K近邻(K Nearest Neighbor-KNN)原理讲解及实现
算法原理
K最近邻(k-Nearest Neighbor)算法是比较简单的机器学习算法。它采用测量不同特征值之间的距离方法进行分类。它的思想很简单:如果一个样本在特征空间中的k个最近邻(最相似)的样本中的大多数都属于某一个类别,则该样本也属于这个类别。第一个字母k可以小写,表示外部定义的近邻数量。
举例说明
首先我们准备一个数据集,这个数据集很简单,是由二维空间上的4个点构成的一个矩阵,如表1所示:
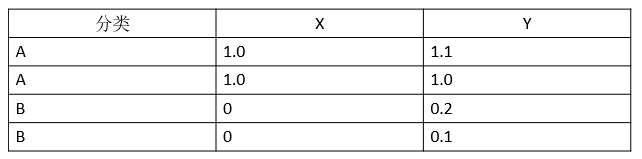
表1:训练集
其中前两个点构成一个类别A,后两个点构成一个类别B。我们用Python把这4个点在坐标系中绘制出来,如图1所示:

图1:训练集绘制
绘制所用的代码如下:
# -*- encoding:utf-8-* -
from numpy import *
import matplotlib.pyplot as plt def createDataSet():
dataSet = array([[1.0, 1.1], [1.0, 1.0], [0, 0.2], [0, 0.1]]) # 数据集
labels = ['A', 'A', 'B', 'B'] # 数据集对应的类别标签
return dataSet, labels dataSet, labels = createDataSet()
# 显示数据集信息
fig = plt.figure()
ax = fig.add_subplot(111)
indx = 0
for point in dataSet:
if labels[indx] == 'A':
ax.scatter(point[0], point[1], c='blue', marker='o', linewidths=0, s=300)
plt.annotate("("+str(point[0])+","+str(point[1])+")", xy=(point[0], point[1]))
else:
ax.scatter(point[0], point[1], c='red', marker='^', linewidths=0, s=300)
plt.annotate("("+str(point[0])+","+str(point[1])+")", xy=(point[0], point[1]))
indx += 1
plt.show()
从图形中可以清晰地看到由4个点构成的训练集。该训练集被分为两个类别:A类——蓝色圆圈,B类——红色三角形。因为红色区域内的点距比它们到蓝色区域内的点距要小的多,这种分类也很自然。
下面我们给出测试集,只有一个点,我们把它加入到刚才的矩阵中去,如表2所示:

表2:加入了一个训练样本
我们想知道给出的这个测试集应该属于哪个分类,最简单的方法还是画图,我们把新加入的点加入图中,图2很清晰,从距离上看,它更接近红色三角形的范围,应该归于B类,这就是KNN算法的基本原理。
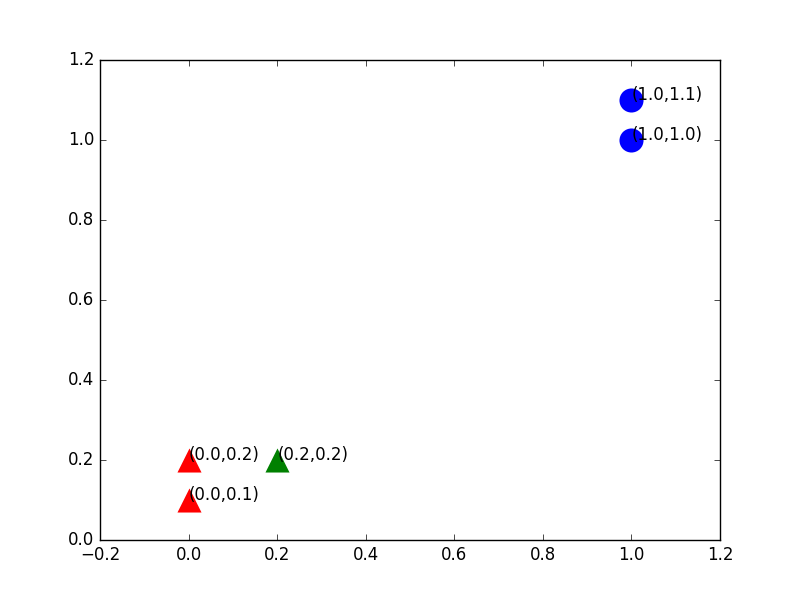
图2:加入一个训练样本后绘制
在上述代码的基础上,绘制测试样本点的代码如下:
# 显示即将需要测试的数据信息
testdata = [0.2, 0.2]
ax.scatter(testdata[0], testdata[1], c='green', marker='^', linewidths=0, s=300)
plt.annotate("(" + str(testdata[0]) + "," + str(testdata[1]) + ")", xy=(testdata[0], testdata[1]))
plt.show()
算法实现
综上所述,KNN算法应由以下步骤构成。
第一阶段:确定k值(就是指最近邻居的个数)。一般是一个奇数,因为测试样本有限,故取值为3。
第二阶段:确定距离度量公式。文本分类一般使用夹角余弦,得出待分类数据点和所有已知类别的样本点,从中选择距离最近的k个样本。
夹角余弦:
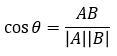
