基于word2vec训练词向量(二)
转自:http://www.tensorflownews.com/2018/04/19/word2vec2/
一.基于Hierarchical Softmax的word2vec模型的缺点
上篇说了Hierarchical Softmax ,使用霍夫曼树结构代替了传统的神经网络,可以提高模型训练的效率。但是如果基于Hierarchical Softmax的模型中所以词的位置是基于词频放置的霍夫曼树结构,词频越高的词在离根节点越近的叶子节点,词频越低的词在离根节点越远的叶子节点。也就是说当该模型在训练到生僻词时,需要走很深的路径经过更多的节点到达该生僻词的叶子节点位置,这样在训练的过程中,会有更多的θ_i向量要更新。举个例子,如图一所示:
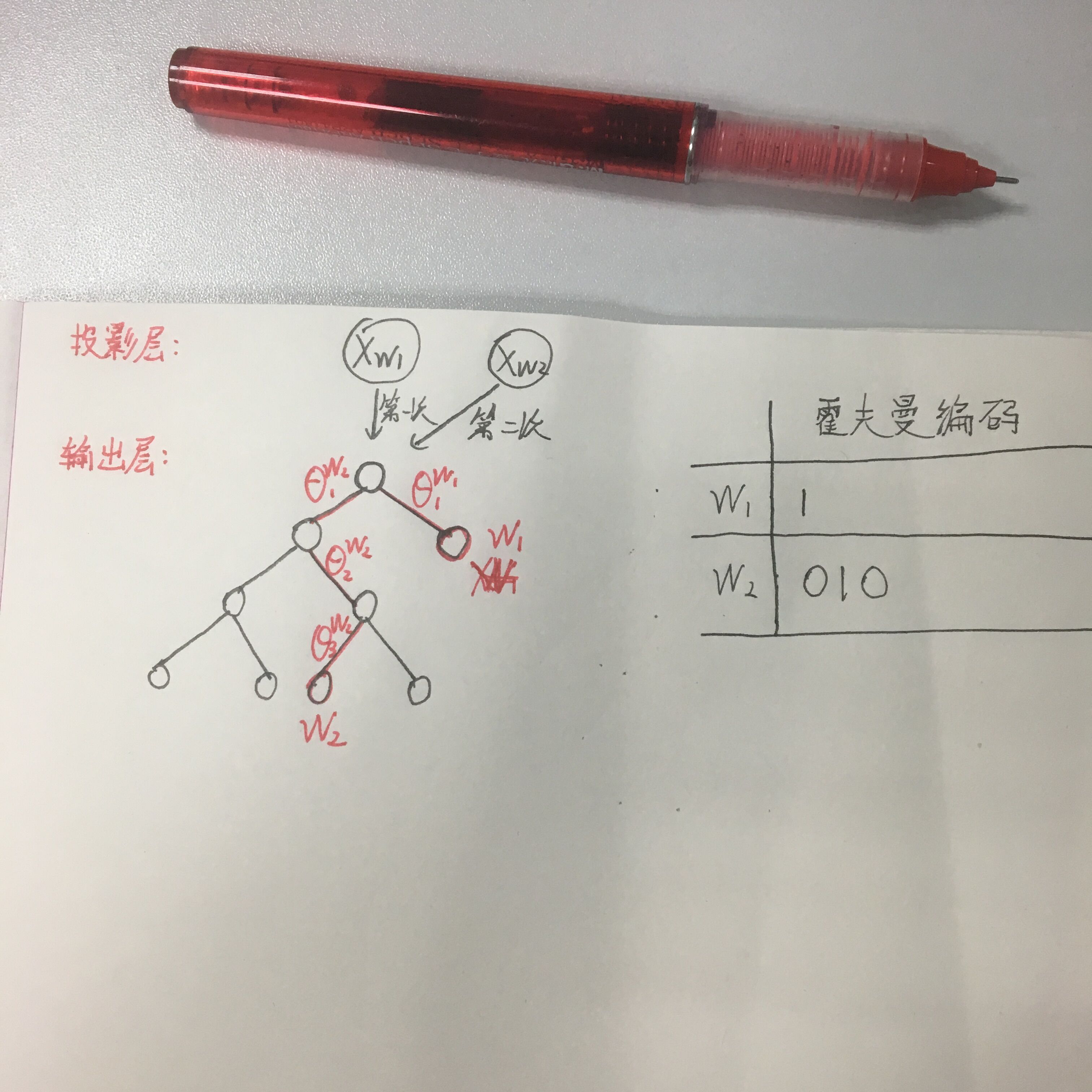
图一
假设规定霍夫曼树编码,往左子树编码为0,右子树编码为1,假设现有一棵霍夫曼树,第一层右子树是一个叶子节点词w_1,该词霍夫曼编码是1,那么在训练过程只需要训练θ_1这个向量更新他只需要一个计算量。假如现在存在一个路径很深的叶子节点在第五层词w_2(根节点在第0层),其霍夫曼编码是010,那么训练到该叶子节点时需要计算并更新3个θ_i参数。这样对于生僻词的训练是很不友好的。
二.Negative SampliNg模型
Negative Sampling是word2vec模型的另一种方法,采用了Negative Sampling(负采样)的方法来求解。
Negative Sampling的网络结构(CBOW方式训练),如图二所示:
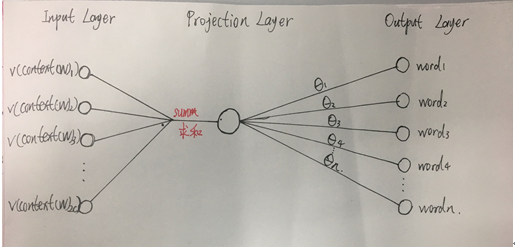
图二
Negative Sampling与Hierarchical Softmax最大的不同它放弃了投影层到输出层的霍夫曼树结构,以CBOW模型训练为例,Negative Sampling每次选取一个中心词是w_0,若neg别的词w_i,i=1,2,3…neg(一般neg值很小,不超过10),和他周围上下文共有2c个词,记为context(W)。其中中心词与context(w_0)相关,所以以context(w_0)作为输入,中心词w作为输出是一个正例。而context(w_0)作为输入,与每个w_i并不真实与输入相关的词作输出构成了neg个负例。一共有neg+1个训练样本来训练,这种训练方式就叫做Negative Sampling(负采样)训练。利用这一个正例和neg个负例进行二元逻辑回归,每次迭代都更新了θ_i(i=0,1,2…neg)和context(w)就可以得到每个词对应的θ_i向量和每个词的词向量。
