day08 MapReduce
PS: HDFS对于MapReduce来说,HDFS就是一个就是一个客户端。
PS: 离线就是 写sql,sparkh还是写sql
1. MAPREDUCE原理篇(1)
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;
Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上;

PS: 上图为mapreduce的设计思想,以wordcount为例子,首先把一个任务分我 两个阶段。 第一map阶段负责业务逻辑,第二数据的合并(比如按a-h合并,然后第二个安装i-k)。中间还有还多负责的业务
管理逻辑,由mr application master来管理,协调调度。
PS: MapReduce程序都是依赖于HDFS,以流的形式读取
----------------------------------------------------------------------------------------------------------------
1.1 为什么要MAPREDUCE
(1)海量数据在单机上处理因为硬件资源限制,无法胜任
(2)而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度
(3)引入mapreduce框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将分布式计算中的复杂性交由框架来处理
-----------------------------------------------------------
设想一个海量数据场景下的wordcount需求:
|
单机版:内存受限,磁盘受限,运算能力受限 分布式: 1、文件分布式存储(HDFS) 2、运算逻辑需要至少分成2个阶段(一个阶段独立并发,一个阶段汇聚) 3、运算程序如何分发 4、程序如何分配运算任务(切片) 5、两阶段的程序如何启动?如何协调? 6、整个程序运行过程中的监控?容错?重试? |
可见在程序由单机版扩成分布式时,会引入大量的复杂工作。为了提高开发效率,可以将分布式程序中的公共功能封装成框架,让开发人员可以将精力集中于业务逻辑。
而mapreduce就是这样一个分布式程序的通用框架,其应对以上问题的整体结构如下:
|
1、MRAppMaster(mapreduce application master) 2、MapTask 3、ReduceTask |
1.2 MAPREDUCE框架结构及核心运行机制
1.2.1 结构
一个完整的mapreduce程序在分布式运行时有三类实例进程:
1、MRAppMaster:负责整个程序的过程调度及状态协调
2、mapTask:负责map阶段的整个数据处理流程
3、ReduceTask:负责reduce阶段的整个数据处理流程
-----------------------------------------------------------------------------
PS:写程序代码
1.配置项目,common和hdfs如之前配置

2.配置mapreduce

3.配置yarn。PS:
yarn
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,
它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
------------------
YARN的基本思想是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)
