Scrapy - CrawlSpider爬虫
crawlSpider 爬虫
思路:
从response中提取满足某个条件的url地址,发送给引擎,同时能够指定callback函数。
1. 创建项目
scrapy startproject myspiderproject
2. 创建crawlSpider 爬虫
scrapy genspider -t crawl 爬虫名 爬取网站域名
3. 启动爬虫
scrapy crawl 爬虫名 # 会打印日志 scrapy crawl 爬虫名 --nolog
crawlSpider 的参数解析:
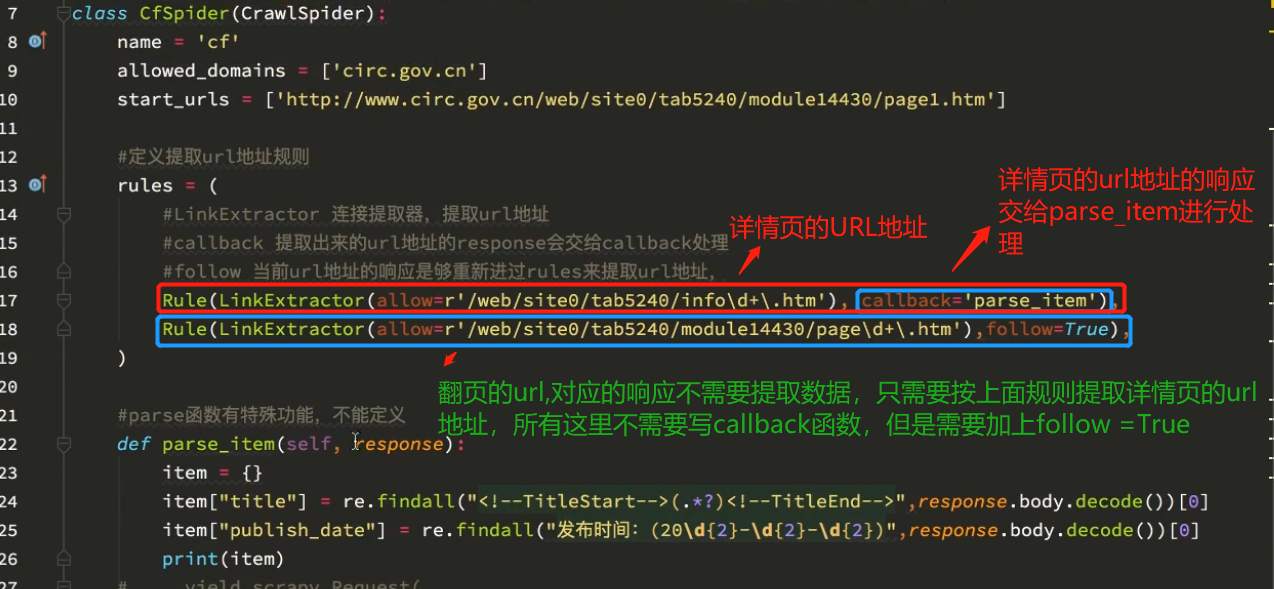
案例
需求:爬取csdn上面所有的博客专家及其文章的文章 Url地址:http://blog.csdn.net/experts.html 。
分析:

使用crawlSpider 的注意点:

补充知识点:

Scrapy - CrawlSpider爬虫的更多相关文章
- scrapy 中crawlspider 爬虫
爬取目标网站: http://www.chinanews.com/rss/rss_2.html 获取url后进入另一个页面进行数据提取 检查网页: 爬虫该页数据的逻辑: Crawlspider爬虫类: ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- scrapy -->CrawlSpider 介绍
scrapy -->CrawlSpider 介绍 1.首先,通过crawl 模板新建爬虫: scrapy genspider -t crawl lagou www.lagou.com 创建出来的 ...
- crawlspider爬虫:定义url规则
spider爬虫,适合meta传参的爬虫(列表页,详情页都有数据要爬取的时候) crawlspider爬虫,适合不用meta传参的爬虫 scrapy genspider -t crawl it it. ...
- 创建CrawlSpider爬虫简要步骤
创建CrawlSpider爬虫简要步骤: 1. 创建项目文件: e.g: scrapy startproject douyu (douyu为项目名自定义) 2. 进入项目文件: e.g: cd dou ...
- 爬虫(十八):Scrapy框架(五) Scrapy通用爬虫
1. Scrapy通用爬虫 通过Scrapy,我们可以轻松地完成一个站点爬虫的编写.但如果抓取的站点量非常大,比如爬取各大媒体的新闻信息,多个Spider则可能包含很多重复代码. 如果我们将各个站点的 ...
- 爬虫学习之基于Scrapy的爬虫自动登录
###概述 在前面两篇(爬虫学习之基于Scrapy的网络爬虫和爬虫学习之简单的网络爬虫)文章中我们通过两个实际的案例,采用不同的方式进行了内容提取.我们对网络爬虫有了一个比较初级的认识,只要发起请求获 ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- Scrapy框架-----爬虫
说明:文章是本人读了崔庆才的Python3---网络爬虫开发实战,做的简单整理,希望能帮助正在学习的小伙伴~~ 1. 准备工作: 安装Scrapy框架.MongoDB和PyMongo库,如果没有安装, ...
随机推荐
- Python3 tkinter基础 Label compound 图片上显示文字 fg字体颜色 font字体大小
Python : 3.7.0 OS : Ubuntu 18.04.1 LTS IDE : PyCharm 2018.2.4 Conda ...
- Git 收集别名
.gitconfig文件夹一般是在C:\Users\Administrator路径下,用于全局的git的配置 下面是git别名的设置: [alias] last = log -1 --stat a = ...
- 永久修改VS include目录
原文:https://blog.csdn.net/sysprogram/article/details/49214727 VS2008在选项里可以设置全局的Include目录和Lib目录, 但是VS2 ...
- HDU 6318 Swaps and Inversions(归并排序 || 树状数组)题解
题意:一个逆序对罚钱x元,现在给你交换的机会,每交换任意相邻两个数花钱y,问你最少付多少钱 思路:最近在补之前还没过的题,发现了这道多校的题.显然,交换相邻两个数逆序对必然会变化+1或者-1,那我们肯 ...
- (转载)西门子PLC学习笔记十五-(数据块及数据访问方式)
一.数据块 数据块是在S7 CPU的存储器中定义的,用户可以定义多了数据块,但是CPU对数据块数量及数据总量是有限制的. 数据块与临时数据不同,当逻辑块执行结束或数据块关闭,数据块中的数据是会保留住的 ...
- Java中泛型Class<T>、T与Class<?>、 Object类和Class类、 object.getClass()和Object.class
一.区别 单独的T 代表一个类型(表现形式是一个类名而已) ,而 Class<T>代表这个类型所对应的类(又可以称做类实例.类类型.字节码文件), Class<?>表示类型不确 ...
- cookie 简单用法
cookie 简单用法 //当前登录人的组织Id HttpCookie SingleValueCookie = new HttpCookie("DepartmentId", &qu ...
- 基于 Python 和 Pandas 的数据分析(6) --- Joining and Merging
这一节我们将看一下如何通过 join 和 merge 来合并 dataframe. import pandas as pd df1 = pd.DataFrame({'HPI':[80,85,88,85 ...
- hdu 6070 Dirt Ratio 线段树+二分
Dirt Ratio Time Limit: 18000/9000 MS (Java/Others) Memory Limit: 524288/524288 K (Java/Others)Spe ...
- mysql5.7.23手动配置安装windows版
1.mysql下载地址 官网:https://dev.mysql.com/downloads/mysql/5.7.html#downloads 官网我下载的是: 百度网盘:链接: https://pa ...