基于docker 搭建Elasticsearch5.6.4 分布式集群
说明:
准备2台机器,我这里有192.168.0. 和 192.168.0.164
192.168.0.164 作为master
192.168.0.107 作为普通node
一、环境
.docker 环境
.Elasticsearch5.6.4
.Elasticsearch-head: 插件
二、下载
head 只需要在一台机器上装就行了、我直接和master节点装在164上
docker pull elasticsearch:5.6.
docker pull mobz/elasticsearch-head:
三、设置elasticsearch 配置环境
1、master[192.168.0.164] 配置
es1.yml:
#集群名称 所有节点要相同
cluster.name: "mangues_es"
#本节点名称
node.name: master
#作为master节点
node.master: true
#是否存储数据
node.data: true
# head插件设置
http.cors.enabled: true
http.cors.allow-origin: "*"
#设置可以访问的ip 这里全部设置通过
network.bind_host: 0.0.0.0
#设置节点 访问的地址 设置master所在机器的ip
network.publish_host: 192.168.0.164
2、启动master
我的配置文件 和 data所在目录都设置在物理机器上,这里-v 映射下就可以了
docker run -d --name es1 -p : -p : -v /Users/mangues/Desktop/database/Elasticsearch/es1.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /Users/mangues/Desktop/database/Elasticsearch/esdata1:/usr/share/elasticsearch/data elasticsearch:5.6.
3、node[192.168.0.107] 配置
es2.yml
cluster.name: "mangues_es"
#子节点名称
node.name: node
#不作为master节点
node.master: false
node.data: true http.cors.enabled: true
http.cors.allow-origin: "*" network.bind_host: 0.0.0.0
network.publish_host: 192.168.0.107
#设置master地址
discovery.zen.ping.unicast.hosts: [192.168.0.164]
2、启动node
docker run -d --name es2 -p : -p : -v /Users/mangues/Desktop/database/Elasticsearch/es2.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /Users/mangues/Desktop/database/Elasticsearch/esdata1:/usr/share/elasticsearch/data elasticsearch:5.6.