和若干个针对应用程序的ApplicationMaster(AM)。这里的应用程序是指传统的MapReduce作业或作业的DAG(有向无环图)。
-------------------------------------------------------------------
package cn.itcast.bigdata.mr.wcdemo; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; /**
* KEYIN: 默认情况下,是mr框架所读到的一行文本的起始偏移量,Long,
* 但是在hadoop中有自己的更精简的序列化接口,所以不直接用Long,而用LongWritable
*
* VALUEIN:默认情况下,是mr框架所读到的一行文本的内容,String,同上,用Text
*
* KEYOUT:是用户自定义逻辑处理完成之后输出数据中的key,在此处是单词,String,同上,用Text
* VALUEOUT:是用户自定义逻辑处理完成之后输出数据中的value,在此处是单词次数,Integer,同上,用IntWritable
*
* @author
*
*/ public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ /**
* map阶段的业务逻辑就写在自定义的map()方法中
* maptask会对每一行输入数据调用一次我们自定义的map()方法
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //将maptask传给我们的文本内容先转换成String
String line = value.toString();
//根据空格将这一行切分成单词
String[] words = line.split(" "); //将单词输出为<单词,1>
for(String word:words){
//将单词作为key,将次数1作为value,以便于后续的数据分发,可以根据单词分发,以便于相同单词会到相同的reduce task
context.write(new Text(word), new IntWritable(1));
}
} }
package cn.itcast.bigdata.mr.wcdemo; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; /**
* KEYIN, VALUEIN 对应 mapper输出的KEYOUT,VALUEOUT类型对应
*
* KEYOUT, VALUEOUT 是自定义reduce逻辑处理结果的输出数据类型
* KEYOUT是单词
* VLAUEOUT是总次数
* @author
*
*/
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ /* 到这里的时候,数据已经按照一定的特性(规律如 统计a-h) 分组好了,所以入参的时候是一个同样的key,values是Itrater专门用来迭代累加; 然后再执行第二组 hello ,1,...指导统计完
* <angelababy,1><angelababy,1><angelababy,1><angelababy,1><angelababy,1>
* <hello,1><hello,1><hello,1><hello,1><hello,1><hello,1>
* <banana,1><banana,1><banana,1><banana,1><banana,1><banana,1>
* 入参key,是一组相同单词kv对的key
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count=0;