第三阶段:统计这k个样本点中各个类别的数量。上例中我们选定k值为3,则B类样本(三角形)有2个,A类样本(圆形)有 1个,那么我们就把这个方形数据点定位B类;即,根据k个样本中数量最多的样本是什么类别,我们就把这个数据点定为什么类别。
实现代码如下:
from numpy import *
import operator # 产生数据集
def createDataSet():
dataSet = array([[1.0, 1.1], [1.0, 1.0], [0, 0.2], [0, 0.1]]) # 数据集
labels = ['A', 'A', 'B', 'B'] # 数据集对应的类别标签
return dataSet, labels # 夹角余弦距离公式
def cosdist(vector1, vector2):
return dot(vector1, vector2) / (linalg.norm(vector1) * linalg.norm(vector2)) # KNN 分类器
# 测试集:testdata; 训练集:trainSet;类别标签:listClasses;k: k个邻居数
def classify(testdata, trainSet, listClasses, k):
dataSetSize = trainSet.shape[0] # 返回样本集的行数
distances = array(zeros(dataSetSize))
for indx in xrange(dataSetSize): # 计算测试集与训练集之间的距离:夹角余弦
distances[indx] = cosdist(testdata, trainSet[indx])
# 根据生成的夹角余弦按从小到大排序,结果为索引号
sortedDistIndicies = argsort(distances)
classCount = {}
for i in range(k):
# 按排序顺序返回样本集对应的类别标签
voteIlabel = listClasses[sortedDistIndicies[i]]
# 为字典classCount赋值,相同的key,value加1
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
# sorted():按字典值进行排序,返回list
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0] # dataSet:测试数据集
# labels:测试数据集对应的标签
dataSet, labels = createDataSet()
testdata = [0.2, 0.2]
k = 3 # 选取最近的K个样本进行类别判定
# 判定testdata类别,输出类别结果
print "label is: " + classify(testdata, dataSet, labels, k)
输出:“label is: B“
K近邻(K Nearest Neighbor-KNN)原理讲解及实现的更多相关文章
- k近邻法(k-nearest neighbor, k-NN)
一种基本分类与回归方法 工作原理是:1.训练样本集+对应标签 2.输入没有标签的新数据,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最相似数据(最近邻)的分类标签. 3.一般 ...
- K近邻(k-Nearest Neighbor,KNN)算法,一种基于实例的学习方法
1. 基于实例的学习算法 0x1:数据挖掘的一些相关知识脉络 本文是一篇介绍K近邻数据挖掘算法的文章,而所谓数据挖掘,就是讨论如何在数据中寻找模式的一门学科. 其实人类的科学技术发展的历史,就一直伴随 ...
- 机器学习分类算法之K近邻(K-Nearest Neighbor)
一.概念 KNN主要用来解决分类问题,是监督分类算法,它通过判断最近K个点的类别来决定自身类别,所以K值对结果影响很大,虽然它实现比较简单,但在目标数据集比例分配不平衡时,会造成结果的不准确.而且KN ...