Negative Sampling选取中心词,基于中心词的上下文词以及反例词示例:
假如现在存在的词汇表里有:Beijin Shanghai Guangzhou Shenzhen Chaoshan beef meatball is delicious
windy sunshine computer …若干词,其中 Chaoshan beef meatball is delicious 是一句话,我们选取这句话中meatball为中心词w_0,那么上下文context(w_0)是[Chaoshan,beef,is,delicious],假设选取两个反例词Shanghai,sunshine为w_1,w_2。那么(context(w_0),w_0)就是一个正例,(context(w_0),w_1)和(context(w_0),w_2)就是两个反例。训练这一个正例和两个反例,更新w_0,w_1,w_2对应的参数θ_w和context(w_0)中上下文的词向量。如图三所示:
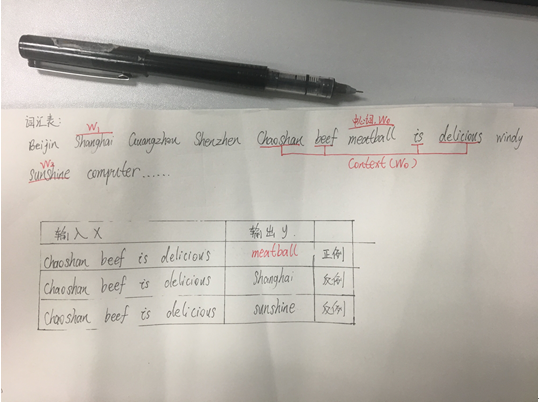
图三
例子中的训练过程如图四所示:
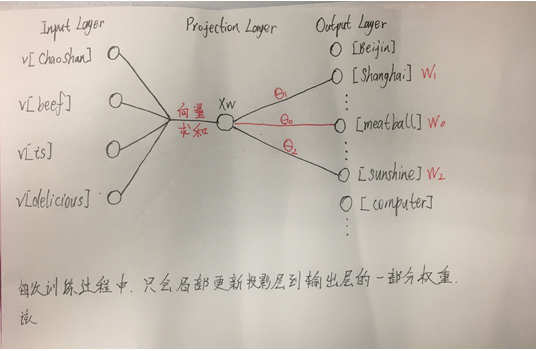
图四
一次迭代训练中,输入为Context(w_0),输出为w_0(正例),w_1,w_2。分别用梯度上升法依次更新θ_1,θ_2,θ_3和[Chaoshan],[beef],[is],[delicious]对应的词向量。注意,这里的θ_i跟Hierarchical Softmax中一样,只是投影层到输出层的权重,不代表词向量。
三.Negative Sampling优化原理
给定一个训练样本,一个词w和它的上下文Context(w),(Context(w),w)作为一个正例。通过负采样选择了词汇表中其他一些词作为负例的输出值,(Context(w),w_i)作为neg个负例,获得了负例子集NEG(w),对于正负样本,分别给定一个标签:
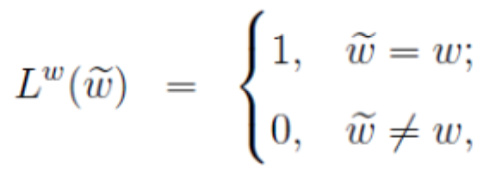
公式一
对于给定正样本(Context(w),w),对于现在的一个正样本{w}和neg个负样本NEG(w)中,我们希望最大化似然函数:
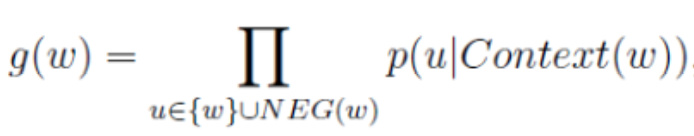
公式二
其中p(u|Context(w))代表的是正例词w+负例词NEG(W)其中一个词对应的概率:
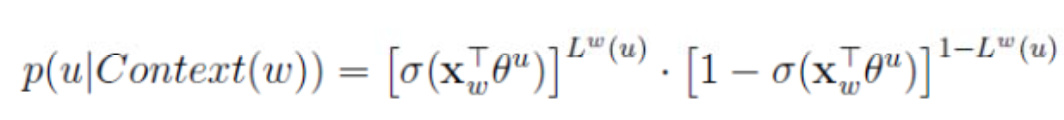
公式三
也就是说,通过sigmoid函数求每个样本的概率,我们希望最大化正例w的概率,最小化负例的概率。将g(w)变成对数似然函数,再使用梯度上升法,每次迭代更新context(w)中上下文词对应的词向量和θ_i。其更新原理和上一篇的Hierarchical Softmax原理相同,这里就不再重复推导。
整个基于CBOW训练方式的Negative Sampling训练伪代码如图五所示:

图五
先随机初始化所有词汇表的词向量,还有θ_i,在一次迭代中,输入几个上下文词context(w)词向量求和平均以后,开始从中心词w和负例词NEG(w)依次反向对与其对应的θ_i梯度上升法更新θ_i和context(w)上下文的词向量。
四.Negative Sampling选取负例词原理
Negative Sampling训练过程推理都说完了,现在我们来说下最后一个问题,如何选取负例词,得到neg个负例。我们想,频率更高的词应该要有更高的概率被采样,将所有词根据词的词频放在长度为1的线段中随机选取符合我们的设定的采样方法:
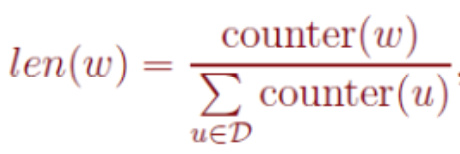
公式四
其中counter(w)是w的词频于是我们公平的将不同词频的词放到了长度为1的线段中,如图五所示:

图六
word2vec中,我们对这个长度为1的线段改成长度为M,这个长度M的线段刻度之间是等间隔的,即1/M:
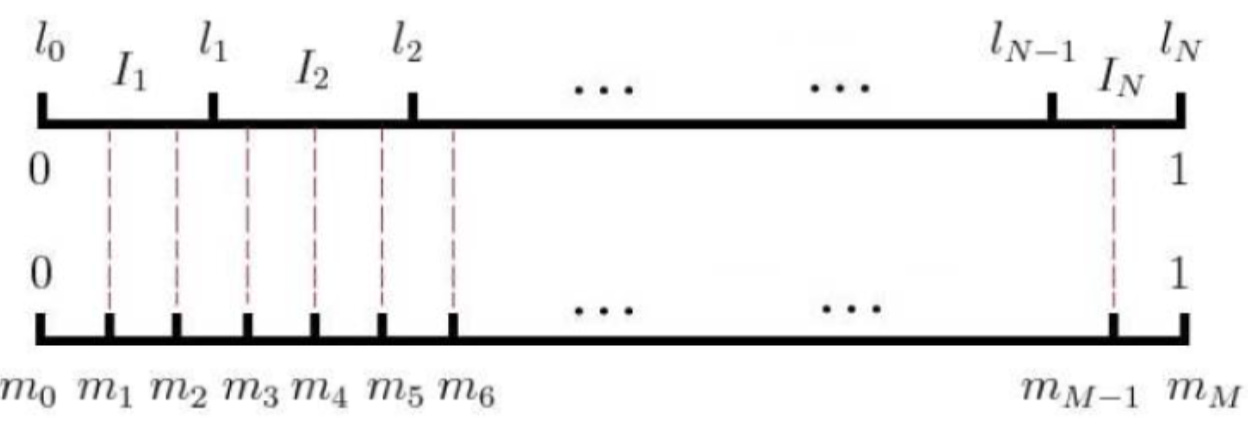
图七
这样只要每次生成随机数0~M之间的整数,这样就能选到对应I_i的词了,每次去neg个词,如果选到的负例词刚好是中心词w本身,则跳过继续重新生成随机数0~M去找新的负例词。
五.代码实现
在python中使用gensim包调用Word2vec方便快捷,在这简单演示下,gensim下word2vec详细的参数不在此详细阐述。本次的数据是之前比赛中公开的旅游数据集,具体的word2vec训练词向量步骤如下:
1)导包:导入必要的包,其中的jieba是为了给文本进行分词。
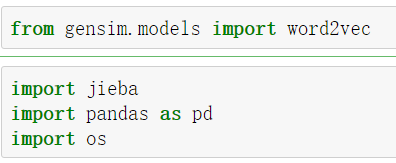
