R语言学习——根据信息熵建决策树KD3
R语言代码
决策树的构建
rm(list=ls())
setwd("C:/Users/Administrator/Desktop/R语言与数据挖掘作业/实验3-决策树分类") #save print
sink("tree1.txt") inputfile=read.csv(file="./bank-data.csv",header=TRUE) #age
for(i in 1:length(inputfile$age))
inputfile$age[i]=ifelse(inputfile$age[i]<30,"<=30",
ifelse(inputfile$age[i]<40,"31-40",">=40")) # sub=which(is.na(inputfile$age))
# inputfile=inputfile[-sub,]
#
# sub=which(is.na(inputfile$sex))
# inputfile=inputfile[-sub,]
#
# sub=which(is.na(inputfile$region))
# inputfile=inputfile[-sub,] sub=which(is.na(inputfile$income))
inputfile=inputfile[-sub,] # sub=which(is.na(inputfile$married))
# inputfile=inputfile[-sub,]
#
# sub=which(is.na(inputfile$children))
# inputfile=inputfile[-sub,]
#
# sub=which(is.na(inputfile$car))
# inputfile=inputfile[-sub,]
#
# sub=which(is.na(inputfile$save_act))
# inputfile=inputfile[-sub,]
#
# sub=which(is.na(inputfile$current_act))
# inputfile=inputfile[-sub,]
#
# sub=which(is.na(inputfile$mortgage))
# inputfile=inputfile[-sub,]
#
# sub=which(is.na(inputfile$pep))
# inputfile=inputfile[-sub,]
# #income
for (i in 1:length(inputfile$income))
inputfile$income[i]=ifelse(inputfile$income[i]<12640.3,1,
ifelse(inputfile$income[i]<17390.1,2,
ifelse(inputfile$income[i]<29622,3,
ifelse(inputfile$income[i]<43228.2,4,5))))
#id
inputfile$id=NULL #拆分数据
train_data=inputfile[1:500,]
print(length(train_data))
as.data.frame(train_data)
write.csv(train_data,file = "train_data.csv",row.names = FALSE) test_data=inputfile[-100,]
print(length(test_data))
as.data.frame(test_data)
write.csv(test_data,file = "test_data.csv",row.names = FALSE) #计算信息熵
calcent<-function(data){
nument<-length(data[,1])#
key<-rep("a",nument)#初始化key #把标签存到key
for(i in 1:nument)
key[i]<-data[i,length(data)] ent<-0
prob<-table(key)/nument#table[key]=[272,228]代表272个1,228个2
#print(prob)
#print(prob[1])
for(i in 1:length(prob))
ent=ent-prob[i]*log(prob[i],2)
#print(str(ent))
return(ent)
} calcent(train_data) #分数据用
split<-function(data,variable,value){
result<-data.frame()
