gbdt xgboost 贼难理解!
https://www.zybuluo.com/yxd/note/611571
https://zhuanlan.zhihu.com/p/29765582
gbdt 在看统计学习方法的时候 理解很吃力。 参考了以上两篇文章,作者写的非常好。
冒昧转载过来。
机器学习-一文理解GBDT的原理-20171001
现在网上介绍gbdt算法的文章并不算少,但总体看下来,千篇一律的多,能直达精髓的少,有条理性的就更稀少了。我希望通过此篇文章,能抽丝剥茧般的向初学者介绍清楚这个算法的原理所在。如果仍不清楚可以在文后留言。
1、如何在不改变原有模型的结构上提升模型的拟合能力
假设现在你有样本集 ,然后你用一个模型,如
去拟合这些数据,使得这批样本的平方损失函数(即
)最小。但是你发现虽然模型的拟合效果很好,但仍然有一些差距,比如预测值
=0.8,而真实值
=0.9,
=1.4,
=1.3等等。另外你不允许更改原来模型
的参数,那么你有什么办法进一步来提高模型的拟合能力呢。
既然不能更改原来模型的参数,那么意味着必须在原来模型的基础之上做改善,那么直观的做法就是建立一个新的模型 来拟合
未完全拟合真实样本的残差,即
。所以对于每个样本来说,拟合的样本集就变成了:
.
2、基于残差的gbdt
在第一部分, 被称为残差,这一部分也就是前一模型(
)未能完全拟合的部分,所以交给新的模型来完成。
我们知道gbdt的全称是Gradient Boosting Decision Tree,其中gradient被称为梯度,更一般的理解,可以认为是一阶导,那么这里的残差与梯度是什么关系呢。在第一部分,我们提到了一个叫做平方损失函数的东西,具体形式可以写成 ,熟悉其他算法的原理应该知道,这个损失函数主要针对回归类型的问题,分类则是用熵值类的损失函数。具体到平方损失函数的式子,你可能已经发现它的一阶导其实就是残差的形式,所以基于残差的gbdt是一种特殊的gbdt模型,它的损失函数是平方损失函数,常用来处理回归类的问题。具体形式可以如下表示:
损失函数的一阶导:
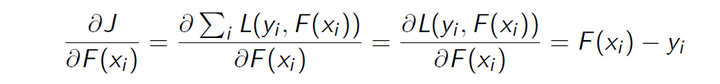
正好残差就是负梯度:
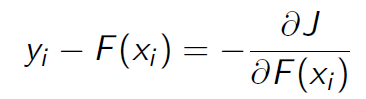
3、为什么基于残差的gbdt不是一个好的选择
基于残差的gbdt在解决回归问题上不算是一个好的选择,一个比较明显的缺点就是对异常值过于敏感。我们来看一个例子:

很明显后续的模型会对第4个值关注过多,这不是一种好的现象,所以一般回归类的损失函数会用绝对损失或者huber损失函数来代替平方损失函数:

4、Boosting的加法模型
如前面所述,gbdt模型可以认为是是由k个基模型组成的一个加法运算式:
其中F是指所有基模型组成的函数空间。
那么一般化的损失函数是预测值 与 真实值
之间的关系,如我们前面的平方损失函数,那么对于n个样本来说,则可以写成:
更一般的,我们知道一个好的模型,在偏差和方差上有一个较好的平衡,而算法的损失函数正是代表了模型的偏差面,最小化损失函数,就相当于最小化模型的偏差,但同时我们也需要兼顾模型的方差,所以目标函数还包括抑制模型复杂度的正则项,因此目标函数可以写成:
其中 代表了基模型的复杂度,若基模型是树模型,则树的深度、叶子节点数等指标可以反应树的复杂程度。
对于Boosting来说,它采用的是前向优化算法,即从前往后,逐渐建立基模型来优化逼近目标函数,具体过程如下:
那么,在每一步,如何学习一个新的模型呢,答案的关键还是在于gbdt的目标函数上,即新模型的加入总是以优化目标函数为目的的。
我们以第t步的模型拟合为例,在这一步,模型对第 个样本
的预测为:
其中 就是我们这次需要加入的新模型,即需要拟合的模型,此时,目标函数就可以写成:
即此时最优化目标函数,就相当于求得了 。
5、什么是gbdt的目标函数
我们知道泰勒公式中,若 很小时,我们只保留二阶导是合理的(gbdt是一阶导,xgboost是二阶导,我们以二阶导为例,一阶导可以自己去推,因为更简单),即:
那么在等式(1)中,我们把 看成是等式(2)中的x,
看成是
,因此等式(1)可以写成:
其中 为损失函数的一阶导,
为损失函数的二阶导,注意这里的导是对
求导。我们以 平方损失函数为例
,则
,
。
由于在第t步 其实是一个已知的值,所以
是一个常数,其对函数优化不会产生影响,因此,等式(3)可以写成:
所以我么只要求出每一步损失函数的一阶和二阶导的值(由于前一步的 是已知的,所以这两个值就是常数)代入等式4,然后最优化目标函数,就可以得到每一步的
,最后根据加法模型得到一个整体模型。
6、如何用决策树来表示上一步的目标函数
假设我们boosting的基模型用决策树来实现,则一颗生成好的决策树,即结构确定,也就是说树的叶子结点其实是确定了的。假设这棵树的叶子结点有 片叶子,而每片叶子对应的值
。熟悉决策树的同学应该清楚,每一片叶子结点中样本的预测值都会是一样的,在分类问题中,是某一类,在回归问题中,是某一个值(在gbdt中都是回归树,即分类问题转化成对概率的回归了),那么肯定存在这样一个函数
,即将
中的每个样本映射到每一个叶子结点上,当然
和
我们都是不知道的,但我们也不关心,这里只是说明一下决策树表达数据结构的方法是怎么样的,不理解也没有问题。
那么 就可以转成
,这里的
代表了每个样本在哪个叶子结点上,而
则代表了哪个叶子结点取什么
值,所以
就代表了每个样本的取值
(即预测值)。
如果决策树的复杂度可以由正则项来定义 ,即决策树模型的复杂度由生成的树的叶子节点数量和叶子节点对应的值向量的L2范数决定。
我们假设 为第
个叶子节点的样本集合,则等式4根据上面的一些变换可以写成:
即我们之前样本的集合,现在都改写成叶子结点的集合,由于一个叶子结点有多个样本存在,因此才有了 和
这两项。
定义 ,
,则等式5可以写成:
如果树的结构是固定的,即 是确定的,或者说我们已经知道了每个叶子结点有哪些样本,所以
和
是确定的,但
不确定(
其实就是我们需要预测的值),那么令目标函数一阶导为0,则可以求得叶子结点
对应的值:
目标函数的值可以化简为:
7、如何最优化目标函数
那么对于单棵决策树,一种理想的优化状态就是枚举所有可能的树结构,因此过程如下:
a、首先枚举所有可能的树结构,即 ;
b、计算每种树结构下的目标函数值,即等式7的值;
c、取目标函数最小(大)值为最佳的数结构,根据等式6求得每个叶子节点的 取值,即样本的预测值。
但上面的方法肯定是不可行的,因为树的结构千千万,所以一般用贪心策略来优化:
a、从深度为0的树开始,对每个叶节点枚举所有的可用特征
b、 针对每个特征,把属于该节点的训练样本根据该特征值升序排列,通过线性扫描的方式来决定该特征的最佳分裂点,并记录该特征的最大收益(采用最佳分裂点时的收益)
c、 选择收益最大的特征作为分裂特征,用该特征的最佳分裂点作为分裂位置,把该节点生长出左右两个新的叶节点,并为每个新节点关联对应的样本集
d、回到第1步,递归执行到满足特定条件为止
那么如何计算上面的收益呢,很简单,仍然紧扣目标函数就可以了。假设我们在某一节点上二分裂成两个节点,分别是左(L)右(R),则分列前的目标函数是 ,分裂后则是
,则对于目标函数来说,分裂后的收益是(这里假设是最小化目标函数,所以用分裂前-分裂后):
等式8计算出来的收益,也是作为变量重要度输出的重要依据。
所以gbdt的算法可以总结为:
a、算法在拟合的每一步都新生成一颗决策树;
b、在拟合这棵树之前,需要计算损失函数在每个样本上的一阶导和二阶导,即 和
;
c、通过上面的贪心策略生成一颗树,计算每个叶子结点的的 和
,利用等式6计算预测值
;
d、把新生成的决策树 加入
,其中
为学习率,主要为了抑制模型的过拟合。
gbdt xgboost 贼难理解!的更多相关文章
- RF,GBDT,XGBoost,lightGBM的对比
转载地址:https://blog.csdn.net/u014248127/article/details/79015803 RF,GBDT,XGBoost,lightGBM都属于集成学习(Ensem ...
