Tesseract-OCR-04-使用 jTessBoxEditor 进行训练
Tesseract-OCR-04-使用 jTessBoxEditor 进行训练
- 本篇是关于 jTessBoxEditor 进行训练,使 Tesseract-OCR 文字识别准确率得到极大的提高,本篇完善了很多细节,初学者也可以看懂,一起学习吧!
- 想要一遍成功要细心关注【注意】,我踩过的坑都标出来了
训练的大致步骤:
- 1.安装 jTessBoxEditor
- 2.获取样本文件
- 3.Merge 样本文件
- 4.生成 .box 文件
- 5.定义字符配置文件
- 6.字符矫正
- 7.执行批处理文件
- 8.将生成的 num.trainddata 放入 Tesseract 安装目录的 tessdata 文件夹里
1.安装 jTessBoxEditor
- 下载jTessBoxEditor,地址https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
- 解压后得到jTessBoxEditor
- 由于这是由Java开发的,所以我们应该确保在运行jTessBoxEditor前先安装JRE(Java Runtime Environment,Java运行环境)
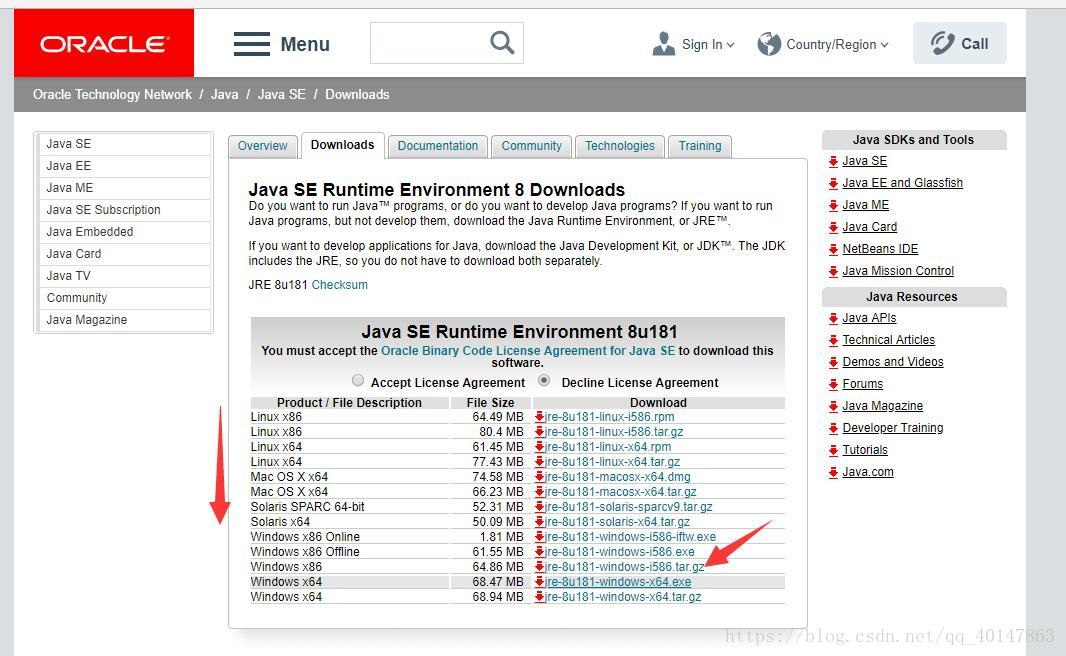
- 没有安装 jre 的可以到官网下载安装:
http://www.oracle.com/technetwork/java/javase/downloads/jre8-downloads-2133155.html
- jre 安装就不仔细介绍了,因为能找到这篇的,基本都安装过了,下面介绍 jTessBoxEditor
- 但是呢,这个 jTessBoxEditor ,不用安装,直接解压就可以,单击解压到或者直接拉出来就可以了

2.获取样本文件