for(i in 1:length(data[,1])){
if(data[i,variable]==value)
result<-rbind(result,data[i,-variable])
}
return(result)
} #选择第几列为最佳划分
choose<-function(data){
numvariable<-length(data[1,])-1 #10个属性
#print("baseent")
baseent<-calcent(data)
#print(baseent)
bestinfogain<-0
bestvariable<-0
infogain<-0
featlist<-c()
uniquevals<-c()
for(i in 1:numvariable)#遍历每一个属性
{ featlist<-data[,i]#获得这一列所有属性
uniquevals<-unique(featlist)#去掉重复项,eg:对于age:uniquevals=[">=40" "<=30" "31-40"]
#print("uniquevals")
#print(uniquevals)
newent<-0
for(j in 1:length(uniquevals))#遍历该属性的每一个值
{
subset<-split(data,i,uniquevals[j])#调用自己写的split函数,把第i列为uniquevals[j]的都挑出来放到subset中
#print(subset)
prob<-length(subset[,1])/length(data[,1])
newent<-newent+prob*calcent(subset)
}
infogain<-baseent-newent
if(infogain>bestinfogain)
{
bestinfogain<-infogain
bestvariable<-i
}
}
return(bestvariable)
} choose(train_data) # #设置决策树分裂条件
# can_stop<-function(data)
# {
# if(length(data)>50) return(FALSE)
# yes_num<-0
# no_num<-0
# for(i in 1:length(data))
# {
# #print(data[i,length(data[i])])
# if(data[i,length(data[i])]=="YES") yes_num=yes_num+1
# else if(data[i,length(data[i])]=="NO")
# {
# no_num=no_num+1
# }
# }
# if(abs(yes_num-no_num)>5) return(TRUE)#最终的叶子的纯净度
# return(FALSE)
#
# } is_or_no<-function(data)
{
yes_num<-0
no_num<-0
for(i in 1:length(data))
{
#if(is.null(data[i,length(data[i])])) {next}
if(is.na(data[i,length(data[i])])) {next}
if(data$pep[i]=="YES") yes_num=yes_num+1
else if(data$pep[i]=="NO")
{
no_num=no_num+1
}
}
#print("yes_num")
#print(yes_num)
#print("no_num")
#print(no_num)
if(yes_num>no_num) return("")#111代表这一类基本都是YES
return("")#111代表这一类基本都是NO
} #建树
bulidtree<-function(data){
choose_data<-choose(data)
if(choose_data==0)
print("finish")
else
{
#print(choose_data)
print(colnames(data)[choose_data])
level<-unique(data[,choose_data])
print(level)
#输出属性名
#print("length(level)")
print(length(level))
if(length(level)==1)#如果种类只有一个了,那就停止
print("finish")
else
for(i in 1:length(level))
{
data1<-split(data,choose_data,level[i])