/*Iterator<IntWritable> iterator = values.iterator();
while(iterator.hasNext()){
count += iterator.next().get();
}*/ for(IntWritable value:values){ count += value.get();
} context.write(key, new IntWritable(count)); } }
package cn.itcast.bigdata.mr.wcdemo; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* 相当于一个yarn集群的客户端
* 需要在此封装我们的mr程序的相关运行参数,指定jar包
* 最后提交给yarn
* @author
*
*/
public class WordcountDriver { public static void main(String[] args) throws Exception { if (args == null || args.length == 0) {
args = new String[2];
args[0] = "hdfs://192.168.8.10:9000/wordcount/input/wordcount.txt";
args[1] = "hdfs://192.168.8.10:9000/wordcount/output";
} Configuration conf = new Configuration(); //设置的没有用! ?????? 因为在linux下允许,所以这些注释了
// conf.set("HADOOP_USER_NAME", "hadoop");
// conf.set("dfs.permissions.enabled", "false"); // ---因为linux和windows操作系统的环境变量不同,所以不能直接运行在windows上,现在打包到linux系统上,那么,就不用注释了(因为集群上已经配置过了)
/*conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resoucemanager.hostname", "mini1");*/
Job job = Job.getInstance(conf); /*job.setJar("/home/hadoop/wc.jar");*/
//指定本程序的jar包所在的本地路径
job.setJarByClass(WordcountDriver.class); //指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class); //指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); //指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); //指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path(args[1])); //将job中配置的相关参数,以及job所用的java类所在的jar包,提交给yarn去运行
/*job.submit();*/
boolean res = job.waitForCompletion(true);
System.exit(res?0:1); }
}
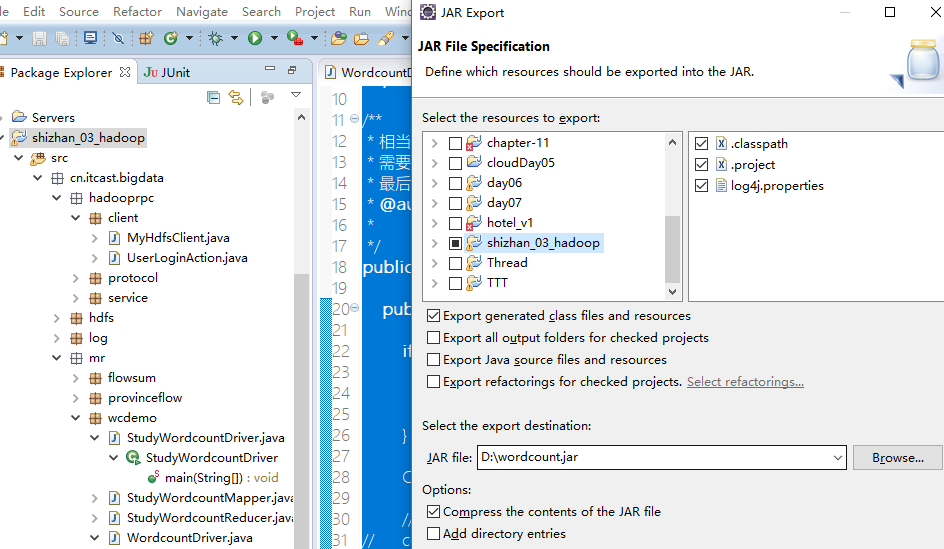
PS:打包文件

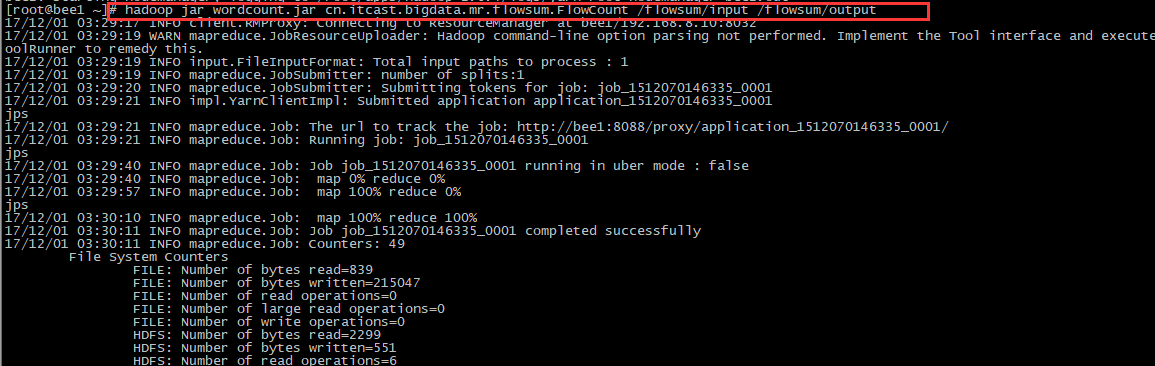
