【转】自编码算法与稀疏性(AutoEncoder and Sparsity)
目前为止,我们已经讨论了神经网络在有监督学习中的应用。在有监督学习中,训练样本时有类别标签的。现在假设我们只有一个没带类别标签的训练样本集合 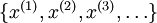 ,其中
,其中 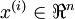 。自编码神经网络是一种无监督学习算法,它使用了反向传播算法,并让目标值等于输入值,比如
。自编码神经网络是一种无监督学习算法,它使用了反向传播算法,并让目标值等于输入值,比如 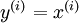 。下图是一个自编码神经网络的示例。
。下图是一个自编码神经网络的示例。
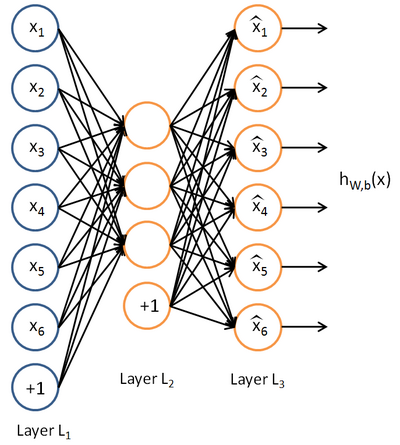
自编码神经网络尝试学习一个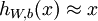 的函数。换句话说,它尝试逼近一个恒等函数,从而使得
的函数。换句话说,它尝试逼近一个恒等函数,从而使得 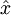 接近于输入
接近于输入  。恒等函数虽然看上去不太有学习的意义,但是当我们为自编码神经网络加入某些限制,比如限定隐藏神经元的数量,我们就可以从输入数据中发现一些有趣的结构。举例来说,假设某个自编码神经网络的输入 是一张
。恒等函数虽然看上去不太有学习的意义,但是当我们为自编码神经网络加入某些限制,比如限定隐藏神经元的数量,我们就可以从输入数据中发现一些有趣的结构。举例来说,假设某个自编码神经网络的输入 是一张 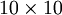 图像(共100个像素)的像素灰度值,于是
图像(共100个像素)的像素灰度值,于是 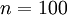 ,其隐藏层
,其隐藏层 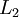 中有50个隐藏神经元。注意,输出也是100维的
中有50个隐藏神经元。注意,输出也是100维的 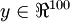 。由于只有50个隐藏神经元,我们迫使自编码神经网络去学习输入数据的压缩表示,也就是说,它必须从50维的隐藏神经元激活度向量
。由于只有50个隐藏神经元,我们迫使自编码神经网络去学习输入数据的压缩表示,也就是说,它必须从50维的隐藏神经元激活度向量 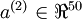 中重构出100维的像素灰度值输入 。如果网络的输入数据是完全随机的,比如每一个输入
中重构出100维的像素灰度值输入 。如果网络的输入数据是完全随机的,比如每一个输入 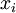 都是一个跟其它特征完全无关的独立同分布高斯随机变量,那么这一压缩表示将会非常难学习。但是如果输入数据中隐含着一些特定的结构,比如某些输入特征是彼此相关的,那么这一算法就可以发现输入数据中的这些相关性。事实上,这一简单的自编码神经网络通常可以学习出一个跟主元分析(PCA)结果非常相似的输入数据的低维表示。
都是一个跟其它特征完全无关的独立同分布高斯随机变量,那么这一压缩表示将会非常难学习。但是如果输入数据中隐含着一些特定的结构,比如某些输入特征是彼此相关的,那么这一算法就可以发现输入数据中的这些相关性。事实上,这一简单的自编码神经网络通常可以学习出一个跟主元分析(PCA)结果非常相似的输入数据的低维表示。
我们刚才的论述是基于隐藏神经元数量较小的假设。但是即使隐藏神经元的数量较大(可能比输入像素的个数还要多),我们仍然通过给自编码神经网络施加一些其他的限制条件来发现输入数据中的结构。具体来说,如果我们给隐藏神经元加入稀疏性限制,那么自编码神经网络即使在隐藏神经元数量较多的情况下仍然可以发现输入数据中一些有趣的结构。
稀疏性可以被简单地解释如下。如果当神经元的输出接近于1的时候我们认为它被激活,而输出接近于0的时候认为它被抑制,那么使得神经元大部分的时间都是被抑制的限制则被称作稀疏性限制。这里我们假设的神经元的激活函数是sigmoid函数。如果你使用tanh作为激活函数的话,当神经元输出为-1的时候,我们认为神经元是被抑制的。
注意到 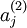 表示隐藏神经元
表示隐藏神经元  的激活度,但是这一表示方法中并未明确指出哪一个输入 带来了这一激活度。所以我们将使用
的激活度,但是这一表示方法中并未明确指出哪一个输入 带来了这一激活度。所以我们将使用 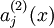 来表示在给定输入为 情况下,自编码神经网络隐藏神经元 的激活度。 进一步,让