#print(data1)
if(length(data1)<10){ #通过对10这个数字的更改可以调整决策树的大小和深度
print("finish")#设置结束函数
#print(length(data1))
if(length(data1)!=0)
{
print(is_or_no(data1))
}
}
else
bulidtree(data1)
}
}
} bulidtree(train_data)
sink()
输出结果会在当前工作台下的tree1.txt文件中
如图所示:
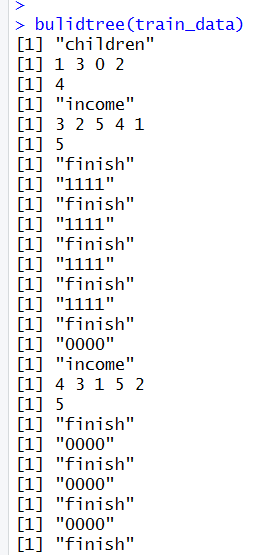
对输出结果的解释:
第一个挑出的是“children”这个属性,然后根据这个属性的1 3 0 2下设四个分支,其中1这个分支挑出的属性是“income”,下设3 2 5 4 1折5个分支,其中3这个分支停止了,为“111”,就是“YES”(“000”代表预测值为“NO”)
如草图:
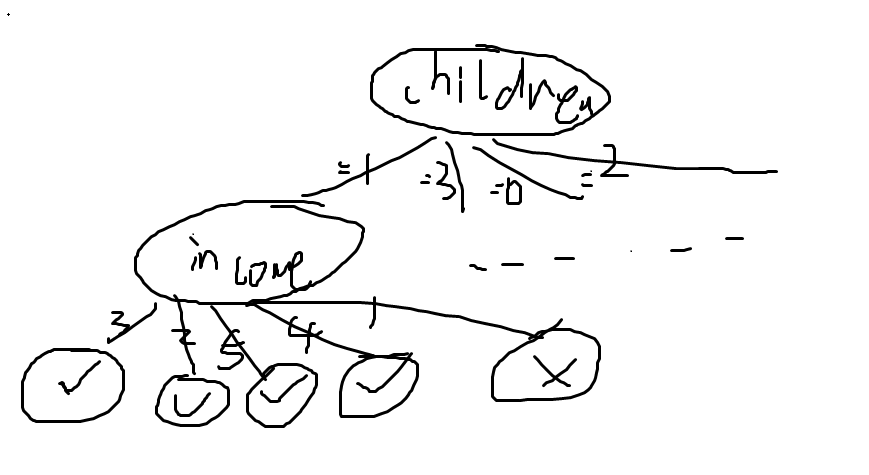
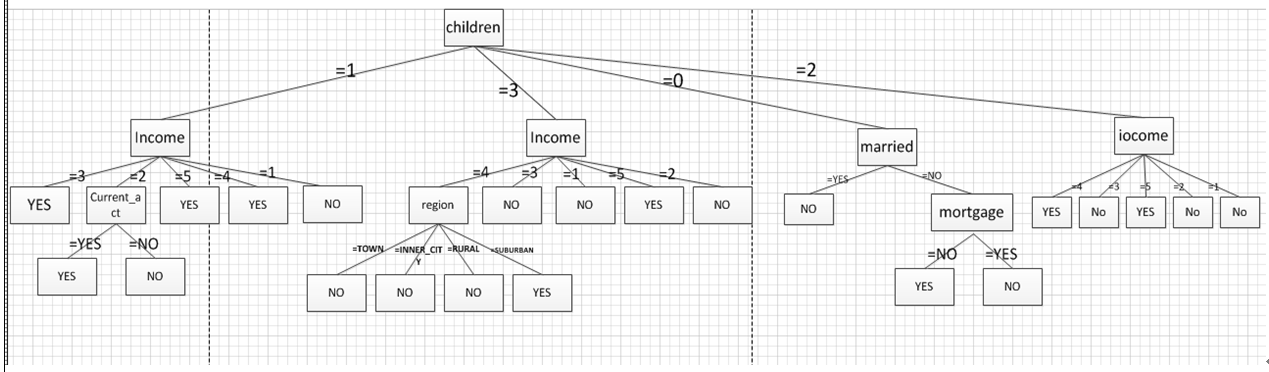
以此类推,就可以画出整棵树了。
一、KD3的想法与实现
下面我们就要来解决一个很重要的问题:如何构造一棵决策树?这涉及十分有趣的细节。
先说说构造的基本步骤,一般来说,决策树的构造主要由两个阶段组成:第一阶段,生成树阶段。选取部分受训数据建立决策树,决策树是按广度优先建立直到每个叶节点包括相同的类标记为止。第二阶段,决策树修剪阶段。用剩余数据检验决策树,如果所建立的决策树不能正确回答所研究的问题,我们要对决策树进行修剪直到建立一棵正确的决策树。这样在决策树每个内部节点处进行属性值的比较,在叶节点得到结论。从根节点到叶节点的一条路径就对应着一条规则,整棵决策树就对应着一组表达式规则。
问题:我们如何确定起决定作用的划分变量。
我还是用鸢尾花的例子来说这个问题思考的必要性。使用不同的思考方式,我们不难发现下面的决策树也是可以把鸢尾花分成3类的。
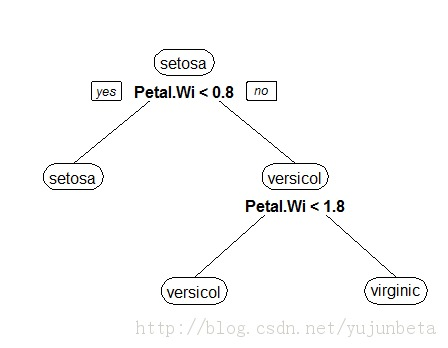
为了找到决定性特征,划分出最佳结果,我们必须认真评估每个特征。通常划分的办法为信息增益和基尼不纯指数,对应的算法为C4.5和CART。
关于信息增益和熵的定义烦请参阅百度百科,这里不再赘述。
直接给出计算熵与信息增益的R代码:
1、 计算给定数据集的熵
calcent<-function(data){
nument<-length(data[,1])
key<-rep("a",nument)
for(i in 1:nument)
key[i]<-data[i,length(data)]
ent<-0
prob<-table(key)/nument
for(i in 1:length(prob))
ent=ent-prob[i]*log(prob[i],2)
return(ent)
}
我们这里把最后一列作为衡量熵的指标,例如数据集mudat(自己定义的)
> mudat
x y z
1 1 1 y
2 1 1 y
3 1 0 n
4 0 1 n
5 0 1 n
计算熵
> calcent(mudat)
1
0.9709506
熵越高,混合的数据也越多。得到熵之后,我们就可以按照获取最大信息增益的方法划分数据集
2、 按照给定特征划分数据集
为了简单起见,我们仅考虑标称数据(对于非标称数据,我们采用划分的办法把它们化成标称的即可)。
R代码:
split<-function(data,variable,value){
result<-data.frame()
for(i in 1:length(data[,1])){
if(data[i,variable]==value)
result<-rbind(result,data[i,-variable])
}
return(result)
}
这里要求输入的变量为:数据集,划分特征变量的序号,划分值。我们以前面定义的mudat为例,以“X”作为划分变量,划分得到的数据集为:
> split(mudat,1,1)
y z
1 1 y
2 1 y
3 0 n
> split(mudat,1,0)
y z
4 1 n
5 1 n
3、选择最佳划分(基于熵增益)
choose<-function(data){
numvariable<-length(data[1,])-1
baseent<-calcent(data)
bestinfogain<-0
bestvariable<-0
infogain<-0
featlist<-c()
uniquevals<-c()
for(i in 1:numvariable){