- 我们可以用画图工具绘制样本文件,数量越多越好,我自己画了 5 张图作为训练的数据,如图:
- 【注意】:样本图像文件格式必须为tif\tiff格式,否则在Merge样本文件的过程中会出现 Couldn’t Seek 的错误。
- 再转格式嫌麻烦就直接拿走我的:https://pan.baidu.com/s/1hoTkxMVw5z_ve9hzftLOqw





3.Merge样本文件
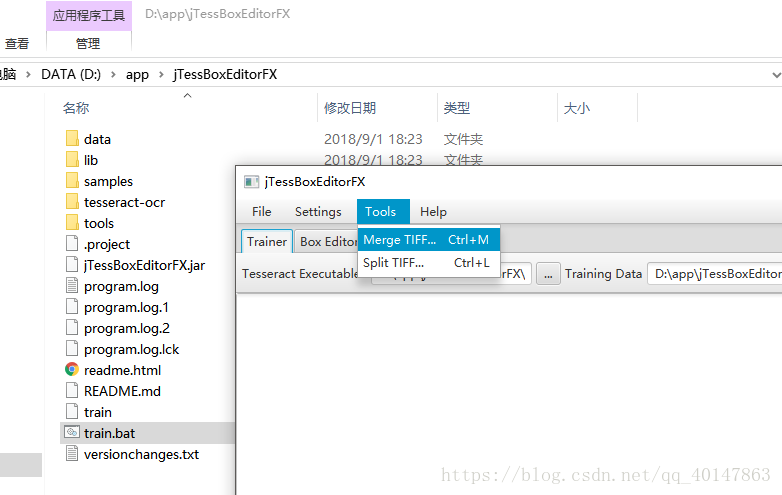
- 在安装目录找到一个【train.bat】打开 jTessBoxEditor >【Tools】>【Merge TIFF】
- 操作截图:
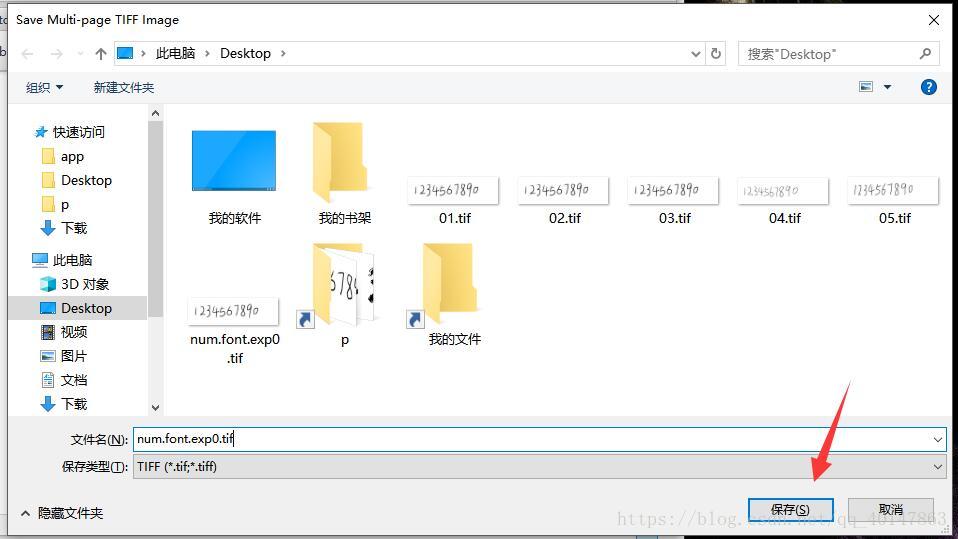
- 将样本文件全部选上,安装 Ctrl 键不松
- 【注意】:这里是没有界面化的提示的,选中后,点击【打开】,立马就是输入合成后的文件名界面,输入num.font.exp0.tif,点击【保存】
- 也就是将合并文件保存为 num.font.exp0.tif
4.生成BOX文件
- 打开 cmd 并切换至 num.font.exp0.tif 所在目录
- 使用 cd 目录名 进入目录
- 使用 cd.. 返回上一级目录
- 输入下面命令,生成文件名为num.font.exp0.box
tesseract num.font.exp0.tif num.font.exp0 batch.nochop makebox
【语法】:tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
【语法】:lang为语言名称,fontname为字体名称,num为序号;在tesseract中,一定要注意格式
- 操作截图
如果报错可能是没有进入合并好的 tif 文件目录下,也可能是没有换成自己用的文件名哦

5.定义字符配置文件