hadoop jar wordcount.jar cn.itcast.bigdata.mr.wcdemo.WordcountDriver /wordcount/input /wordcount/output1
PS: 红色命令 其实就是 调用 jar命令 ,只是把关联的jar链接上了
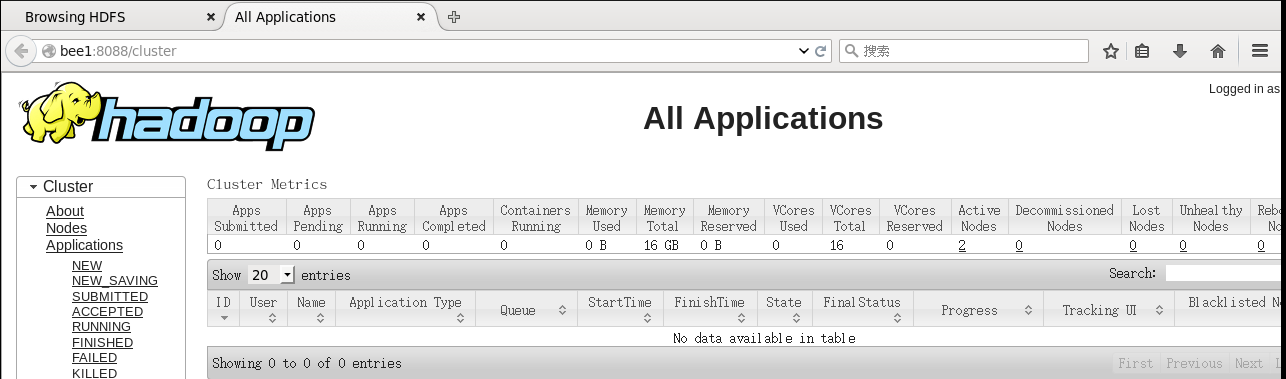
PS:在界面端也有一个专门界面。

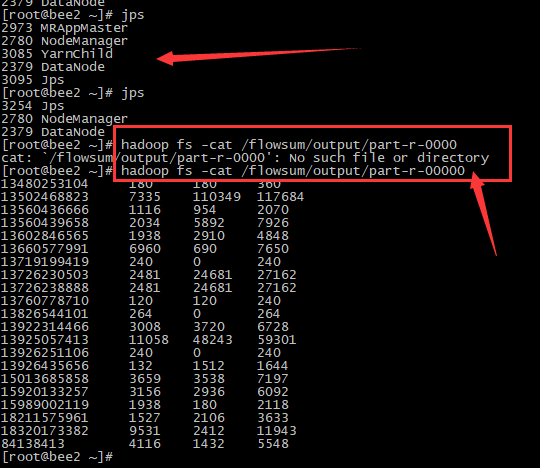
PS:这个文件可以part-r-0000可以自定义文件的个数,现在把所有的文件都放在part-r-0000中。
PS:程序先启动的时候先启动Mr application master,然后再启动map task 、reducetask
------------------------------------------------------------------------------------WordCount程序运行流程分析------------------------------------------------

PS:上图应该这么看,首先待处理文件。当submit()的时候,会看到文件的规模,进行map()划分(启动maptask的多少,这个文件是job.split),然后job.split、wc.jar、job。xml提交到云端的YARN进行管理。
然后yarn启动mr appmaster,启动相应的Node Manager进行管理。
执行map()任务,他是通过InputFormat组件以流的形式读入一定范围的数据进来,每一个任务执行完了,接着通过另一个组件outputController会生成分区且排序的结果文件,
再进入reducetask()任务, 每传过来maptask可以根据分区号进行分区,也就是输出的part-r-0000X的变化的值。
在mapreduce线程中,执行业务逻辑,通过outputFormat输出,最后生成文件(读取多个的文件,输出会进行文件)。
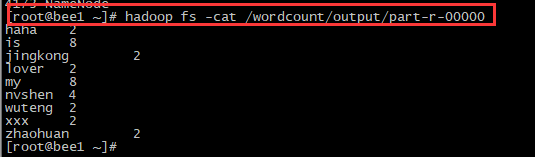
PS: 上图为输出的应用结果, key为单词字符,value是每个单词的个数
---------------------------------

-----------------------------------------MapReduce 应用编译执行
1. PS:
start-dfs.sh //启动应用
start-yarn.sh //启动yarn管理器
--------------------------------------------另一个程序练习


/*
PS: 打印什么内容是 由key 和 输出 value对象的toString方法所决定的。
*/
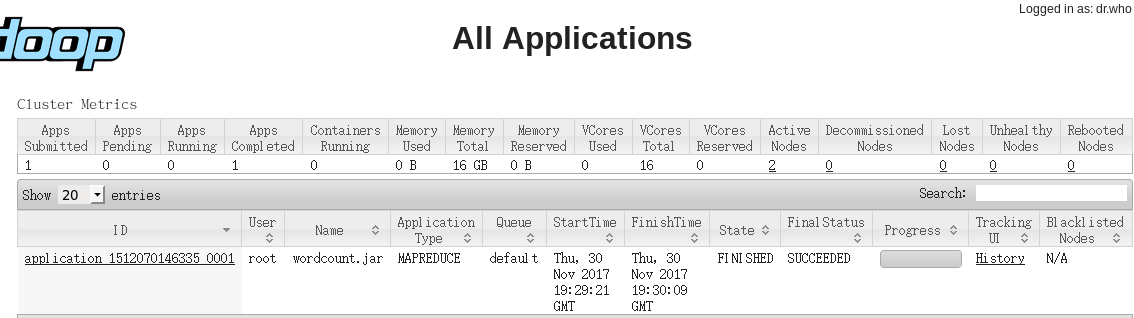
PS:文件在hdfs上,用jar包进行编译执行。




--------------------------切片和并行度的概念------------
1.3.1 mapTask并行度的决定机制
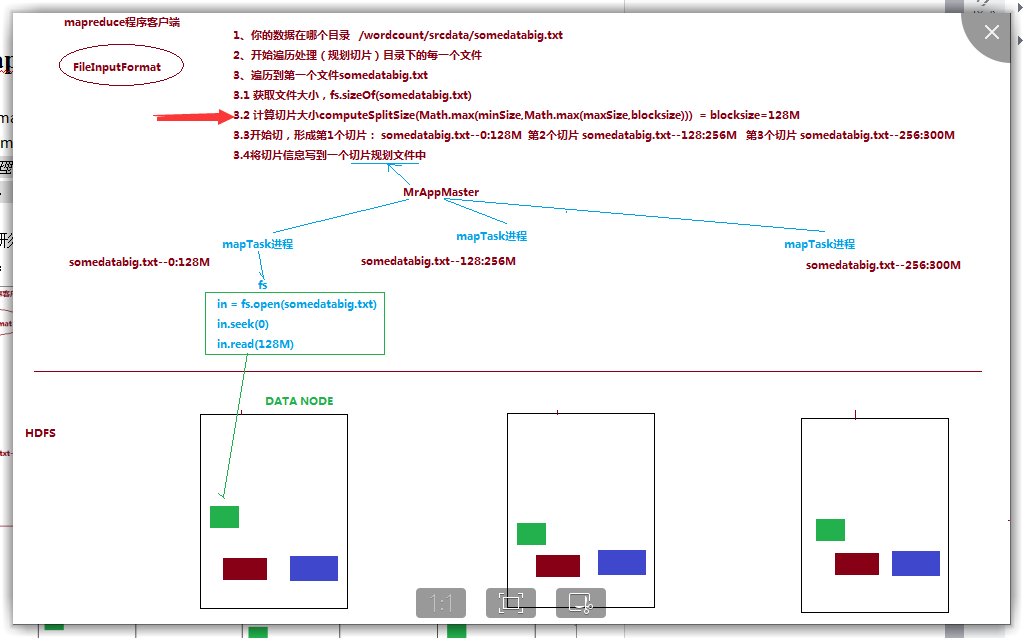
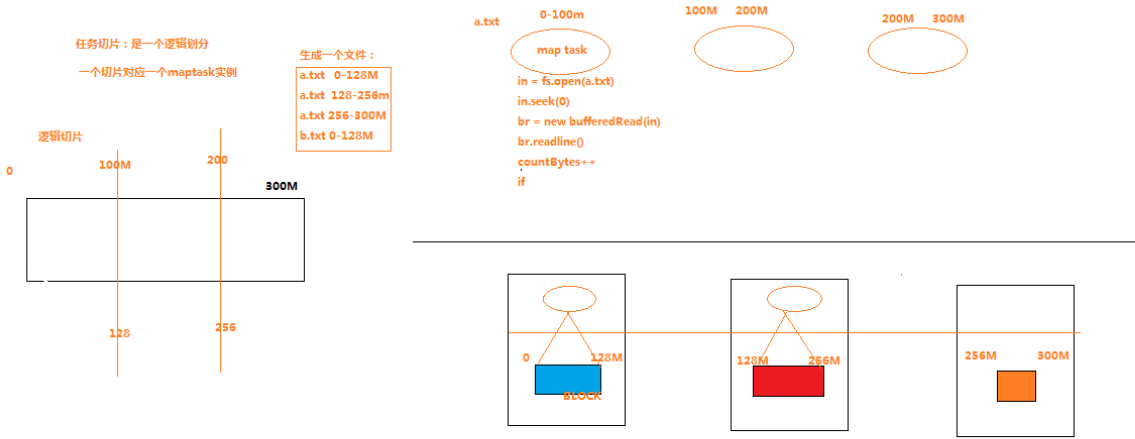
一个job的map阶段并行度由客户端在提交job时决定
而客户端对map阶段并行度的规划的基本逻辑为:
将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分成逻辑上的多个split),然后每一个split分配一个mapTask并行实例处理