四、开启head查看
docker run -p : mobz/elasticsearch-head:
打开链接 http://192.168.0.164:9100/ 查看节点状态
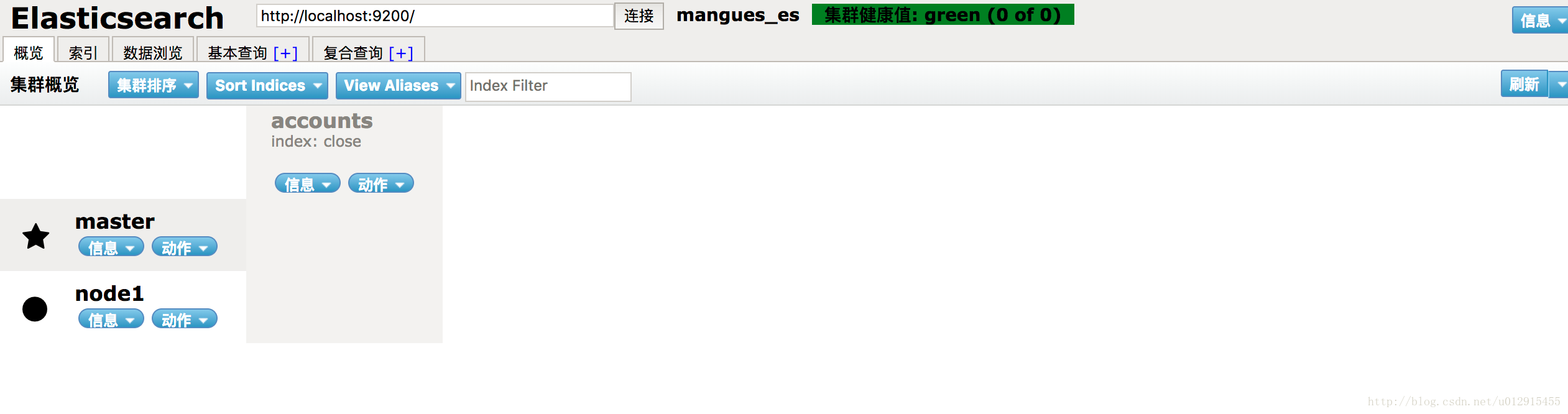
五、其他
1、安装docker-ui 可视化docker管理工具
docker run -d -p : --privileged -v /var/run/docker.sock:/var/run/docker.sock uifd/ui-for-docker
打开链接 http://192.168.0.164:9000/ 查看164机器的docker
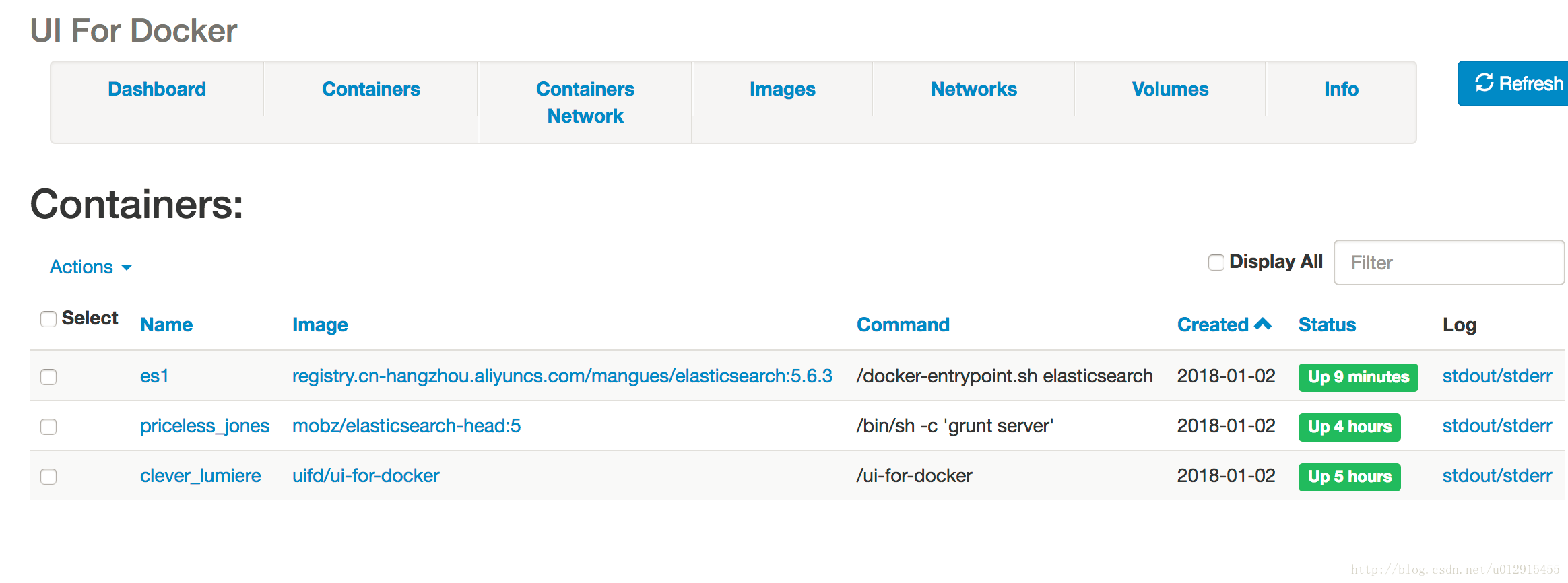
2、问题
elasticsearch max virtual memory areas vm.max_map_count [] is too low
解决办法:
、切换到root用户修改配置sysctl.conf vi /etc/sysctl.conf 添加下面配置: vm.max_map_count= 并执行命令: sysctl -p 然后,重新启动elasticsearch,即可启动成功。
3. 安装ik 中文分词插件
进入容器
$ sudo docker exec -it imageId /bin/bash
$ cd plugins
$ wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.6.4/elasticsearch-analysis-ik-5.6.4.zip
$ unzip elasticsearch-analysis-ik-5.6..zip
$ rm elasticsearch-analysis-ik-5.6..zip
利用
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.6.4/elasticsearch-analysis-ik-5.6.4.zip
会出问题:
java.io.FileNotFoundException: /usr/share/elasticsearch/config/analysis-ik/IKAnalyzer.cfg.xml (No such file or directory)
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012915455/article/details/78952068
基于docker 搭建Elasticsearch5.6.4 分布式集群的更多相关文章
- 搭建Elasticsearch5.6.8 分布式集群
集群搭建 1.master[192.168.101.175] 配置elasticsearch.yml #集群名称 所有节点要相同 cluster.name: my-application #本节点名称 ...