- 在文件夹文件夹内,新建一个文本文件,名为font_properties,删掉.txt,用记事本打开,写入内容为:
font 0 0 0 0 0
【语法】:<fontname> <italic> <bold> <fixed> <serif> <fraktur>
【语法】:fontname为字体名称,italic为斜体,bold为黑体字,
fixed为默认字体,serif为衬线字体,fraktur德文黑字体,
1和0代表有和无,精细区分时可使用
6.准备环节
- 将5个tif文件,num.font.exp0.tif,生成的num.font.exp0.box文件,还有font_properties文件放在同一个目录下
- 目前8个文件,截图:
7.字符矫正
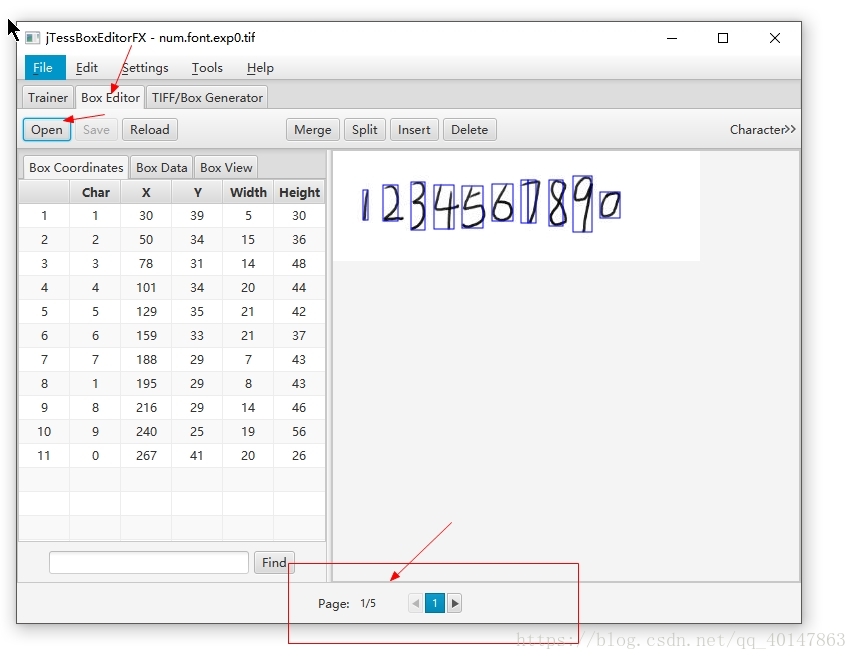
- 打开 jTessBoxEditor>【BOX Editor】> 【Open】,打开num.font.exp0.tif;矫正【Char】上的字符
- 操作截图:
- 【注意】:记得[Page]有好多页哦!修改后记得保存
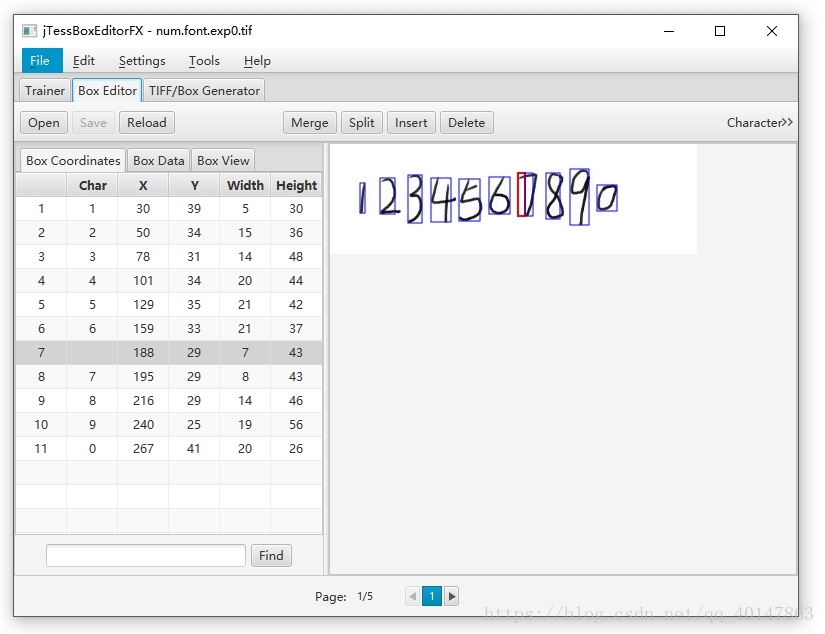
- 当然有可能生成的 box 文件后,会多一个盒子,它把7识别成了两个
- 处理方式:自己根据看到的数字修改char,如果不是完整字符就敲 空格,然后回车
- 操作截图:
- 然后就是依次处理 5 页
- 最后保存,替换原来的 box 文件
8.执行批处理文件
- 【注意】:执行该批处理文件前,先要目录下创建font_properties文件 ,也就是滴 5 步
- **在目标目录下,新建一个txt文件,复制代码,重命名为 do.bat,直接更改后缀名就可以 **
- 代码如下
echo Run Tesseract for Training..
tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train