2)导入数据集:

3)提取所需要的数据,收集到10W调用户评价的数据:

4)给提取的数据进行分词,用jieba分词,分完后放入新建的文件中:
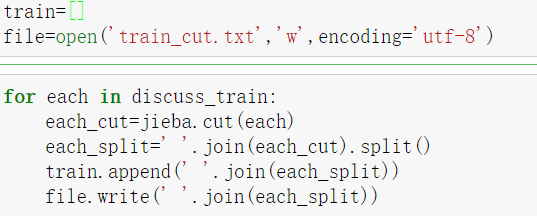
5)加载分好词的文件,并用word2vec进行训练:

6)word2vec训练完词向量后,查看效果,以查找某一个词的相似词为例:

六.总结
Negative Sampling相比于Hierarchical Softmax,摒弃了投影层到输出层的霍夫曼树结构,改成全连接。Negative Sampling虽然投影层到输出层是全连接,但是每次只会取输出层中的中心词和少数用作负例的词进行梯度上升法更新θ_i和context(w)上下文词对应的词向量,并没有像DNN中对所有位置进行计算。这样相比于Hierarchical Softmax,在对生僻词进行训练时,训练时要找的反例词个数不变,所以每次训练更新的θ_i参数的个数不变,花费的训练时间不变。这样就会让训练速度更稳定,不会因为生僻词而使训练耗费更多的时间,所以Negative Sampling训练生僻词的词向量会更稳定更快些。
Word2vec的训练方式有两种,分别是CBOW和Skip-gram。Word2vec训练词向量的加速训练方式有两种,一种是Hierarchical Softmax,一种是Negative Sampling。Word2vec训练出来的词向量效果挺好,其训练出来的词向量可以衡量不同词之间的相近成都。但是word2vec也存在缺点,因为在使用context(w)中并没有考虑w上下文的词序问题,这就造成了训练时输入层所有的词都是等价的,这样训练出来的词向量归根结底只包含大量语义,语法信息。所以一般想拥有比较好的词向量,还是应该在一个有目标导向的神经网络中训练,比如目标是情感分析,在这样的神经网络中去取得第一层embedding层作为词向量,其表达的的效果应该会比word2vec训练出来的效果好得多,当然一般我们可能不需要精准表达的词向量,所以用word2vec来训练出词向量,也是一种可选择的快速效率的方法。
基于word2vec训练词向量(二)的更多相关文章
- 基于word2vec训练词向量(一)
转自:https://blog.csdn.net/fendouaini/article/details/79905328 1.回顾DNN训练词向量 上次说到了通过DNN模型训练词获得词向量,这次来讲解 ...