Ps:由HDFS读取到 日志文件后,根据文件block的大小进行并行度的确定。通常大文件直接有文件块决定,决定时机是在 waitForCompletion这个函数执行时,会生成一个分块的文件。
然后再mapreduce执行时,MRAppMaster就可以读取到信息进行调度操作了。


PS:上图为提交数据的完成的信息,里面有包含分块的信息。所有配置参数,这些参数可以让MRAppMaster读取数据

PS :客户端提交MR程序job的流程

-------------------------------------------------------------------------------------
按照不同号码分区
package cn.itcast.bigdata.mr.provinceflow; import java.util.HashMap; import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner; /**
* K2 V2 对应的是map输出kv的类型,
* @author
* 返回的是分区地址的hashcode
*/
public class ProvincePartitioner extends Partitioner<Text, FlowBean>{ public static HashMap<String, Integer> proviceDict = new HashMap<String, Integer>();
static{
proviceDict.put("136", 0);
proviceDict.put("137", 1);
proviceDict.put("138", 2);
proviceDict.put("139", 3);
} @Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
String prefix = key.toString().substring(0, 3);
Integer provinceId = proviceDict.get(prefix); return provinceId==null?4:provinceId;
}
}
package cn.itcast.bigdata.mr.provinceflow; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class FlowCount { static class FlowCountMapper extends Mapper<LongWritable, Text, Text, FlowBean>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); //将一行内容转成string
String[] fields = line.split("\t"); //切分字段
String phoneNbr = fields[1]; //取出手机号 long upFlow = Long.parseLong(fields[fields.length-3]); //取出上行流量下行流量
long dFlow = Long.parseLong(fields[fields.length-2]); context.write(new Text(phoneNbr), new FlowBean(upFlow, dFlow));
}
} static class FlowCountReducer extends Reducer<Text, FlowBean, Text, FlowBean>{
//<183323,bean1><183323,bean2><183323,bean3><183323,bean4>.......
