【Java并发编程六】线程池
一、概述
在执行并发任务时,我们可以把任务传递给一个线程池,来替代为每个并发执行的任务都启动一个新的线程,只要池里有空闲的线程,任务就会分配一个线程执行。在线程池的内部,任务被插入一个阻塞队列(BlockingQueue),线程池里的线程会去取这个队列里的任务。
利用线程池有三个好处:
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗
- 提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控
二、线程池的使用
1、创建线程池
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime,
TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
创建一个线程池需要的几个参数:
- corePoolSize:线程池的基本大小,当提交一个任务到线程池,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任务数大于corePoolSize时就不再创建。如果调用了线程池的prestartAllCoreThreads方法,线程池会提前创建并启动所有基本线程。
- maximumPoolSize:线程池最大大小,线程池允许创建的最大线程数,如果队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。
- keepAliveTime:线程活动保持时间,线程池的工作线程空闲后,保持存活的时间。
- unit:线程活动保持时间的单位
- workQueue:任务队列,用于保存等待执行的任务的阻塞队列,可以选择以下几个队列:
1、ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序。
2、LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO (先进先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
3、SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
4、PriorityBlockingQueue:一个具有优先级得无限阻塞队列。
- threadFactory:用于设置创建线程的工厂,可以通过线程工程给每个创建出来的线程设置更有意义的名字。
- handler:饱和策略,当线程池和队列都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是AbortPolicy,表示无法处理新任务时抛出异常。
此外,我们还可以通过调用Ececutors中的某个静态工厂方法来创建一个线程池(它们的内部实现原理都是相同的,仅仅是使用了不同的工作队列或线程池大小):
newFixedThreadPool:创建一个定长的线程池,每当提交一个任务就创建一个线程,直到达到池的最大长度,这时线程池会保持长度不在变化
newCachedThreadPool:创建一个可缓存的线程池,如果当前的线程池的长度超过了处理的需要时,它可以灵活的回收空闲的线程,当需求增加时,它可以灵活的添加新的线程,并不会对池的长度做任何限制
newSingleThreadPool:创建一个单线程化的executor,它只会创建唯一的工作者线程来执行任务
newScheduledThreadPool:创建一个定长的线程池,而且支持定时的以及周期性的任务执行,类似于Timer
2、向线程池提交任务
可以使用execute向线程池提交任务:
public class Test2
{
public static void main(String[] args)
{
BlockingQueue<Runnable> workQueue=new LinkedBlockingDeque<Runnable>();
ThreadPoolExecutor poolExecutor=new ThreadPoolExecutor(2, 3, 60, TimeUnit.SECONDS, workQueue);
poolExecutor.execute(new Task1());
poolExecutor.execute(new Task2());
poolExecutor.shutdown();
}
}
class Task1 implements Runnable
{ public void run()
{
System.out.println("执行任务1");
}
}
class Task2 implements Runnable
{ public void run()
{
System.out.println("执行任务2");
}
}
也可以使用submit方法来提交任务,它会返回一个future,我们可以通过这个future来判断任务是否执行成功,通过future的get方法获取返回值,get方法会阻塞直到任务完成。
public class Test3
{
public static void main(String[] args) throws InterruptedException, ExecutionException
{
ExecutorService executorService = Executors.newCachedThreadPool();
List<Future<String>> resultList = new ArrayList<Future<String>>();
// 创建10个任务并执行
for (int i = 0; i < 10; i++)
{
// 使用ExecutorService执行Callable类型的任务,并将结果保存在future变量中
Future<String> future = executorService.submit(new TaskWithResult(i));
resultList.add(future);
}
for (Future<String> future : resultList)
{
while (!future.isDone());// Future返回如果没有完成,则一直循环等待,直到Future返回完成
{
System.out.println(future.get()); // 打印各个线程(任务)执行的结果
}
}
executorService.shutdown();
}
}
class TaskWithResult implements Callable<String>
{
private int id;
public TaskWithResult(int id)
{
this.id = id;
}
public String call() throws Exception
{
return "执行结果"+id;
}
}
3、线程关闭
可以通过调用线程池的shutdown或shutdownNow方法来关闭线程池,但是它们的实现原理不同,shutdown的原理是只是将线程池的状态设置成SHUTDOWN状态,然后中断所有没有正在执行任务的线程。shutdownNow的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。shutdownNow会首先将线程池的状态设置成STOP,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表。
只要调用了这两个关闭方法的其中一个,isShutdown方法就会返回true。当所有的任务都已关闭后,才表示线程池关闭成功,这时调用isTerminaed方法会返回true。至于我们应该调用哪一种方法来关闭线程池,应该由提交到线程池的任务特性决定,通常调用shutdown来关闭线程池,如果任务不一定要执行完,则可以调用shutdownNow。
三、线程池的执行过程
整个ThreadExecutor的任务处理经过下面4个步骤,如下图所示:

1、如果当前的线程数<corePoolSize,提交的Runnable任务,会直接作为new Thread的参数,立即执行,当提交的任务数超过了corePoolSize,就进入第二部操作
2、将当前的任务提交到BlockingQueue阻塞队列中,如果Block Queue是个有界队列,当队列满了之后就进入第三步
3、如果poolSize < maximumPoolsize时,会尝试new 一个Thread的进行救急处理,执行对应的runnable任务
4、如果第三步也无法处理,就会用RejectedExecutionHandler来做拒绝处理
四、执行定时及周期性任务
Timer工具管理任务的定时以及周期性执行。示例代码如下:
public class TimerTest
{
final static SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public static void main(String[] args)
{
TimerTask timerTask1=new TimerTask()
{
@Override
public void run()
{
System.out.println("任务1执行时间:"+sdf.format(new Date()));
try
{
Thread.sleep(3000);//模拟任务1执行时间为3秒
}
catch (InterruptedException e)
{
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
};
System.out.println("当前时间:"+sdf.format(new Date()));
Timer timer=new Timer();
timer.schedule(timerTask1, new Date(),4000); //间隔4秒周期性执行
}
}
执行结果:
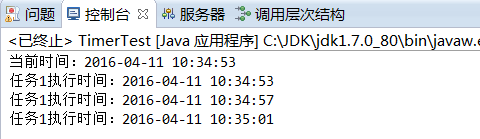
可以看到上述任务1以4秒为间隔周期性执行。但是Timer存在一些缺陷,主要是下面两个方面的问题:
缺陷1:Timer只创建唯一的线程的来执行所有的Timer任务,如果一个time任务的执行很耗时,会导致其他的TimeTask的时效准确性出问题。看下面的例子:
public class TimerTest
{
final static SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public static void main(String[] args)
{
TimerTask timerTask1=new TimerTask()
{
@Override
public void run()
{
System.out.println("任务1执行时间:"+sdf.format(new Date()));
try
{
Thread.sleep(10000);
}
catch (InterruptedException e)
{
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
};
TimerTask timerTask2=new TimerTask()
{
@Override
public void run()
{ System.out.println("任务2执行时间:"+sdf.format(new Date()));
}
};
System.out.println("当前时间:"+sdf.format(new Date()));
Timer timer=new Timer();
timer.schedule(timerTask1, new Date(),1000); //间隔1秒周期性执行
timer.schedule(timerTask2, new Date(),4000); //间隔4秒周期性执行
}
}
执行结果:

缺陷2:如果TimeTask抛出未检查的异常,Timer将产生无法预料的行为。Timer线程并不捕获线程,所有TimerTask抛出的未检查的异常会终止timer线程。看下面的代码:
public class TimerTest2
{
final static SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public static void main(String[] args)
{
TimerTask timerTask1=new TimerTask()
{
@Override
public void run()
{
System.out.println("任务1执行时间:"+sdf.format(new Date()));
throw new RuntimeException();
}
}; TimerTask timerTask2=new TimerTask()
{
@Override
public void run()
{
System.out.println("任务2执行时间:"+sdf.format(new Date()));
}
};
System.out.println("当前时间:"+sdf.format(new Date()));
Timer timer=new Timer();
timer.schedule(timerTask1, new Date(),1000); //周期1秒执行任务1
timer.schedule(timerTask2, new Date() ,3000); //周期3秒执行任务2 }
}
执行结果为:

针对上述的两个问题,我们可以使用ScheduledThreadPoolExecutor来作为Timer的替代。
针对问题1,有下面代码:
public class ScheduledThreadPoolExecutorTest
{
final static SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public static void main(String[] args)
{
TimerTask timerTask1 = new TimerTask()
{ @Override
public void run()
{
System.out.println("任务1执行时间:" + sdf.format(new Date()));
try
{
Thread.sleep(10000);
} catch (InterruptedException e)
{
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
};
TimerTask timerTask2 = new TimerTask()
{
@Override
public void run()
{
System.out.println("任务2执行时间:" + sdf.format(new Date()));
}
};
System.out.println("当前时间:" + sdf.format(new Date()));
ScheduledThreadPoolExecutor poolExecutor=new ScheduledThreadPoolExecutor(2);
poolExecutor.scheduleAtFixedRate(timerTask1, 0, 1000,TimeUnit.MILLISECONDS);
poolExecutor.scheduleAtFixedRate(timerTask2, 0, 4000,TimeUnit.MILLISECONDS);
}
}
执行的结果为:

针对问题2,有下面代码:
public class ScheduledThreadPoolExecutorTest2
{
final static SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public static void main(String[] args)
{
TimerTask timerTask1 = new TimerTask()
{ @Override
public void run()
{
System.out.println("任务1执行时间:" + sdf.format(new Date()));
throw new RuntimeException();
}
};
TimerTask timerTask2 = new TimerTask()
{
@Override
public void run()
{ System.out.println("任务2执行时间:" + sdf.format(new Date()));
}
};
System.out.println("当前时间:" + sdf.format(new Date()));
ScheduledThreadPoolExecutor poolExecutor=new ScheduledThreadPoolExecutor(2);
poolExecutor.scheduleAtFixedRate(timerTask1, 0, 1000, TimeUnit.MILLISECONDS);
poolExecutor.scheduleAtFixedRate(timerTask2, 0, 2000, TimeUnit.MILLISECONDS);
}
}
执行结果为:

五、参考资料
1、Java并发编程实践
【Java并发编程六】线程池的更多相关文章
- Java并发编程:线程池的使用
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
- Java并发编程:线程池的使用(转)
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
- (转)Java并发编程:线程池的使用
背景:线程池在面试时候经常遇到,反复出现的问题就是理解不深入,不能做到游刃有余.所以这篇博客是要深入总结线程池的使用. ThreadPoolExecutor的继承关系 线程池的原理 1.线程池状态(4 ...
- Java并发编程:线程池的使用(转载)
转载自:https://www.cnblogs.com/dolphin0520/p/3932921.html Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实 ...
- Java并发编程:线程池的使用(转载)
文章出处:http://www.cnblogs.com/dolphin0520/p/3932921.html Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实 ...
- [转]Java并发编程:线程池的使用
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
- 【转】Java并发编程:线程池的使用
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
- 13、Java并发编程:线程池的使用
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
- Java并发编程之线程池的使用
1. 为什么要使用多线程? 随着科技的进步,现在的电脑及服务器的处理器数量都比较多,以后可能会越来越多,比如我的工作电脑的处理器有8个,怎么查看呢? 计算机右键--属性--设备管理器,打开属性窗口,然 ...
- Java并发编程之线程池及示例
1.Executor 线程池顶级接口.定义方法,void execute(Runnable).方法是用于处理任务的一个服务方法.调用者提供Runnable 接口的实现,线程池通过线程执行这个 Runn ...
随机推荐
- 微信公众号基础02_获取accessToken和用户信息
上一篇分享了搭建微信公众号server,本文分享一下假设获取access_Token和用户信息.工具还是新浪云SAE 1.获取access_Token 相见开发文档:https://mp.weixin ...
- 天猫魔盒1代TMB100E刷机, 以及右声道无声的问题
这个是在小米盒子1代之后买的, 当时速度比小米盒子快, 除了遥控器比较软, 电池盖不太对得齐以外, 用起来还不错. 但是时间长了之后总是不停自己升级, 自己安装一些应用, 还删不了, 要知道这个盒子的 ...
- 【CLR】解析CLR的托管堆和垃圾回收
目录结构: contents structure [+] 为什么使用托管堆 从托管堆中分配资源 托管堆中的垃圾回收 垃圾回收算法 代 垃圾回收模式 垃圾回收触发条件 强制垃圾回收 监视内存 对包装了本 ...
- Java并发之线程池ThreadPoolExecutor源码分析学习
线程池学习 以下所有内容以及源码分析都是基于JDK1.8的,请知悉. 我写博客就真的比较没有顺序了,这可能跟我的学习方式有关,我自己也觉得这样挺不好的,但是没办法说服自己去改变,所以也只能这样想到什么 ...
- stale element reference: element is not attached to the page document 异常
在执行脚本时,有时候引用一些元素对象会抛出如下异常 org.openqa.selenium.StaleElementReferenceException: stale element referenc ...
- vue-worker的介绍和使用
vue-worker把复杂的web worker封装起来,提供一套非常简明的api接口,使用的时候可以说像不接触worker一样方便.那么具体怎么使用呢? 安装 npm i -S vue-worker ...
- [Big Data - Kafka] Kafka设计解析(三):Kafka High Availability (下)
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
- 利用OCR识别扫描的jpg、tif文件的文字
第一步:下载老马哥的从 office和sharepoint 提取出来的注册表和dll http://115.com/file/dpa4qrt2 或者直接安装office和sharepoint2007 ...
- linux每日命令(8):mv命令
mv命令是move的缩写,可以用来移动文件或者将文件改名(move (rename) files),是Linux系统下常用的命令,经常用来备份文件或者目录. 一.命令格式: mv [选项] 源文件或目 ...
- <王二的经济学故事>读书笔记
不是简单地用价格把供需弄平衡就完事了,座位分配给谁同样重要 一个成功的社会必须要有成功的人,必须要给成功的人应得的回报 需求曲线向下倾斜,价格越高需求越少 先来的都是那些时间最不值钱的 无论收入分配差 ...