来表示在给定输入为 情况下,自编码神经网络隐藏神经元 的激活度。 进一步,让
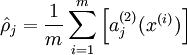
表示隐藏神经元 的平均活跃度(在训练集上取平均)。我们可以近似的加入一条限制
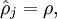
其中, 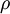 是稀疏性参数,通常是一个接近于0的较小的值(比如
是稀疏性参数,通常是一个接近于0的较小的值(比如 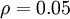 )。换句话说,我们想要让隐藏神经元 的平均活跃度接近0.05。为了满足这一条件,隐藏神经元的活跃度必须接近于0。
)。换句话说,我们想要让隐藏神经元 的平均活跃度接近0.05。为了满足这一条件,隐藏神经元的活跃度必须接近于0。
为了实现这一限制,我们将会在我们的优化目标函数中加入一个额外的惩罚因子,而这一惩罚因子将惩罚那些 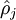 和 有显著不同的情况从而使得隐藏神经元的平均活跃度保持在较小范围内。惩罚因子的具体形式有很多种合理的选择,我们将会选择以下这一种:
和 有显著不同的情况从而使得隐藏神经元的平均活跃度保持在较小范围内。惩罚因子的具体形式有很多种合理的选择,我们将会选择以下这一种:
这里, 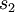 是隐藏层中隐藏神经元的数量,而索引 依次代表隐藏层中的每一个神经元。如果你对相对熵(KL divergence)比较熟悉,这一惩罚因子实际上是基于它的。于是惩罚因子也可以被表示为
是隐藏层中隐藏神经元的数量,而索引 依次代表隐藏层中的每一个神经元。如果你对相对熵(KL divergence)比较熟悉,这一惩罚因子实际上是基于它的。于是惩罚因子也可以被表示为
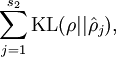
其中 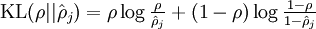 是一个以 为均值和一个以 为均值的两个伯努利随机变量之间的相对熵。相对熵是一种标准的用来测量两个分布之间差异的方法。
是一个以 为均值和一个以 为均值的两个伯努利随机变量之间的相对熵。相对熵是一种标准的用来测量两个分布之间差异的方法。
这一惩罚因子有如下性质,当 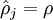 时
时 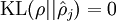 ,并且随着 与 之间的差异增大而单调递增。举例来说,在下图中,我们设定
,并且随着 与 之间的差异增大而单调递增。举例来说,在下图中,我们设定 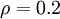 并且画出了相对熵值
并且画出了相对熵值 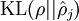 随着 变化的变化。
随着 变化的变化。
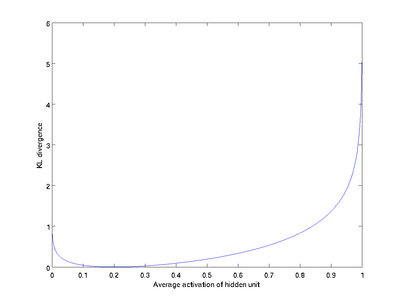
我们可以看出,相对熵在 时达到它的最小值0,而当 靠近0或者1的时候,相对熵则变得非常大(其实是趋向于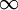 )。所以,最小化这一惩罚因子具有使得 靠近 的效果。 现在,我们的总体代价函数可以表示为
)。所以,最小化这一惩罚因子具有使得 靠近 的效果。 现在,我们的总体代价函数可以表示为
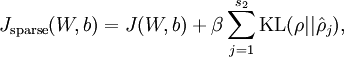
其中 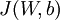 如之前所定义,而
如之前所定义,而 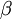 控制稀疏性惩罚因子的权重。 项则也(间接地)取决于
控制稀疏性惩罚因子的权重。 项则也(间接地)取决于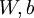 ,因为它是隐藏神经元 的平均激活度,而隐藏层神经元的激活度取决于 。
,因为它是隐藏神经元 的平均激活度,而隐藏层神经元的激活度取决于 。
为了对相对熵进行导数计算,我们可以使用一个易于实现的技巧,这只需要在你的程序中稍作改动即可。具体来说,前面在后向传播算法中计算第二层( 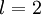 )更新的时候我们已经计算了
)更新的时候我们已经计算了
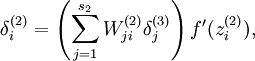
现在我们将其换成
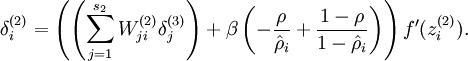
就可以了。