- 基于winserver的Apollo配置中心分布式&集群部署实践(正确部署姿势)
基于winserver的Apollo配置中心分布式&集群部署实践(正确部署姿势) 前言 前几天对Apollo配置中心的demo进行一个部署试用,现公司已决定使用,这两天进行分布式部署的时候 ...
- (转)基于keepalived搭建MySQL的高可用集群
基于keepalived搭建MySQL的高可用集群 原文:http://www.cnblogs.com/ivictor/p/5522383.html MySQL的高可用方案一般有如下几种: keep ...
- 亿级Web系统搭建:单机到分布式集群
亿级Web系统搭建:单机到分布式集群 当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压 ...
- docker swarm快速部署redis分布式集群
环境准备 四台虚拟机 192.168.2.38(管理节点) 192.168.2.81(工作节点) 192.168.2.100(工作节点) 192.168.2.102(工作节点) 时间同步 每台机器都执 ...
- [转]亿级Web系统搭建:单机到分布式集群
当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压力带来问题,我们需要在Web系统架构层 ...
- 亿级Web系统搭建:单机到分布式集群【转】
当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压力带来问题,我们需要在Web系统架构层 ...
- Ganglia环境搭建并监控Hadoop分布式集群
简介 Ganglia可以监控分布式集群中硬件资源的使用情况,例如CPU,内存,网络等资源.通过Ganglia可以监控Hadoop集群在运行过程中对集群资源的调度,作为简单地运维参考. 环境搭建流程 1 ...
- 一张图讲解最少机器搭建FastDFS高可用分布式集群安装说明
很幸运参与零售云快消平台的公有云搭建及孵化项目.零售云快消平台源于零售云家电3C平台私有项目,是与公司业务强耦合的.为了适用于全场景全品类平台,集团要求项目平台化,我们抢先并承担了此任务.并由我来主 ...
随机推荐
- 如何查看VisualStudio的编译, 链接命令
VisualStudio默认是不显示编译命令的,如何查看呢. 对于链接器: 项目属性 -> 配置属性 -> 链接器 -> 常规 -> 显示进度 -> 设为 "/ ...
- redis命令使用
set key value get key 删除key (返回被移除key的数量.):del key 检查给定key是否存在(若key存在,返回1,否则返回0.):exists key > ex ...
- 使用Fiddler调试线上JS代码
在下面的命令框输入“select script”回车来筛选js请求 将HTTP请求重定向到本地的文件,进行web调试.这种调试方式不需要发布到线上再验证,避免了修改不成功.对用户造成影响的风险 左边一 ...
- css 禅意花园 笔记
1. FOUC(Flash Of Unstyled Content) 现象( 在某些情况下,IE加载网页时会出现短暂的CSS样式失效. a: 只发生在Windows上的 IE (5.0版本以上) b ...
- datagrid后台分页js
$(function () { gridbind(); bindData(); }); //表格绑定function gridbind() { $('#dg').datagrid({ title: ' ...
- bash脚本IFS=',' read的意思
IFS is the Input Field Separator, which means the string read will be split based on the characters ...
- requirejs学习(一)
requirejs学习(一) 随着网站功能逐渐丰富,网页中的js也变得越来越复杂和臃肿,各种依赖(插件等)也逐渐增多,原有通过script标签来导入一个个的js文件这种方式已经不能满足现在的需求,我们 ...
- TortoiseGit上传项目代码到github方法(超简单)
Github是咱广大开发者用的非常多的项目代码版本管理网站,项目托管可以是私人的(private)或者公开的(public),私人的收费,一个月7美金.咱这里就只说我们个人使用的,一般都是代码对外开放 ...
- ListView setOnItemClickListener无效原因具体分析
前言 近期在做项目的过程中,在使用listview的时候遇到了设置item监听事件的时候在没有回调onItemClick 方法的问题. 我的情况是在item中有一个Buttonbutton. 所以不会 ...
- jq 之Autocomplete 引发联想及思考
前情纪要:JQuery UI 是以 JQuery 为基础的开源 JavaScript 网页用户界面代码库.包含底层用户交互.动画.特效和可更换主题的可视控件,这些控件主要包括:Accordion,Au ...