- 《机实战》第2章 K近邻算法实战(KNN)
1.准备:使用Python导入数据 1.创建kNN.py文件,并在其中增加下面的代码: from numpy import * #导入科学计算包 import operator #运算符模块,k近邻算 ...
- k 近邻算法(k-Nearest Neighbor,简称kNN)
预约助教问题: 1.计算1-NN,k-nn和linear regression这三个算法训练和查询的时间复杂度和空间复杂度? 一. WHy 最简单最初级的分类器是将全部的训练数据所对应的类别都记录下来 ...
- k近邻法( k-nearnest neighbor)
基本思想: 给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,这k个实例的多数属于某个类,就把该输入实例分为这个类 距离度量: 特征空间中两个实例点的距离是两个实例点相似 ...
- 第三章 K近邻法(k-nearest neighbor)
书中存在的一些疑问 kd树的实现过程中,为何选择的切分坐标轴要不断变换?公式如:x(l)=j(modk)+1.有什么好处呢?优点在哪?还有的实现是通过选取方差最大的维度作为划分坐标轴,有何区别? 第一 ...
- KNN (K近邻算法) - 识别手写数字
KNN项目实战——手写数字识别 1. 介绍 k近邻法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法.它的工作原理是:存在一个 ...
- 统计学习三:1.k近邻法
全文引用自<统计学习方法>(李航) K近邻算法(k-nearest neighbor, KNN) 是一种非常简单直观的基本分类和回归方法,于1968年由Cover和Hart提出.在本文中, ...
随机推荐
- Linux安装模式AppImage,Flatpak,Snap整理
本文只谈Linux世界用户较多的前2大主要分支, RedHat Red Hat Enterprise Linux 简称RHEL rpm (RedHat, CentOS, Fedora, Oracle. ...
- 计算x
如果x的x次幂结果为10(参见[图1.png]),你能计算出x的近似值吗? 显然,这个值是介于2和3之间的一个数字. 请把x的值计算到小数后6位(四舍五入),并填写这个小数值. 注意:只填写一个小数, ...
- (4)django的新手三件套(返回页面、返回字符、重定向)
from django.shortcuts import render,HttpResponse,redirect 新手三件套,前期开发都会用到 render #向浏览器返回页面 HttpResp ...
- tomcat部署项目(war文件)
首先配置jdk环境 下载jdk 例如,我将jdk安装在d盘jdk目录下 配置系统环境 新建系统变量JAVA_HOME值为D:\jdk 新建系统变量CLASS_HOME值为 .%JAVA_HOME%\l ...
- goreplay 输出流量捕获数据到 elasticsearch
goreplay 是一个很不错的流量拷贝,复制工具,小巧,支持一些扩展,当然也提供了企业版,企业版 功能更强大,支持二进制协议的分析 . 为了方便数据的存储,我们可以使用es 进行存储 环境准备 do ...
- Go语言编程 (许式伟 等 著)
第1章 初识Go语言 1.1 语言简史 1.2 语言特性 1.2.1 自动垃圾回收 1.2.2 更丰富的内置类型 1.2.3 函数多返回值 1.2.4 错误处理 1.2.5 匿名函数和闭包 1.2.6 ...
- S老师 Top-Down RPG Starter Kit 学习
character creation using UnityEngine; using System.Collections; public class CharacterCreation : Mon ...
- 配置B类内网 和 配置A类内网
首先 A 类网 对应的 子网掩码是255.0.0.0 B 类网 对应的 子网掩码是255.255.0.0 C 类网 对应的 子网掩码是255.255.255.0 一般来说 10 开头的都是 A 类网 ...
- nonzero
在python的numpy里面这个函数的意义是返回参数数组中不为0的元素的索引(indics). from numpy import array from numpy import nonzero x ...
- java-shiro登录验证
登录验证: LoginController:(LoginController.java) @ResponseBody @RequestMapping(value="/login", ...