有一个需要注意的地方就是我们需要知道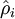 来计算这一更新项。所以在计算任何神经元的后向传播之前,你需要对所有的训练样本计算一遍前向传播,从而获取平均激活度。然后你就可以使用事先计算好的激活度来对所有的训练样本进行后向传播的计算。如果你的数据量太大,无法全部存入内存,你就可以扫过你的训练样本并计算一次前向传播,然后将获得的结果累积起来并计算平均激活度 (当某一个前向传播的结果中的激活度
来计算这一更新项。所以在计算任何神经元的后向传播之前,你需要对所有的训练样本计算一遍前向传播,从而获取平均激活度。然后你就可以使用事先计算好的激活度来对所有的训练样本进行后向传播的计算。如果你的数据量太大,无法全部存入内存,你就可以扫过你的训练样本并计算一次前向传播,然后将获得的结果累积起来并计算平均激活度 (当某一个前向传播的结果中的激活度 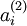 被用于计算平均激活度 之后就可以将此结果删除)。然后当你完成平均激活度 的计算之后,你需要重新对每一个训练样本做一次前向传播从而可以对其进行后向传播的计算。对于后一种情况,你对每一个训练样本需要计算两次前向传播,所以在计算上的效率会稍低一些。
被用于计算平均激活度 之后就可以将此结果删除)。然后当你完成平均激活度 的计算之后,你需要重新对每一个训练样本做一次前向传播从而可以对其进行后向传播的计算。对于后一种情况,你对每一个训练样本需要计算两次前向传播,所以在计算上的效率会稍低一些。
可视化自编码器训练结果
训练完(稀疏)自编码器,我们还想把这自编码器学到的函数可视化出来,好弄明白它到底学到了什么。我们以在10×10图像(即n=100)上训练自编码器为例。在该自编码器中,每个隐藏单元i对如下关于输入的函数进行计算:
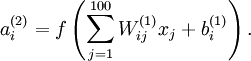
我们将要可视化的函数,就是上面这个以2D图像为输入、并由隐藏单元i计算出来的函数。它是依赖于参数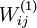 的(暂时忽略偏置项bi)。需要注意的是,可以看作输入x的非线性特征。不过还有个问题:什么样的输入图像x可让得到最大程度的激励(自己理解:也就是说对于什么样的输入的这种特征最好,相应的特征值达到最大)?(通俗一点说,隐藏单元
的(暂时忽略偏置项bi)。需要注意的是,可以看作输入x的非线性特征。不过还有个问题:什么样的输入图像x可让得到最大程度的激励(自己理解:也就是说对于什么样的输入的这种特征最好,相应的特征值达到最大)?(通俗一点说,隐藏单元 要找个什么样的特征?)。这里我们必须给x加约束,否则会得到平凡解。
要找个什么样的特征?)。这里我们必须给x加约束,否则会得到平凡解。
若假设输入有范数约束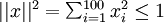 ,则可证(请读者自行推导)令隐藏单元得到最大激励的输入应由下面公式计算的像素
,则可证(请读者自行推导)令隐藏单元得到最大激励的输入应由下面公式计算的像素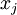 给出(共需计算100个像素,j=1,…,100):
给出(共需计算100个像素,j=1,…,100):
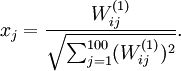
当我们用上式算出各像素的值、把它们组成一幅图像、并将图像呈现在我们的面前之时,隐藏单元i所追寻特征的真正含义也就明朗起来。
假如我们训练的自编码器有100个隐藏单元,可视化结果就会包含100幅这样的图像——每个隐藏单元都对应一幅图像。审视这100幅图像,我们可以试着体会这些隐藏单元学出来的整体效果是什么样的。(自己注意:可视化图像是怎么得出来的)
当我们对稀疏自编码器(100个隐藏单元,在10×10像素输入上训练)进行上述可视化处理之后,结果如下所示:

每个小方块都给出了一个(带有有界范数的)输入图像x,它可使这100个隐藏单元中的某一个获得最大激励。我们可以看到,不同的隐藏单元学会了在图像的不同位置和方向进行边缘检测。
显而易见,这些特征对物体识别等计算机视觉任务是十分有用的。若将其用于其他输入域(如音频),该算法也可学到对这些输入域有用的表示或特征。
【转】自编码算法与稀疏性(AutoEncoder and Sparsity)的更多相关文章
- UFLDL(五)自编码算法与稀疏性
新教程内容太繁复,有空再看看,这节看的还是老教程: http://ufldl.stanford.edu/wiki/index.php/%E8%87%AA%E7%BC%96%E7%A0%81%E7%AE ...
- 机器学习入门13 - 正则化:稀疏性 (Regularization for Sparsity)
原文链接:https://developers.google.com/machine-learning/crash-course/regularization-for-sparsity/ 1- L₁正 ...