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException { long sum_upFlow = 0;
long sum_dFlow = 0; //遍历所有bean,将其中的上行流量,下行流量分别累加
for(FlowBean bean: values){
sum_upFlow += bean.getUpFlow();
sum_dFlow += bean.getdFlow();
} FlowBean resultBean = new FlowBean(sum_upFlow, sum_dFlow);
context.write(key, resultBean);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
/*conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resoucemanager.hostname", "mini1");*/
Job job = Job.getInstance(conf); /*job.setJar("/home/hadoop/wc.jar");*/
//指定本程序的jar包所在的本地路径
job.setJarByClass(FlowCount.class); //指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(FlowCountMapper.class);
job.setReducerClass(FlowCountReducer.class); //指定我们自定义的数据分区器
job.setPartitionerClass(ProvincePartitioner.class);
//同时指定相应“分区”数量的reducetask
job.setNumReduceTasks(5); //数量必须和分区相对应,可以为1 可以大于分区个数。单数少于1到分区数会报错。 //指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class); //指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class); //指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path(args[1])); //将job中配置的相关参数,以及job所用的java类所在的jar包,提交给yarn去运行
/*job.submit();*/
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
} }

----------------------------作业:对以下数据进行排序,按照流量排序,这个是在之前生成数据的基础上做的
PS:不要想着程序一下子全部完成,也可以分步骤解决问题、
package cn.itcast.bigdata.mr.flowsum; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.WritableComparable; public class FlowBean implements WritableComparable<FlowBean>{ private long upFlow;
private long dFlow;
private long sumFlow; //反序列化时,需要反射调用空参构造函数,所以要显示定义一个
public FlowBean(){} public FlowBean(long upFlow, long dFlow) {
this.upFlow = upFlow;
this.dFlow = dFlow;
this.sumFlow = upFlow + dFlow;
} public void set(long upFlow, long dFlow) {
this.upFlow = upFlow;
this.dFlow = dFlow;
this.sumFlow = upFlow + dFlow;
} public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getdFlow() {
return dFlow;
}
public void setdFlow(long dFlow) {
this.dFlow = dFlow;
}
public long getSumFlow() {
return sumFlow;
} public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
/**
* 序列化方法
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(dFlow);
out.writeLong(sumFlow); }
/**
* 反序列化方法
* 注意:反序列化的顺序跟序列化的顺序完全一致
*/
@Override
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
dFlow = in.readLong();
sumFlow = in.readLong();
} @Override
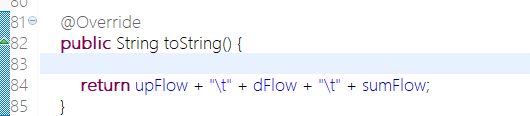
public String toString() {
return upFlow + "\t" + dFlow + "\t" + sumFlow;
} @Override
public int compareTo(FlowBean o) {
return this.sumFlow>o.getSumFlow()?-1:1; //从大到小, 当前对象和要比较的对象比, 如果当前对象大, 返回-1, 交换他们的位置(自己的理解)
} }