featlist<-data[,i]
uniquevals<-unique(featlist)
newent<-0
for(j in 1:length(uniquevals)){
subset<-split(data,i,uniquevals[j])
prob<-length(subset[,1])/length(data[,1])
newent<-newent+prob*calcent(subset)
}
infogain<-baseent-newent
if(infogain>bestinfogain){
bestinfogain<-infogain
bestvariable<-i
}
}
return(bestvariable)
}
函数choose包含三个部分,第一部分:求出一个分类的各种标签;第二部分:计算每一次划分的信息熵;第三部分:计算最好的信息增益,并返回分类编号。
我们以上面的简易例子mudat为例,计算划分,有:
> choose(mudat)
[1] 1
也就是告诉我们,将第一个变量值为1的分一类,变量值为0的分为另一类,得到的划分是最好的。
4、 递归构建决策树
我们以脊椎动物数据集为例,这个例子来自《数据挖掘导论》,具体数据集已上传至百度云盘(点击可下载)
我们先忽略建树细节,由于数据变量并不大,我们手动建一棵树先。
>animals<-read.csv("D:/R/data/animals.csv")
>choose(animals)
[1] 1
这里变量1代表names,当然是一个很好的分类,但是意义就不大了,我们暂时的解决方案是删掉名字这一栏,继续做有:
>choose(animals)
[1] 4
我们继续重复这个步骤,直至choose分类为0或者没办法分类(比如sometimes
live in water的动物)为止。得到最终分类树。
给出分类逻辑图(遵循多数投票法):
至于最后的建树画图涉及R的绘图包ggplot,这里不再给出细节。
下面我们使用著名数据集——隐形眼镜数据集,利用上述的想法实现一下决策树预测隐形眼镜类型。这个例子来自《机器学习实战》,具体数据集已上传至百度云盘(点击可下载)。
下面是一个十分简陋的建树程序(用R实现的),为了叙述方便,我们给隐形眼镜数据名称加上标称:age,prescript,astigmatic,tear rate.
建树的R程序简要给出如下:
bulidtree<-function(data){
if(choose(data)==0)
print("finish")
else{
print(choose(data))
level<-unique(data[,choose(data)])
if(level==1)
print("finish")
else
for(i
in1:length(level)){
data1<-split(data,choose(data),level[i])
if(length(data1)==1)print("finish")
else
bulidtree(data1)
}
}
}
运行结果:
>bulidtree(lenses)
[1] 4
[1]"finish"
[1] 3
[1] 1
[1]"finish"
[1]"finish"
[1] 1
[1]"finish"
[1]"finish"
[1] 2
[1]"finish"
[1] 1
[1]"finish"
[1]"finish"
[1]"finish"
这棵树的解读有些麻烦,因为我们没有打印标签,(程序的简陋总会带来这样,那样的问题,欢迎帮忙完善),人工解读一下:
首先利用4(tear
rate)的特征reduce,normal将数据集划分为nolenses(至此完全分类),normal的情况下,根据3(astigmatic)的特征no,yes分数据集(划分顺序与因子在数据表的出现顺序有关),no这条分支上选择1(age)的特征pre,young,presbyopic划分,前两个得到结果soft,最后一个利用剩下的一个特征划分完结(这里,由于split函数每次调用时,都删掉了一个特征,所以这里的1是实际第二个变量,这个在删除变量是靠前的情形时要注意),yes这条分支使用第2个变量prescript作为特征划分my ope划分完结,hyper利用age进一步划分,得到最终分类。
R语言学习——根据信息熵建决策树KD3的更多相关文章
- R语言学习 第四篇:函数和流程控制
变量用于临时存储数据,而函数用于操作数据,实现代码的重复使用.在R中,函数只是另一种数据类型的变量,可以被分配,操作,甚至把函数作为参数传递给其他函数.分支控制和循环控制,和通用编程语言的风格很相似, ...