echo Compute the Character Set..
unicharset_extractor.exe num.font.exp0.box
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
echo Clustering..
cntraining.exe num.font.exp0.tr
echo Rename Files..
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable
echo Create Tessdata..
combine_tessdata.exe num.
echo. & pause
- 保存后,双击执行即可,执行后会在文件夹生成很多文件,如下:
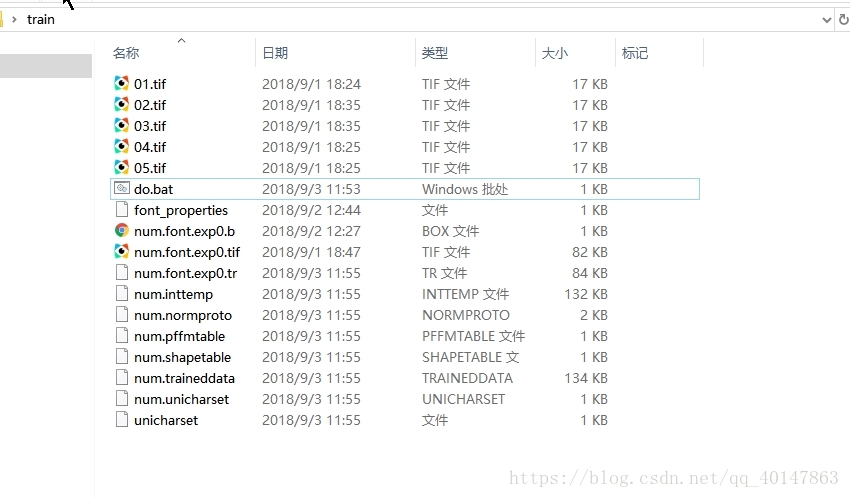
9.拷贝 num.trainddata 文件
- 最后将 num.trainddata 复制到 Tesseract-OCR 安装目录下的 tessdata 文件夹
- 【注意】:这里是【Tesseract-OCR 安装目录下的 tessdata 文件夹】
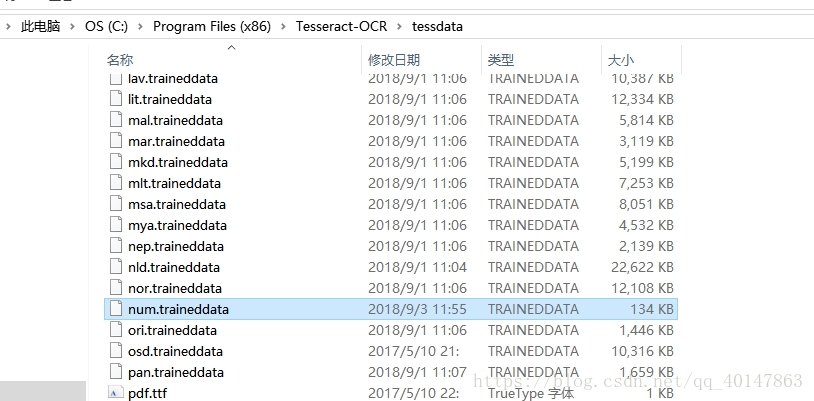
10.大功告成,测试结果
- 这里我是将图片 num1.jpg 放在了:D:\p
- 我们需要在 cmd 进入此目录
- 使用 cd 目录名 进入目录
- 使用 cd.. 返回上一级目录
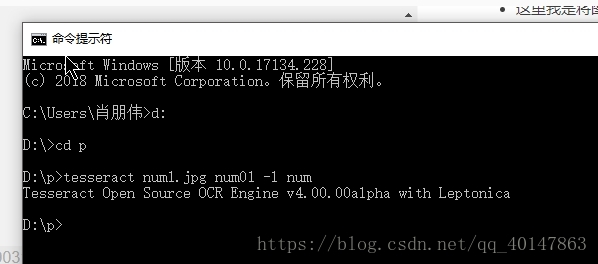
- 使用 Tesseract 命令:
- 【注意】:语言参数要设置成 num,就是我们刚才拷贝的,没拷贝 num.trainddata 文件不能使用
tesseract 文件名 保存的txt文件名 例:
tesseract num1.jpg num01 -l num
操作截图:
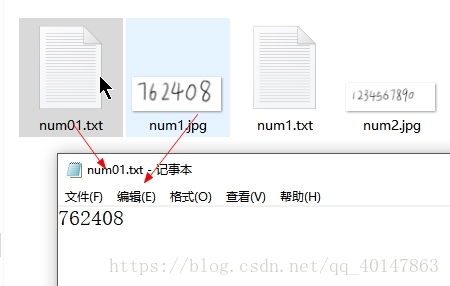
运行结果:
我们可以看到新生成的文件 num01 的内容为 762408,内容完全正确。细心的人会发现,最后一句指令,我们使用了指令[-l num]而不是[-l eng]。这说明,最后一次转换我们使用的是新生成的num语言的匹配库而不是默认的 eng 语言匹配库
我们可以看到,经过简单的训练,我们对于数字数据的转换准确率提高了很多
看到这里如果还没有安装工具,参考:Windows下 Tesseract-OCR 的安装与 环境变量配置
本篇完善了很多细节,初学者也可以看懂,奉上 原文链接,拜拜
更多文章链接:Tesseract 随笔
- 本笔记不允许任何个人和组织转载
Tesseract-OCR-04-使用 jTessBoxEditor 进行训练的更多相关文章
- tesseract ocr文字识别Android实例程序和训练工具全部源代码
tesseract ocr是一个开源的文字识别引擎,Android系统中也可以使用.可以识别50多种语言,通过自己训练识别库的方式,可以大大提高识别的准确率. 为了节省大家的学习时间,现将自己近期的学 ...
- 孤荷凌寒自学python第八十四天搭建jTessBoxEditor来训练tesseract模块
孤荷凌寒自学python第八十四天搭建jTessBoxEditor来训练tesseract模块 (完整学习过程屏幕记录视频地址在文末) 由于本身tesseract模块针对普通的验证码图片的识别率并不高 ...
- Tesseract OCR使用介绍
#Tesseract OCR使用介绍 ##目录[TOC] ##下载地址及介绍 官网介绍:http://code.google.com/p/tesseract-ocr/wiki/TrainingTess ...