package cn.itcast.bigdata.mr.flowsum; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import cn.itcast.bigdata.mr.flowsum.FlowCount.FlowCountMapper;
import cn.itcast.bigdata.mr.flowsum.FlowCount.FlowCountReducer; /**
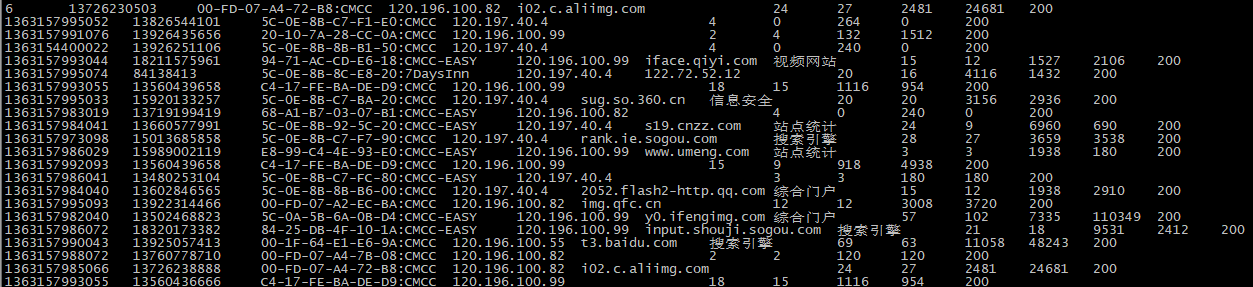
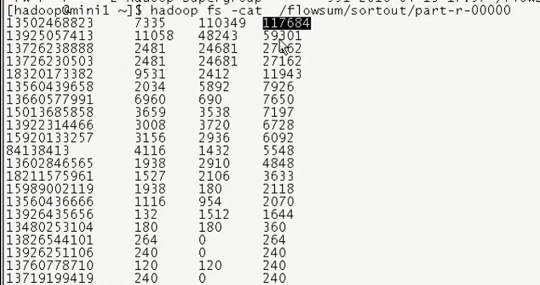
* 13480253104 180 180 360 13502468823 7335 110349 117684 13560436666 1116 954
* 2070
*
* @author
*
*/
public class FlowCountSort { static class FlowCountSortMapper extends Mapper<LongWritable, Text, FlowBean, Text> { FlowBean bean = new FlowBean();//!!!虽然这是一个对象,但是是序列化,所以不用担心数据操作
Text v = new Text(); @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 拿到的是上一个统计程序的输出结果,已经是各手机号的总流量信息
String line = value.toString(); String[] fields = line.split("\t"); String phoneNbr = fields[0]; long upFlow = Long.parseLong(fields[1]);
long dFlow = Long.parseLong(fields[2]); bean.set(upFlow, dFlow);
v.set(phoneNbr); context.write(bean, v); } } /**
* 根据key来掉, 传过来的是对象, 每个对象都是不一样的, 所以每个对象都调用一次reduce方法
* @author: 张政
* @date: 2016年4月11日 下午7:08:18
* @package_name: day07.sample
*/
static class FlowCountSortReducer extends Reducer<FlowBean, Text, Text, FlowBean> { // <bean(),phonenbr>
@Override
protected void reduce(FlowBean bean, Iterable<Text> values, Context context) throws IOException, InterruptedException { context.write(values.iterator().next(), bean); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration();
/*conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resoucemanager.hostname", "mini1");*/
Job job = Job.getInstance(conf); /*job.setJar("/home/hadoop/wc.jar");*/
//指定本程序的jar包所在的本地路径
job.setJarByClass(FlowCountSort.class); //指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(FlowCountSortMapper.class);
job.setReducerClass(FlowCountSortReducer.class); //指定mapper输出数据的kv类型
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(Text.class); //指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class); //指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定job的输出结果所在目录 Path outPath = new Path(args[1]);
/*FileSystem fs = FileSystem.get(conf);
if(fs.exists(outPath)){
fs.delete(outPath, true);
}*/
FileOutputFormat.setOutputPath(job, outPath); //将job中配置的相关参数,以及job所用的java类所在的jar包,提交给yarn去运行
/*job.submit();*/
boolean res = job.waitForCompletion(true);
System.exit(res?0:1); } }
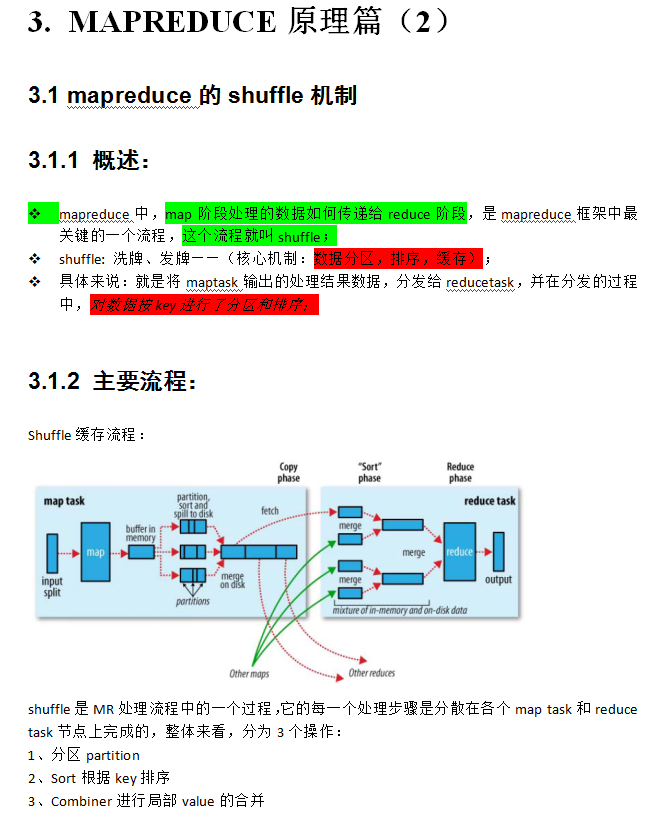

3.1.4 详细流程示意图 --------------这个图非常重要
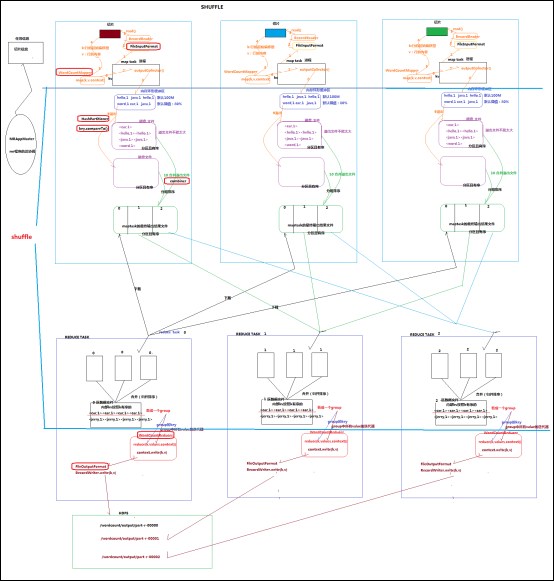
------------------------Yarn拿到程序怎样启动,这是今天关心的问题---------------------------------
PS:
day08 MapReduce的更多相关文章
- Mapreduce的文件和hbase共同输入
Mapreduce的文件和hbase共同输入 package duogemap; import java.io.IOException; import org.apache.hadoop.co ...