- RF/GBDT/XGBoost/LightGBM简单总结(完结)
这四种都是非常流行的集成学习(Ensemble Learning)方式,在本文简单总结一下它们的原理和使用方法. Random Forest(随机森林): 随机森林属于Bagging,也就是有放回抽样 ...
- GBDT && XGBOOST
GBDT && XGBOOST Outline Introduction GBDT Model XGBOOST Model ...
- K8S核心概念之SVC(易混淆难理解知识点总结)
本文将结合实际工作当中遇到的一些问题和情况来解析SVC的作用以及一些比较易混淆和难理解的概念,方便日后工作用到或者遗忘时可以直接在自己曾经学习总结的博客当中直接查找到. 首先应该清楚SVC的作用是什么 ...
- 机器学习 GBDT+xgboost 决策树提升
目录 xgboost CART(Classify and Regression Tree) GBDT(Gradient Boosting Desicion Tree) GB思想(Gradient Bo ...
- 机器学习之——集成算法,随机森林,Bootsing,Adaboost,Staking,GBDT,XGboost
集成学习 集成算法 随机森林(前身是bagging或者随机抽样)(并行算法) 提升算法(Boosting算法) GBDT(迭代决策树) (串行算法) Adaboost (串行算法) Stacking ...
- 认为C/C++很难理解、找工作面试笔试,快看看这本书!
假设你是C/C++谁刚开始学习,看这本书.因为也许你读其他的书还不如不看.一定要选择一本好书. 假设你正在准备工作,请认真看这本书,由于这本书会教会你工作中必备的知识,相信你即将面临的语法类题目不会超 ...
- GBDT XGBOOST的区别与联系
Xgboost是GB算法的高效实现,xgboost中的基学习器除了可以是CART(gbtree)也可以是线性分类器(gblinear). 传统GBDT以CART作为基分类器,xgboost还支持线性分 ...
- viewport其实没那么难理解
在学习移动端布局的时候,你肯定听说过"viewport"这个词,然后去问度娘或谷歌.你会惊奇的发现,这个viewport不简单,居然有那么多兄弟——layout viewport. ...
随机推荐
- 【逆向工具】IDA使用2-VS2015版本release查找main函数入口,局部变量
VS2015版本release查找main函数入口 vc++开发的程序main或WinMain函数是语法规定的用户入口,而不是应用程序入口.入口代码是mainCRTstartup.wmainCRTSt ...
- SHA1算法原理
一.SHA1与MD5差异 SHA1对任意长度明文的预处理和MD5的过程是一样的,即预处理完后的明文长度是512位的整数倍,但是有一点不同,那就是SHA1的原始报文长度不能超过2的64次方,然后SHA1 ...
- Linux性能分析的前60000毫秒【转】
Linux性能分析的前60000毫秒 为了解决性能问题,你登入了一台Linux服务器,在最开始的一分钟内需要查看什么? 在Netflix我们有一个庞大的EC2 Linux集群,还有非常多的性能分析工具 ...
- 多个SpingBoot项目的搭建与部署
最近几年SpringBoot大热,很多IT公司都开始采用SpringBoot来替换传统的SpringMVC项目.那么如何搭建一个适合开发的项目架构呢? 这里我主要介绍Java程序员使用最多的两种工具进 ...
- 教你构建好 SpringBoot + SSM 框架
来源:Howie_Y https://juejin.im/post/5b53f677f265da0f8f203914 目前最主流的 java web 框架应该是 SSM,而 SSM 框架由于更轻便与灵 ...
- 用PNChart绘制折线图
写在前面 上一篇文章已经介绍过用PNChart绘制饼状图了,绘制折线图的步骤和饼状图的步骤是相似的,按照中的准备做好准备工作后就可以绘制折线图了. 开始使用 1.在view中声明一个PNLineCha ...
- 性能测试十:jmeter进阶之webService与socket
一.webService 1.添加http post请求2.添加header:Conent-type:text/xml Post请求的body中填写<soapenv:Envelope xmln ...
- Crack相关
Microsoft Office 2007专业增强版密钥:KXFDR-7PTMK-YKYHD-C8FWV-BBPVWM7YXX-XJ8YH-WY349-4HPR9-4JBYJCTKXX-M97FT-8 ...
- 《microsoft sql server 2008技术内幕 t-sql语言基础》
第一章 TSQL编程基础 源代码下载:TSQLFundamentals2008 创建表 USE testdb; CREATE TABLE dbo.Employess ( empid INT NOT N ...
- 解决python中遇到的乱码问题
1. 解决中文乱码的一种可行方法 # -*- coding:utf-8 -*- from __future__ import unicode_literals import chardet def s ...