- Tesseract——OCR图像识别 入门篇
Tesseract——OCR图像识别 入门篇 最近给了我一个任务,让我研究图像识别,从我们项目的screenshot中识别文字信息,so我开始了学习,与大家分享下. 我看到目前OCR技术有很多,最主要 ...
- 开源图片文字识别引擎——Tesseract OCR
Tessseract为一款开源.免费的OCR引擎,能够支持中文十分难得.虽然其识别效果不是很理想,但是对于要求不高的中小型项目来说,已经足够用了. 文字识别可应用于许多领域,如阅读.翻译.文献资料的检 ...
- Tesseract–OCR 库原理探索
一,简介: Tesseract is probably the most accurate open source OCR engine available. Combined with the Le ...
- Tesseract Ocr引擎
Tesseract Ocr引擎 1.Tesseract介绍 tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/t ...
- Python下Tesseract Ocr引擎及安装介绍
1.Tesseract介绍 tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/tesseract,目前最新的源码 ...
- Tesseract 3.04 + VS2013 配置心得(包括静态库版本号和Release版本号)
研究Tesseract也有几个星期了 走了一些弯路 网上有非常多VS2010的配置心得 但没有VS2013的, 找到一篇之后, 又发现会有一些小问题, 这里记录下来, 也为新人提供一些帮助. Tess ...
随机推荐
- JAVA数据结构--AVL树的实现
AVL树的定义 在计算机科学中,AVL树是最先发明的自平衡二叉查找树.在AVL树中任何节点的两个子树的高度最大差别为1,所以它也被称为高度平衡树.查找.插入和删除在平均和最坏情况下的时间复杂度都是.增 ...
- Linux下安装渗透测试框架Metasploit
我们先来说一种方法,直接从github来下载: git clone --depth=1 git://github.com/rapid7/metasploit-framework metasploit ...
- 更新Mac双系统多分区
前言制作Mac USB系统安装盘安装Mac OS 10.12制作win10 USB系统安装盘安装win10windows多分区实现 前言 同事有一台mac pro,系统是mac os 10.9+win ...
- Java设计模式之适配器模式(Adapter)
转载:<JAVA与模式>之适配器模式 这个总结的挺好的,为了加深印象,我自己再尝试总结一下 1.定义: 适配器模式把一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口不匹配而无法 ...
- android去除标题栏
在 AndroidManifast.xml 文件中 将 theme="@style/AppTheme" 改为 theme="@style/Theme.AppCompat. ...
- Windows加密API的功能分类
本地数据加密保护本地数据加密保护机制提供了简单的DAPI调用接口,密钥管理等等一概由系统来处理.DAPI的数据加密保护机制在用户登录会话范围或者本地计算范围,使用操作系统设计的方式加密保护数据和解密还 ...
- AtCoder Grand Contest 006 F - Blackout
Description 在 \(n*n\) 的棋盘上给出 \(m\) 个黑点,若 \((x,y)\),\((y,z)\) 都是黑点,那么 \((z,x)\) 也会变成黑点,求最后黑点的数量 题面 So ...
- Git - 远程库的创建与认证
前些日子因为某些原因,需要在windows上创建一个remote仓库. 由于实在是太麻烦而且时间紧急,就直接用了gitstack. 发现这个东西居然需要付费,未认证时只能创建两个用户. 其实对我而言足 ...
- nodejs图片上传
node中图片上传的中间键很多,比如formidable等,这里我们使用nodejs中的fs来实现文件上传处理: 1.安装中间键connect-multiparty npm install conne ...
- Ruby 踩坑 “Failed to build gem native extension”
ruby新手,总是会出现这样那样的问题,这里先记录下,希望能解决你得问题. 首先是安装ruby 环境,楼主愚钝,在公司和自己的电脑上来来回回整了好几天,每次安装 gem 包的时候总是报错,错误信息大致 ...