断的), ...
- 安卓中location.href或者location.reload 不起作用
链接:https://www.cnblogs.com/joshua317/p/6163471.html 在移动wap中,经常会使用window.location.href去跳转页面,这个方法在绝大多数 ...
- luogu P3760 [TJOI2017]异或和
传送门 对于每个二进制位考虑有多少区间和这一位上为1 从前往后扫每个前缀和,如果当前这个前缀和某一个二进制位上为1,因为区间和由这个前缀和减去前面的前缀和得来,如果减去了这一位为0的前缀和,那么 减去 ...
- NSURLResponse下载
// // ViewController.m // 05-NSURLConnestion(下载) // // Created by jerry on 15/10/24. // Copyright (c ...
- java 多线程二
java 多线程一 java 多线程二 java 多线程三 java 多线程四 线程中断: /** * Created by root on 17-9-30. */ public class Test ...
- Jetson tk1 安装 Intel 7260 无线网卡驱动
Jseton TK1上没有集成的无线网卡,开发板上有一个mini pci-e接口,可以插入Intel 7260这款继承了wifi和蓝牙功能的无线网卡: 该网卡实物如下图,在淘宝和Amazon上都可以买 ...
- 一份通过IPC$和lpk.dll感染方式的病毒分析报告
样本来自52pojie论坛,从事过两年渗透开始学病毒分析后看到IPC$真是再熟悉不过. 1.样本概况 1.1 样本信息 病毒名称:3601.exe MD5值:96043b8dcc7a977b16a28 ...
- 一文看懂汽车电子ECU bootloader工作原理及开发要点
随着半导体技术的不断进步(按照摩尔定律),MCU内部集成的逻辑功能外设越来越多,存储器也越来越大.消费者对于汽车节能(经济和法规对排放的要求)型.舒适性.互联性.安全性(功能安全和信息安全)的要求越来 ...
- ARMV8 datasheet学习笔记1:预备知识
1. 前言 ARMv8的架构继承以往ARMv7与之前处理器技术的基础; 除了支持现有的16/32bit的Thumb2指令外,也向前兼容现有的A32(ARM 32bit)指令集. 基于64bit的AAr ...