大数据学习--day03(运算符、流程控制语句)
运算符、流程控制语句

自增自减容易出错的地方:
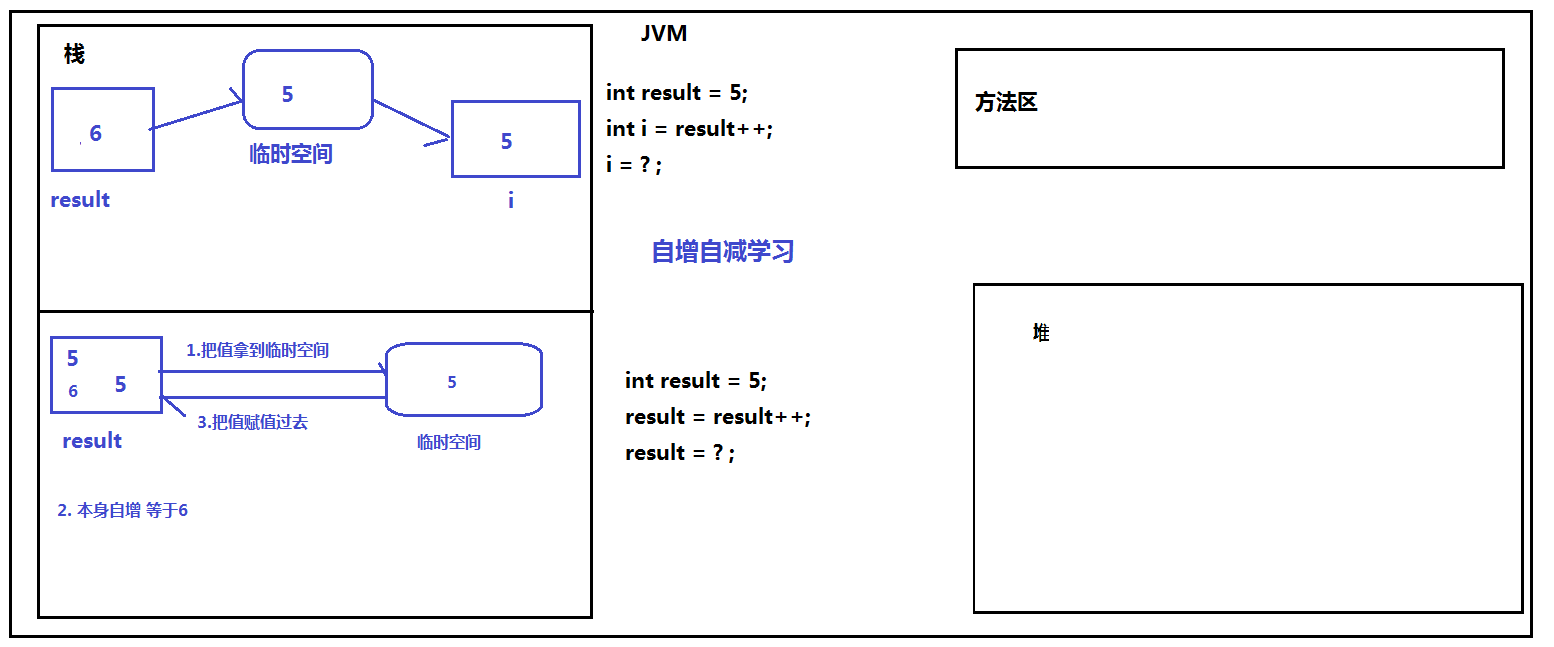

& && 有何区别
| || 有何不同之处
三目运算符:
位运算符
<< 左移
>> 右移
>>> 无符号右移
if语句同c#不讲了
大数据学习--day03(运算符、流程控制语句)的更多相关文章
- 大数据学习day38----数据仓库01-----区域字典的生成
更多内容见文档 1. 区域字典的生成 mysql中有如下表格数据 现要将这类数据转换成(GEOHASH码, 省,市,区)如下所示 (1)第一步:在mysql中使用sql语句对表格数据进行整理(此处使用 ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习笔记——Java篇之集合框架(ArrayList)
Java集合框架学习笔记 1. Java集合框架中各接口或子类的继承以及实现关系图: 2. 数组和集合类的区别整理: 数组: 1. 长度是固定的 2. 既可以存放基本数据类型又可以存放引用数据类型 3 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习之Linux进阶02
大数据学习之Linux进阶 1-> 配置IP 1)修改配置文件 vi /sysconfig/network-scripts/ifcfg-eno16777736 2)注释掉dhcp #BOOTPR ...
随机推荐
- Netty入门1之----认识Netty
Netty 什么是Netty? Netty 是一个利用 Java 的高级网络的能力,隐藏其背后的复杂性而提供一个易于使用的 API 的客户端/服务器框架. Netty 是一个广泛使用的 Java ...
- QT的mouseMoveEvent事件失效
void TalkWindow::enterEvent(QEvent *event){ grabMouse();}void TalkWindow::leaveEvent(QResizeEvent *e ...
- Python学习---进程 1225
进程创建 进程创建: 第一种:直接创建 第二种:利用类来实现 第一种:直接创建 from multiprocessing import Process import time def f(name): ...
- python IO 文件读写
IO 由于CPU和内存的速度远远高于外设的速度,所以,在IO编程中,就存在速度严重不匹配的问题. 如要把100M的数据写入磁盘,CPU输出100M的数据只需要0.01秒,可是磁盘要接收这100M数据可 ...
- 使用with子句优化代码中重复查询
/*好处: 1. 性能更好,一份复制(类似SYS_TMP...),多份使用. 2. 结构清晰,预先定义. 3. 代码修改不必修改多处. 请注意观察语句1和语句2执行 ...
- 使用nodejs代码在SAP C4C里创建Individual customer
需求:使用nodejs代码在SAP Cloud for Customer里创建Individual customer实例. 代码: var createAndBind = require('../je ...
- 财务软件(gnucash)
apt-get install gnucash
- Java对象表示方式1:序列化、反序列化的作用
1.序列化是的作用和用途 序列化:把对象转换为字节序列的过程称为对象的序列化. 反序列化:把字节序列恢复为对象的过程称为对象的反序列化. 对象的序列化主要有两种用途: 1) 把对象的字节序列永久地保存 ...
- C/C++心得-从内存开始
因工作与自身各方面需要,开始重新学C,其实说重新也不太准,原来只是大学里面接触过,且还未得多少精髓就转其他开发,不过也正是因此才有了重新学习的必要,基础部分的心得将通过博文记录下来,对于初学者应该有些 ...
- HDU 1698 【线段树,区间修改 + 维护区间和】
题目链接 HDU 1698 Problem Description: In the game of DotA, Pudge’s meat hook is actually the most horri ...