- mapreduce多文件输出的两方法
mapreduce多文件输出的两方法 package duogemap; import java.io.IOException; import org.apache.hadoop.conf ...
- mapreduce中一个map多个输入路径
package duogemap; import java.io.IOException; import java.util.ArrayList; import java.util.List; imp ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- [Hadoop in Action] 第5章 高阶MapReduce
链接多个MapReduce作业 执行多个数据集的联结 生成Bloom filter 1.链接MapReduce作业 [顺序链接MapReduce作业] mapreduce-1 | mapr ...
- MapReduce
2016-12-21 16:53:49 mapred-default.xml mapreduce.input.fileinputformat.split.minsize 0 The minimum ...
- 使用mapreduce计算环比的实例
最近做了一个小的mapreduce程序,主要目的是计算环比值最高的前5名,本来打算使用spark计算,可是本人目前spark还只是简单看了下,因此就先改用mapreduce计算了,今天和大家分享下这个 ...
- MapReduce剖析笔记之八: Map输出数据的处理类MapOutputBuffer分析
在上一节我们分析了Child子进程启动,处理Map.Reduce任务的主要过程,但对于一些细节没有分析,这一节主要对MapOutputBuffer这个关键类进行分析. MapOutputBuffer顾 ...
- MapReduce剖析笔记之七:Child子进程处理Map和Reduce任务的主要流程
在上一节我们分析了TaskTracker如何对JobTracker分配过来的任务进行初始化,并创建各类JVM启动所需的信息,最终创建JVM的整个过程,本节我们继续来看,JVM启动后,执行的是Child ...
随机推荐
- day17-json格式转换
Json简介:Json,全名 JavaScript Object Notation,是一种轻量级的数据交换格式.Json最广泛的应用是作为AJAX中web服务器和客户端的通讯的数据格式.现在也常用于h ...
- NTT模板(无讲解)
#include<bits/stdc++.h>//只是在虚数部分改了一下 using namespace std; typedef long long int ll; ; ; ; ; ll ...
- CSS--margin塌陷
margin塌陷 解决方法: 1.给父级顶加上一条线,不太合适. 2.bfc block format context 设定bfc后,特定的盒子会遵循另一套语法规则,解决了margin塌陷 触发bfc ...
- 泛型算法,排序的相关操作,lower_bound、upper_bound、equal_range
body, table{font-family: 微软雅黑; font-size: 13.5pt} table{border-collapse: collapse; border: solid gra ...
- 深入理解java虚拟机---对象的访问定位(十)
引用其他人的文章: https://www.cnblogs.com/YYfish/p/6722258.html 那是怎么访问对象呢? java 程序是通过栈上的reference数据来操作堆上的具体对 ...
- MATLAB 地图工具箱 m_map 的安装和入门技巧(转)
reference: http://blog.sina.com.cn/s/blog_8fc890a20102v6pm.html 需要用一些地图工具,arcgis懒得装了,GMT(generic m ...
- TensorFlow函数:tf.zeros_like
tf.zeros_like函数 tf.zeros_like( tensor, dtype=None, name=None, optimize=True ) 定义在:tensorflow/python/ ...
- python-web-django前后端交互
1.前端请求数据URL由谁来写 在开发中,URL主要是由后台来写好给前端. 若后台在查询数据,需要借助查询条件才能查询到前端需要的数据时,这时后台会要求前端提供相关的查询参数(即URL请求的参数). ...
- Ubuntu16.04下通过tar.gz包安装MySQL5.5.52
1.下载 tar.gz包 : https://dev.mysql.com/downloads/mysql/ 2. // 安装依赖 sudo apt-get install libaio-dev // ...
- 【Python】混合驱动实例
keywords2.txt: get||ie||{urls.txt} get||chrome||http://www.iciba.com main.py: from selenium import w ...