- deep learning 自编码算法详细理解与代码实现(超详细)
在有监督学习中,训练样本是有类别标签的.现在假设我们只有一个没有带类别标签的训练样本集合 ,其中 .自编码神经网络是一种无监督学习算法,它使用了反向传播算法,并让目标值等于输入值,比如 .下图是一个自 ...
- 三层神经网络自编码算法推导和MATLAB实现 (转载)
转载自:http://www.cnblogs.com/tornadomeet/archive/2013/03/20/2970724.html 前言: 现在来进入sparse autoencoder的一 ...
- cuSPARSELt开发NVIDIA Ampere结构化稀疏性
cuSPARSELt开发NVIDIA Ampere结构化稀疏性 深度神经网络在各种领域(例如计算机视觉,语音识别和自然语言处理)中均具有出色的性能.处理这些神经网络所需的计算能力正在迅速提高,因此有效 ...
- Android数据加密之Base64编码算法
前言: 前面学习总结了平时开发中遇见的各种数据加密方式,最终都会对加密后的二进制数据进行Base64编码,起到一种二次加密的效果,其实呢Base64从严格意义上来说的话不是一种加密算法,而是一种编码算 ...
- 【字符编码】字符编码 && Base64编码算法
一.前言 在前面的解决乱码的一文中,只找到了解决办法,但是没有为什么,说白了,就是对编码还是不是太熟悉,编码问题是一个很简单的问题,计算机从业人员应该也必须弄清楚,基于编码的应用有Base64加密算法 ...
- 浅谈URLEncoder编码算法
一.为什么要用URLEncoder 客户端在进行网页请求的时候,网址中可能会包含非ASCII码形式的内容,比如中文. 而直接把中文放到网址中请求是不允许的,所以需要用URLEncoder编码地址, 将 ...
- 浅谈Hex编码算法
一.什么是Hex 将每一个字节表示的十六进制表示的内容,用字符串来显示. 二.作用 将不可见的,复杂的字节数组数据,转换为可显示的字符串数据 类似于Base64编码算法 区别:Base64将三个字节转 ...
随机推荐
- 自己用原生JS写的轮播图,支持移动端触屏滑动,面向对象思路。分页器圆点支持click和mouseover。
自己用原生javascript写的轮播图,面向对象思路,支持移动端手指触屏滑动.分页器圆点可以选择click点击或mouseover鼠标移入时触发.图片滚动用的setInterval,感觉setInt ...
- google friendly testing
https://www.google.com/webmasters/tools/mobile-friendly/?mc_cid=cc21b18877&mc_eid=cf2bbeb9b2 htt ...
- Java设计模式(5)——创建型模式之建造者模式(Builder)
一.概述 概念 将一个复杂的构建与其表示相分离,使得同样的构建过程可以创建不同的表示.(与工厂类不同的是它用于创建复合对象) UML图 主要角色 抽象建造者(Builder)——规范建造方法与结果 ...
- 使用cgroups来控制磁盘IO带宽
磨砺技术珠矶,践行数据之道,追求卓越价值 回到上一级页面:PostgreSQL内部结构与源代码研究索引页 回到顶级页面:PostgreSQL索引页 [作者 高健@博客园 luckyjackga ...
- Android stdio build.gradle buildscript 里面的repositories 和allprojects里面 repositories 的区别
第一段 buildscript 里面的 repositories 表示只有编译工具才会用这个仓库. 比如 buildscript 里面的 dependencies classpath 'com.and ...
- logback.xml日志文件配置
放在resources目录下面就可以自动读取<?xml version="1.0" encoding="UTF-8"?> <configura ...
- RTL8188EUS之MAC地址烧写(使用利尔达模组)
1. 手上有几个RTL8188EUS的wifi模块,打算把台式机装个无线网卡,但是插上之后发现没有MAC,没办法只能自己去找个烧写MAC的软件.RTL8188内部有个eFuse,用来配置之类的.这个e ...
- SpringBoot学习:整合shiro(rememberMe记住我后自动登录session失效解决办法)
项目下载地址:http://download.csdn.NET/detail/aqsunkai/9805821 定义一个拦截器,判断用户是通过记住我登录时,查询数据库后台自动登录,同时把用户放入ses ...
- Ruby 基础教程1-6
1.循环实现方法 循环语句 (while;for; loop,until) 循环方法(times,each) 2.for for 变量 in 对象 主体 ...
- vim程序员加强功能
1.折叠 1.1折叠的方式有六种 manual:以标准的vim结构定义折叠跨越的范围,类似移动命令 indent:折叠与折叠的层次,对应于文本的缩排与 ...