- 文本分布式表示(二):用tensorflow和word2vec训练词向量
看了几天word2vec的理论,终于是懂了一些.理论部分我推荐以下几篇教程,有博客也有视频: 1.<word2vec中的数学原理>:http://www.cnblogs.com/pegho ...
- 基于Doc2vec训练句子向量
目录 一.Doc2vec原理 二.代码实现 三.总结 一.Doc2vec原理 前文总结了Word2vec训练词向量的细节,讲解了一个词是如何通过word2vec模型训练出唯一的向量来表示的.那接着 ...
- word2vec预训练词向量
NLP中的Word2Vec讲解 word2vec是Google开源的一款用于词向量计算 的工具,可以很好的度量词与词之间的相似性: word2vec建模是指用CBoW模型或Skip-gram模型来计算 ...
- 文本分类实战(一)—— word2vec预训练词向量
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 词表征 3:GloVe、fastText、评价词向量、重新训练词向量
原文地址:https://www.jianshu.com/p/ca2272addeb0 (四)GloVe GloVe本质是加权最小二乘回归模型,引入了共现概率矩阵. 1.基本思想 GloVe模型的目标 ...
- tensorflow如何正确加载预训练词向量
使用预训练词向量和随机初始化词向量的差异还是挺大的,现在说一说我使用预训练词向量的流程. 一.构建本语料的词汇表,作为我的基础词汇 二.遍历该词汇表,从预训练词向量中提取出该词对应的词向量 三.初始化 ...
- DNN模型训练词向量原理
转自:https://blog.csdn.net/fendouaini/article/details/79821852 1 词向量 在NLP里,最细的粒度是词语,由词语再组成句子,段落,文章.所以处 ...
- PyTorch在NLP任务中使用预训练词向量
在使用pytorch或tensorflow等神经网络框架进行nlp任务的处理时,可以通过对应的Embedding层做词向量的处理,更多的时候,使用预训练好的词向量会带来更优的性能.下面分别介绍使用ge ...
随机推荐
- 集合求交集 & 去除列表中重复的元素
集合求交集: set1 = {1,2,3,4,5} set2 = {4,5,6,7,8} 交集:set3 = set1 & set2 print(ste3) #结果为{4,5} 或者ste1. ...
- html简单网页1
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- React之生命周期
哈喽,这是我的第一篇博客,请大家多多关照~ 追根溯源:What's the lifeCycle? 生命周期函数指在某一时刻组件会自动调用执行的函数: React生命周期概览: 接下来我们就着生命周期的 ...
- 对oracle中SQL优化的理解
Oracle数据库里SQL优化的终极目标就是要缩短目标SQL语句的执行时间.要达到上述目的,我们通常只有如下三种方法可以选择:1.降低目标SQL语句的资源消耗.2.并行执行目标SQL语句.3.平衡系统 ...
- react native touchable
<Button style={{marginTop: 30}} onPress={() => { Alert.alert("你点击了按钮!"); }} onPressI ...
- 香港低价linux虚拟主机,
https://www.sugarhosts.com/zh-cn/hosting/shared-web-hosting Shared Baby 36 个月 ¥ 26.99 19 99 · / 月 续费 ...
- XML 文档(1, 2)中有错误:不应有 <xml xmlns=''>
症状 用XmlSerializer进行xml反序列化的时候,程序报错: 不应有 <xml xmlns=''>. 说明: 执行当前 Web 请求期间,出现未经处理的异常.请检查堆栈跟踪信息, ...
- java取得汉字拼音(pinyin4j)
jar包:pinyin4j.jar 基本用法: String[] pinyin = PinyinHelper.toHanyuPinyinStringArray('重'); 例如“重”字,该方法返回一个 ...
- ASP.Net中的四种状态保持机制
每个人上网可多有过这样的情况,当我们登陆某个网站时,在登陆的旁边会有一个 "记住我" 的复选框,有的网站还会让用户选择记住我.这个记住我是怎么实现的呢? 其实就用利用的是cooki ...
- python安装pandas模块
直接安装时报错了 localhost:~ ligaijiang$ pip3 install pandas Collecting pandas Downloading https://files.pyt ...