- R语言学习笔记—决策树分类
一.简介 决策树分类算法(decision tree)通过树状结构对具有某特征属性的样本进行分类.其典型算法包括ID3算法.C4.5算法.C5.0算法.CART算法等.每一个决策树包括根节点(root ...
- R语言学习笔记之: 论如何正确把EXCEL文件喂给R处理
博客总目录:http://www.cnblogs.com/weibaar/p/4507801.html ---- 前言: 应用背景兼吐槽 继续延续之前每个月至少一次更新博客,归纳总结学习心得好习惯. ...
- R语言学习路线和常用数据挖掘包(转)
对于初学R语言的人,最常见的方式是:遇到不会的地方,就跑到论坛上吼一嗓子,然后欣然or悲伤的离去,一直到遇到下一个问题再回来.当然,这不是最好的学习方式,最好的方式是——看书.目前,市面上介绍R语言的 ...
- R语言学习笔记(二)
今天主要学习了两个统计学的基本概念:峰度和偏度,并且用R语言来描述. > vars<-c("mpg","hp","wt") &g ...
- R语言学习笔记:小试R环境
买了三本R语言的书,同时使用来学习R语言,粗略翻下来感觉第一本最好: <R语言编程艺术>The Art of R Programming <R语言初学者使用>A Beginne ...
- R语言学习 第一篇:变量和向量
R是向量化的语言,最突出的特点是对向量的运算不需要显式编写循环语句,它会自动地应用于向量的每一个元素.对象是R中存储数据的数据结构,存储在内存中,通过名称或符号访问.对象的名称由大小写字母.数字0-9 ...
- R语言学习笔记:基础知识
1.数据分析金字塔 2.[文件]-[改变工作目录] 3.[程序包]-[设定CRAN镜像] [程序包]-[安装程序包] 4.向量 c() 例:x=c(2,5,8,3,5,9) 例:x=c(1:100) ...
- R语言学习笔记:使用reshape2包实现整合与重构
R语言中提供了许多用来整合和重塑数据的强大方法. 整合 aggregate 重塑 reshape 在整合数据时,往往将多组观测值替换为根据这些观测计算的描述统计量. 在重塑数据时,则会通过修改数据的结 ...
随机推荐
- Django book manage system
创建一个简易的可以增删改查book的书籍管理system urls.py from django.contrib import admin from django.urls import re_pat ...
- 最小生成树&&最大生成树模板
#include<bits/stdc++.h> using namespace std; int n,m; struct edge { int x; int y; int len; }ed ...
- 【Jmeter】分布式并发测试
一.前提: 1.最近在做一下压测,但是单台服务器的CPU,内存可能不够支撑压测的项目,这时候,我们可以使用Jmeter分布式压测. 2.本次使用的环境: 1台服务器做master(调度器) 5台服务器 ...
- Go Example--Hello
Hello world package main import "fmt" //通过import导入fmt标准包 func main() { //语句结尾不需要;分号, //Pri ...
- LG4071 [SDOI2016]排列计数
题意 题目描述 求有多少种长度为 n 的序列 A,满足以下条件: 1 ~ n 这 n 个数在序列中各出现了一次 若第 i 个数 A[i] 的值为 i,则称 i 是稳定的.序列恰好有 m 个数是稳定的 ...
- MySQL Disk--SSD和HDD的性能
========================================================= 机械硬盘的性能 7200转/分的STAT硬盘平均物理寻道时间是9ms 10000转/ ...
- terraform plugin 版本以及changlog 规范
文章来自官方文章,转自:https://www.terraform.io/docs/extend/best-practices/versioning.html 里面包含了版本命名的规范,以及chang ...
- Singer 学习八 运行&&开发taps、targets (三 开发tap)
如何没有找到适合的tap,那么我们可以自己开发一个 hello world tap 仅仅是一个程序,我们可以使用任何语言进行编写,根据singer 指南,输出数据到stdout 即可,实际上一个简单的 ...
- 01python简介
目录 1. Python起源 2. 解释器 3. Python 的设计目标 4. Python 的设计哲学 5. 为什么选择 Python ? 6. Python 特点 7. Pyth ...
- HDU2220 Eddy's AC难题
版权声明:长风原创 https://blog.csdn.net/u012846486/article/details/27853287 Eddy's AC难题 Time Limit: 3000/100 ...